-
2022年笔试知识总结展望(前后端均有)
博主自己在平时遇到有用知识进行的总结归纳,随缘温故而知新,看看知识加深印象,希望学得更好,有个好结果。大伙可以先看一下目录自己进行一个回答,再往下看我总结出来的答案,希望对你有帮助~~
目录
2. 排序算法的平均时间复杂度、最坏时间复杂度、空间复杂度、稳定性比较
1.如何避免在产品开发后期不断有重大修改,导致其它模块的连锁反应?
2. [‘1‘, ‘2‘, ‘3‘].map(parseInt) 输出结果
3. display: none、visibility: hidden与opacity:0的区别
算法语言知识
1. 八种排序算法的稳定性分析
排序算法的稳定性通俗地讲就是能
保证排序前两个相等的数据其在序列中的先后位置顺序与排序后它们两个先后位置顺序相同。1)稳定的排序算法:冒泡排序、插入排序、归并排序、基数排序;
- 冒泡排序:将相邻的两个元素进行比较(小的往前调,大的往后调,相等不调);
- 插入排序:讲一个元素插入到一个已经有序的小序列上,从后往前不断对比找位置;
- 归并排序:把数列递归分成短序列,然后进行合并;
- 基数排序:按照低位先排序,然后收集;在按照高位排序,再收集,
2)不稳定的排序算法:选择排序、快速排序、希尔排序、堆排序;
- 选择排序:选择排序即给每个位置选择 待排序元素 中最小的元素;

- 快速排序:
- 先选一个key,然后左右指针不断的往中间找到交换的值,再在左右序列进行相同快排,不稳定在交换的值和可以交换的时刻;

快排左右指针法 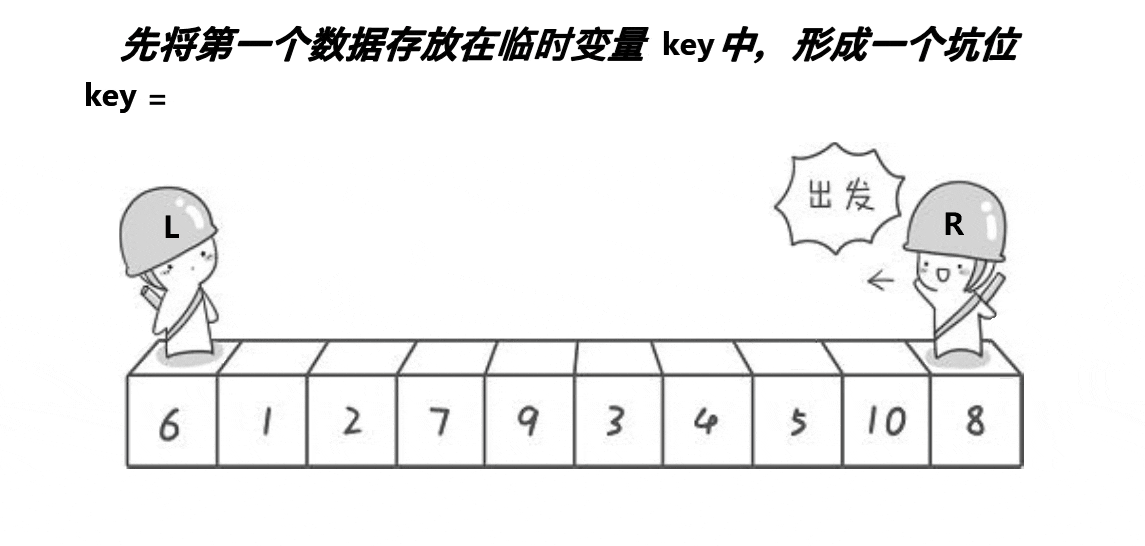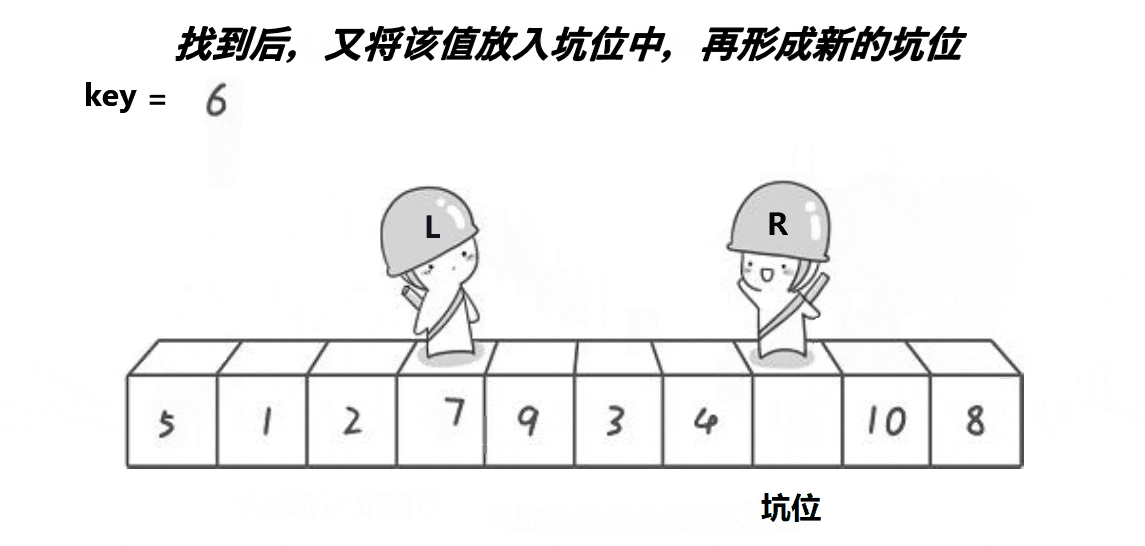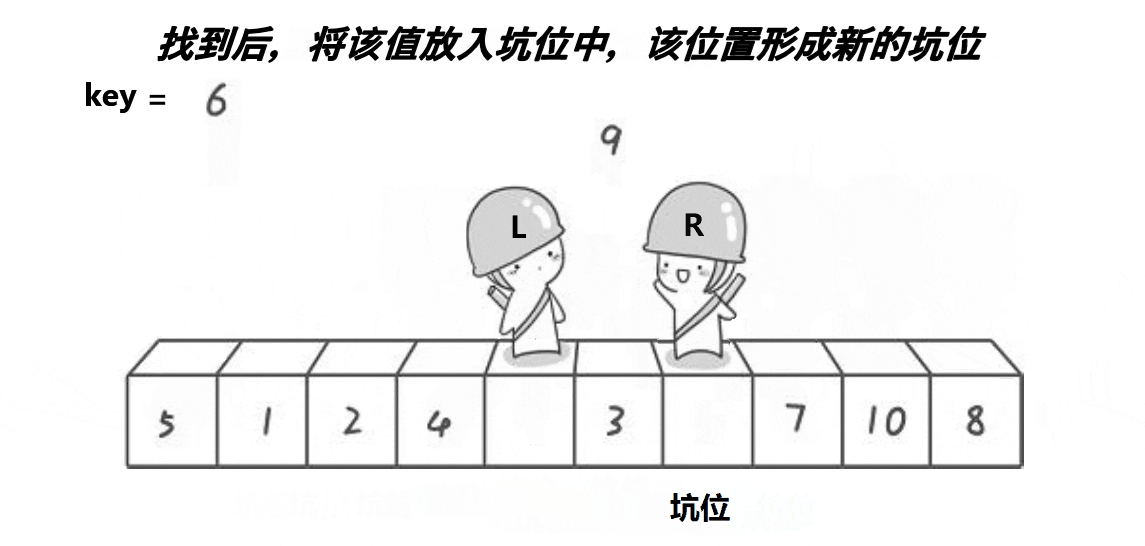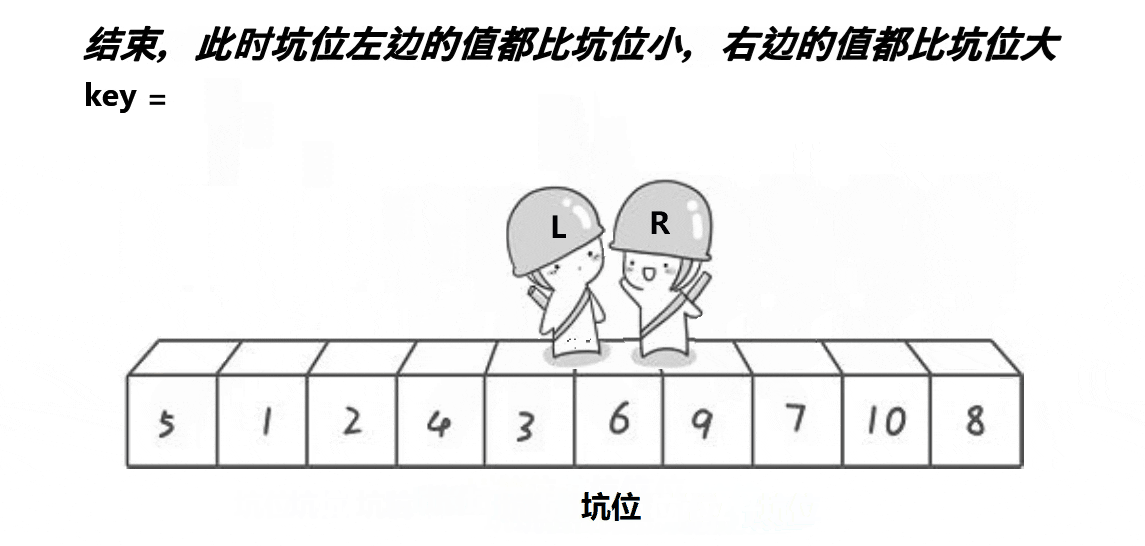
快排递归挖坑法 - 希尔排序:希尔排序是按照不同步长对元素进行插入排序的;

- 堆排序
- 为什么要区分排序算法的稳定性?
