
作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/33
本文地址:http://www.showmeai.tech/article-detail/142
声明:版权所有,转载请联系平台与作者并注明出处
n维数组是NumPy的核心概念,大部分数据的操作都是基于n维数组完成的。本系列内容覆盖到1维数组操作、2维数组操作、3维数组操作方法,本篇讲解Numpy与1维数组操作。
一、向量初始化
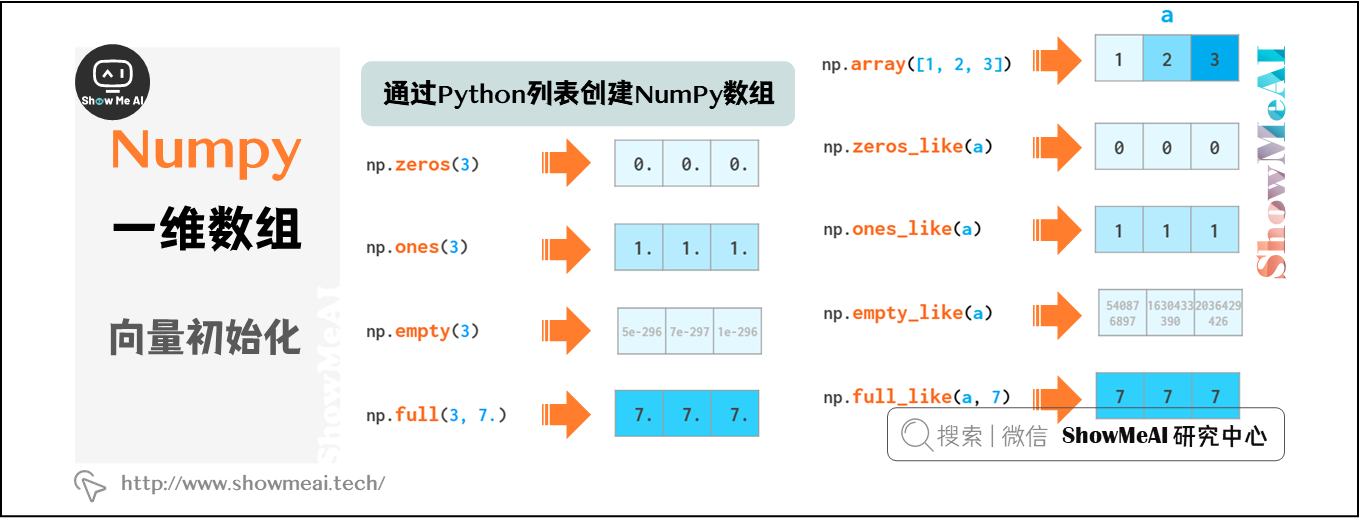
可以通过Python列表创建NumPy数组。

如图中(a),将列表元素转化为一维数组。注意,这里一般会确保列表元素类型相同,否则默认dtype=’object',会影响后续运算,甚至产生语法错误。
由于在数组末尾没有预留空间以快速添加新元素,NumPy数组无法像Python列表那样增长。因此,通常的处理方式包括:
