-
zookeeper的ZAB协议的原理以及底层源码实现超级详解
一,zookeeper的ZAB协议
1,ZAB概述
ZAB:zookeeper atomic broadcast(zookeeper原子广播协议)
ZAB协议主要包括这个 原子广播 和 崩溃恢复原子广播
就是说集群的主结点leader用来写,其他follow从结点只用来读。在主结点写完会将数据同步到从结点,只要写入成功的从结点的数量超过一半,那么这个数据就同步成功。这个主结点同步到从结点可能会有一定的延迟,因此这个zookeeper主要是为了保证这个数据的最终一致性,也可以叫为顺序一致性。崩溃恢复
如果在主结点刚把数据写完,这个主结点挂了,那么这个集群就会重新选举新的leader。选leader的规则就是先比较zxid事务id,再比较这个机器对应的myid,谁大谁被选为leader。二,ZAB协议流程的源码实现
需要下载zookeeper源码,可以参考上一篇:https://blog.csdn.net/zhenghuishengq/article/details/126673923?spm=1001.2014.3001.5502
1,客户端建立连接
1,先创建一个zookeeper对象
ZooKeeper zooKeeper=new ZooKeeper(...);- 1
这个zookeeper的构造方法可能如下,里面会有很多参数,里面主要是会对创建一个connection的连接。
public ZooKeeper( String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly, HostProvider hostProvider, ZKClientConfig clientConfig) throws IOException{ //增加一个监听机制 validateWatcher(watcher); this.clientConfig = clientConfig != null ? clientConfig : new ZKClientConfig(); ConnectStringParser connectStringParser = new ConnectStringParser(connectString); this.hostProvider = hostProvider; //建立一个ClientCnxn连接,会和这个服务端建立连接 cnxn = new ClientCnxn( connectStringParser.getChrootPath(), hostProvider, sessionTimeout, this.clientConfig, watcher, getClientCnxnSocket(), sessionId, sessionPasswd, canBeReadOnly); //开始连接 cnxn.start(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2,然后进入这个开始连接的start方法,这个方法里面主要是会去开启两个线程,一个线程主要用来连接服务端,一个线程主要用来响应连接后的事件
public void start() { sendThread.start(); eventThread.start(); }- 1
- 2
- 3
- 4
- 5
开启这个了线程之后,主要是查看这个线程的run方法。
接下来看第一个 sendThread 线程的run方法,主要如下,用于连接这个服务端,主要是基于nio和netty两种方式实现这个连接。在连接成功之后,会通过这个nio轮询的方式监听里面的读写事件的发生,并对这个事件进行处理@Override public void run() { while (state.isAlive()) { try { //如果没有建立连接 if (!clientCnxnSocket.isConnected()) { onConnecting(serverAddress); //建立连接 startConnect(serverAddress); } //在建立连接之后,会通过这个nio监听这个读写事件并处理 clientCnxnSocket.doTransport(to, pendingQueue, ClientCnxn.this); } } } private void startConnect(InetSocketAddress addr) throws IOException { //基于这个nio或者netty两种方式实现,连接这个客户端 clientCnxnSocket.connect(addr); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
接下来看第二个线程 eventThread 的run方法,主要是调用一个watcher的一个监听机制
@Override public void run() { while (true) { //从阻塞队列里面获取一个事件对象 Object event = waitingEvents.take(); //处理这个事件 processEvent(event); } } private void processEvent(Object event) { WatcherSetEventPair pair = (WatcherSetEventPair) event; //Watcher监听机制,用于事件回调 watcher.process(pair.event); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2,客户端写数据
3,建立连接成功之后,就可以开始写数据的操作,主要是通过这个create的这个方法实现
zooKeeper.create("/myconfig", bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);- 1
这个create的方法具体如下,就是会将这个发送的数据以及存放的路径做一个封装
public String create( final String path, byte[] data, List<ACL> acl, CreateMode createMode) throws KeeperException, InterruptedException { //会将传进来的数据和路径封装到一个request里面 request.setData(data); request.setFlags(createMode.toFlag()); request.setPath(serverPath); //通过这个连接对象实现这个客户端向服务端发送数据 ReplyHeader r = cnxn.submitRequest(h, request, response, null); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