- 排序算法的稳定性概念:通俗地讲就是能保证排序前两个相等的数据在其序列中的先后位置顺序与排序后他们两个的先后顺序相同;
- 如果排序算法是稳定的,那么从上一个键上排序,然后从另一个键上排序,第一个键排序的结果可以为第二个键排序所利用;
- 在多个属性的数组中,有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序,最后的次序结果就是高优先级高的在前,高优先级相同的情况下低优先级高的在前。
2. 排序算法的平均时间复杂度、最坏时间复杂度、空间复杂度、稳定性比较
平均时间复杂度 最坏时间复杂度 空间复杂度 稳定性 冒泡排序 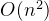

是 插入排序 是 选择排序 否 归并排序 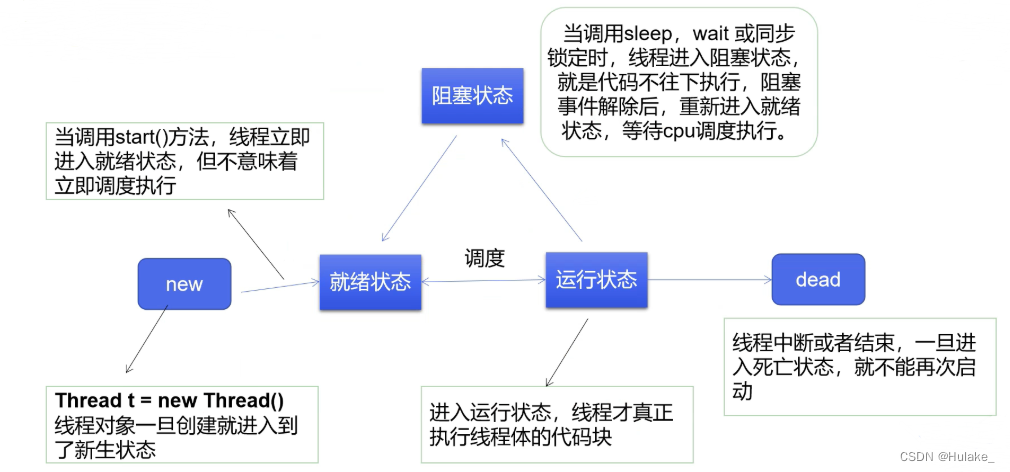
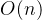
是 快速排序 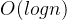
否 堆排序 否 希尔排序 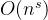
否 基数排序 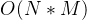
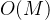
是 注:
- 归并排序可以通过手摇算法将空间复杂度降到,但是时间复杂度会提高。
- 基数排序时间复杂度为,其中N为数据个数,M为数据位数。
辅助记忆
- 时间复杂度记忆-
- 冒泡、选择、直接 排序需要两个for循环,每次只关注一个元素,平均时间复杂度为(一遍找元素,一遍找位置)
- 快速、归并、希尔、堆基于二分思想,log以2为底,平均时间复杂度为(一遍找元素,一遍找位置)
- 稳定性记忆-“快希选堆”(快牺牲稳定性)
- 排序算法的稳定性:排序前后相同元素的相对位置不变,则称排序算法是稳定的;否则排序算法是不稳定的。
3. std::map的使用
详细参考资料:std::map的基本使用
- std::map 是有序键值对容器,它的元素的键是唯一的;
- 用比较函数Compare排序键;
- 搜索、移除和插入操作拥有对数复杂度。;
- map 通常实现为红黑树;
- 思想: map映照容器运用了哈希表地址映射的思想,也就是key-value的思想,每一个key对应着一个值,每个key是唯一的,底层采用红黑树的数据结构实现;
- 特点:增加和删除节点对迭代器的影响很小,出来那个操作节点,对其他的节点都没有什么影响。对于迭代器来说,可以修改实值,而不能修改key;
- map会根据key自动排序,建立Key-value(键值对)的对应。key和value可以使任意你需要的类型。
- 根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录、快速删除记录、根据Key修改value记录,遍历所有记录;
std::map满足容器(Container)、具分配容器(AllocatorAwareContainer)、关联容器(AssociativeContainer)和可逆容器(ReversibleContainer)的要求。
4. 二叉树中度为0的结点数与度为2的结点数关系论证
叶子结点:一棵树当中没有子结点(即度为0)的结点,称为叶子结点,简称“叶子”。 叶子是指度为0的结点,又称为终端结点。
由二叉树的性质可知,度为0的结点数比度为2的结点数多1,即n0=n2+1,下面论证这一关系:
假如二叉树度为0的结点数为n0,度为1的节点总数为n1,度为2的节点总数为n2,那么二叉树总结点数n满足以下关系:n = n0 + n1 + n2 ①
另一方面,除根节点以外的所有节点总数,即 :n - 1 = n1 + 2n2 ②
综合两式,①-②得:1= n0- n2,即n0=n2+1
5. 树的基本概念
1)树的定义
- 空树:节点数为0的树;
- 叶子结点:没有后继的节点;
- 分支节点:有后继的节点;
- 任何节点有且仅有一个前驱;
2)基本术语
- 结点的层次(深度):从上往下,根节点为第一层,子结点为第二层,依次向下递推;
- 结点的高度:从下往上;
- 树的高度:总共多少层;
- 结点的度:有几个孩子;
- 树的度:各结点的度的最大值;
6. 串的模式匹配算法
在实际应用中我们常常能用到类似串的模式匹配,也称子串的定位操作。例如单词查找,百度搜索都是串的模式匹配操作。
字符串模式匹配: 在主串中找到与模式串相同的⼦串,并返回其所在位置。
- 子串——主串的⼀部分,⼀定存在;
- 模式串——不⼀定能在主串中找到。
7. Java线程的五种状态
参考文章:线程的状态
线程有5种状态:新建(new Thread)、就绪(runnable),运行(running)、阻塞(blocked)、结束(dead)
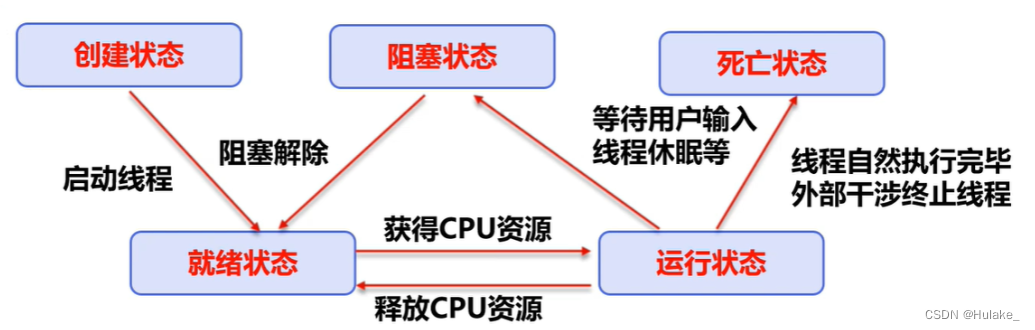
1)主要方法:
- setPriority:更改优先级
- sleep(休眠):休眠多少毫秒;每个对象都有一把锁,sleep不会释放锁
- join(加入):插队,当有新的线程加入时,主线程会进入等待状态,一直到调用join()方法的线程执行结束为止。
