-
Day39、40、41 尚硅谷JUC——ThreadPool线程池
我是大白(●—●),这是我开始学习记录大白Java软件攻城狮晋升之路的第三十九到四十一天,今天学习的是【尚硅谷】大厂必备技术之JUC并发编程
一、概述和架构
1.线程池简介
线程池(thread pool) : 一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。
例子: 10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球, CPU需要来回切换。现在是多核电脑, 多个线程各自跑在独立的CPU上,不用切换效率高。
2.线程池的优势
线程池的优势:线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后再线程创建后启动这些任务,如果线程数量超过最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
主要特点是:线程复用、控制并发数、管理线程
降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。增加线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配,调优和监控。
3.线程池的架构
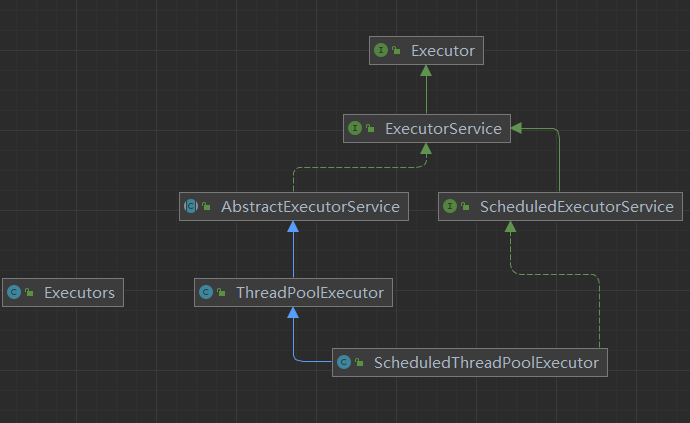
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor , Executors,ExecutorService , ThreadPoolExecutor这几个类二、使用方式和底层逻辑
1. 线程池的使用方式
Executors.newFixedThreadPool(int):一池N线程
Executors.newsingleThreadExecutor():一个任务一个任务执行,一池一线程
Executors.newCachedThreadPool():线程池根据需求创建线程,可扩容,遇强则强演示线程池三种常用分类(模拟银行办理业务):
public class MyThreadPoolDemo { public static void main(String[] args) { ExecutorService threadPool = Executors.newFixedThreadPool(5); //一池5个处理线程 // ExecutorService threadPool = Executors.newSingleThreadExecutor();//一池1个处理线程 // ExecutorService threadPool = Executors.newCachedThreadPool(); //一池N个处理线程 try { //10个客户请求 for (int i = 0; i < 10; i++) { threadPool.execute(() -> { System.out.println(Thread.currentThread().getName() + "\t 办理业务"); }); } }catch (Exception e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
newFixedThreadPool运行结果

