-
YOLO系列解读(上)-----YOLOv1到YOLOv3梳理
YOLO系列解读(上)
1. 背景介绍

写这篇文章的契机是6月底和7月初,Yolo v6和Yolo v7版本相继发布。其中Yolo v7还得到了darknet官方的背书。
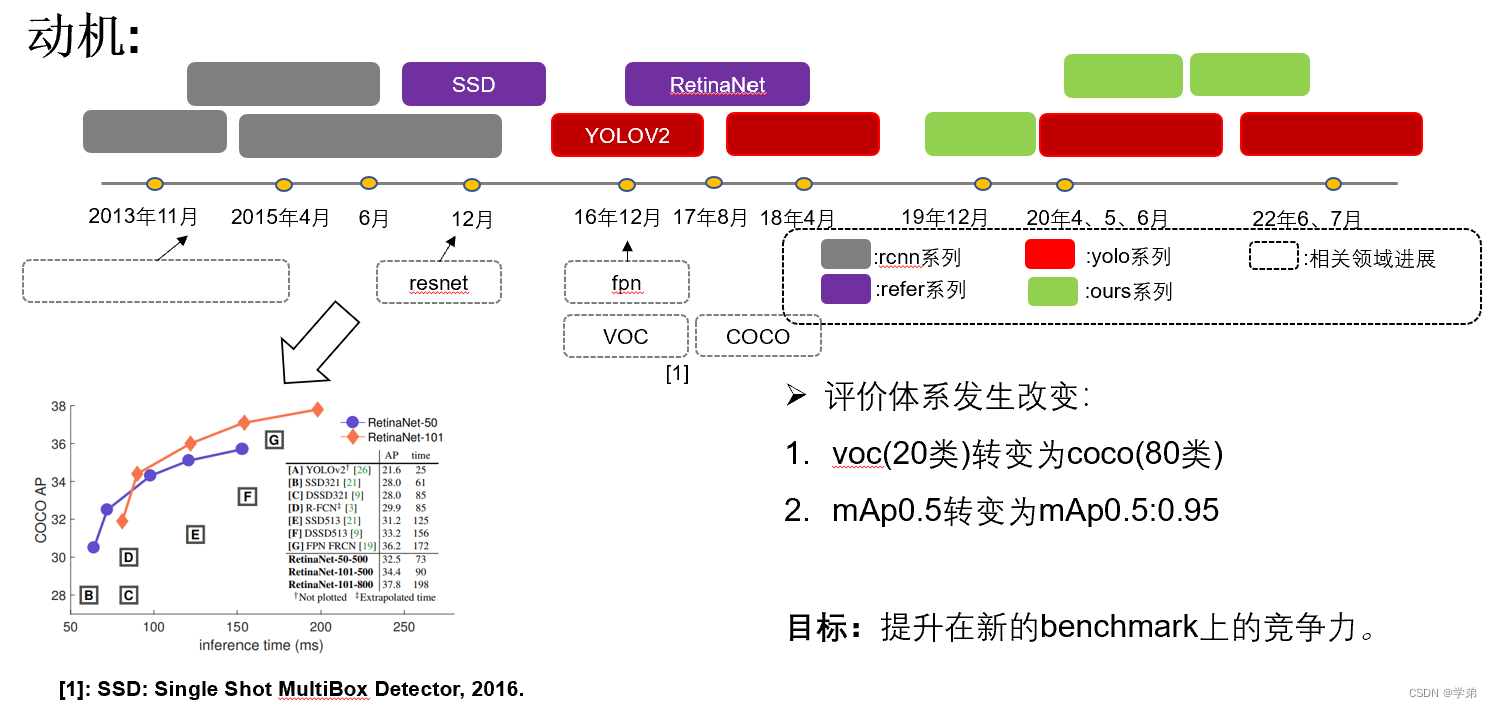
Yolo系列从2015年提出的Yolo(You Only Look Once),到如今已经经历了7年。它的历程可以用下图进行展示。本篇博客仅仅是对Yolo犀利中,Yolov1, Yolov2和Yolov3的梳理。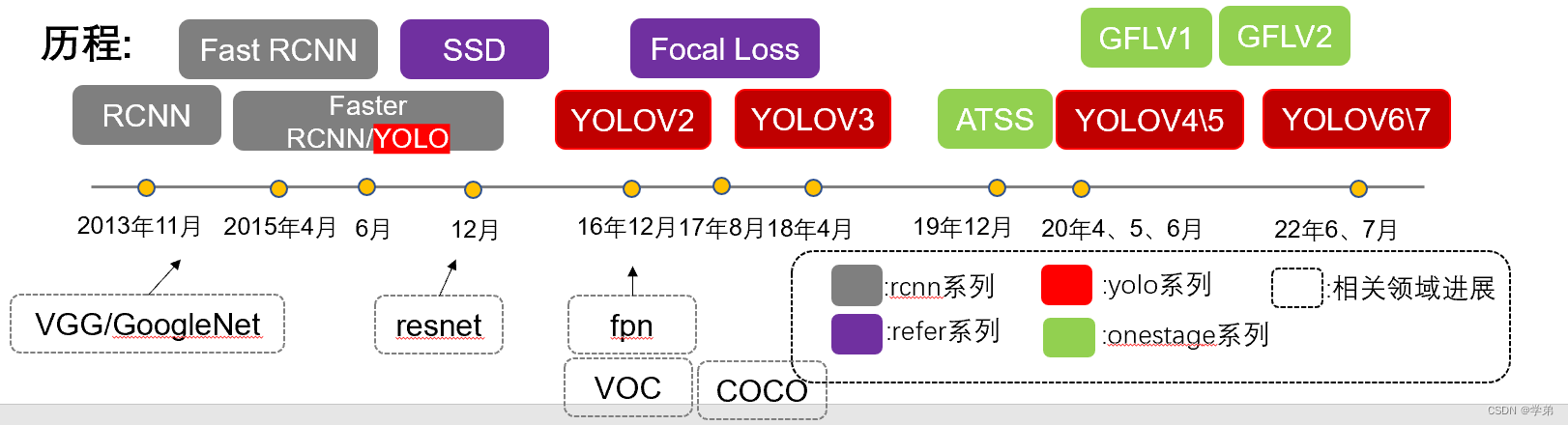