- yield(礼让):线程A抢到CPU了,线程B在外面等待,这是线程A调用yield()方法,就会退出来和线程B一起再抢一次。(注:yield()方法只是提出申请释放CPU资源,至于能否成功释放由JVM决定。由于这个特性,一般编程中用不到此方法,但在很多并发工具包中,yield()方法被使用,如AQS、ConcurrentHashMap、FutureTask等。)
- isAlive:测试线程是否处于活动状态
2)yield()方法和sleep()方法有什么区别
yield()方法调用后线程处于RUNNABLE(就绪)状态,而sleep()方法调用后线程处于TIME_WAITING(等待)状态,所以yield()方法调用后线程只是暂时的将调度权让给别人,但立刻可以回到竞争线程锁的状态;而sleep()方法调用后线程处于阻塞状态。
3)sleep()和wait()方法有什么区别:
sleep()睡眠时,保持对象锁,仍然占有该锁;
而wait()睡眠时,释放对象锁。
但是wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态,从而使线程立刻抛出InterruptedException(但不建议使用该方法)。4)线程的特点:
- 一个线程是一个任务(一个程序段)的一次执行过程。
- 线程不占有内存空间,它包括在进程的内存空间中。
- 线程比进程开销小,更加轻量。
- 在同一进程内,多个线程可以并发执行。
- 在同一进程内,多个线程共享进程的资源。
数据库知识
1.mysql 索引失效的7种情况
- 有or必全有索引:如果条件中有or,即使其中有部分条件带索引也不会使用(这也是为什么尽量少用or的原因),如果要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引;
- 复合索引未用左列字段:对于复合索引,如果不使用前列,后续列也将无法使用;
- like查询是以%开头;
- 需要类型转换:存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引;
- where中索引列有运算:where 子句里对索引列上有数学运算,用不上索引;
- where中索引列使用了函数:where 子句里对有索引列使用函数,用不上索引;
- 如果mysql觉得全表扫描更快时:如果mysql估计使用全表扫描要比使用索引快,则不使用索引(比如数据量极少的表);
2.不推荐使用索引的4种情况
- 唯一性差:比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描;
- 频繁更新的字段不用(更新索引消耗):比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描;
- where中不用的字段:字段不在where语句出现时不要添加索引,如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引;
- 索引使用<>时,效果一般;
软件工程知识
1.如何避免在产品开发后期不断有重大修改,导致其它模块的连锁反应?
这个问题是一定要尽量避免的,如果后期出现需要重大修改的情况,肯定是因为早期的需求分析以及设计部分就出了问题,然后会导致程序出现不兼容或功能冲突的连锁反应。所以在早期进行设计文档的时候一定要进行多次审查复核,确保逻辑功能可以正常实现后才进行代码层次的开发。
但如果后期真的很不幸出现了重大修改,我们就只好进行代码重构,尽量对代码进行优化整理,争取降低连锁反应带来的影响。
操作系统、计网知识:
1. TCP的拥塞控制
参考文章:TCP的拥塞控制(详解)
网络拥塞:在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫做网络拥塞。
TCP的四种拥塞控制算法
- 慢开始
- 拥塞控制
- 快重传
- 快恢复
2. 磁盘高速缓存(Disk Cache)
- 操作系统中使用磁盘高速缓存技术来提高磁盘的IO速度,对高速缓存复制的访问要比原始数据访问更高效。例如正在运行的进程的指令即存储在磁盘上,也存储在物理内存上,也被复制到CPU的二级和一级高速缓存中。
- 不过磁盘高速缓存技术不同于通常意义下的介于CPU与内存之间的小容量高速存储器,而是利用内存的存储空间来暂存从磁盘读出的一些了盘块中的信息。因此,磁盘高速缓存在逻辑上属于磁盘,在物理上则是驻留在内存中的盘块。
- 高速缓存在内存中分为两种形式:
- 一种是在内存中开辟一个单独的存储空间作为磁盘高速缓存,大小固定;
- 另一种是把未利用的内存空间作为缓冲池,共请求分页系统和磁盘IO时共享。
3. 缓冲区(Buffer)
1)在设备管理子系统中,引入缓冲区的目的主要有:
- 缓和CPU与IO设备间速度不匹配的矛盾
- 减少对CPU的中断频率,放款对CPU中断响应时间的限制
- 解决基本单元数据大小不匹配的问题
- 提高CPU和IO设备之间的并行性
2)实现方法有:
- 采用硬件缓存器,但由于成本太高,除一些关键部位外,一般不采用硬件缓冲器;
- 采用缓冲区(位于内存区域)。
3)特点
- 当缓冲区的数据非空时,不能往缓冲区冲入数据,只能把缓冲区数据传出;
- 当缓冲区数据为空时,可以往缓冲区冲入数据,但必须把缓冲区充满以后,才能从缓冲区中把数据传出。
4. 热点Key问题
参考文章:Redis——热点key问题