newSingleThreadExecutor运行结果
newCachedThreadPool运行结果

自己搜集的一些资料:- newFixedThreadPool:
固定线程数的线程池。corePoolSize = maximumPoolSize,keepAliveTime为0,即使线程是空闲状态也不会被回收,工作队列使用无界的LinkedBlockingQueue。适用于为了满足资源管理的需求,而需要限制当前线程数量的场景,适用于负载比较重的服务器。由于该线程池线程数固定,且不被回收,线程与线程池的生命周期同步,所以适用于任务量比较固定但耗时长的任务 - newSingleThreadExecutor:只有
一个线程的线程池。corePoolSize = maximumPoolSize = 1,keepAliveTime为0, 工作队列使用无界的LinkedBlockingQueue。适用于需要保证顺序的执行各个任务的场景。
和new FixedThreadPool(1)有什么区别呢? 根据官方注释上说,两者的区别是:后者可以重新构造核心线程的数量,但是前者不行。意思就是FixedThreadPool构造完成后可以设置核心线程的数量,但是singleThreadExecutor不行
- newCachedThreadPool: 按需要创建新线程的线程池。
核心线程数为0,最大线程数为Integer.MAX_VALUE,keepAliveTime为60秒,工作队列使用同步移交 SynchronousQueue。SynchronousQueue,这个队列是无法插入任务的,一有任务立即执行。该线程池可以无限扩展,当需求增加时,可以添加新的线程,而当需求降低时会自动回收空闲线程。适用于执行很多的短期异步任务,或者是负载较轻的服务器。适合双十二提交订单 - newScheduledThreadPool:创建一个以延迟或定时的方式来执行任务的线程池,工作队列为DelayedWorkQueue,是个无界的队列,延时执行队列任务,或者每隔一段时间执行一个任务。
适用于需要多个后台线程执行周期的重复任务。
2.线程池的底层逻辑
查看上面三个创建线程池的源码可以发现都是创建了ThreadPoolExecutor对象
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
其中ThreadPoolExecu的构造方法如下,会发现有七个参数,下面章节将会对这七个参数的含义进行详细的讲解。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
三、七个参数介绍
1、corePoolSize(核心线程数):线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,他们也不会被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。
2、maximumPoolSize(最大线程数):一个任务被提交到线程池以后,首先会找有没有空闲存活线程,如果有则直接将任务交给这个空闲线程来执行,如果没有则会缓存到工作队列(后面会介绍)中,如果工作队列满了,才会创建一个新线程,然后从工作队列的头部取出一个任务交由新线程来处理,而将刚提交的任务放入工作队列尾部。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize指定。
如何设置核心线程数
CPU密集型(该任务需要大量的计算,大量if else):CPU核数+1
IO密集型(大量数据库查询等):- C P U 核数 ∗ 2 CPU核数 * 2 CPU核数∗2 (由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程)
- C P U 核数 / 1 − 阻塞系数 CPU核数 /1 - 阻塞系数 CPU核数/1−阻塞系数 阻塞系数在0.8~0.9之间(大量的io,即大量的阻塞线程)
活跃时间(时间和单位):
3、keepAliveTime(空闲线程存活时间):一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定。
4、unit (空闲线程存活单位):keepAliveTime的计量单位5、workQueue 阻塞队列:被提交但尚未被执行的任务,上一篇阻塞队列 有讲
- ① ArrayBlockingQueue: 基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
- ② LinkedBlockingQuene: 基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
- ③ SynchronousQuene: 一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
- ④ PriorityBlockingQueue: 具有优先级的无界阻塞队列,基于最小二插堆。优先级通过参数Comparator实现。
- ⑤ DelayQueue:一个使用优先级队列实现的无界阻塞队列;
- ⑥ LinkedTransferQueue:一个由链表结构组成的无界阻塞队列;
- ⑦ LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
6、threadFactory 线程工厂:创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等
7、handler 拒绝策略:
AbortPolicy:直接丢弃任务,抛出RejectedExcutionException异常,这是默认的策略DiscardPolicy:直接丢弃新任务,也不抛出异常。CallerRunPolicy:用调用者所在的线程处理任务,也就是说,放下手中的活帮我处理掉的意思。该策略不会抛弃任务,也不会抛出异常。而是将某些任务回退到调用者,从而降低新任务的流量。DiscardOldestPolicy:丢弃队列中等待最旧的任务,然后把当前任务加入队列中尝试再次提交当前任务。
四、线程池工作流程
注意:当执行了ExecutorService的 execute() 方法,才开始创建线程。
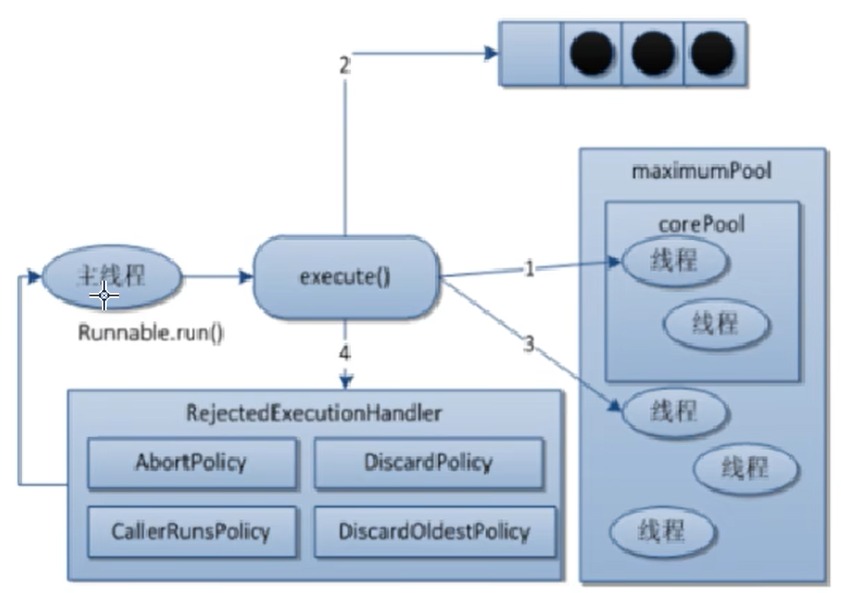
当一个任务提交到线程时,执行流程为:- 在创建了线程池后,等待提交过来的任务请求。
- 当调用 execute() 方法添加一个请求任务时,就会做出如下判断:
- 如果正在运行的线程数量小于corePoolSize,那么马上创建线程执行这个任务。
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入阻塞队列中;
- 如果这时候队列满了且正在运行的线程数量小于maxmumPoolSize,那么还是要创建非核心线程去立刻执行这个任务;
- 如果这时候队列满了且正在运行的线程数量大于或等于maxmumPoolSize,那么线程池就会启动执行饱和拒绝策略来执行。
- 当一个线程完成任务时,它会从阻塞队列中取出一个任务来执行。
- 当一个线程空闲时间超过keepAliveTime时,线程池会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
五、自定义线程池
上述创建线程池的方法很方便,但是在实际生产中还是尽量不要去使用,阿里巴巴开发手册中也有相关规定不允许使用Executors的方式创建线程池:

自定义线程池创建实例public class MyThreadPoolDemo { public static void main(String[] args) { ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 2, 5, 1L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy() ); //处理10个顾客请求 try { for (int i = 0; i < 100; i++) { threadPool.execute(() -> { System.out.println(Thread.currentThread().getName() + "\t 办理业务"); }); } }catch (Exception e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
运行结果如下,可以发现当超过最大线程后,在提交任务就会抛出异常:

-
相关阅读:
Bash sleep随机时间
Vue和Element UI 路由跳转,侧边导航的路由跳转,侧边栏拖拽
maven的使用方式(三)——Maven
2022-6学习笔记
锅总浅析Prometheus 设计
vue项目根据不同环境进行设置打包命令
力扣-1984. 学生分数的最小差值
发布 rust 源码包 (crates.io)
测试概念第三篇—注册登陆测试用例
Java String.valueOf()方法具有什么功能呢?
- 原文地址:https://blog.csdn.net/qq2632246528/article/details/127417068
