-
【MySQL从0到1】第五篇:表的增删查改
文章目录
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
一、Create
语法:
INSERT [INTO] table_name [(column [, column] ...)] VALUES (value_list) [, (value_list)] ... value_list: value, [, value] ...- 1
- 2
- 3
- 4
- 5
案例:
1.1 单行数据 + 全列插入

1.2 多行数据 + 指定列插入

1.3 插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
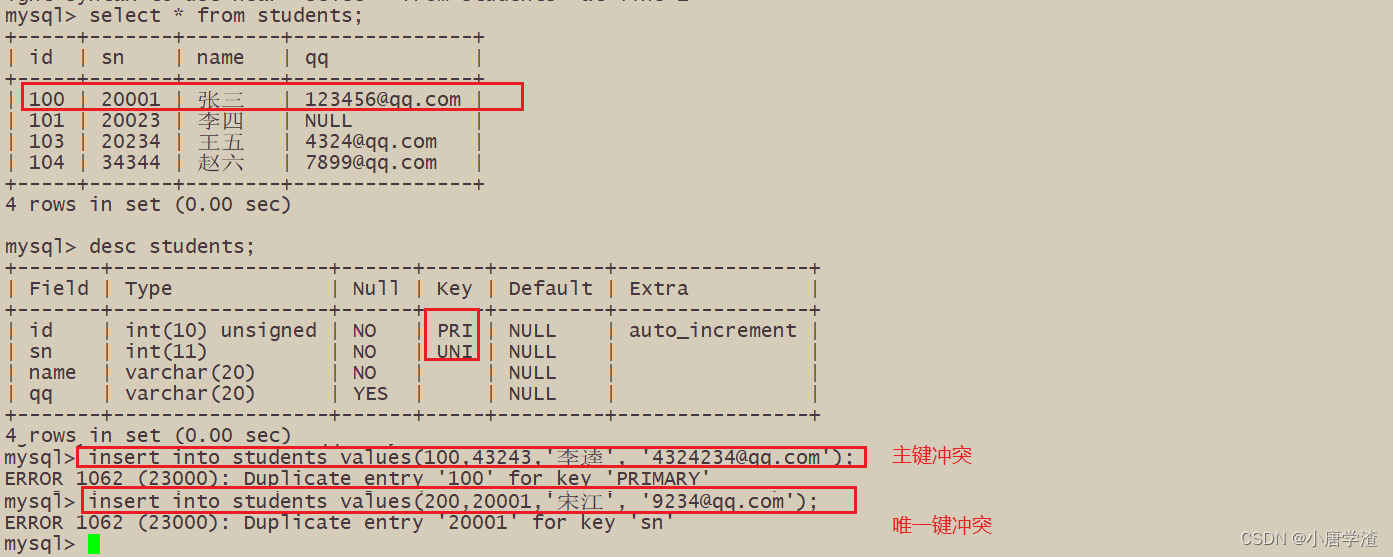
可以选择性的进行同步更新操作 语法:INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ... ON DUPLICATE KEY 当发生重复key的时候```- 1
- 2
- 3
- 4
- 5
– 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
