-
蒙特卡洛树搜索方法介绍——Q规划与Dyna-Q算法
引言
上一节介绍了规划与学习的相关信息,并介绍了直接强化学习(Direct Reinforcement Learning)和间接强化学习(Indirect Reinforcement Learning),本节利用上述两种概念,介绍 Q Q Q规划算法与Dyna-Q算法。
回顾:直接强化学习与间接强化学习
如果单纯使用规划方法,其主要思想表示如下:
- 已知环境模型——对任意状态 s ∈ S s \in \mathcal S s∈S,动作 a ∈ A ( s ) a \in \mathcal A(s) a∈A(s)确定的情况下,其转移后的新状态 s ′ s' s′,对应的奖励结果 r r r的动态特性函数 P ( s ′ , r ∣ s , a ) P(s',r \mid s,a) P(s′,r∣s,a)均是给定的;
- 根据状态-动作对
(
s
,
a
)
(s,a)
(s,a),通过 环境模型 进行搜索(Search),得到新状态
s
′
s'
s′和对应奖励结果
r
r
r(基于 模拟经验(Simulation Experience)产生的结果);
注意:此时产生的s'和r被称为‘模拟经验’——它并不是从真实环境中真实地执行了一次状态转移过程,而是在动态特性函数P(s',r|s,a)中基于转移后新状态的概率分布,随机选择的结果。 - 至此,得到了一组 模拟状态转移结果
→
(
s
,
a
,
s
′
,
r
)
\to (s,a,s',r)
→(s,a,s′,r),利用该结果更新策略
π
\pi
π。
以动态规划方法为例,该方法主要使用策略迭代操作:- 策略评估(Policy Evaluation):(贝尔曼期望方程的不动点性质)
V k + 1 ( s ) = ∑ a ∈ A ( s ) π ( a ∣ s ) ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V k ( s ′ ) ] V_{k+1}(s) = \sum_{a \in \mathcal A(s)}\pi(a \mid s) \sum_{s',r}P(s',r \mid s,a)[r+ \gamma V_{k}(s')] Vk+1(s)=a∈A(s)∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+γVk(s′)] - 策略改进(Policy Improvment):(贪心算法)
π ∗ ( a ∣ s ) = { 1 i f a = arg max a ∈ A q π ∗ ( s , a ) 0 e l s e \pi_*(a \mid s) = \left\{\right. π∗(a∣s)={1ifa=a∈Aargmaxqπ∗(s,a)0else1 i f a = arg max a ∈ A q π ∗ ( s , a ) 0 e l s e
- 策略评估(Policy Evaluation):(贝尔曼期望方程的不动点性质)
由于上述思想是基于环境模型给定的条件下,直接使用环境模型对策略进行规划。因此,上述方法属于直接强化学习。
直接强化学习的定义:在真实环境中采集真实经验,根据真实经验直接更新值函数或策略,不受模型偏差的影响。
在动态规划方法中,它通过动态特性函数获取模拟经验,它不是真实经验,但为什么‘动态规划方法’是‘直接强化学习’呢?
以下是个人看法:动态规划中已知的动态特性函数就是‘理想状态下模型的表达’——也可以理解成经过无数次采样近似出的‘完美环境模型’。因此,动态规划方法产生的经验同样是‘真实经验’。使用学习方法的主要思想是基于环境模型未知或未完全可知,导致我们 无法使用环境模型直接对策略进行规划。因此,使用学习(Learning)方法求解真实经验:
在真实环境中,给定状态 s s s条件下,选择具体动作 a ∈ A ( s ) a \in \mathcal A(s) a∈A(s),并执行一次真实的状态转移过程得到新状态 s ′ s' s′以及对应奖励 r r r。至此,我们得到一组 真实状态转移结果 ( s , a , s ′ , r ) (s,a,s',r) (s,a,s′,r),在求解策略 π \pi π的方向中,共分为 两条路径:
- 由于
(
s
,
a
,
s
′
,
r
)
(s,a,s',r)
(s,a,s′,r)是真实转移结果,完全可以 使用采样近似的方法直接求解策略
π
\pi
π。例如
Q
−
L
e
a
r
n
i
n
g
Q-Learning
Q−Learning:
- 评估过程:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a Q ( s ′ , a ) − Q ( s , a ) ] Q(s,a) \gets Q(s,a) + \alpha[r + \gamma \mathop{\max}\limits_{a} Q(s',a) - Q(s,a)] Q(s,a)←Q(s,a)+α[r+γamaxQ(s′,a)−Q(s,a)] - 改进过程(
ϵ
−
\epsilon-
ϵ−贪心策略):
a ∗ ← arg max a Q ( s , a ) b ( a ∣ s ) ← { 1 − ϵ k + ϵ k ∣ A ( s ) ∣ i f a = a ∗ ϵ k ∣ A ( s ) ∣ o t h e r w i s ea∗b(a∣s)←aargmaxQ(s,a)←{1−ϵk+∣A(s)∣ϵkifa=a∗∣A(s)∣ϵkotherwisea ∗ ← arg max a Q ( s , a ) b ( a ∣ s ) ← { 1 − ϵ k + ϵ k | A ( s ) | i f a = a ∗ ϵ k | A ( s ) | o t h e r w i s e
- 评估过程:
这种方法通过真实采样直接对策略 π \pi π进行学习。因此,上述方式同样属于直接强化学习。
- 另一条路线:使用真实转移结果去近似求解模型(这里区别于上述给定的环境模型),此时已经有了模型,完全可以再次使用规划方法对策略进行求解。
这种方式明显是先求模型,再通过模型求解策略——我们称其为间接强化学习。
规划与学习的差异性
分布模型与样本模型
- 在理想情况下,例如动态规划方法,我们无须担心环境模型,该模型是一个 完全符合环境的、完美的概率分布——我们称该模型为分布模型;
- 在真实环境中,上面的分布模型是极难实现的,我们只能通过真实样本作为输入,通过 真实的状态转移过程 得到真实经验,从而对模型进行学习。
但这种做法会带来模型偏差:通过真实样本结果得到了一个状态转移后的新状态,但 真实情况可能是新状态的选择存在随机性。即它有可能选择好多种状态,该真实样本只是恰巧选择了其中一个。
在这里我们为简化起见:消除随机性,将 真实样本直接看成环境模型。即不考虑任何模型偏差,将真实样本 ( s , a , s ′ , r ) (s,a,s',r) (s,a,s′,r)视作 P ( s ′ , r ∣ s , a ) = 1 P(s',r \mid s,a)=1 P(s′,r∣s,a)=1的环境模型。它的概率分布可以理解为:
P ( s ′ , r ∣ s , a ) ← { 1 i f S t + 1 = s ′ , R t + 1 = r 0 o t h e r w i s e P(s',r \mid s,a) \gets \left\{\right. P(s′,r∣s,a)←{1ifSt+1=s′,Rt+1=r0otherwise1 i f S t + 1 = s ′ , R t + 1 = r 0 o t h e r w i s e
我们称该模型为样本模型。
从算法更新图的角度认识规划与学习的差异性
观察动态规划方法、蒙特卡洛方法、时序差分方法的算法更新图如下:


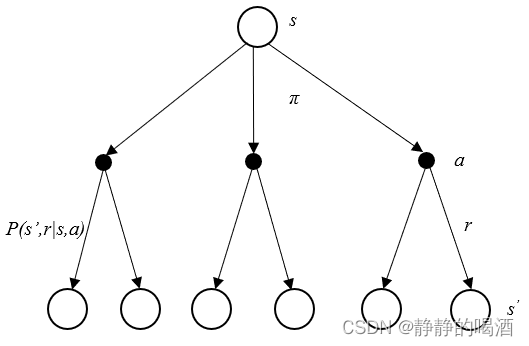
三张图中,只有动态规划方法是基于规划方法执行的操作,剩余两种方法是基于学习方法执行的操作。观察:- 动态规划方法将 一次状态转移后的所有可能发生的新状态全部遍历一遍,并对所有新状态的价值函数进行求解,最终使用所有状态价值函数的期望对当前状态进行更新。我们称这种更新方式为 期望更新。
V k + 1 ( s ) = ∑ a ∈ A ( s ) π ( a ∣ s ) ∑ s ′ , r P ( s ′ , r ∣ s , a ) [ r + γ V k ( s ′ ) ] V_{k+1}(s) = \sum_{a \in \mathcal A(s)}\pi(a \mid s) \sum_{s',r}P(s',r \mid s,a)[r+ \gamma V_{k}(s')] Vk+1(s)=a∈A(s)∑π(a∣s)s′,r∑P(s′,r∣s,a)[r+γVk(s′)] - 反观蒙特卡洛、时序差分方法,他们都是通过采集真实样本对当前状态进行更新。我们称这种更新方式为 采样更新。
从遍历深度和遍历广度两个角度观察规划和学习的差异性:
-
从广度角度(执行一次状态转移操作后遍历新状态的数量)来看,基于学习方法的采样更新自然 一次只能遍历一个新状态节点,基于规划方法的期望更新能够 一次遍历多个新状态节点;
采样不广 -