热点key问题就是某个瞬间有大量的请求去访问Redis上某个固定的key,导致缓存击穿,请求都打到了DB上,压垮了缓存服务和DB服务,从而影响到应用服务可用的可用性;
1)什么样的key被称为热key
通常以Key被请求频率来判定,目前没有很具体的数值来定义热key,但是下面的示例可以做一个参照,如:
- QPS集中在特定的Key:Redis实例的总QPS(每秒查询率)为2W,而其中一个Key的每秒访问量达到了1W以上;
- 带宽使用率集中在特定的Key:对一个拥有上千个成员且总大小为1MB以上的HASH Key,每秒发送大量的HGETALL操作请求;
- CPU使用时间占比集中在特定的Key:对一个拥有数万个成员的Key(ZSET类型)每秒发送大量的ZRANGE操作请求;
2)热点Key问题的危害
- 流量集中,达到物理网卡上限;
- 请求过多,缓存分片服务被打垮;
- 集群架构下,产生访问倾斜;
- DB 击穿,引起业务雪崩;
3)热点Key的解决方案
- 使用二级缓存;
- 将热key分散到不同的服务器中;
- 热key拆分;
- 将核心/非核心业务做Redis的隔离;
5. HTTP状态码总结
参考文章:HTTP状态码
- 1XX:信息提示
这类状态代码表示临时的响应。客户端在收到常规响应之前,应准备接受一个或者多个1XX响应;
- 2XX:成功
这类状态代码表明服务器成功地接受了客户端请求;
- 3XX:重定向
客户端浏览器必须采取更多操作来实现请求。例如,浏览器可能不得不请求服务器上的不同页面,或通过代理服务器重复该请求;
- 4XX:客户端错误
发生错误,客户端似乎有问题。例如,客户端请求不存在的页面,客户端未提供有效的身份验证信息;
- 400:错误请求;
- 401:访问被拒绝;
- 403:服务器拒绝请求,可以理解为没有权限访问此网站,服务器能够收到请求但拒绝提供服务;
- 404:服务器找不到请求的网页。例如,访问网站中不存在的页面,或者原有页面被移走或删除,则可能会出现改状态码;
- 5XX:服务器错误
服务器由于遇到错误而不能完成该请求;
6. 常见路由协议以及路由算法
参考文章:常见路由协议以及路由算法
1)路由协议
- RIP(Route Information Protocol):路由信息协议,主要传递路由信息,通过每隔30秒广播一次路由表,维护相邻路由器的位置关系,同时根据收到的路由表信息计算自己的路由表信 息。
- OSPF(Open Shortest Path First):开放式最短路径优先协议,属于链路状态路由协议。OSPF提出了“区域(area)”的概念,每个区域中所有路由器维护着一个相同的链路状态数据库 (LSDB)。
- IS-IS(Intermediate system to intermediate system):中间系统到中间系统协议,属于链路状态路由协议。标准IS-IS协议是由国际标准化组织制定的ISO/IEC 10589:2002 所定义的,标准IS-IS不适合用于IP网络,因此IETF制 定了适用于IP网络的集成化IS-IS协议(Integrated IS-IS)。
- IGRP(Interior Gateway Routing Protool):内部网关路由协议,IGRP和RIP一样,同属距离矢量路由协议。IGRP最大的特点是使用了混合度量值,同时考虑了链路的带宽、 延迟、负载、MTU、可靠性5个方面来计算路由的度量值,而不像其他IGP协议单纯的考虑某一个方面来计算度量值。
- BGPB(order Gateway Protocol):边界网关协议,处理各ISP之间的路由传递。但是BGP运行在相对核心的地位,需要用户对网络的结构有相当的了解,否则可能会造成较大损失。为了维护各个ISP的独立利益,标准化组织制定了ISP间的路由协议BGP。
2)路由算法
- 总体式路由算法:每个路由器都拥有网络中其他路由器的全部信息,以及网络的流量状态。也叫LS (链路状态)算法。
- 分散式路由算法:每个路由器只有与它直接相连的路由器的信息,没有网络中每个路由器的信息。也叫DV (距离向量)算法。
7. TCP/IP 网络
TCP/IP 网络通常是由上到下分成 4 层,分别是应用层,传输层,网络层和网络接口层。
给大家贴一下每一层的封装格式:
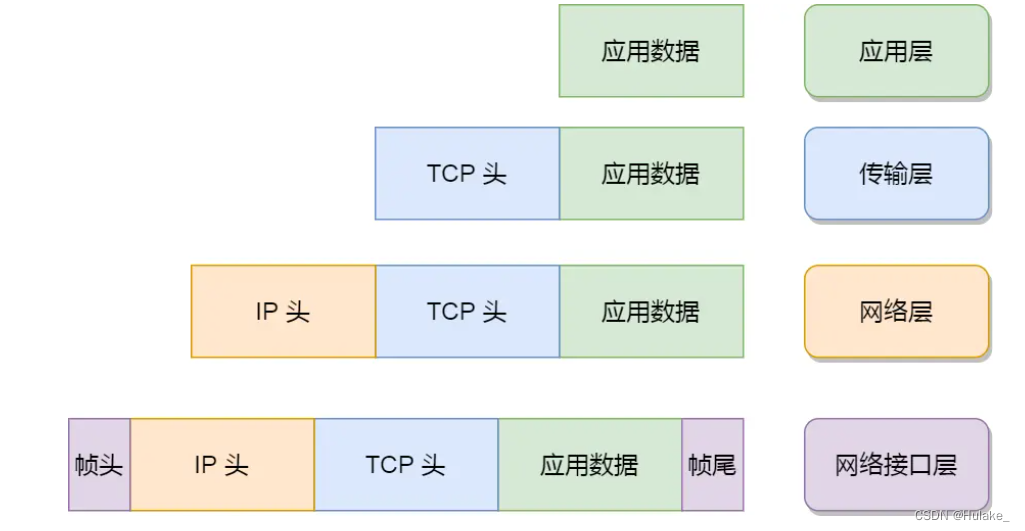
网络接口层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)。但这些名词并没有什么本质的区分,可以统称为数据包。
前端知识
1. position属性
- 定位属性
- static:默认值,默认定位方式;
- relative:相对定位;
- 可以配合着偏移属性进行位置的移动;
- 相对定位后元素会相对它原来的位置偏移某个位置;
- 元素移动位置后,原来所占据的空间依然保留;
- absolute:绝对定位;
- 可以配合着偏移属性实现位置的初始化或移动;
- 元素会脱离文档流;
- 相对于最近的,已定位的祖先元素,来实现位置的初始化;
- 如果元素没有已定位祖先元素,那么它的位置就相对于最初的包含块(body,html);
- 绝对定位的元素会变成块级;
- 绝对定位的元素
- fixed:固定定位;
- 将元素固定在网页的某个位置;
- 不会随着滚动条而发生位置的变化;
- 固定定位永远都是相对于浏览器窗口进行的位置初始化;