2. 正文:Yolov1~Yolov3
2.1 Yolov1
2.1.1 Yolov1介绍
Yolo提出于2015年6月,在此之前的RCNN系列还是借用分类器来解决目标检测任务。而Yolo则通过一个网络直接以回归的方式来建模。具体的过程可以参看下图。这样做的好处在于训练简单并且推理迅速。
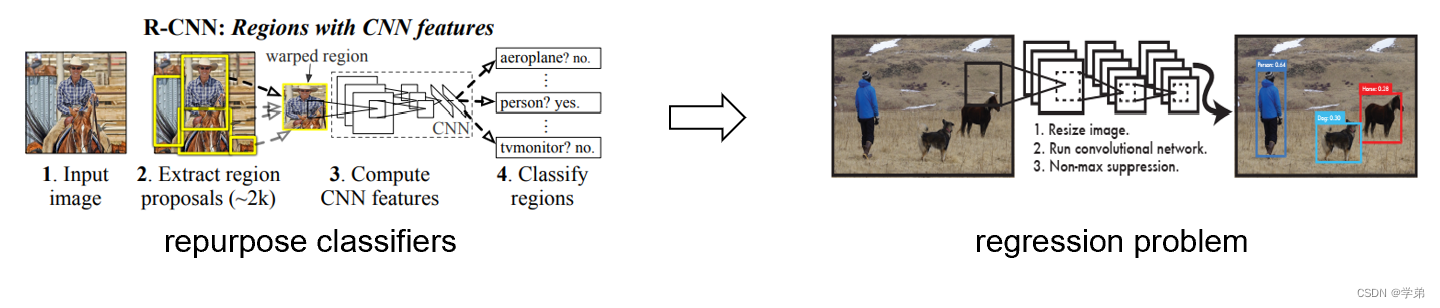
Yolo采用了如下图所示的方法
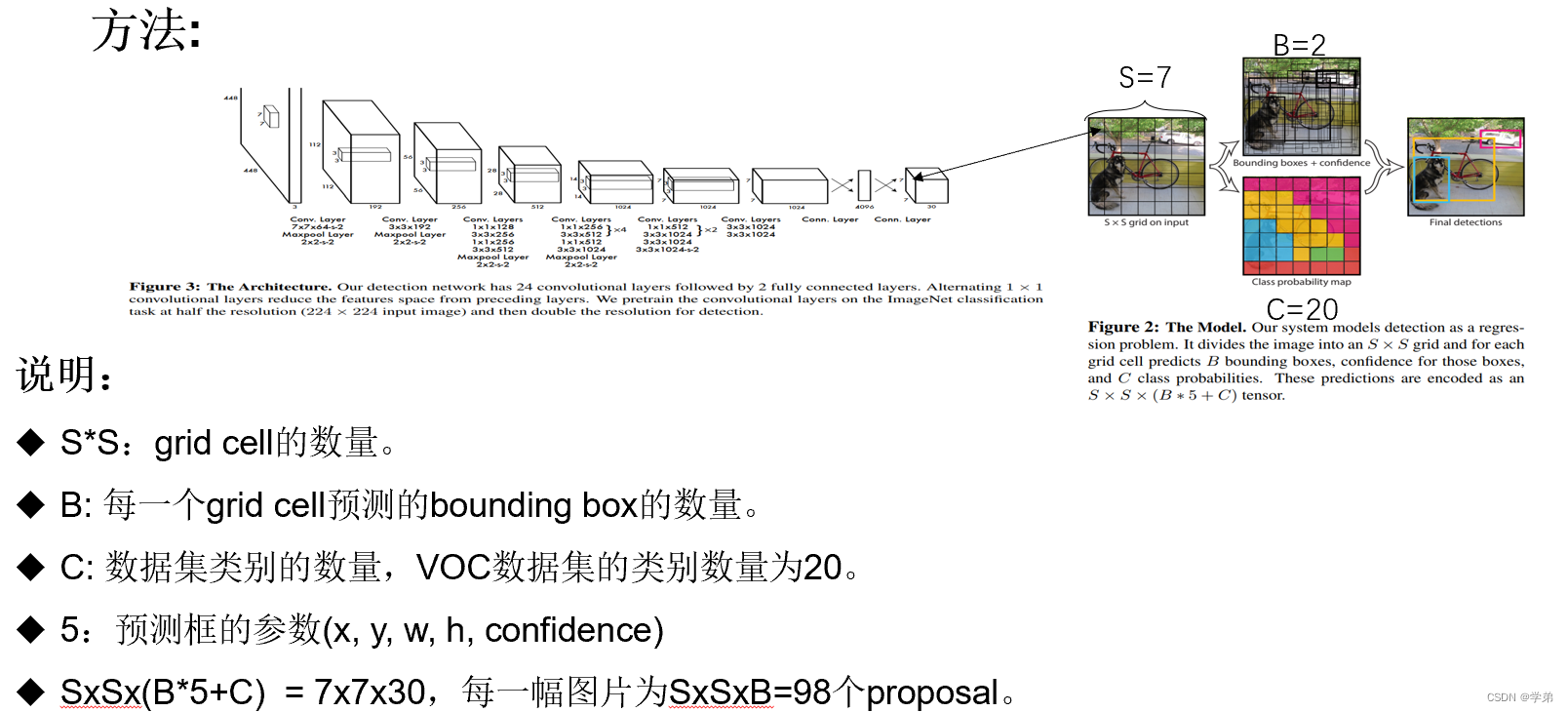