发送数据的具体实现如下,会对这个传来的数据进行一个打包的操作,在数据打包之后,会将这个数据存放到一个阻塞队列里面
public ReplyHeader submitRequest(...){ //对这个传过来的数据进行一个打包操作 Packet packet = queuePacket(h,r,request,response,null,null,null,null, watchRegistration,watchDeregistration); waitForPacketFinish(r, packet); } public Packet queuePacket(){ synhronized (outgoingQueue) { if (!state.isAlive() || closing) { conLossPacket(packet); } else { if (h.getType() == OpCode.closeSession) { closing = true; } //将打包的数据存放到一个阻塞队列里面 outgoingQueue.add(packet); } //唤醒被阻塞的selector,然后向这个管道写入一个数据, //这样就可以触发前面的sendThread线程,并触发里面的写事件,将数据写入到服务端 sendThread.getClientCnxnSocket().packetAdded(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
最终会通过这个Socket的write写入事件,将这个序列化后的数据存放到buffer里面,然后通过这个SocketChannel的write方法将数据写入到服务端。数据主要是通过这个outgoingQueue队列,以异步的方式将这个信息发送到服务端。
3,服务端接收数据
4,服务端这边主要是在这个 ServerCnxnFactory 类下面的 createFactory 方法里面来构建与客户端的连接,这个服务端接收数据主要是通过主结点和这个客户端进行一个交互
public abstract class ServerCnxnFactory { static public ServerCnxnFactory createFactory() throws IOException { //这里主要是选择nio的方式或者选择netty的方式建立一个连接 String serverCnxnFactoryName = System.getProperty(ZOOKEEPER_SERVER_CNXN_FACTORY); if (serverCnxnFactoryName == null) { serverCnxnFactoryName = NIOServerCnxnFactory.class.getName(); } try { //然后通过这个反射的方式找到对应的server,如使用的netty连接就会找nettyServer ServerCnxnFactory serverCnxnFactory = (ServerCnxnFactory) Class.forName(serverCnxnFactoryName) .getDeclaredConstructor().newInstance(); return serverCnxnFactory; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5,接下来主要查看这个 NettyServerCnxnFactory 类的这个构造方法,底层主要是一些netty的一些实现逻辑。主要用来实现数据的传输
NettyServerCnxnFactory() { EventLoopGroup bossGroup = NettyUtils.newNioOrEpollEventLoopGroup( NettyUtils.getClientReachableLocalInetAddressCount()); EventLoopGroup workerGroup = NettyUtils.newNioOrEpollEventLoopGroup(); ServerBootstrap bootstrap = new ServerBootstrap() .group(bossGroup, workerGroup) .channel(NettyUtils.nioOrEpollServerSocketChannel()) // parent channel options .option(ChannelOption.SO_REUSEADDR, true) // child channels options .childOption(ChannelOption.TCP_NODELAY, true) .childOption(ChannelOption.SO_LINGER, -1) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); if (secure) { initSSL(pipeline, false); } else if (shouldUsePortUnification) { initSSL(pipeline, true); } pipeline.addLast("servercnxnfactory", channelHandler); } }); this.bootstrap = configureBootstrapAllocator(bootstrap); this.bootstrap.validate(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
6,在建立好连接之后,服务端这边会通过这个channelRead 这个方法来读取通道的信息,就是客户端发过来的信息。