注意:position取值relative,absolute,fixed的元素被称为已定位元素;
- 偏移属性
作用:移动移动已定位元素;(top、bottom、left、right)
- 堆叠顺序 z-index
- 作用:处理已定位元素的堆叠效果;
- 默认堆叠效果:
- 平级元素——后来者居上;
- 子元素压在父元素之上——子压父;
- 注意:
- z-index必须配合position属性使用;
- z-index的取值数值越大就越靠上;
- 取值可以为负,取值为负时,当前元素会位于页面正常显示内容之下;
- z-index是无法改变父子关系的堆叠顺序;
2. [‘1‘, ‘2‘, ‘3‘].map(parseInt) 输出结果
输出结果:[1, NaN, NaN]
解析:
- 我们先看parseInt(string,radix)函数:
- string:要被解析的值。
- 如果参数不是一个字符串,则将其转换为字符串(toString)。字符串开头的空白符将会被忽略。
- radix:可选。
- 从 2 到 36,表示被解析的值的进制。例如说指定 10 就等于指定十进位。
- parseInt(string, radix)将一个字符串string转换为radix进制的整数, radix为介于2-36之间的数,返回解析后的整数值,如果被解析参数的第一个字符无法被转化成数值类型,则返回NaN。
- 注意一点的是,radix是undefined、0或未指定时,JS会假定radix的值:
- String以0X/0x开头时,则radix为16,即16进制;
- String以0开头时,radix则可能是8(八进制)或者10(十进制),看具体情况,一般是十进制;
- String以任何其他值开头,radix是10(十进制);
- Array.prototype.map(callback, ):
map方法的作用,该方法接受两个参数:
- 第一个是一个回调函数,数组中的每一项都会执行该函数,这个回调函数接受三个参数,第一个是正在处理的元素,第二个是正在处理的索引,第三个是当前数组;
- 第二个参数是调用回调函数的this。(当前元素属于的数组对象)
- 回到问题:['1', '2', '3'].map(parseInt):
- 相当于遍历执行parseInt(‘数组元素’,‘索引’);
- parseInt('1', 0),直接按照10进制解析,结果为1;
- parseInt('2', 1),传入了非2~36的值,结果为NaN;
- parseInt('3', 2),按照2进制进行解析,2进制可以解析的数字只有1和0,所以返回NaN。
3. display: none、visibility: hidden与opacity:0的区别
相同点:都能让元素不可见;
不同点:
- display: none
-
DOM 结构:浏览器不会渲染 display 属性为 none 的元素,会让元素完全从渲染树中消失,渲染的时候不占据任何空间;
-
事件监听:无法进行 DOM 事件监听,不能点击;
-
性能:修改元素会造成文档回流(reflow 与 repaint),读屏器不会读取display: none元素内容,性能消耗较大;
-
继承:是非继承属性,由于元素从渲染树消失,造成子孙节点消失,即使修改子孙节点属性子孙节点也无法显示,毕竟子类也不会被渲染;
-
场景:显示出原来这里不存在的结构;
-
transition:transition 不支持 display。
- visibility: hidden
-
DOM 结构:不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见;
-
事件监听:无法进行 DOM 事件监听,不能点击;
-
性能:修改元素只会造成本元素的重绘(repaint),是重回操作,比回流操作性能高一些,性能消耗较少;读屏器读取visibility: hidden元素内容;
-
继承:是继承属性,子孙节点消失是由于继承了visibility: hidden,子元素可以通过设置 visibility: visible 来取消隐藏;
-
场景:显示不会导致页面结构发生变动,不会撑开;
-
transition:transition 支持 visibility,visibility 会立即显示,隐藏时会延时。
- opacity: 0
- DOM 结构:透明度为 100%,不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见;
-
事件监听:可以进行 DOM 事件监听,可以点击;
-
性能:提升为合成层,是重建图层,不和动画属性一起则不会产生repaint(不脱离文档流,不会触发重绘),性能消耗较少;
-
继承:会被子元素继承,且子元素并不能通过 opacity: 1 来取消隐藏;
-
场景:可以跟transition搭配;
-
transition:transition 支持 opacity,opacity 可以延时显示和隐藏。
具体效果分析:
-
display: none: 从这个世界消失了, 不存在了;
-
opacity: 0: 视觉上隐身了, 看不见, 可以触摸得到;
-
visibility: hidden: 视觉和物理上都隐身了, 看不见也摸不到, 但是存在的;
4. 搞懂箭头函数,说说它的特点?