- 在变长Python列表中准备好数据,然后将其转换为NumPy数组
- 使用
np.zeros或np.empty预先分配必要的空间(图中b)
通过图中(c)方法,可以创建一个与某一变量形状一致的空数组。
不止是空数组,通过上述方法还可以将数组填充为特定值:
在NumPy中,还可以通过单调序列初始化数组:

如果我们需要浮点数组,可以使用 arange(3).astype(float) 这样的操作更改arange输出的类型,也可以在参数端使用浮点数,比如 arange(4.) 来生产浮点数Numpy数组。
以下是arange浮点类型数据可能出现的一些问题及解决方案:

图中,0.1对我们来说是一个有限的十进制数,但对计算机而言,它是一个二进制无穷小数,必须四舍五入为一个近似值。因此,将小数作为arange的步长可能导致一些错误。可以通过以下两种方式避免如上错误:
- 使间隔末尾落入非整数步数,但这会降低可读性和可维护性;
- 使用linspace,这样可以避免四舍五入的错误影响,并始终生成要求数量的元素。
- 使用linspace时尤其需要注意最后一个的数量参数设置,由于它计算点数量,而不是间隔数量,因此上图中数量参数是11,而不是10。
随机数组的生成方法如下:

二、向量索引
NumPy可以使用非常直接的方式对数组数据进行访问:
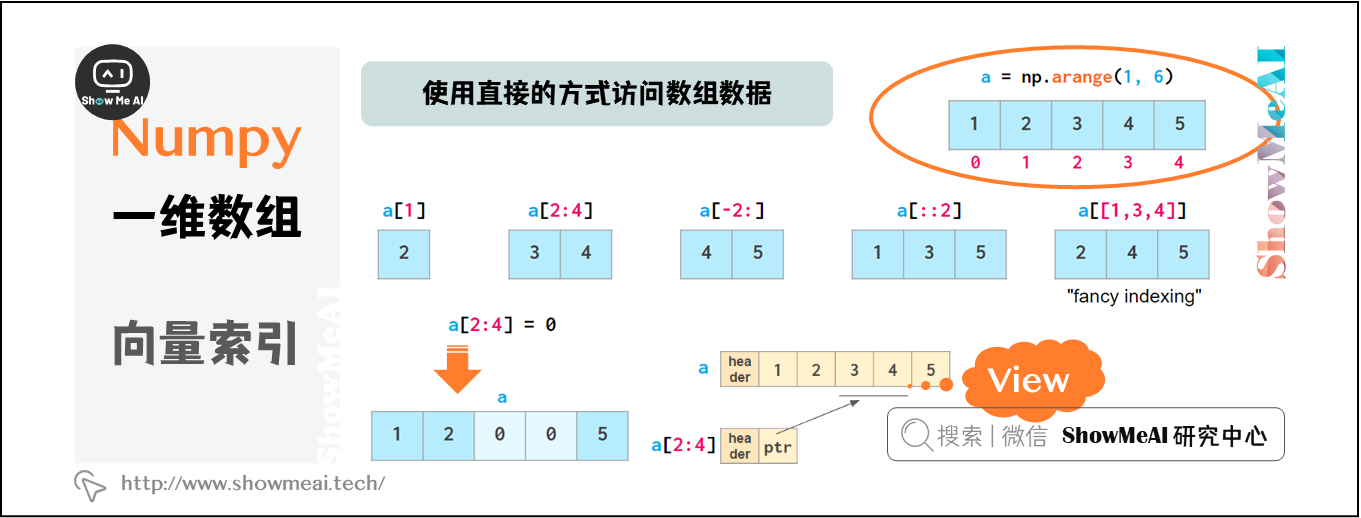
图中,除“fancy indexing”外,其他所有索引方法本质上都是views:它们并不存储数据,如果原数组在被索引后发生更改,则会反映出原始数组中的更改。
上述所有这些方法都可以改变原始数组,即允许通过分配新值改变原数组的内容。这导致无法通过切片来复制数组。如下是python列表和NumPy数组的对比:

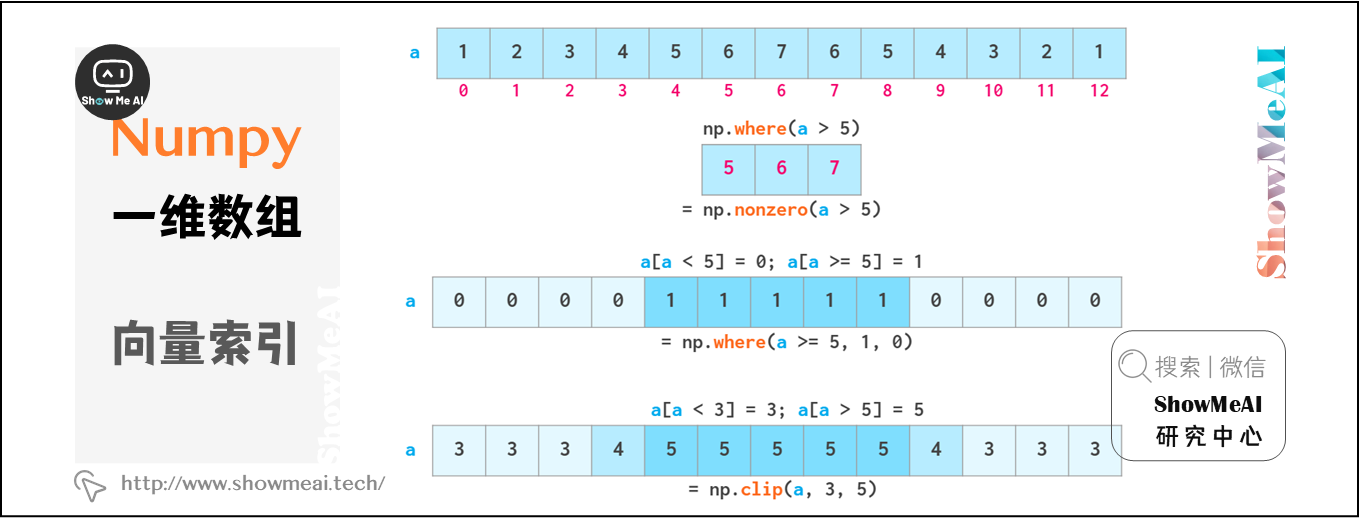
NumPy数组支持通过布尔索引获取数据,结合各种逻辑运算符可以有很高级的数据选择方式,这在Python列表中是不具备的:

注意,不可以使用3 <= a <= 5这样的Python“三元”比较。
如上所述,布尔索引是可写的。如下图 np.where 和 np.clip 两个专有函数。
三、向量操作
NumPy支持快速计算,向量运算操作接近C++速度级别,并不受Python循环本身计算慢的限制。NumPy允许像普通数字一样操作整个数组:
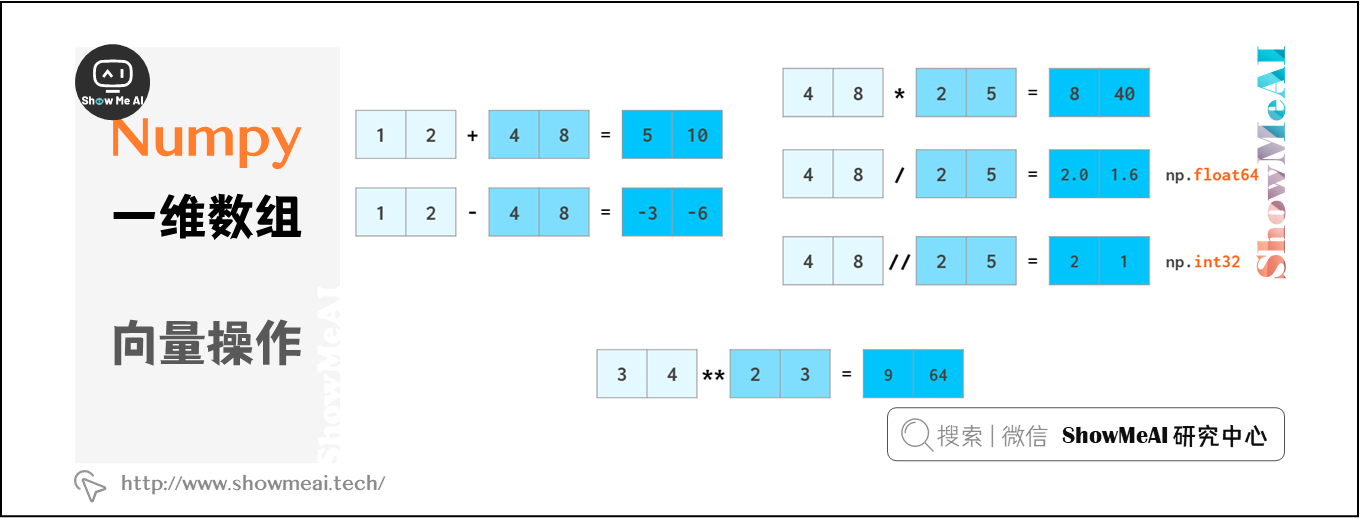
在python中,a//b表示a div b(除法的商),x**n表示 xⁿ
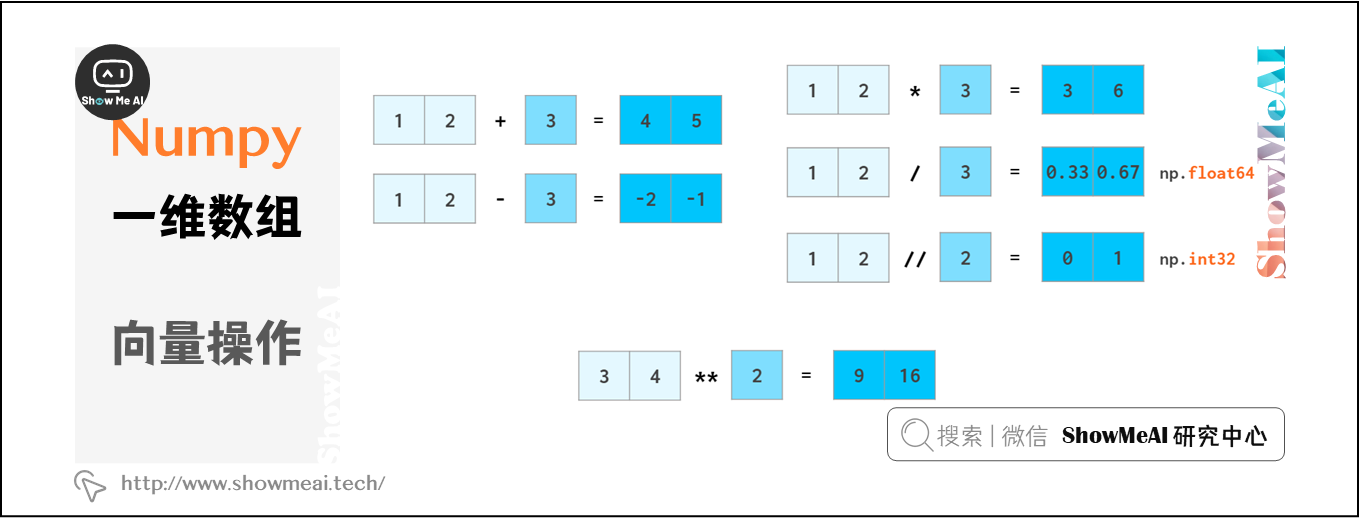
浮点数的计算也是如此,NumPy能够将标量广播到数组:
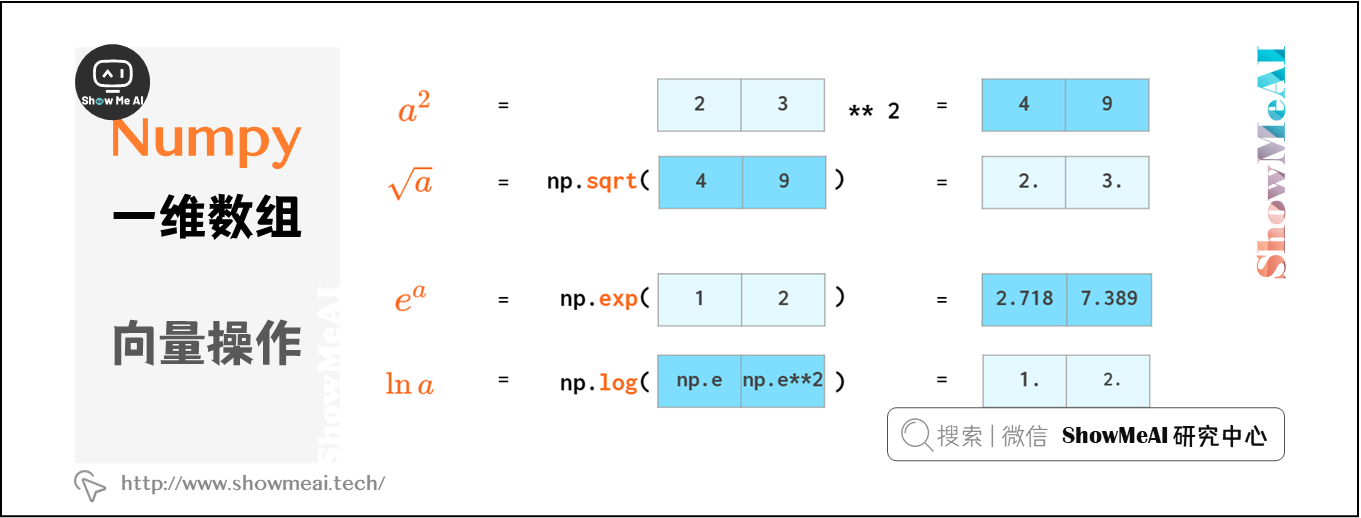
Numpy提供了许多数学函数来处理矢量:
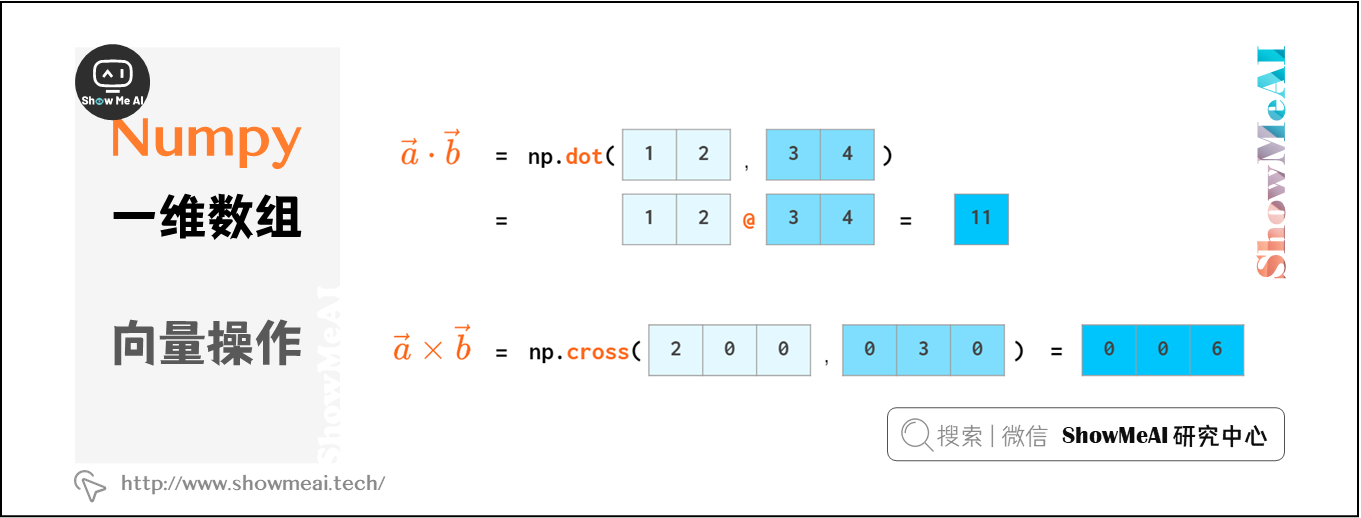