– 1 row affected: 表中没有冲突数据,数据被插入
– 2 row affected: 表中有冲突数据,并且数据已经被更新1.4 替换
– 主键 或者 唯一键 没有冲突,则直接插入;
– 主键 或者 唯一键 如果冲突,则删除后再插入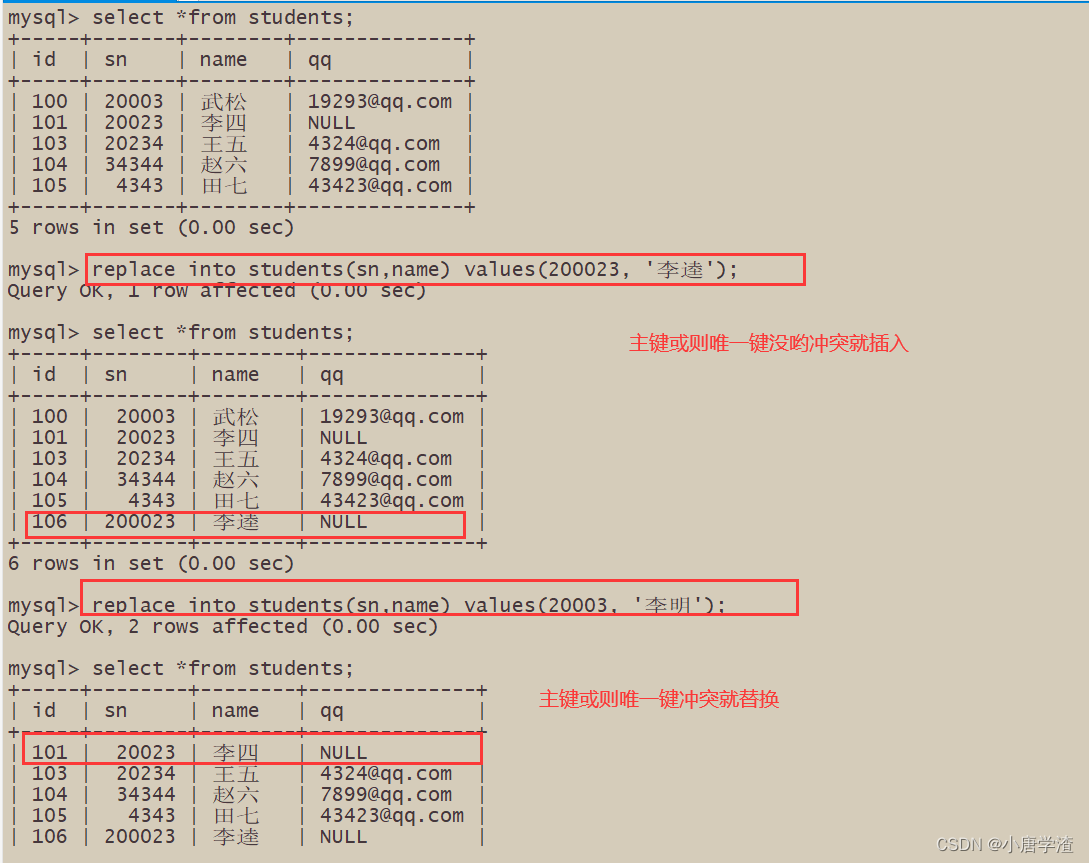
二、Retrieve
语法:
SELECT [DISTINCT] {* | {column [, column] ...} [FROM table_name] [WHERE ...] [ORDER BY column [ASC | DESC], ...] LIMIT ...- 1
- 2
- 3
- 4
- 5
- 6
案例:
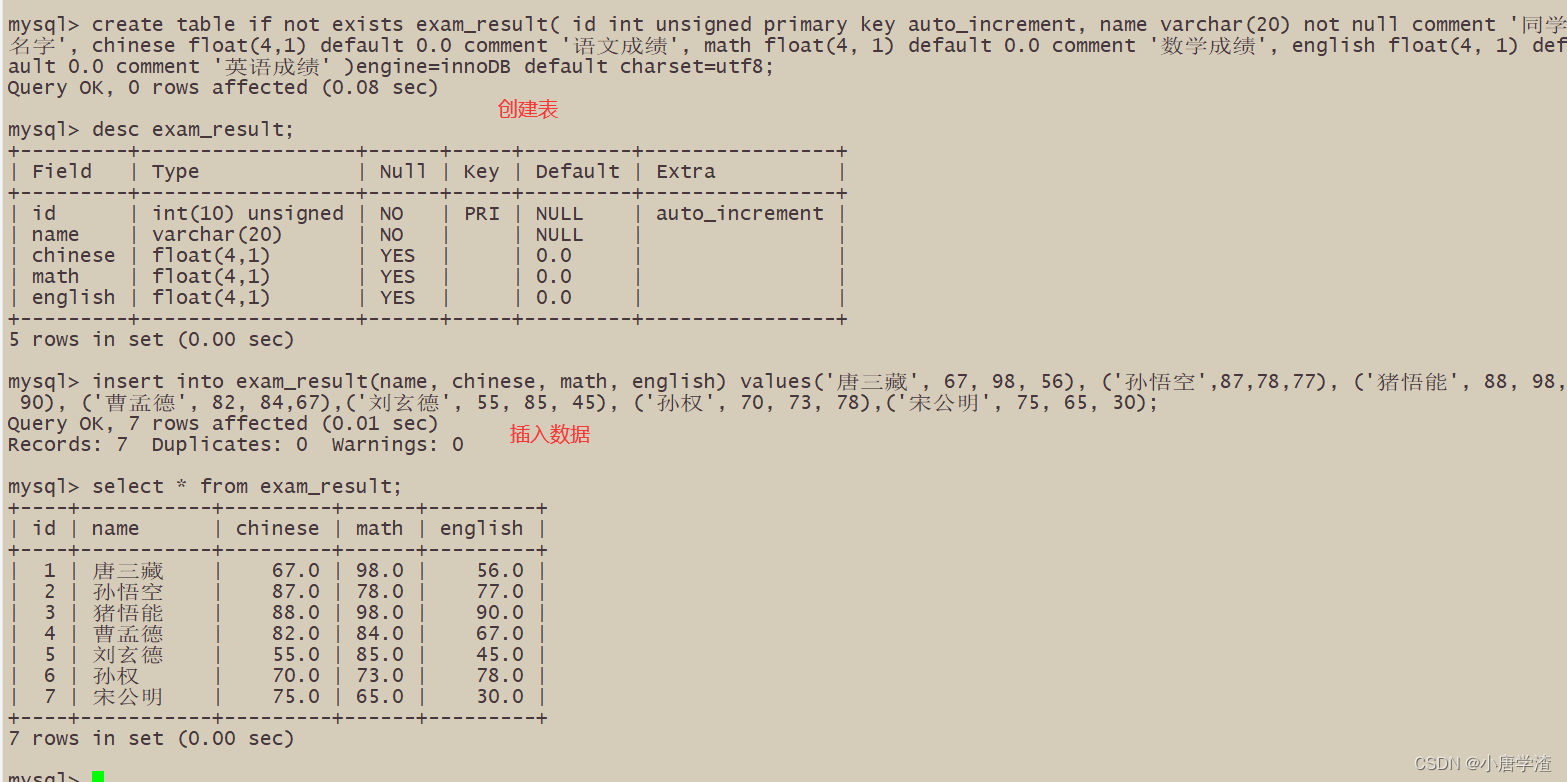
2.1 SELECT 列
2.1.1 全列查询
– 通常情况下不建议使用 * 进行全列查询
– 1. 查询的列越多,意味着需要传输的数据量越大;
– 2. 可能会影响到索引的使用。(索引待后面讲解)
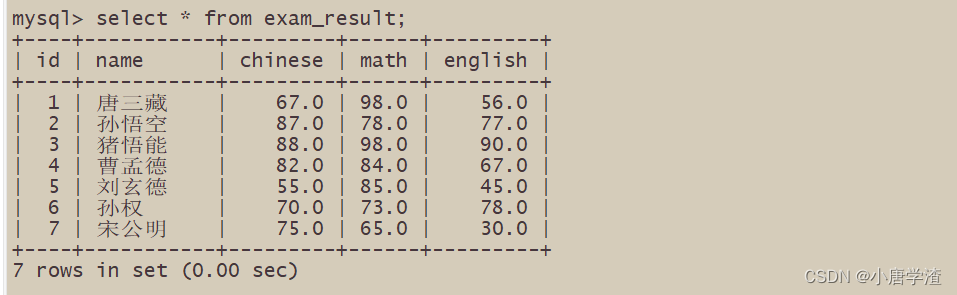
2.1.2 指定列查询
– 指定列的顺序不需要按定义表的顺序来