从深度角度(更新一次策略需要的状态转移次数)来看,时序差分方法、动态规划方法都基于 自举(Bootstrapping)思想,因此每次迭代仅执行一次状态转移过程;
即便是SARSA,使用同轨策略执行了两次动作的选择,但仍然是只有一次状态转移过程。
但蒙特卡洛方法至少要遍历一个完整情节才能执行一次迭代过程,一个完整情节的遍历自然存在若干次状态转移过程。
自举不深
随机采样单步表格式Q规划
该算法的算法流程表示如下:
- 从状态集合 S \mathcal S S中随机选择某一状态 s ∈ S s \in \mathcal S s∈S,从对应的动作集合 A ( s ) \mathcal A(s) A(s)中选择一个动作 a ∈ A ( s ) a \in \mathcal A(s) a∈A(s)构成状态-动作对 ( s , a ) (s,a) (s,a);
- 将状态-动作对
(
s
,
a
)
(s,a)
(s,a)带入样本模型(Sample Model),从而得到下一时刻状态
s
′
s'
s′和对应奖励
r
r
r;
该步骤体现的Planning思想; - 将该样本
(
s
,
a
,
s
′
,
r
)
(s,a,s',r)
(s,a,s′,r)使用
Q
−
P
l
a
n
n
i
n
g
Q-Planning
Q−Planning进行对
Q
−
T
a
b
l
e
Q-Table
Q−Table进行更新;
该步骤体现的Q-Learning思想;
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a Q ( s ′ , a ) − Q ( s , a ) ] Q(s,a) \gets Q(s,a) + \alpha [r + \gamma \mathop{\max}\limits_{a} Q(s',a) - Q(s,a)] Q(s,a)←Q(s,a)+α[r+γamaxQ(s′,a)−Q(s,a)]
本质上Q规划是将规划(Planning)和Q-Learning相结合的简单算法。
分析:该算法中的样本模型(Sample Model)是 给定 的(在算法执行之前,就已经通过真实样本构建了一个样本模型)
这种模型即:给定一个状态 s ∈ S s \in \mathcal S s∈S,某一动作 a ∈ A ( s ) a \in \mathcal A(s) a∈A(s),必然会转移至确定状态 s ′ s' s′ 及对应奖励结果 r r r。
通过观察可知,Q-规划算法中并不存在通过真实样本去学习环境模型的步骤,自然也不存在环境模型被更新的过程。
其本质上就是构建了一个 当前样本模型相匹配的 Q − T a b l e Q-Table Q−Table而已。Dyna-Q算法
初始化部分:
状态集合: S \mathcal S S;动作集合: s ∈ S , a ∈ A ( s ) s \in \mathcal S,a \in \mathcal A(s) s∈S,a∈A(s); Q − T a b l e Q-Table Q−Table: Q ( s , a ) ∈ R Q(s,a) \in \mathbb R Q(s,a)∈R;样本模型(Sample Model): M o d e l ( s , a ) ∈ R Model(s,a) \in \mathbb R Model(s,a)∈R
注意:这里以‘样本模型’为例。
该算法的算法流程可以表示为两个过程:
学习过程:- repeat 每个情节 k = 0 , 1 , 2 , . . . k=0,1,2,... k=0,1,2,...;
- 当前状态(非终止状态) s s s;
- 从基于
Q
−
T
a
b
l
e
Q-Table
Q−Table中 状态
s
s
s 所在行使用
ϵ
−
\epsilon-
ϵ−贪心策略
π
(
s
)
\pi(s)
π(s)随机获取动作
a
a
a;
a ∗ ← arg max a Q ( s , a ) π ( s ) ← { 1 − ϵ k + ϵ k ∣ A ( s ) ∣ i f a = a ∗ ϵ k ∣ A ( s ) ∣ o t h e r w i s e a ← π ( s )a∗π(s)a←aargmaxQ(s,a)←{1−ϵk+∣A(s)∣ϵkifa=a∗∣A(s)∣ϵkotherwise←π(s)a ∗ ← arg max a Q ( s , a ) π ( s ) ← { 1 − ϵ k + ϵ k | A ( s ) | i f a = a ∗ ϵ k | A ( s ) | o t h e r w i s e a ← π ( s ) - 执行动作 a a a,得到下一状态 s ′ s' s′和对应奖励 r r r;
