-
四十九、Hadoop HA部署(MINI版)
环境准备:
编号
主机名
类型
用户
密码
1
master1-1
主节点
root
passwd
2
slave1-1
从节点
root
passwd
3
slave1-2
从节点
root
passwd
注:提取码均为: 0000
机器检查:
1、输入用户名及登录密码进行登录

2、检查内网是否畅通
A、查看机器IP地址
ip addr- 1

注:通过观察此台机器IP为192.168.231.244
B、测试内网



注:通过观察机器内网畅通
C、测试外网

注:通过观察此台机器外网畅通
注:三台机器分别进行检查,网络配置无误
静态IP配置:
1、查看各台机器IP地址
ip addr- 1
2、编辑ifcfg-ens33网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33- 1

注:BOOTPROTO的值更改为static,加入最下面五行内容,分别为:IP,子网掩码,网关,DNS1,DNS2 其余配置勿进行更改
提示:IP地址要与网关处于同一网段内,DNS1与网关相同即可,子网掩码,DNS2照搬即可
3、重启网络
service network restart- 1
4、进行内网与外网的检查
ping 192.168.231.244 ping www.baidu.com- 1
- 2
- 3
此处笔者IP为:
主机名
IP
master1-1
192.168.231.244
slave1-1
192.168.231.245
slave1-2
192.168.231.246
环境部署:
一、解压 JDK 安装包到“/usr/local/src”路径,并配置环境变量;截取环境变量配置文件截图
1、关闭防火墙 和关闭防火墙自启
systemctl stop firewalld.service systemctl disable firewalld.service- 1
- 2
- 3
注:三台机器全部都要关闭防火墙 和 自启
2、进入 /h3cu/ 目录

3、解压 jdk 到 /usr/local/src
tar -zxvf jdk1.8.0_221.tar.gz -C /usr/local/src/- 1
4、配置环境变量
vi /etc/profile- 1

二、在指定目录下安装ssh服务,查看ssh进程并截图(安装包统一在“/h3cu/”)
1、查看是否已安装ssh服务
rpm -qa | grep ssh- 1

注:如有这些包,说明ssh服务已安装
2、使用yum进行安装ssh服务
yum -y install openssh openssh-server- 1
3、查看ssh进程
ps -ef | grep ssh- 1

三、创建 ssh 密钥,实现主节点与从节点的无密码登录;截取主节点登录其中一个从节点的结果
1、在指定目录下生成密钥对
ssh-keygen -t rsa- 1

注:依次在系统等待输入时敲入回车键(一共4次回车)后,即可生成密钥对
2、分发公匙文件
ssh-copy-id 192.168.231.244 ssh-copy-id 192.168.231.245 ssh-copy-id 192.168.231.246- 1
- 2
- 3
注:此为例图,需要免密登录的机器全部都要分发
3、主节点免密登录从节点

四、根据要求修改每台主机 host 文件,截取“/etc/hosts”文件截图

注:此处需注意,三台机器的hosts文件全部都要修改
五、修 改 每 台 主 机 hostname 文 件 配 置 IP 与 主 机 名 映 射 关 系 ; 截 取 “/etc/hostname”文件截图
三台电脑分别设置主机名
hostnamectl set-hostname master1-1 hostnamectl set-hostname slave1-1 hostnamectl set-hostname slave1-2- 1
- 2
- 3



六、在主节点和从节点修改 Hadoop 环境变量,并截取修改内容
1、修改Hadoop环境变量
vi /etc/profile- 1

七、需安装 Zookeeper 组件具体要求同 Zookeeper 任务要求,并与 Hadoop HA 环境适配
1、解压zookeeper
tar -zxvf /h3cu/zookeeper-3.4.8.tar.gz -C /usr/local/src/- 1
2、重命名
mv /usr/local/src/zookeeper-3.4.8 /usr/local/src/zookeeper- 1
3、进入zookeeper/conf目录下
cd /usr/local/src/zookeeper/conf- 1
4、重命名zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg- 1
5、修改zoo.cfg配置文件
vi zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 clientPort=2181 dataDir=/usr/local/src/zookeeper/data dataLogDir=/usr/local/src/zookeeper/logs server.1=master1-1:2888:3888 server.2=slave1-1:2888:3888 server.3=slave1-2:2888:3888- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6、创建ZooKeeper 的数据存储与日志存储目录
mkdir /usr/local/src/zookeeper/data mkdir /usr/local/src/zookeeper/logs- 1
- 2
7、创建myid文件并写入内容:1
vi /usr/local/src/zookeeper/data/myid- 1
8、添加zookeeper环境变量
vi /etc/profile export ZK_HOME=/usr/local/src/zookeeper export PATH=$PATH:$ZK_HOME/bin- 1
- 2
- 3
- 4
9、集群分发
scp -r /etc/profile slave1-1:/etc/profile scp -r /etc/profile slave1-2:/etc/profile scp -r /usr/local/src/zookeeper slave1-1:/usr/local/src/ scp -r /usr/local/src/zookeeper slave1-2:/usr/local/src/- 1
- 2
- 3
- 4
- 5
- 6
- 7
10、修改slave1-1 和 slave1-2的myid文件分别为2 ,3
vi /usr/local/src/zookeeper/data/myid- 1
八、修改 namenode、datanode、journalnode 等存放数据的公共目录为 /usr/local/hadoop/tmp
1、解压安装Hadoop
tar -zxvf /h3cu/hadoop-2.7.1.tar.gz -C /usr/local/- 1
2、重命名Hadoop
mv /usr/local/hadoop-2.7.1 /usr/local/hadoop- 1
3、进入hadoop配置文件目录
cd /usr/local/hadoop/etc/hadoop- 1
4、配置hadoop-env.sh文件