2.1.3 查询字段为表达式
– 表达式不包含字段
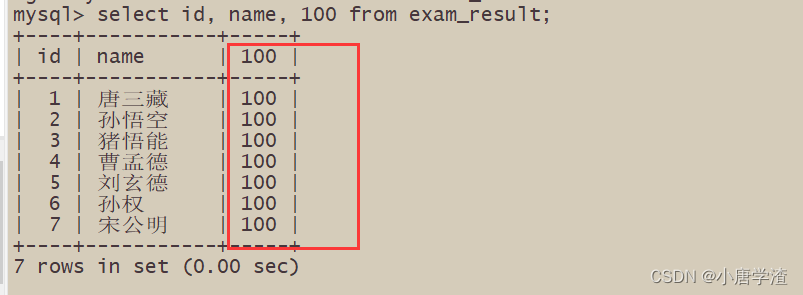
– 表达式包含一个字段

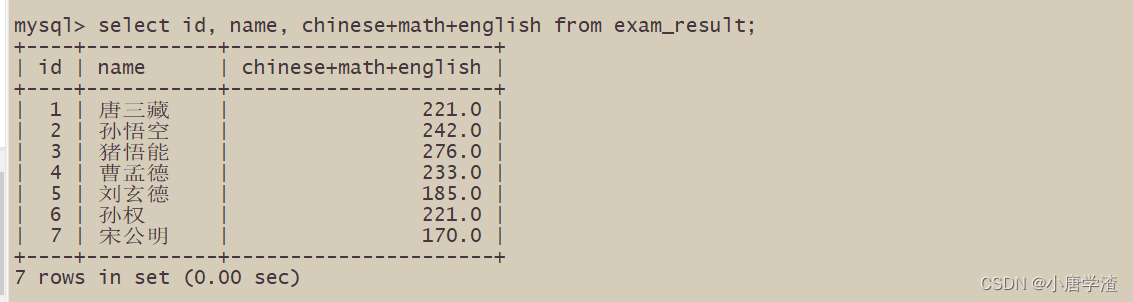
– 表达式包含多个字段
2.1.4 为查询结果指定别名
语法:
- SELECT column [AS] alias_name […] FROM table_name;