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { try { if (LOG.isTraceEnabled()) { LOG.trace("message received called {}", msg); } try { if (LOG.isDebugEnabled()) { LOG.debug("New message {} from {}", msg, ctx.channel()); } //服务端的连接对象 NettyServerCnxn cnxn = ctx.channel().attr(CONNECTION_ATTRIBUTE).get(); if (cnxn == null) { } else { //处理客户端传过来的数据 cnxn.processMessage((ByteBuf) msg); } } catch (Exception ex) { LOG.error("Unexpected exception in receive", ex); throw ex; } } finally { ReferenceCountUtil.release(msg); } } //处理这个客户端传过来的数据 void processMessage(ByteBuf buf){ receiveMessage(buf); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
7,接下来就是正式的接收这个发送过来的数据,并对这个数据进行处理
private void receiveMessage(ByteBuf message) { //读取message,将数据读取到服务端的byteBuffer里面 message.readBytes(bb); //处理这个打包好的数据 zks.processPacket(this, bb); }- 1
- 2
- 3
- 4
- 5
- 6
接下来进入这个processPacket 这个方法,主要是用来解析打包的数据。并且在服务端中,又会将这个数据进行一个打包,封装到一个request的一个阻塞队列里面,最后将这个打包的数据进行提交
public void processPacket(ServerCnxn cnxn, ByteBuffer incomingBuffer) throws IOException { //二进制流接收数据 InputStream bais = new ByteBufferInputStream(incomingBuffer); BinaryInputArchive bia = BinaryInputArchive.getArchive(bais); //将传送过来的序列化的数据进行一个反序列化 RequestHeader h = new RequestHeader(); h.deserialize(bia, "header"); //最后将客户端传过来的数据又封装到一个request的对象里面 Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(), h.getType(), incomingBuffer, cnxn.getAuthInfo()); si.setOwner(ServerCnxn.me); setLocalSessionFlag(si); //提交这个数据 submitRequest(si); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4,服务端主结点处理数据
8,就是进入上面的这个 submitRequest 的提交数据的这个方法,里面主要是通过一个processRequest的这个方法来进行处理这些数据
public void submitRequest(Request si) { firstProcessor.processRequest(si); }- 1
- 2
- 3
9,这个firstProcessor的处理器主要是在 LeaderZooKeeperServer 类下面的这个 setupRequestProcessors 的这个方法初始化的。服务端这边主要会初始化这个Processor的一个链条,底层主要是通过这个责任链的方式实现。责任链主要是为了分工合作,模块解耦
@Override protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); //将上一个processor放入下一个processor,开始构建一个责任链的一个链条 RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader()); commitProcessor = new CommitProcessor(toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener()); commitProcessor.start(); ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor); proposalProcessor.initialize(); prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor); //获取队列的数据,并对数据进行读取 prepRequestProcessor.start(); firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor); setupContainerManager(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这个链条如下

10,在执行这个链条的过程中,会通过这个prepRequestProcessor这个线程来读取加在服务端队列的里面的消息,接下来主要就是查看这个线程里面的run方法。这个结点其主要是为了填充这个zxid,就是事务id
@Override public void run() { try{ Request request = submittedRequests.take(); //通过这个方法进行最终的处理 pRequest(request); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在这个pRequest方法里面,会比较之前客户端传过来的命令,比如说create,delete命令等,那么服务端就会执行具体的操作。