5、配置core-site.xml文件
fs.defaultFS hdfs://mycluster hadoop.tmp.dir /usr/local/hadoop/tmp ha.zookeeper.quorum master1-1:2181,slave1-1:2181,slave1-2:2181 ha.zookeeper.session-timeout.ms 30000 ms fs.trash.interval 1440 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6、配置hdfs-site.xml文件
dfs.qjournal.start-segment.timeout.ms 60000 dfs.nameservices mycluster dfs.ha.namenodes.mycluster master1-1,slave1-1 dfs.namenode.rpc-address.mycluster.master1-1 master1-1:9000 dfs.namenode.rpc-address.mycluster.slave1-1 slave1-1:9000 dfs.namenode.http-address.mycluster.master1-1 master1-1:50070 dfs.namenode.http-address.mycluster.slave1-1 slave1-1:50070 dfs.namenode.shared.edits.dir qjournal://master1-1:8485;slave1-1:8485;slave1-2:8485/mycluster dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence shell(/bin/true) dfs.permissions.enabled false dfs.support.append true dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.replication 2 dfs.namenode.name.dir /usr/local/hadoop/tmp/name dfs.datanode.data.dir /usr/local/hadoop/tmp/data dfs.journalnode.edits.dir /usr/local/hadoop/tmp/journal dfs.ha.automatic-failover.enabled true dfs.webhdfs.enabled true dfs.ha.fencing.ssh.connect-timeout 30000 ha.failover-controller.cli-check.rpc-timeout.ms 60000 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
7、配置mapred-site.xml文件
A、拷贝mapred-site.xml.template重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml- 1
B、编辑文件
vi mapred-site.xmlmapreduce.framework.name yarn mapreduce.jobhistory.address master1-1:10020 mapreduce.jobhistory.webapp.address master1-1:19888 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
8、配置yarn-site.xml文件
yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id yrc yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 master1-1 yarn.resourcemanager.hostname.rm2 slave1-1 yarn.resourcemanager.zk-address master1-1:2181,slave1-1:2181,slave1-2:2181 yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 86400 yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
9、创建tmp , logs, tmp/下创建name,data,journal目录
mkdir /usr/local/hadoop/tmp mkdir /usr/local/hadoop/logs mkdir /usr/local/hadoop/tmp/journal mkdir /usr/local/hadoop/tmp/data mkdir /usr/local/hadoop/tmp/name- 1
- 2
- 3
- 4
- 5
10、配置hadoop/etc/hadoop/slaves文件
master1-1 slave1-1 slave1-2- 1
- 2
- 3
11、分发jdk和hadoop文件
scp -r /usr/local/src/jdk1.8.0_221/ slave1-1:/usr/local/src/ scp -r /usr/local/src/jdk1.8.0_221/ slave1-2:/usr/local/src/ scp -r /usr/local/hadoop slave1-1:/usr/local/ scp -r /usr/local/hadoop slave1-2:/usr/local/- 1
- 2
- 3
- 4
12、确保3台机器的环境变量已经生效
source /etc/profile- 1
注:三台机器全部进行source即时生效
九、根据要求修改 Hadoop 相关文件,并初始化 Hadoop,截图初始化结果
1、启动zookeeper集群并查看状态
进入zookeeper安装目录下
bin/zkServer.sh start bin/zkServer.sh status- 1
- 2
- 3
注:三台机器都要启动
2、初始化HA在zookeeper中的状态
进入hadoop安装目录下
bin/hdfs zkfc -formatZK- 1
3、启动全部机器的 journalnode 服务
进入/usr/local/hadoop安装目录下
sbin/hadoop-daemon.sh start journalnode- 1
注:三台机器全部启动journalnode进程
4、初始化namenode
进入hadoop/bin目录下
hdfs namenode -format- 1

注:观察是否有报错信息,status是否为0,0即为初始化成功,1则报错,检查配置文件是否有误
十、启动 Hadoop,使用相关命令查看所有节点 Hadoop 进程并截图
1、启动hadoop所有进程
进入hadoop安装目录下
sbin/start-all.sh- 1


注:三台机器使用 ps -ef 命令查看进程
十一、本题要求配置完成后在 Hadoop 平台上运行查看进程命令,要求运行结果的截屏保存



注:三台机器使用 jps 命令查看hadoop 进程
十二、格式化主从节点
1、复制 namenode 元数据到其它节点
scp -r /usr/local/hadoop/tmp/* slave1-1:/usr/local/hadoop/tmp/ scp -r /usr/local/hadoop/tmp/* slave1-2:/usr/local/hadoop/tmp/- 1
- 2
- 3