向量点乘(内积)和叉乘(外积、向量积)如下:
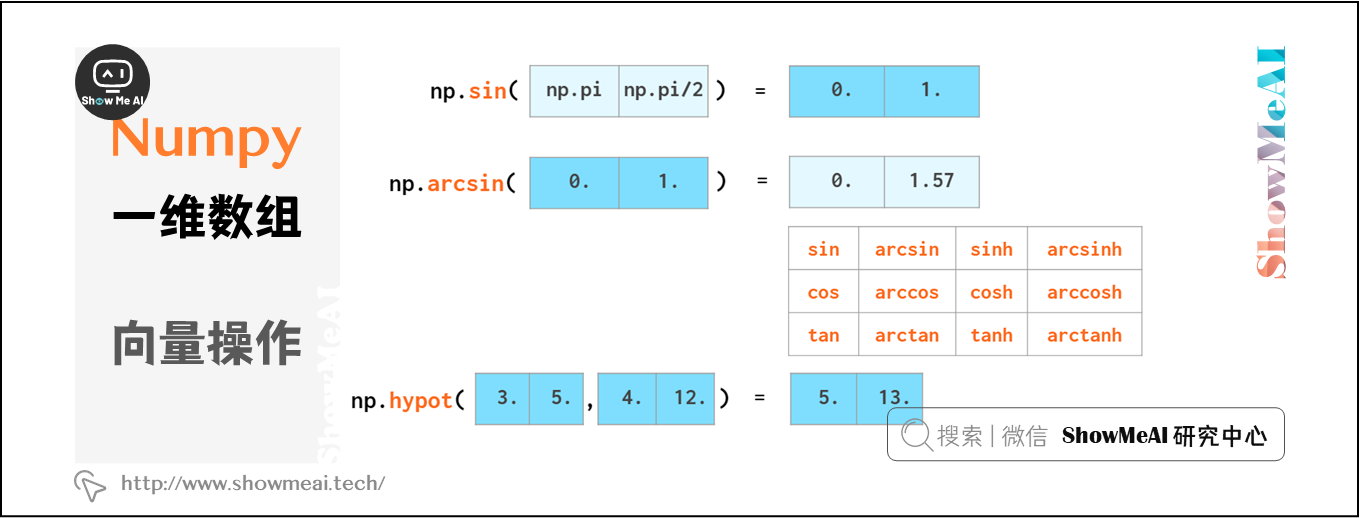
NumPy也提供了如下三角函数运算:
数组整体进行四舍五入:
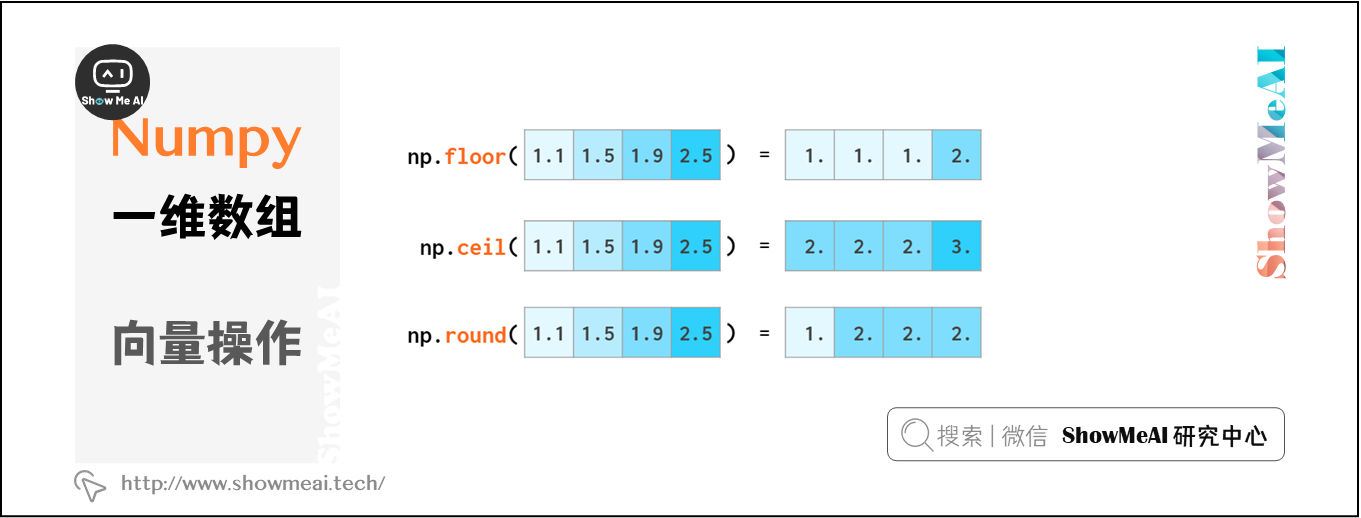
floor向上取整,ceil向下取整,round四舍五入
np.around 与 np.round 是等效的,这样做只是为了避免 from numpy import * 时与Python around的冲突(但一般的使用方式是import numpy as np)。当然,你也可以使用a.round()。
NumPy还可以实现以下功能:

以上功能都存在相应的nan-resistant变体:例如nansum,nanmax等
在NumPy中,排序函数功能有所阉割:

对于一维数组,可以通过反转结果来解决reversed函数缺失的不足,但在2维数组中该问题变得棘手。
四、查找向量中的元素