protected void pRequest(Request request) throws RequestProcessorException { try { switch (request.type) { case OpCode.createContainer: case OpCode.create: case OpCode.create2: CreateRequest create2Request = new CreateRequest(); //创建命令的具体逻辑 pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true); break; case OpCode.createTTL: CreateTTLRequest createTtlRequest = new CreateTTLRequest(); pRequest2Txn(request.type, zks.getNextZxid(), request, createTtlRequest, true); break; case OpCode.deleteContainer: case OpCode.delete: DeleteRequest deleteRequest = new DeleteRequest(); pRequest2Txn(request.type, zks.getNextZxid(), request, deleteRequest, true); break; case OpCode.setData: SetDataRequest setDataRequest = new SetDataRequest(); pRequest2Txn(request.type, zks.getNextZxid(), request, setDataRequest, true); break; ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
接下来就是主要查看一下这个创建命令,主要是通过这个 pRequest2Txn 方法实现,并且里面的这个参数zxid,是一个automic的一个原子类型,不存在这个线程安全问题。获取的命令越新,那么这个zxid的值就越大。 每从这个内存队列里面获取一条消息,那么这个zxid的值就会加1
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException{ //将这个zxid填充回request request.zxid = zks.getZxid(); //由下一个process处理 nextProcessor.processRequest(request); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5,主结点同步数据到从结点(ZAB协议)
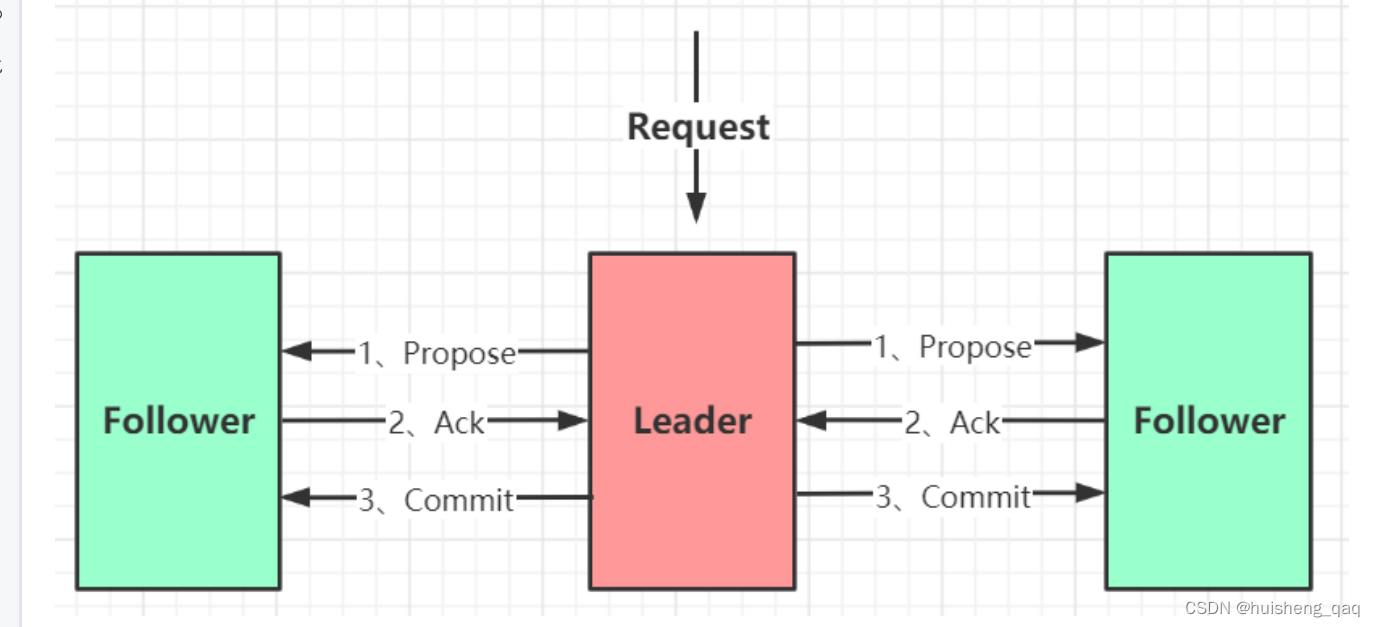
5.1,发送这个propose(第一阶段)
11,完成了这个链条中的第二个环节之后,就进入第三个环节,即ProposalRequestProcessor的这个结点。这一环节只要是为了同步数据到从结点,并且将数据同步到从结点之后,会将这个数据在本地磁盘里面保存一份
public class ProposalRequestProcessor implements RequestProcessor { //主要是会走这个方法 public void processRequest(Request request) throws RequestProcessorException { nextProcessor.processRequest(request); //propose处理这个request zks.getLeader().propose(request); //将数据写入到本地磁盘 syncProcessor.processRequest(request); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
接下来查看这个propose方法,会对主结点中的数据进行一个预处理,并将数据发送给全部的从结点
public Proposal propose(Request request) throws XidRolloverException { //序列化 byte[] data = SerializeUtils.serializeRequest(request); proposalStats.setLastBufferSize(data.length); //对数据进行打包,里面会有几种数据类型,如ping,ack等 QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid, data, null); //将这些数据全部发送出去 sendPacket(pp); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个sendPacket方法,就是会轮询的将数据发送给所有的这个follow从结点
void sendPacket(QuorumPacket qp) { synchronized (forwardingFollowers) { //循环发送 for (LearnerHandler f : forwardingFollowers) { f.queuePacket(qp); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
数据发送完同时也会将数据存放在这个本地磁盘里面,主要是通过这个SyncRequestProcessor 类里面的这个processRequest线程实现,主要查看这个线程的run方法。就是leader主结点将数据存在本地磁盘
@Override public void run() { //将一些数据初始化到磁盘上面 zks.getZKDatabase().rollLog(); //调用一个flush方法,主要用于写日志文件 //主要是写一些事物文件和快照文件 flush(toFlush); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.2,Ack确认机制
12,主要是通过这个 AckRequestProcessor 类实现,里面有一个processRequest的这个方法,就是首先这个leader会先给自己发一个ack,这样在后面统计这个只有从结点的响应的ack的同时,还需要加上这个主结点的ack。
public void processRequest(Request request) { QuorumPeer self = leader.self; if(self != null) leader.processAck(self.getId(), request.zxid, null); else LOG.error("Null QuorumPeer"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过这个processAck 方法可以知道,最终会将这个结点的sid存到主结点的一个hashset的一个集合里面。