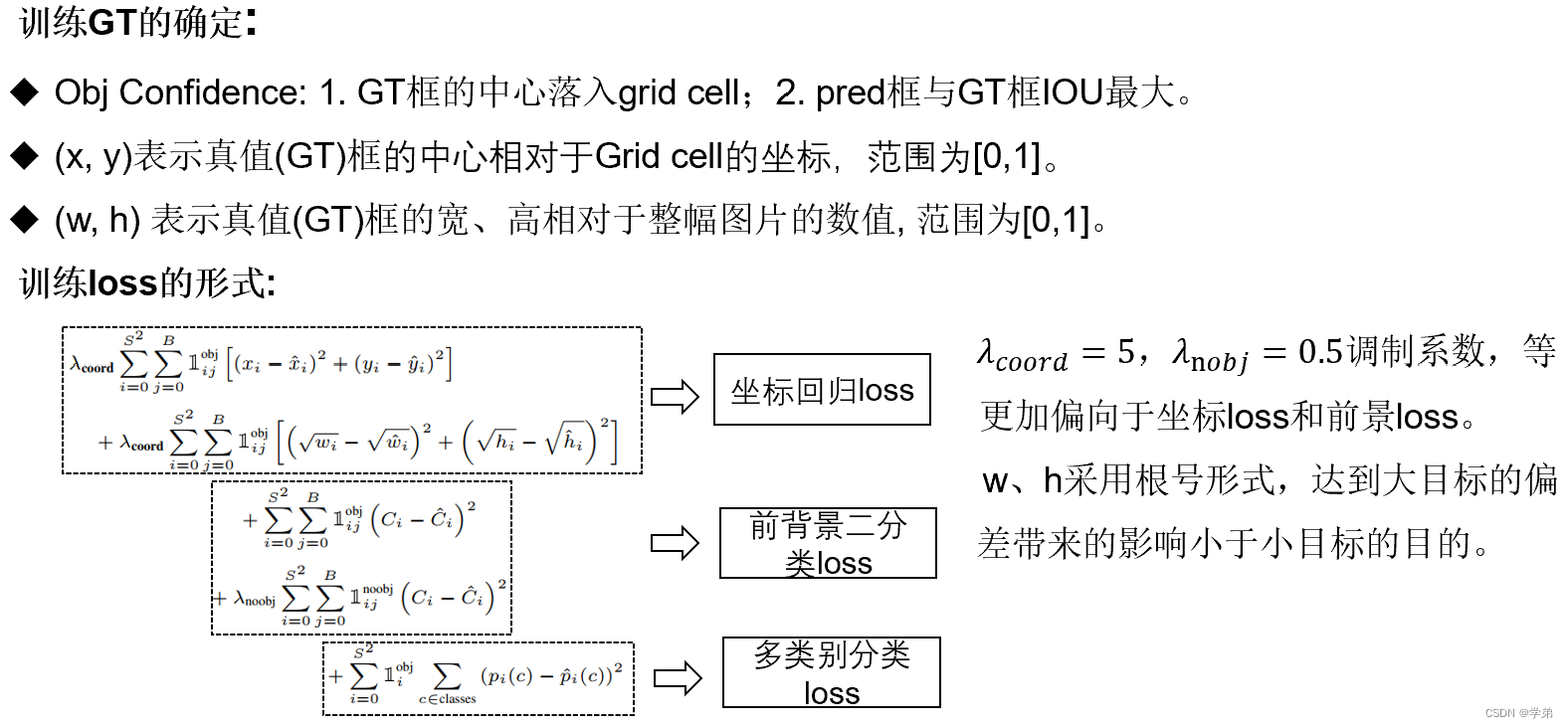
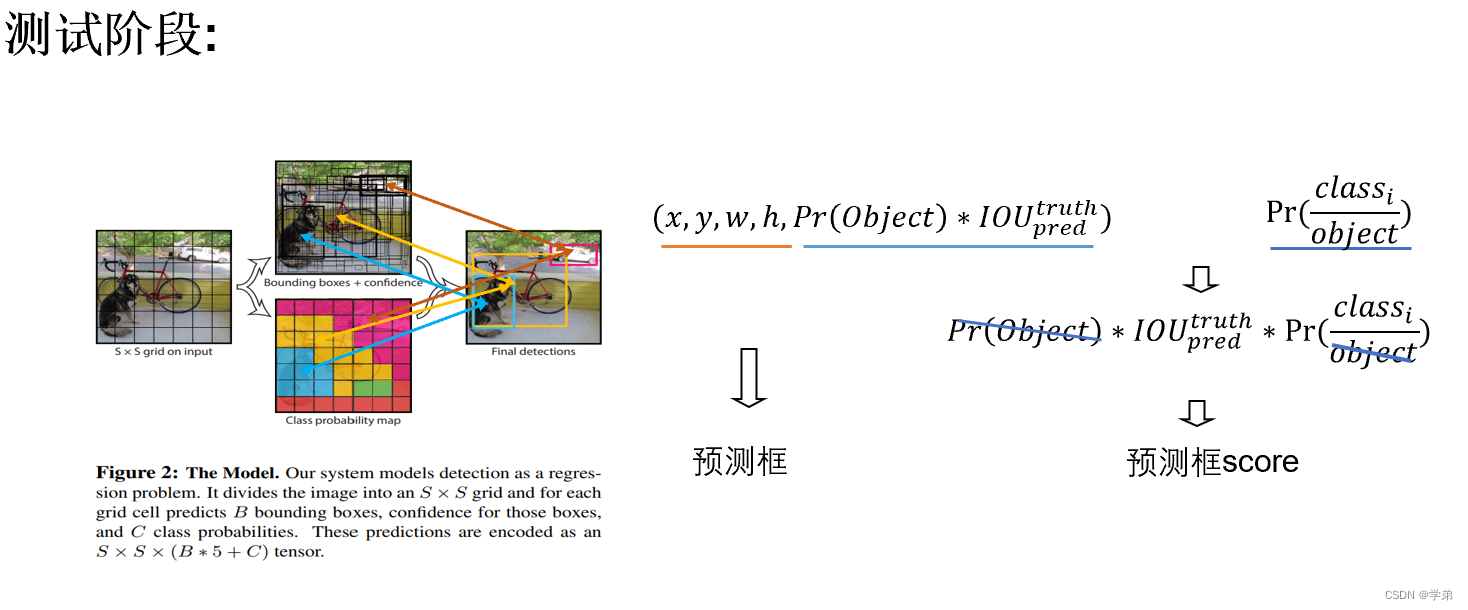
2.1.2 Yolov1 小结
- Yolo并不是让已有的检测pipeline(rnn系列)更快,而是提出了一个全新的pipeline。
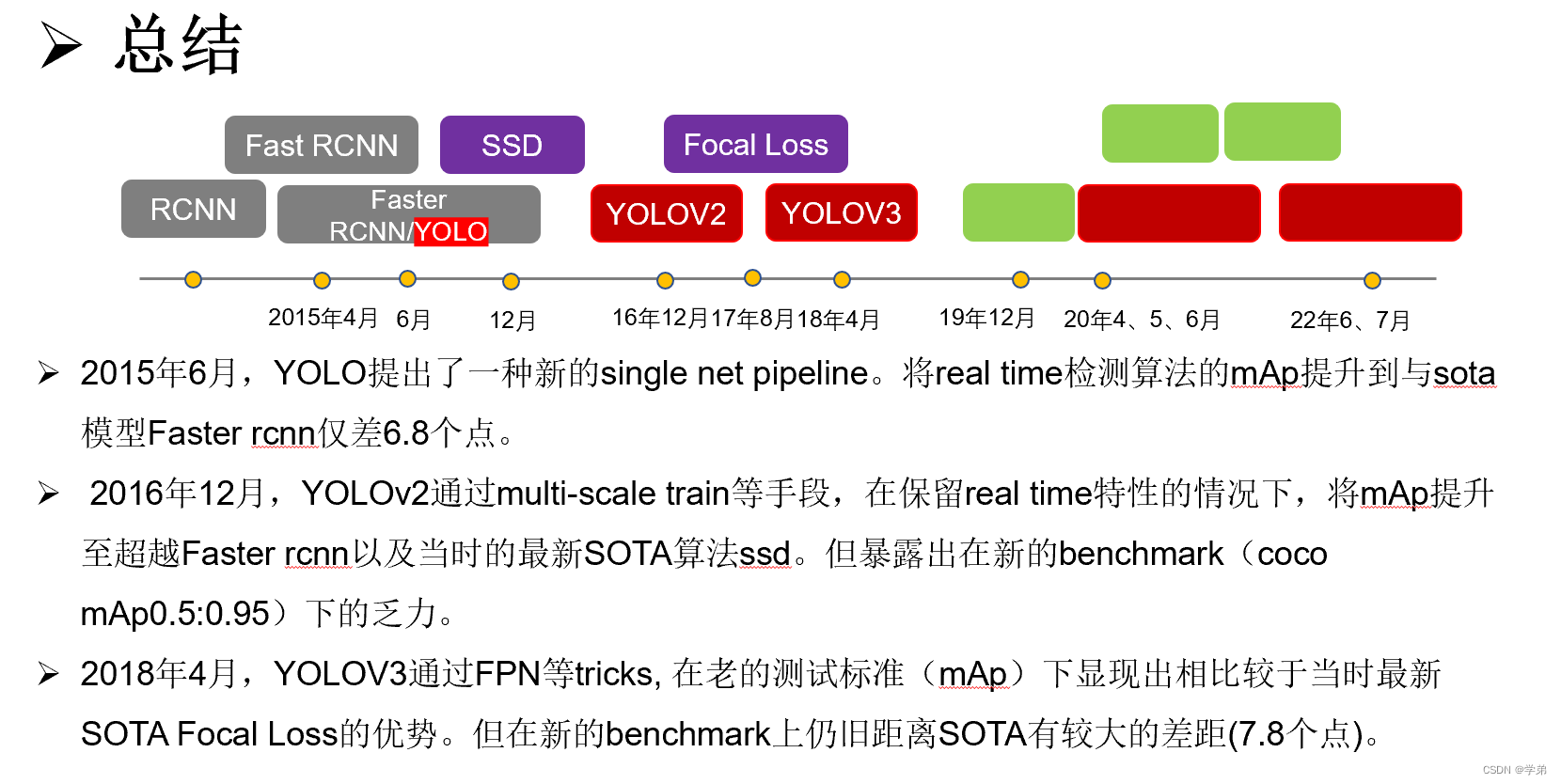
- Yolo在实时检测算法中,性能最高,可以达到double mAp的水平。一般来讲,每秒30帧以上的算法称之为实时检测算法。
- Yolo虽然很快,但性能并非sota。以vgg16作为backbone,距离faster rcnn的mAp还差6.8个点。主要体现在yolo的定位准确度不高。