NumPy数组并没有Python列表中的索引方法,索引数据的对比如下:
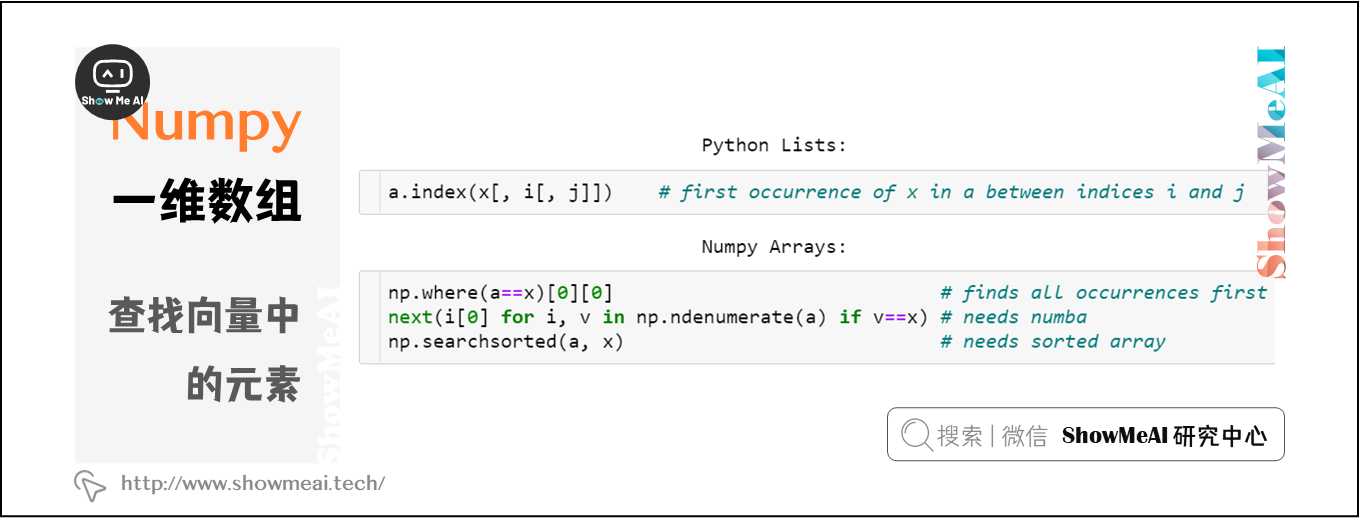
index()中的方括号表示 j 或 i&j 可以省略
- 可以通过
np.where(a==x)[0] [0]查找元素,但这种方法很不pythonic,哪怕需要查找的项在数组开头,该方法也需要遍历整个数组。 - 使用Numba实现加速查找,
next((i[0] for i, v in np.ndenumerate(a) if v==x), -1),在最坏的情况下,它的速度要比where慢。 - 如果数组是排好序的,使用
v = np.searchsorted(a, x);return v if a[v]==x else -1时间复杂度为O(log N),但在这之前,排序的时间复杂度为O(N log N)。
实际上,通过C实现加速搜索并不是困难,问题是浮点数据比较。
五、浮点数比较