- 根据上述状态转移过程对
Q
−
T
a
b
l
e
Q-Table
Q−Table进行更新;
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a Q ( s ′ , a ) − Q ( s , a ) ] Q(s,a) \gets Q(s,a) + \alpha [r + \gamma \mathop{\max}\limits_{a} Q(s',a) - Q(s,a)] Q(s,a)←Q(s,a)+α[r+γamaxQ(s′,a)−Q(s,a)] - 将转移后的结果
s
′
,
r
s',r
s′,r添加到
M
o
d
e
l
Model
Model中(s,a)对应位置上;
M o d e l ( s , a ) ← s ′ , r Model(s,a) \gets s',r Model(s,a)←s′,r - 规划过程(嵌套循环):
规划过程:
- repeat n n n次( n n n表示规划次数);
- 从被访问过的状态集合中随机选择一个状态 s ^ \hat s s^;
- 从被访问过的动作集合中随机选择一个动作 a ^ \hat a a^;
- 将 s , a s,a s,a带入,通过模型 M o d e l Model Model得到一个 模拟经验结果(状态转移结果) s ′ ^ , r ^ \hat{s'},\hat r s′^,r^;
- 将上述状态转移过程对 Q − T a b l e Q-Table Q−Table进行更新;
- Q ( s ^ , a ^ ) ← Q ( s ^ , a ^ ) + α [ r ^ + γ max a Q ( s ′ ^ , a ) − Q ( s ^ , a ^ ) ] Q(\hat s,\hat a) \gets Q(\hat s,\hat a) + \alpha [\hat r + \gamma \mathop{\max}\limits_{a} Q(\hat{s'},a) - Q(\hat s,\hat a)] Q(s^,a^)←Q(s^,a^)+α[r^+γamaxQ(s′^,a)−Q(s^,a^)]
分析:
- 如果 n = 0 n = 0 n=0,整个算法将退化为 Q − L e a r n i n g → Q-Learning \to Q−Learning→只能通过当前情节每状态转移一次就更新一次 Q − T a b l e Q-Table Q−Table;
-
n
>
0
n > 0
n>0条件下发现,学习过程和规划过程都在更新同一个
Q
−
T
a
b
l
e
Q-Table
Q−Table,并且每次迭代(学习过程中的一次状态转移过程)
Q
−
T
a
b
l
e
Q-Table
Q−Table更新次数
<
=
n
+
1
<= n+1
<=n+1;
原因在于,如果在规划过程抽取出的‘状态-动作对’( s ^ , a ^ ) (\hat s,\hat a) (s^,a^)中的a ^ ∉ A ( s ^ ) \hat a \notin \mathcal A(\hat s) a^∈/A(s^),此时M o d e l Model Model中也不存在相应记录,也不会返回对应的s ′ ^ , r ^ \hat {s'},\hat r s′^,r^,相当于一个‘空循环’——没有更新Q-Table中的任何信息。
下一节将介绍基于Dyna-Q在算力聚焦思想中的改进——Dyna-Q+算法。
相关参考:
【强化学习】规划与学习-Dyna Architecture
深度强化学习原理、算法与PyTorch实战——刘全、黄志刚编著 -
相关阅读:
Python中直接赋值、浅拷贝和深拷贝的区别
MySQL之MHA高可用配置及故障切换
HTML西安旅游网页设计作业成品 大学生旅游风景区网页设计作业模板下载 静态HTML旅游景点网页制作下载 DW网页设计代码
TODO Vue typescript forEach的bug,需要再核實
微信小程序使用 scss
SpringCloud - Spring Cloud Netflix 之 Hystrix Dashboard仪表盘监控(九)
LeetCode_数学分析_中等_754.到达终点数字
Leetcode(524)——通过删除字母匹配到字典里最长单词
SpringBoot中的application.properties等一系列的配置文件
java二分查找(含二分查找代码)
- 原文地址:https://blog.csdn.net/qq_34758157/article/details/126135625