-
A Frustratingly Easy Approach for Entity and Relation Extraction 论文阅读
一、概述
论文:https://paperswithcode.com/paper/a-frustratingly-easy-approach-for-joint
解读:https://mp.weixin.qq.com/s/xwljKL3FjY-Nw-Zll4x3pQ
原版本代码:https://github.com/princeton-nlp/PURE
中文版本代码:https://github.com/suolyer/PyTorch_BERT_Pipeline_IE
二、QA
问题一:关系抽取到低怎么利用实体的位置信息的?

主要的思想就是引入实体位置+实体类别来做pipeline的关系分类,因为这两个信息在关系分类里面是非常重要的。
问题二:实体识别里面x_start和x_end是什么意思?
答:可能引入了起始的位置(start,end)信息,并且有利用span的表征的信息来做实体识别。
三、消融实验
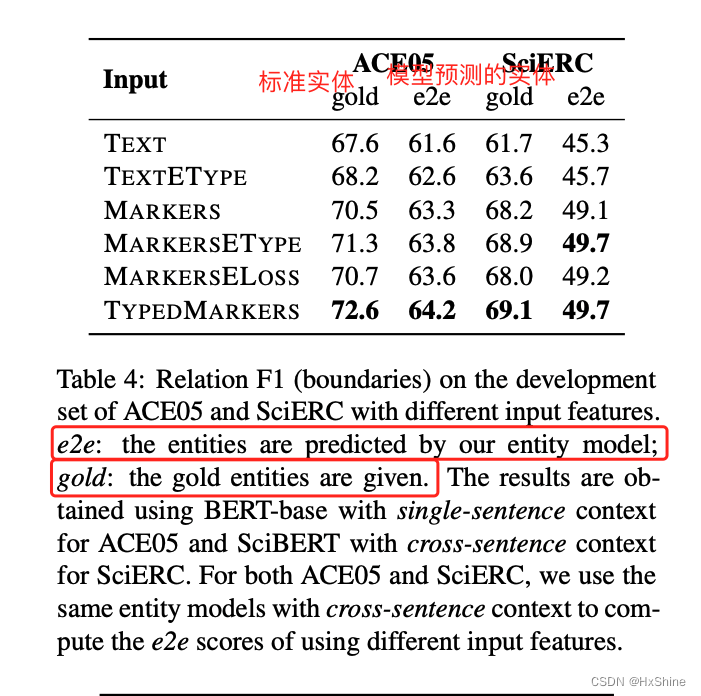
3.1 不同引入实体位置和类型的方法比较:直接通过mark引入类别和位置信息比在loss测引入信息效果更好。
TEXT纯文本:我们使用实体模型(第3.2节)中定义的跨度表示,并将主语和对象的隐藏表示及其元素乘法相连:[he(si),he(sj),he(si) ⊙ he(sj)]。这与Luan等人的关系模型相似。(2018年,2019年)。
TEXTETYPE:我们将TEXT的跨对re-发送与实体类型嵌入ψ(ei),ψ(ej) ∈ RdE (dE = 150)连接起来。
MARKERS标记:我们在输入层使用未键入的实体类型(,,,),并将两个跨度起点的表示连接起来。
MARKERSETYPE:我们将标记的跨对表示与实体类型嵌入ψ(ei), ψ(ej ) ∈ RdE (dE = 150) 连接起来。
MARKERSELOSS:我们还考虑使用未键入标记的变体,但添加另一个FFNN通过辅助损失来预测主体和对象的实体类型。这与实体信息在多任务学习中的使用方式相似(Luan等人,2019年;Wadden等人,2019年)。
类型标记:这是我们在第3.2节中用类型实体标记取消描述的最终模型。● 结论:
○ 通过引入typeMarkers来引入类别和位置信息,这种效果最好
○ 利用标准gold实体来训练关系模型,效果最好3.2 共享encoder并不能带来提升:可能两个任务所侧重的特征各有不同
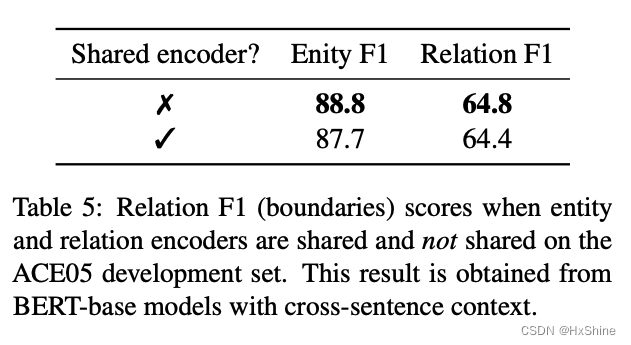
3.3 关系预测的实体用gold还是用pred的结果?发现直接用gold反而效果最好,可能是pred质量不好会影响效果,例如没有预测出实体,导致没有关系模型的数据或者引入了额外的噪声。

● 结论:
○ 10层交叉验证,拿到实体模型结果,效果也比gold差
○ 尝试利用更多的实体对?感觉像是采样更多实体对来做关系预测,然后效果也没有什么提升。3.4 上下文交叉句子特征的影响?发现window size也对实体或者关系的结果有影响。

实体模型:w=300
关系模型:w=100
效果最好 -
相关阅读:
qt学习总结之探索Qt的安装目录结构
C语言中的类型转换
11.10 - 每日一题 - 408
【MyBatis笔记07】MyBatis中的批量操作(批量新增、批量删除、批量更新)
Ubuntu18.04版本下配置ORB-SLAM3和数据集测试方法
springboot-集成flink最佳实践和打包部署
mysql学习之mysql集群
函数探秘:深入理解C语言函数,实现高效模块化编程
vue3 iconify 图标几种使用 并加载本地 svg 图标
网线Cable
- 原文地址:https://blog.csdn.net/qq_16949707/article/details/127092591