2.2 Yolov2
2.2.1 Yolov2介绍
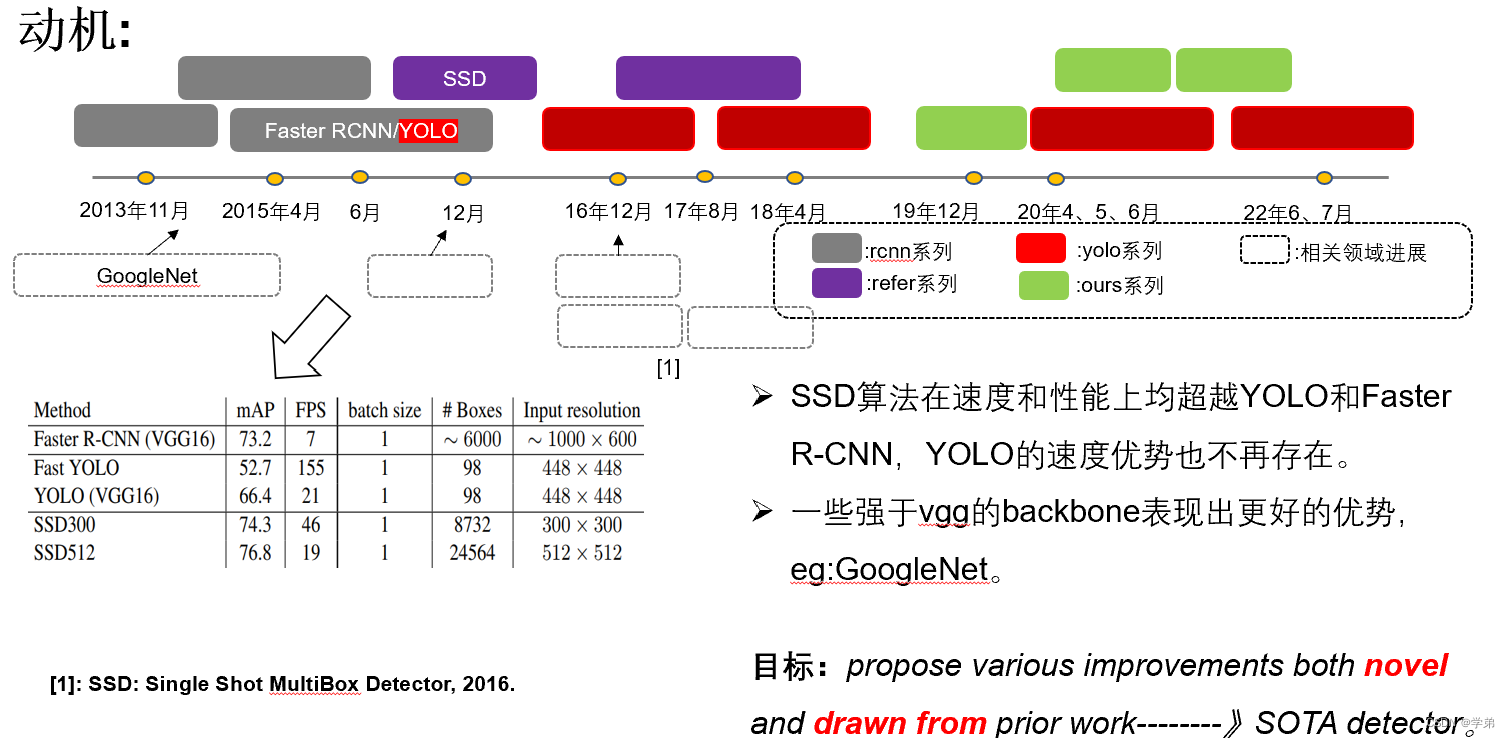

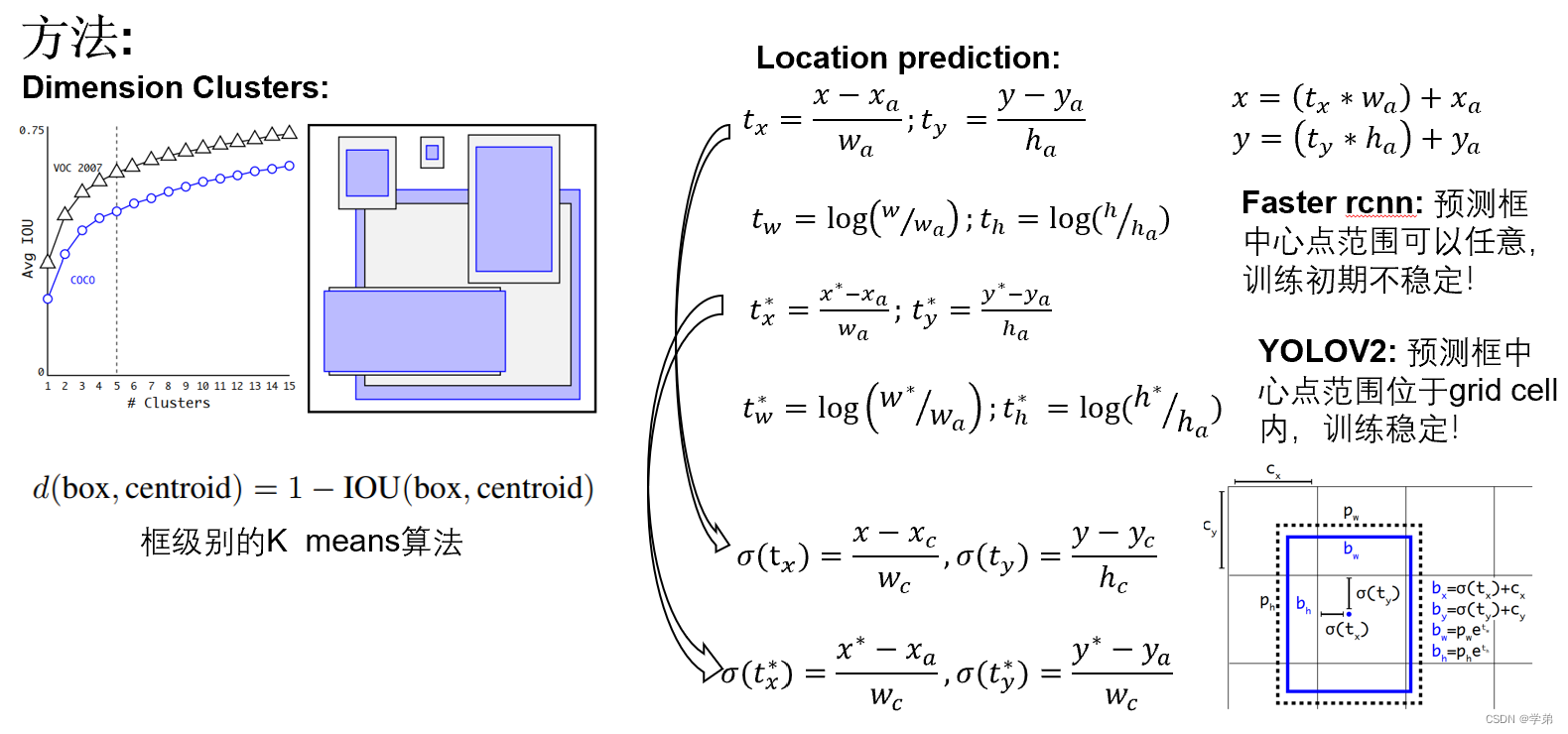
在介绍一下这里面的Dimension Clusters和Location prediction方法。
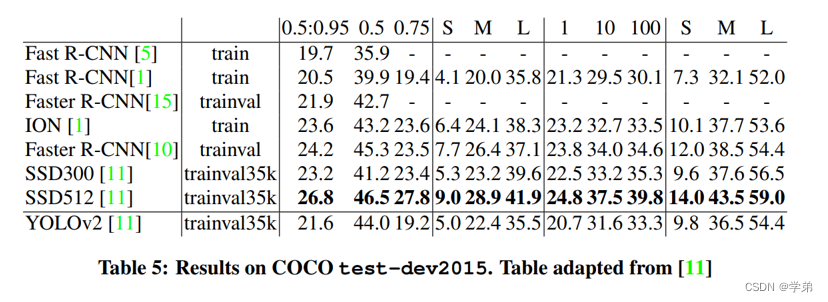
最终Yolov2的性能在VOC数据集上达到了sota。(注意这里强调的是VOC数据集这个条件)。