//将这台机器的sid存在这个hashset里面 p.addAck(sid); //尝试判断这个票数是否大于一半,大于一半则提交 boolean hasCommitted = tryToCommit(p, zxid, followerAddr);- 1
- 2
- 3
- 4
13,主结点会给所有的从结点发送数据,会和这些从结点建立nio的一个连接,然后通过这个 LearnerHandler 类来发送这个消息。这个类继承了一个线程类,那么主要看这个类的run方法
public class LearnerHandler extends ZooKeeperThread { @Override public void run() { //会开始发送这个数据包 startSendingPackets(); } private void startSendingPackets() throws InterruptedException { public void run() { try { //开始发送数据包 sendPackets(); } catch (InterruptedException e) { LOG.warn("Unexpected interruption " + e.getMessage()); } } }.start(); } private void sendPackets() throws InterruptedException { QuorumPacket p; //从队列中获取数据 p = queuedPackets.poll(); //通过bio的方式,将序列化的数据写入到从结点 oa.writeRecord(p, "packet"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
14,主结点将消息发送到这个从结点之后,在这个Follow的这个类里面,通过这个followLeader方法来读取主结点的发过来的消息,同时也会将这个数据存储在这个本地磁盘里面
public class Follower extends Learner{ void followLeader() throws InterruptedException { while (this.isRunning()) { //读取传过来的数据 readPacket(qp); //处理这个packet的这个数据包 processPacket(qp); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从结点处理主结点发送的这个数据包的具体实现如下
//处理这个数据包的过程如下 protected void processPacket(QuorumPacket qp) throws Exception{ case Leader.PING: ping(qp); break; //将传过来的数据写入到磁盘 case Leader.PROPOSAL: fzk.logRequest(hdr, txn); break; case Leader.COMMIT: fzk.commit(qp.getZxid()); break; ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
15,从结点在处理完数据之后,会通过这个 SendAckRequestProcessor 类里面的 processRequest 方法来给这个主结点返回一个ack
public class SendAckRequestProcessor implements RequestProcessor, Flushable { public void processRequest(Request si) { //构建一个返回一个ACK的一个数据包 QuorumPacket qp = new QuorumPacket(Leader.ACK, si.getHdr().getZxid(), null,null); //将数据写入,通过这个bio的连接,将数据写会给这个主结点 learner.writePacket(qp, false); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
16,从结点同步完数据之后,会返回一个ack的一个确认机制,主结点主要是 LearnerHandler 线程类的run方法里面实现,里面有一个while循环一直接收这个从结点发的消息。类型为ack时会和之前的流程一样,将这个从结点的sid存放在一个hashset的一个集合里面,最后会去尝试这个commit提交,大于一半就会提交
public class LearnerHandler extends ZooKeeperThread { @Override public void run() { while (true) { //leader获取数据 qp = new QuorumPacket(); ia.readRecord(qp, "packet"); //获取数据的类型 switch (qp.getType()) { //这个ack会走和主结点ack一样的流程 case Leader.ACK: ...; break; case Leader.PING: ...; break; case Leader.REVALIDATE: ...; break; case Leader.REQUEST: ...; break; } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5.3,commit提交(第二阶段)
17,在主结点获取到这个ack之后,都会有一个尝试commit的提交操作,如果这个票数过半,那么就会走这个正式的commit的提交操作。就是说leader会再发起一个请求,告诉这些从结点也可以进行数据的提交,就是将之前存在日志里面的数据加载到内存里面,那么其他客户端来查询就可以从这个从结点里面查出这个数据。从结点数据提交之后,这个主结点的数据也会提交。
synchronized public boolean tryToCommit(Proposal p, long zxid, SocketAddress followerAddr) { commit(zxid); inform(p); //从结点提交之后,主结点这边也会进行一个提交 zk.commitProcessor.commit(p.request); }- 1
- 2
- 3
- 4
- 5
- 6
然后主要查看这个commit 方法
