-
论文阅读【8】Conditional Random Fields: An Introduction
1.概述
1.1 论文相关
这篇论文是介绍一个经典模型,条件随机场(CRF)。在很多领域中都存在序列标注任务,例如生物信息识别,计算机语言学和语音识别任务,其中自然语言处理中的词性标注任何和命名实体识别任务就是典型的序列标注任务。
通常所用到的方法都是使用隐马尔科夫模型(HMMS)或者使用概率有限状态自动机( probabilistic finite-state automata)去做词性标注任务。HMMS是生成模型的一种形式,它定义了一个联合概率分布p(X,Y),其中X和Y分别是分布在观察序列及其相应的标签序列上的随机变量。生成模型必须枚举所有可能的观察序列——对于大多数领域来说,这一任务是难以处理的,除非观察元素被表示为孤立的单元,独立于观察序列中的其他元素。更准确地说,在任意的给定的一个时间,这些观察元素取决于当前这个状态或者标签。对于一些简单的数据集而言,这是一个合理的假设。然而,大多数真实世界的观测序列最好地表现为多重相互作用的特征和观测元素之间的长期依赖关系。1.2 动机
这种表示问题是标记顺序数据时最基本的问题之一,简而言之,一个模型支持可处理推理是非常有必要的,然而,一个表示数据不做出不合理的独立性假设的模型也是可取的。满足这两个标准的一种方法是使用一个模型,该模型在给定特定观察序列x的标签序列上定义一个条件概率p(Y |x),而不是在标签和观察序列上的联合分布。条件模型被用来标记一个新的观测序列x通过选择标签序列y这使条件概率p (y|x).这种模型的条件性质意味着,在对观察结果进行建模上不浪费任何精力,而且人们不必对这些序列做出毫无根据的独立假设;观测数据的任意属性可以被模型捕获,而建模者不必担心这些属性是如何关联的。
条件随机场(CRFs)是一个用于标记和分割顺序数据的概率框架,基于上一段中所述的有条件的方法。CRF是一种无向图形模型的形式,它在给定一个特定的观察序列的标签序列上定义了一个单一的对数线性分布。与隐马尔可夫模型相比,crf的主要优势是它们的条件性质,导致HMM所要求的独立性假设的放松,以确保可处理的推理。此外,CRFs避免了标签偏差问题,这是最大熵马尔可夫模型(MEMMs)和其他基于有向图形模型的条件马尔可夫模型所表现出的一个弱点。CRFs在许多真实世界的序列标记任务上都优于MEMM和HMM。2.算法
2.1 特征函数
给定以下定义:
x ˉ \bar{x} xˉ:表示一个时序类型的数据(sequence of abservation)
y ˉ \bar{y} yˉ:表示的是一个tags序列,这些tags可以表示词性,也可以表示一个实体标签(sequence of tags)
定义一个特征函数:如何定义一个条件概率函数去计算他们之间的关系呢?
p ( y ˉ ∣ x ˉ ; w ) = 1 z ( x ˉ , w ) e x p ∑ j = 1 J w i F j ( x ˉ , y ˉ ) p(\bar{y}|\bar{x};w)=\frac{1}{z(\bar{x},w)}exp\sum_{j=1}^{J} w_iF_j(\bar{x},\bar{y}) p(yˉ∣xˉ;w)=z(xˉ,w)1exp∑j=1JwiFj(xˉ,yˉ)
不同时序的长度不同,如果根据不通的时序,去抽取相应的特征呢?
p ( y ˉ ∣ x ˉ ; w ) = 1 z ( x ˉ , w ) e x p ∑ j = 1 J w i ∑ i = 2 n f j ( y i − 1 , y i , x ˉ , i ) p(\bar{y}|\bar{x};w)=\frac{1}{z(\bar{x},w)}exp\sum_{j=1}^{J} w_i \sum_{i=2}^{n} f_j(y_{i-1},y_i,\bar{x},i) p(yˉ∣xˉ;w)=z(xˉ,w)1exp∑j=1Jwi∑i=2nfj(yi−1,yi,xˉ,i)
这个式子就是把整个的时序拆分成了多个feature,然后再进行加权平均,这样就不管他的时长是多少,最后得到的都是一个num.
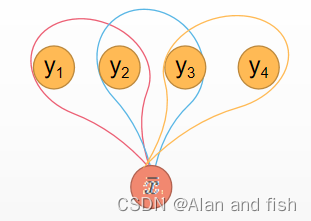
2.2 推理过程
给定参数w,观测值 x ˉ \bar{x} xˉ求助最合适的 y ˉ \bar{y} yˉ,计算过程如下
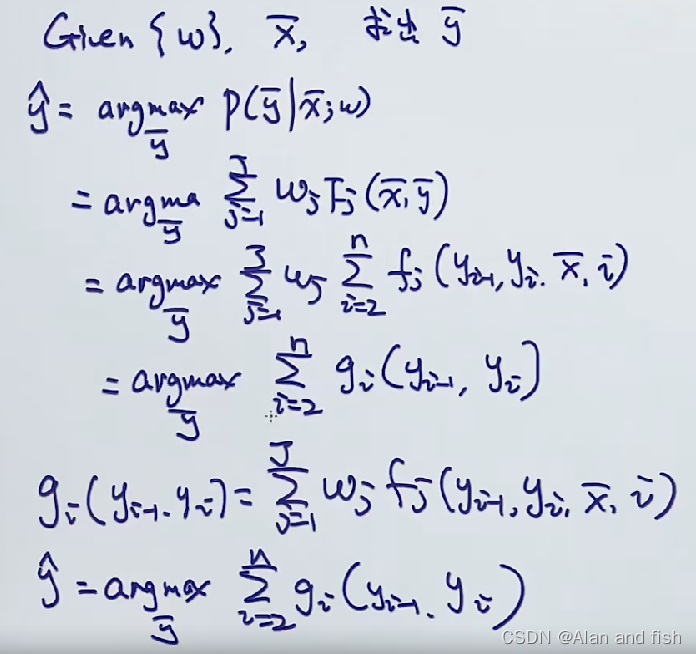
为了求解上面过程,需要使用到维特比算法:

2.3 评估模型参数w

实在学不下去了,这个计算参数w使用的是梯度下降算法,后续有空再把笔记补齐. -
相关阅读:
华为机试真题实战应用【赛题代码篇】-按照路径替换二叉树(附Java和C++代码实现)
云之后,亚马逊云科技要为业界提供水和空气一样的安全防护
操作系统 | 内存文件映射 —— 文件到内存的映射
【学习记录 time: 2022-07-21】Java8 Lambda 表达式中的 forEach 如何提前终止?
大数据ClickHouse(十):MergeTree系列表引擎之SummingMergeTree
5V升压8.4V1A,给双节锂电池充电芯片-PL7501
混合劳动力情况下需要的 3 种移动工具
【c语言】数据在内存中的存储
竞赛选题 深度学习+opencv+python实现昆虫识别 -图像识别 昆虫识别
如何借助问答平台上做好网络营销?
- 原文地址:https://blog.csdn.net/qq_35653657/article/details/127993150