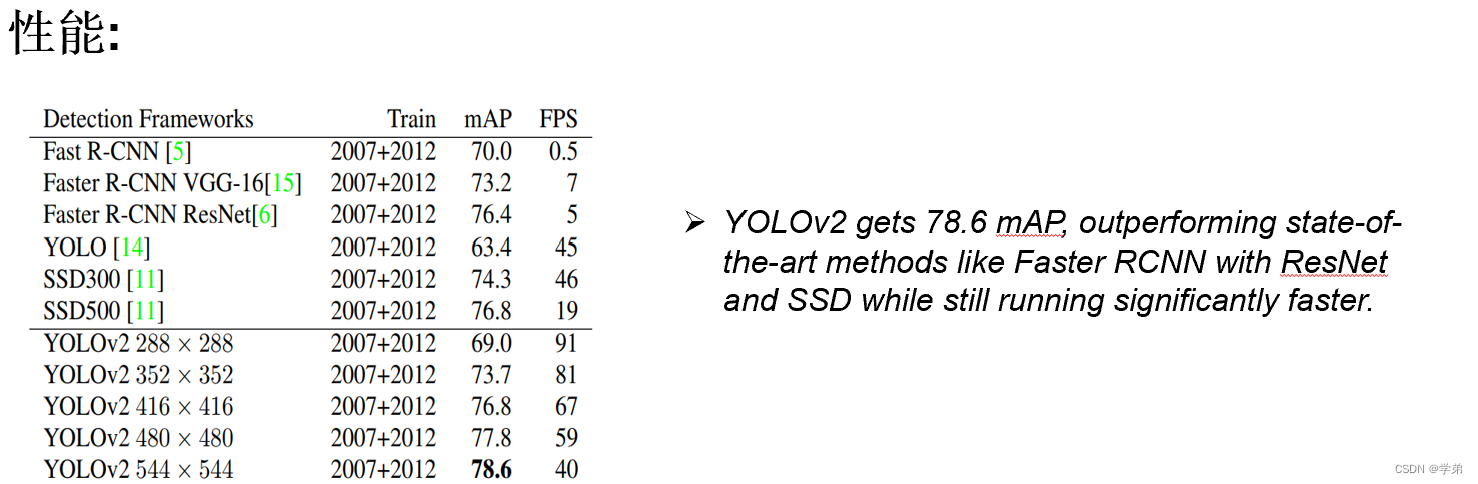
2.2.2 Yolov2小结
- 在voc数据集上达到了sota。
- multi-scale train至今仍旧是一个比较有效的trick。
- 但大部分改进drawn from prior work。
- 论文题目为YOLO9000,想体现的分类、检测联合训练(似乎)影响力有限。
- 在新的benchmark(coco@0.5:0.95)上竞争力有限。
2.3 Yolov3
2.3.1 Yolov3介绍