注:由于之前namenode,datanode,journalnode的数据全部存放在hadoop/tmp目录下,所以直接复制 tmp 目录至从节点
十三、启动两个 resourcemanager 和 namenode
1、在slave1-1节点启动namenode和resourcemanager进程
进入hadoop安装目录
sbin/yarn-daemon.sh start resourcemanager sbin/hadoop-daemon.sh start namenode- 1
- 2
- 3
十四、使用查看进程命令查看进程,并截图(要求截取主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存(要求截到 url 状态)

1、配置windows中的hosts文件
A、进入C:WindowsSystem32driversetc目录下找到hosts文件
B、更改hosts文件的属性,使其可以修改内容
C、最后加入
192.168.231.244 master1-1 master1-1.centos.com 192.168.231.245 slave1-1 slave1-1.centos.com 192.168.231.246 slave1-2 slave1-2.centos.com- 1
- 2
- 3
更改前

更改后

修改hosts文件拒绝访问参考:
2、在浏览访问两个 namenode 和 resourcemanager web 界面
namenode web界面:
地址栏输入master1-1:50070 如图所示

地址栏输入slave1-1:50070 如图所示

resourcemanager web 界面:

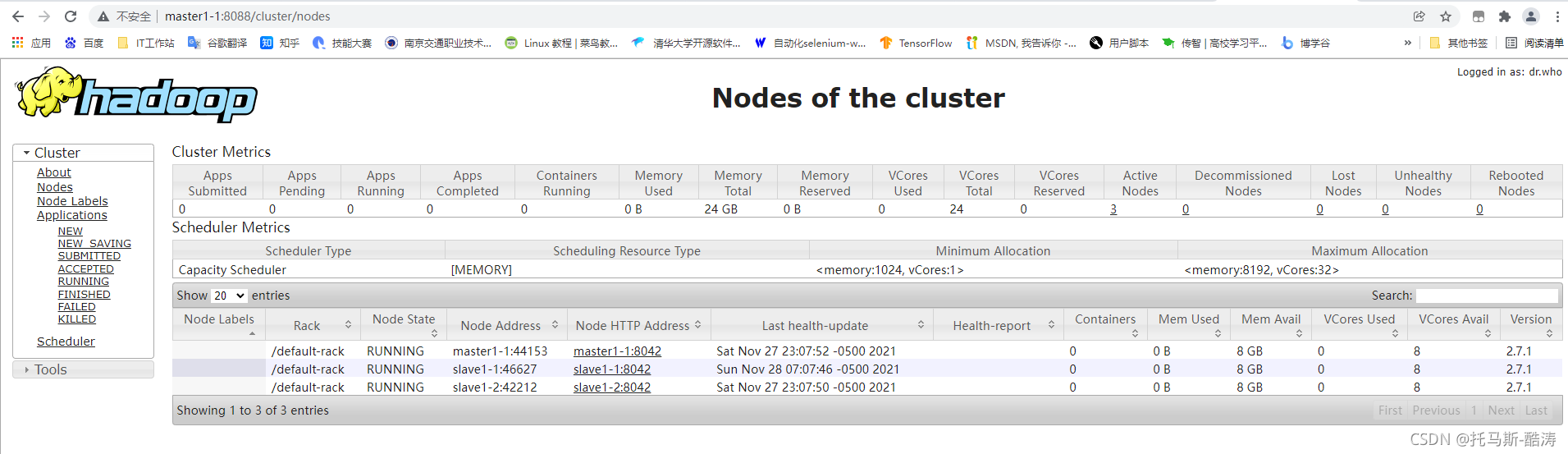
注:点击左方Nodes可以看到当前存在的节点
十五、终止 active 的 namenode 进程,并使用 Jps 查看各个节点进程,(截上主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存 (要求截到 url 和状态)
1、终止活跃状态的namenode
kill -9 (namenode进程号)- 1






十六、重启刚才终止的 namenode,并查看 jps 进程,截图访问两个 namenode 的 web 界面,并截图保存
sbin/hadoop-daemon.sh start namenode- 1



Hadoop HA部署(MINI版)完成
不能打败你的必将使你愈发强大!
-
相关阅读:
Windows专业版的Docker下载、安装与启用Kubenetes、访问Kubernetes Dashboard
maven工程打包引入本地jar包
星河AI网络,大模型纪元的运力答案
项目1-PM2.5预测
Spring IOC源码:registerBeanPostProcessors 详解
开源项目丨Taier1.2版本发布,新增工作流、租户绑定简化等多项功能
Java简单实现图片上传与下载
Linux权限
OpenCV入门(C++/Python)- 使用OpenCV标注图像(六)
pytest + yaml 框架 -4.用例参数化parameters功能实现
- 原文地址:https://blog.csdn.net/m0_67393686/article/details/126565409