-
【文章摘要-20231019】Any-to-Any Generation via Composable Diffusion
论文链接
代码链接作者提出了一个可组合的扩散模型,该模型体现为能够处理任何输入模态的组合,进而输出任何模态组合的新型生成模型,如语言、图像、视频或音频。不同于已经存在的生成式人工智能系统,该算法能够并行生成多个模态并且他的输出不仅限于图像或文本这种子集。尽管对于许多模态的组合训练集是缺乏的,作者提出同时在输出和输入空间对齐多个模态。这使得该算法能够自由调节任何输入模态的结合并生成任何模态的组合,即使在数据训练数据中没有体现。该算法采用一个新颖的可组合式的生成策略,其中包含在扩散过程中通过桥接对齐建立一个共享的多模态空间,进而同步生成相互交织的模态,如暂时性对齐的视频和音频。

同一空间特征对齐、任意模态生成任意模态
方法
3.1 Preliminary: Latent Diffusion Model


3.2 Composable Multimodal Conditioning
作者首先进行模态的加权
提出了"Bridging Alignment",选择文本作为衔接,采用对比学习对齐
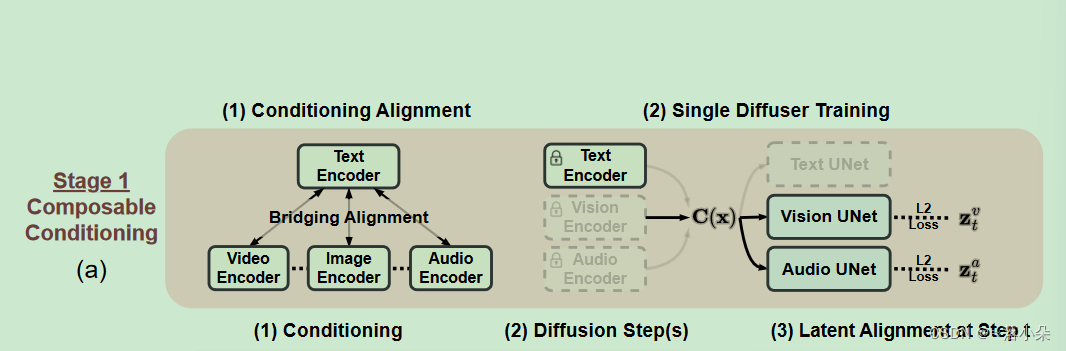
3.3 Composable Diffusion
作者分别构建单个模态的模型,分别训练不同模态的扩散模型
图像:根据文献【41】
文本:
3.4 Joint Multimodal Generation by Latent Alignment
生成模态:联合生成,采用对比学习对齐。

-
相关阅读:
为什么要用WRF计算非绝热加热项,以及如何输出非绝热加热项.
基于竞争学习的粒子群优化算法-附代码
如何实现制造业信息化转型?
RabbitMQ 模拟实现【五】:网络通信设计
【Python】四、程序顺序和分支控制结构
NSSCTF[SWPUCTF 2021 新生赛]hardrce(无字母RCE)
统计学习方法 支持向量机(上)
《动手学深度学习 Pytorch版》 5.4 自定义层
【PCB学习笔记】绘制智能车四层板 --- DRC检查,拼版设计及资料输出
minikube部署K8s命令
- 原文地址:https://blog.csdn.net/weixin_43169773/article/details/133919150