public void commit(long zxid) { synchronized(this){ lastCommitted = zxid; } //又会构建一个数据包,这个类型是COMMIT类型,同时返回一个zxid QuorumPacket qp = new QuorumPacket(Leader.COMMIT, zxid, null, null); //轮询的方式发送给所有的从结点, sendPacket(qp); } void sendPacket(QuorumPacket qp) { //轮询的方式发送 synchronized (forwardingFollowers) { for (LearnerHandler f : forwardingFollowers) { f.queuePacket(qp); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
再查看这个inform 方法,可以发现这个数据也会同步给Observer的结点
public void inform(Proposal proposal) { QuorumPacket qp = new QuorumPacket(Leader.INFORM, proposal.request.zxid, proposal.packet.getData(), null); sendObserverPacket(qp); }- 1
- 2
- 3
- 4
- 5
在从结点提交完数据之后,主结点也会提交数据,就是将存在磁盘里面的数据加载到内存里面
protected void processCommitted() { Request request; //从队列中获取消息 request = committedRequests.poll(); Request pending = nextPending.get(); sendToNextProcessor(pending); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
6,服务端走完最后两个链条结点
18,接下来进入链条的倒数第二个结点ToBeAppliedRequestProcessor
static class ToBeAppliedRequestProcessor implements RequestProcessor{ public void processRequest(Request request) throws RequestProcessorException { //责任链模式,直接进入下一个request next.processRequest(request); } }- 1
- 2
- 3
- 4
- 5
- 6
19,那么直接进入责任链里面的最后一个节点 FinalRequestProcessor
public class FinalRequestProcessor implements RequestProcessor { public void processRequest(Request request) { //处理事务 rc = zks.processTxn(request); } }- 1
- 2
- 3
- 4
- 5
- 6
接下来可以查看这个processTxn的这个方法,就是将这个内存中的数据存储到对应的树形结构里面
private ProcessTxnResult processTxn(Request request, TxnHeader hdr,Record txn) { rc = getZKDatabase().processTxn(hdr, txn); } public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) { //将结果加入到zookeeper的树形结构中 return dataTree.processTxn(hdr, txn); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7,服务端给客户端反馈
20,依旧是在这个责任链模式的最后一个结点FinalRequestProcessor,里面会有一个服务端给客户端的响应。就是告知客户端这条命令执行是否成功失败
public class FinalRequestProcessor implements RequestProcessor { public void processRequest(Request request) { //给客户端响应 cnxn.sendResponse(hdr, rsp, "response"); } }- 1
- 2
- 3
- 4
- 5
- 6
然后就是查看这个sendResponse方法,
public void sendResponse(ReplyHeader h, Record r, String tag) throws IOException { ByteArrayOutputStream baos = new ByteArrayOutputStream(); //对数据进行序列化 BinaryOutputArchive bos = BinaryOutputArchive.getArchive(baos); try { baos.write(fourBytes); bos.writeRecord(h, "header"); if (r != null) { bos.writeRecord(r, tag); } baos.close(); } catch (IOException e) { LOG.error("Error serializing response"); } byte b[] = baos.toByteArray(); serverStats().updateClientResponseSize(b.length - 4); ByteBuffer bb = ByteBuffer.wrap(b); bb.putInt(b.length - 4).rewind(); //以流的方式发送 sendBuffer(bb); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在看这个sendBuffer方法,将封装给客户端的数据返回
@Override public void sendBuffer(ByteBuffer sendBuffer) { if (sendBuffer == ServerCnxnFactory.closeConn) { close(); return; } channel.writeAndFlush(Unpooled.wrappedBuffer(sendBuffer)).addListener( onSendBufferDoneListener); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