yolov3所使用的方法也都是基本来自于prior work。具体可以总结为如下3条:- 使用Multilabel classification代替Multiclass classification。
- FPN(feature pyramid networks)。
- 新的backbone:darknet53(借鉴resnet网络的shortcut)。
2.3.1 Yolov3小结
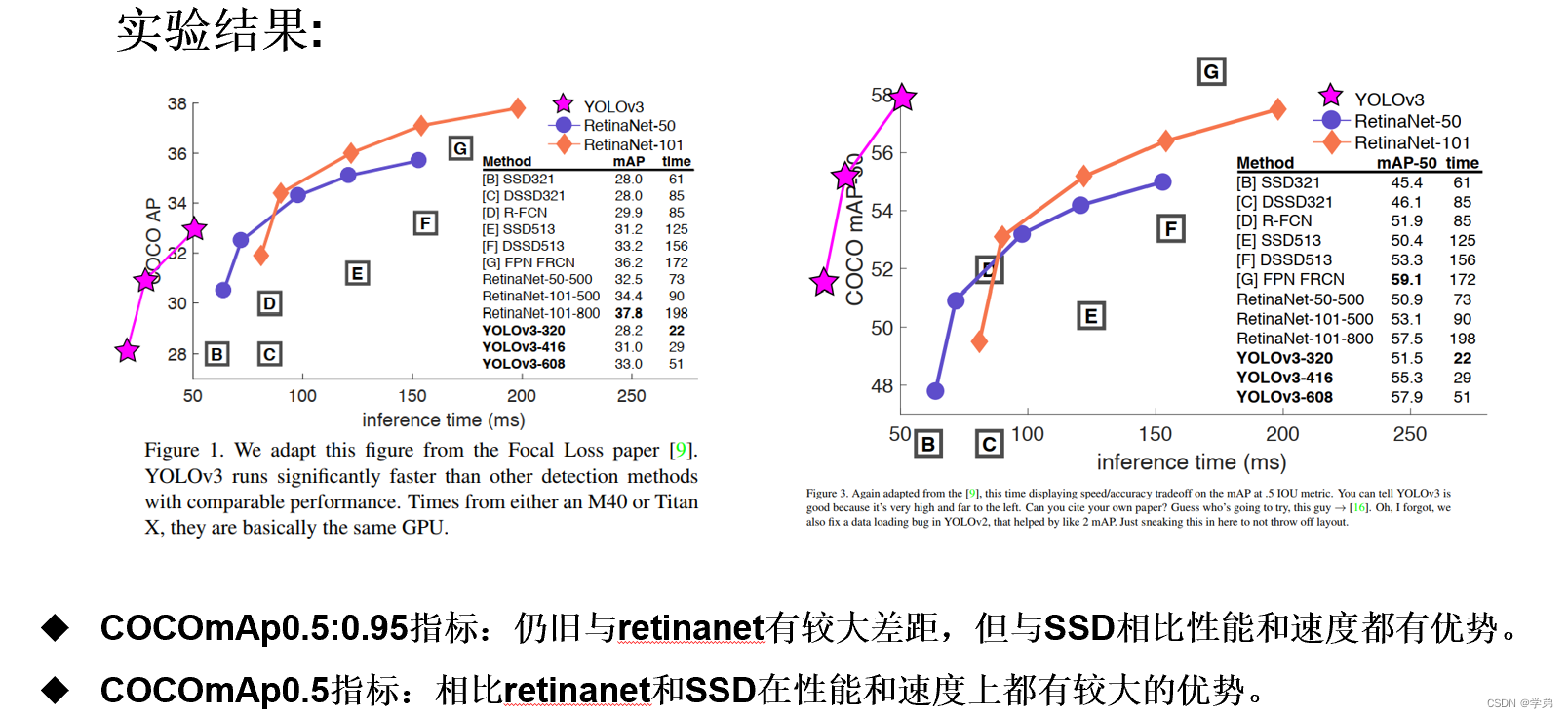
Yolov3适用于对速度要求快,但对IOU阈值要求相对不高的场景。这可能也是Yolo系列论文在工业界流行的原因所在。作者对新的IOU@0.5:0.95的评判标准也提出了自己的一定质疑,并引用了”Best of both worlds: human-machine collaboration for object annotation.“中的一段话:”Training humans to visually inspect a bounding box with IOU of 0.3 and distinguish it from one with IOU 0.5 is surprisingly difficult”。0.3和0.5可能有点夸张了,但0.5和0.7的区分性确实不大。

3. 总结
-
相关阅读:
Leetcode338. 比特位计数
【5】c++11新特性(稳定性和兼容性)—>override关键字
Linux 安装字体
Java基础面试-IOC
Metabase学习教程:系统管理-6
《向量数据库指南》——亚马逊云科技向量数据库揭秘:点亮数据未来!
Vue CLI 3 - 创建我们的项目
JavaSE_Java复习基本搜索树的实现
Spark内部原理之运行原理一
语义分割笔记(三):通过opencv对mask图片来画分割对象的外接椭圆
- 原文地址:https://blog.csdn.net/u011345885/article/details/126590968