详解原文:这一次,彻底搞懂箭头函数
- 相比普通函数,箭头函数有更简洁的语法;
- 箭头函数不绑定this,会捕获其所在上下文的this,作为自己的this;
- 箭头函数式匿名函数,不能作为构造函数,不可以使用new命令,否则抛出错误;
- 箭头函数不绑定arguments,取而代之用rest参数解决,同时没有super和new.target,这些值由外围的非箭头函数决定;
- 箭头函数可以通过拓展运算符获取传入的参数;
- 使用call,apply,bind并不会改变箭头函数中的this指向;
- 箭头函数没有原型对象prototype这个属性,输出undefined;
- 不能使用yield关键字,不能用作Generator函数;
5. arguments是什么?
arguments对象是所有非箭头函数都可用的局部变量,可以使用arguments对象在函数中引用函数的参数,此对象包含传递给函数的每一个参数,第一个参数在索引0的位置;
- 如何将arguments对象转换成数组?
- 通过slice;
- 通过Array.from;
- 通过拓展运算符;
- var args = Array.prototype.slice.call(arguments);
- var args = [].slice.call(arguments);
- const args = Array.from(arguments);
- const args = [...arguments];
- arguments想要调用自身的匿名函数,可以通过arguments.callee来调用;
6. JavaScript中的伪数组与真数组
1)伪数组的创建
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Documenttitle>
- head>
- <body>
- <ul id = 'ul'>
- <li>li>
- <li>li>
- <li>li>
- <li>li>
- ul>
- body>
- <script>
- var liArr = document.getElementById('ul')
- console.dir(liArr.children)
- script>
- html>
上面创建出来的就是一个伪数组,长相很像数组,但打开原型_proto_看,它是没有数组的splice,concat,pop等方法的;

2)特点:
- 具有length属性;
- 能按索引方式存储数组;
- 不具有数组的方法;
3)伪数组转化为真数组:
- 可以用过call或者apply的方法,将伪数组转化为真数组;
- Array.prototype.slice.call(liArr.children)
- //或者
- Array.prototype.slice.apply(liArr.children)
- 此时已经改变了 this 指向,使得 liArr.children 拥有了真数组的原型方法
4)总结
- 伪数组没有数组
Array.prototype的属性值,类型是Object,而数组类型是Array; - 数组是基于索引的实现, length 会自动更新,而对象是键值对;
- 使用对象可以创建伪数组,伪数组可以利用
call或者apply很方便的转化为真数组;
7. CSS盒子模型
参考文章:CSS盒子模型详解
在使用CSS进行网页布局时,我们一定离不开的一个东西————
盒子模型。盒子模型,顾名思义,盒子就是用来装东西的,它装的东西就是HTML元素的内容。或者说,每一个可见的 HTML 元素都是一个盒子,下面所说的盒子都等同于 HTML 元素。这里盒子与 中的盒子又有点不同,这里的盒子是二维的。1)盒子的组成
一个盒子由外到内可以分成四个部分:
margin(外边距)、border(边框)、padding(内边距)、content(内容)。会发现margin、border、padding是CSS属性,因此可以通过这三个属性来控制盒子的这三个部分。
而content则是HTML元素的内容。
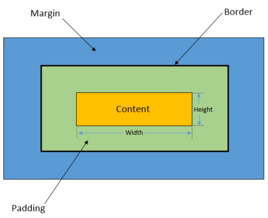
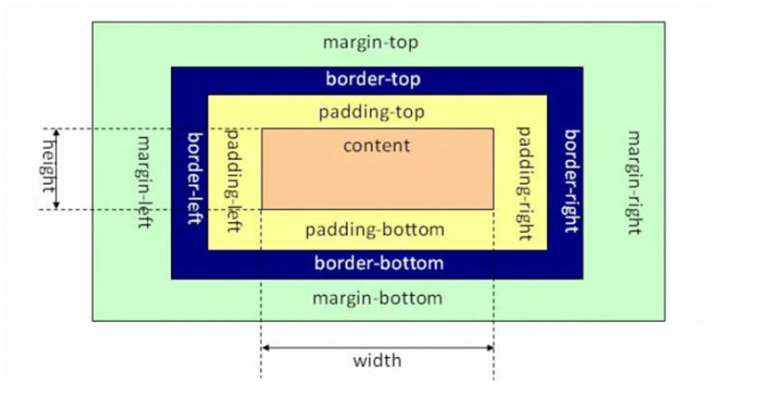
2)盒子的大小
盒子的大小指的是盒子的宽度和高度。大多数初学者容易将宽度和高度误解为width和height属性,然而默认情况下
width和height属性只是设置content(内容)部分的宽和高。盒子真正的宽和高按下面公式计算:- 盒子的宽度 = 内容宽度 + 左填充 + 右填充 + 左边框 + 右边框 + 左边距 + 右边距