np.allclose(a, b)用于容忍误差之内的浮点数比较。
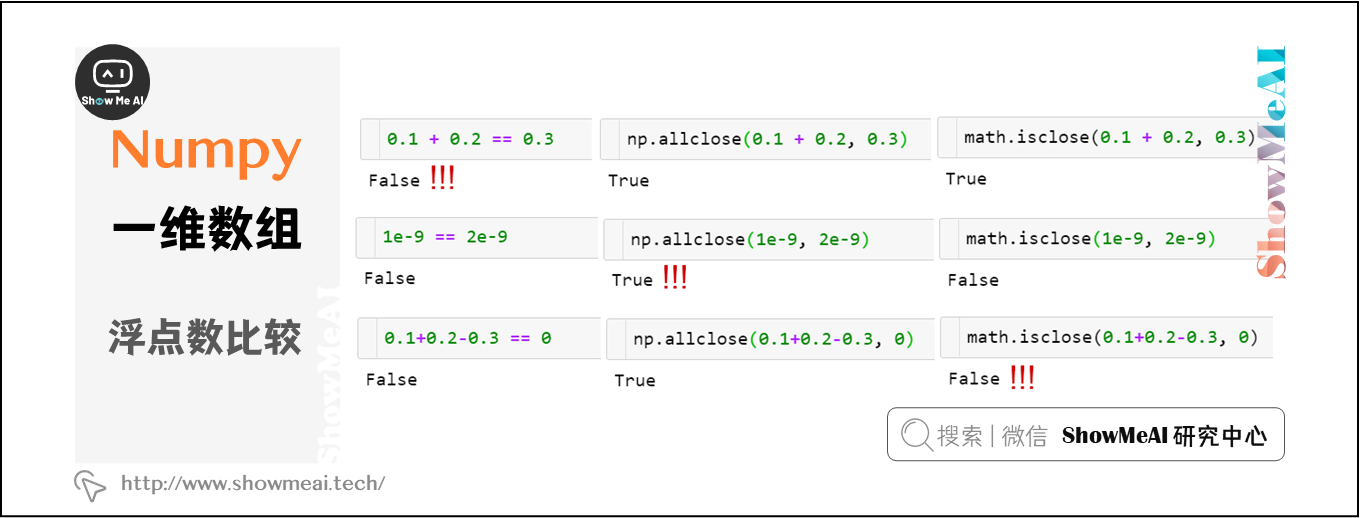
np.allclose假定所有比较数字的尺度为1。如果在纳秒级别上,则需要将默认atol参数除以1e9:np.allclose(1e-9,2e-9, atol=1e-17)==False。math.isclose不对要比较的数字做任何假设,而是需要用户提供一个合理的abs_tol值(np.allclose默认的atol值1e-8足以满足小数位数为1的浮点数比较,即math.isclose(0.1+0.2–0.3, abs_tol=1e-8)==True。
此外,对于绝队偏差和相对偏差,np.allclose依然存在一些问题。例如,对于某些值a、b, allclose(a,b)!=allclose(b,a),而在math.isclose中则不存在这些问题。查看GitHub上的浮点数据指南和相应的NumPy问题了解更多信息。
资料与代码下载
本教程系列的代码可以在ShowMeAI对应的github中下载,可本地python环境运行,能访问Google的宝宝也可以直接借助google colab一键运行与交互操作学习哦!
本系列教程涉及的速查表可以在以下地址下载获取:
拓展参考资料
ShowMeAI相关文章推荐
- 数据分析介绍
- 数据分析思维
- 数据分析的数学基础
- 业务认知与数据初探
- 数据清洗与预处理
- 业务分析与数据挖掘
- 数据分析工具地图
- 统计与数据科学计算工具库Numpy介绍
- Numpy与1维数组操作
- Numpy与2维数组操作
- Numpy与高维数组操作
- 数据分析工具库Pandas介绍
- 图解Pandas核心操作函数大全
- 图解Pandas数据变换高级函数
- Pandas数据分组与操作
- 数据可视化原则与方法
- 基于Pandas的数据可视化
- seaborn工具与数据可视化
ShowMeAI系列教程推荐