8,客户端接收反馈
21,由于这个客户端和这个服务一开始就建立了这个nio连接或者netty连接,因此在服务端给客户端发送这个数据的时候,客户端这边也可以立马收到响应。
依旧是在这个ClientCnxn类里面,找到这个这个客户端的doTransport方法,就是会去处理对应的事件public class ClientCnxn { clientCnxnSocket.doTransport(to, pendingQueue, ClientCnxn.this); }- 1
- 2
- 3
在nio的这个doTransport方法里面,会去判断这个事件的读写
@Override void doTransport(int waitTimeOut, List<Packet> pendingQueue, ClientCnxn cnxn) throws IOException, InterruptedException { //判断是读事件开始写事件 if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) { doIO(pendingQueue, cnxn); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
22,客户端这边主要是通过这个doIO方法来读取这个io流的数据
@Override void doIO(int waitTimeOut, List<Packet> pendingQueue, ClientCnxn cnxn) throws IOException, InterruptedException { //读取这个io sendThread.readResponse(incomingBuffer); } void readResponse(ByteBuffer incomingBuffer) throws IOException { //客户端这边会有一个watcher的监听器 WatchedEvent we = new WatchedEvent(event); //会将这个事件加入到队列中 eventThread.queueEvent( we ); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
接下来查看这个重点的queueEvent方法,就是会将这个事件加入到一个阻塞队列里面。在zookeeper客户端启动的时候,就会创建两个线程,一个就是用于监听机制的eventThread线程,监听的事件就是现在加入的事件。
private void queueEvent(WatchedEvent event,Set<Watcher> materializedWatchers) { WatcherSetEventPair pair = new WatcherSetEventPair(watchers, event); waitingEvents.add(pair); }- 1
- 2
- 3
- 4
三,总结
1,ZAB的消息广播总结
一个zookeeper的原子消息的协议,主要通过两阶段提交的方式实现:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1aBk7lSO-1662303515595)(C:\Users\HULOUBO\AppData\Roaming\Typora\typora-user-images\1662298047795.png)]](https://1000bd.com/contentImg/2023/10/31/022649827.png)
1,在第一阶段,首先zookeeper的客户端和这个服务端的leader主结点会通过nio或者netty的方式建立连接,然后客户端可以向这个主结点里面发送数据。2,主结点接收到数据之后,leader主结点会向这个从结点发送一个proposal的一个命令,并且会以轮询的方式发给所有从结点,同时会将这个data数据和事务id一起发送给从结点
3,主结点发送完这个命令之后,leader主结点会同步将数据存在本地磁盘里面,并且给自己投一个ack的票
4,从结点将主结点发来的数据会先存储在本地磁盘,并且给主结点返回一个ack
5,主结点会去统计这个ack的票数,就是从结点所返回的ack和自己投票的ack
6,在第二阶段,如果ack的票数大于一半,那么主结点就会给从结点发送一个commit提交命令
7,在从结点里面的数据一开始是存储在磁盘的,在接收到这个commit命令之后,会将数据存储到内存
8,主结点也会将存储在磁盘的数据加入这个内存里面
9,主结点最后会给客户端一个数据变动的Event事件,并给这个客户端返回一个命令操作的结果
2,zookeeper的脑分裂问题
就是说在一段很短的时间内,这个网络不稳定或者说这个出现这个断网的现象,那么可能造成leader和follow无法通信的情况,那么的从结点就会认为这个主结点可能挂了,因此集群的从结点就会重新进行一个主结点的选举,在短时间内,这个之前的主结点又恢复了,那么此时会有两个这个主结点,就是造成了这个脑裂问题,这样就会有大量的数据丢失。
解决答案 :就是通过这个zab解决。就是说在如果出现脑分裂,那么就会有两个主结点,其中后面这个新选举的主结点会有从结点,而这个出现网络故障的主结点没有这个从结点。根据这个两阶段提交,如果外面有数据写进来,会先写到磁盘里面,此时两个主结点磁盘都有数据,但是需要通过投票机制,超过一半的投票才能将数据提交到内存里面,这个没有从结点的主结点获取的ack票数不能超过一半,那么就不能触发commit提交,那么就不能将数据加载到内存,就不会出现这个数据丢失的情况。
-
相关阅读:
【0143】 System V共享内存(Shared Memory)
2022-09-09 mysql列存储引擎-POC-需求分析-第二版-有问题的SQL
自动驾驶仿真:python和carsim联合仿真案例
Spring Security认证之基本认证
最新5G部署测试测量解决方案
SPIR-V初窥
双臂复合机器人平台叠方块例程使用与自启设置
linux mysql 安装
XCTF-web1文件包含绕过file include
金融行业安全事件频发,数据共享与安全如何平衡?
- 原文地址:https://blog.csdn.net/zhenghuishengq/article/details/126696204