- 盒子的高度 = 内容高度 + 上填充 + 下填充 + 上边框 + 下边框 + 上边距 + 下边距
或者看属性公式:
- 盒子的宽度 = width + padding-left + padding-right + border-left + border-right + margin-left + margin-right
- 盒子的高度 = height + padding-top + padding-bottom + border-top + border-bottom + margin-top + margin-bottom
8. Cookie和Session的理解应用
共同点:cookie和session都是用来跟踪浏览器用户身份的会话方式;
1)Cookie工作原理
- 浏览器第一次发送请求到服务端;
- 服务端创建Cookie,该Cookie中包含用户的信息,然后将该Cookie发送到浏览器端;
- 浏览器端再次访问服务器端时会携带服务器端创建的Cookie;
- 服务器端通过Cookie中携带的数据区分不同的用户;

2)Session的工作原理
- 浏览器端第一次发送请求到服务端,服务器端创建一个Session,同时会创建一个特殊的Cookie(name为JSESSIOMID的固定值,value为session对象的ID),然后将该Cookie发送至浏览器端;
- 浏览器端发送第N(N>1)次请求到服务器端,浏览器端访问服务器端时就会携带改name为JSESSIONID的cookie对象;
- 服务器端根据name为JSESIONID的Cookie的value(sessionId),去查询Session对象,从而区分不同用户;
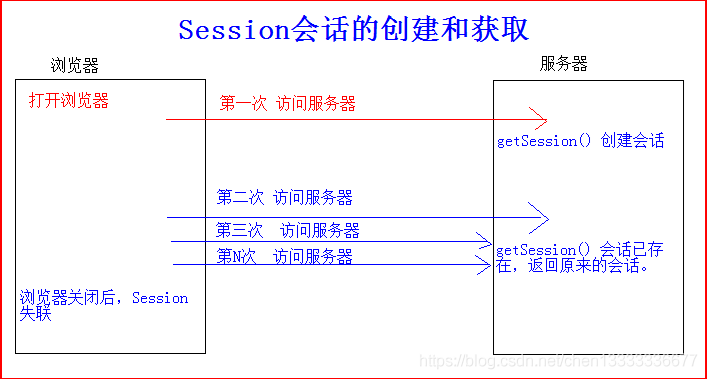
3)cookie和session的区别
cookie数据保存在客户端,session数据保存在服务端;
- session
当我们登录一个网站时,web服务器端使用的是session,那么所有的数据都会保存在服务器上,每次客户端向服务器发出请求时都会发送当前对话的sessionid,服务器会根据当前的sessionid判断相应的用户数据标志,以此来确定用户是否登录或者具有某种权限;
由于数据是存储在服务器上,我们在客户端是不能进行伪造的;
- cookie
cookie上也是有sessionid的,sessionid是服务器和客户端连接时随机分配的;
如果浏览器使用的是cookie,那么所有数据都保存在浏览器端,比如你登录以后,服务器会设置相应的cookie用户名,那么当你再次请求服务器时,浏览器会将用户名一块发送给服务器,这些变量有一定的特殊标记。服务器会解释为cookie变量,所以只要不关闭浏览器,那么cookie变量是一直有效的,所以能保证长时间不掉线。
- ccokie 的弊端
如果我们能够截获某个用户的cookie变量,然后伪造一个数据包发送过去,那么服务器还是认为你是合法的。所以,使用cookie被攻击的可能性比较大。
- 生命周期
两个都可以用来存私密的东西,session过期与否,取决于服务器的设定。cookie过期与否,可以在cookie生成的时候设置进去。
4)总结
- cookie数据存放在客户的浏览器上,session数据放在服务器上;
- 丛刻不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,如果主要考虑到安全,应当使用session;
- session会在一定时间内保存服务器上。但访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用cookie;
- 所以,将登录信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中;
-
相关阅读:
现在微软 SQL 服务器被黑,带宽遭到破坏
【LeetCode】309. 最佳买卖股票时机含冷冻期 动态规划 状态转移分析
认识C语言函数
【计算机网络笔记六】应用层(三)HTTP 的 Cookie、缓存控制、代理服务、短连接和长连接
手把手带你学SQL—牛客网SQL 别名
[第三篇]——CentOS Docker 安装
解析DNA甲基化临床科研 | 无论什么科室,一定要有project的经典视角|易基因
linux中crontab讲解
设计模式学习(十二):享元模式
resp协议
- 原文地址:https://blog.csdn.net/weixin_53919192/article/details/126910732