2.1.5 结果去重
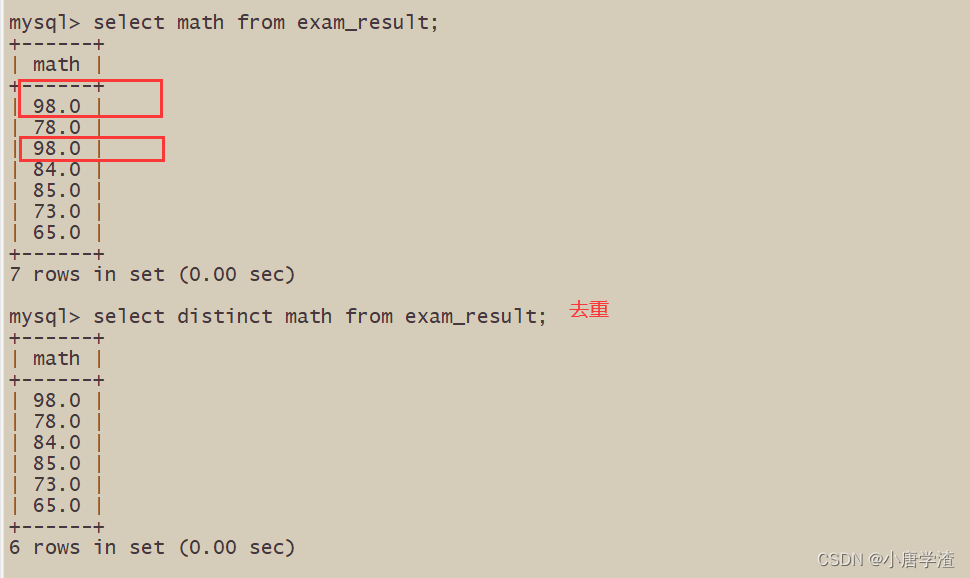
2.2 WHERE 条件
比较运算符:
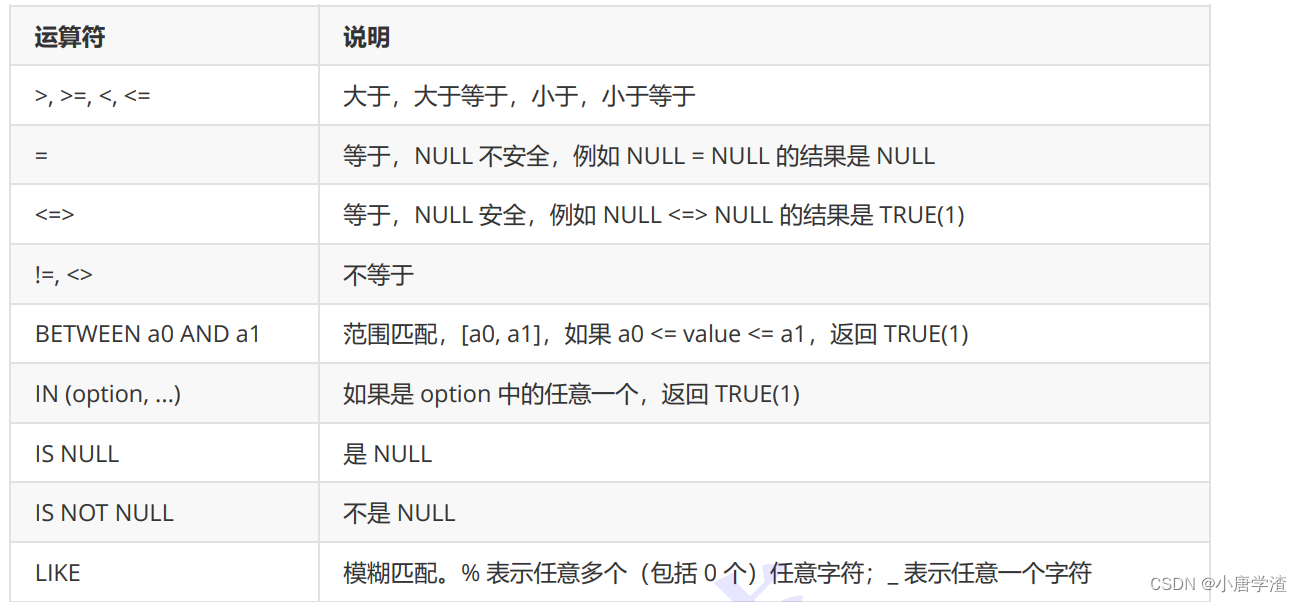
逻辑运算符:运算符 说明 AND 多个条件必须都为 TRUE(1),结果才是 TRUE(1) OR 任意一个条件为 TRUE(1), 结果为 TRUE(1) NOT 条件为 TRUE(1),结果为 FALSE(0) 案例:
2.2.1 英语不及格的同学及英语成绩 ( < 60 )

2.2.2 语文成绩在 [80, 90] 分的同学及语文成绩
– 使用 AND 进行条件连接

– 使用 BETWEEN … AND … 条件

2.2.3 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
– 使用 OR 进行条件连接
– 使用 IN 条件
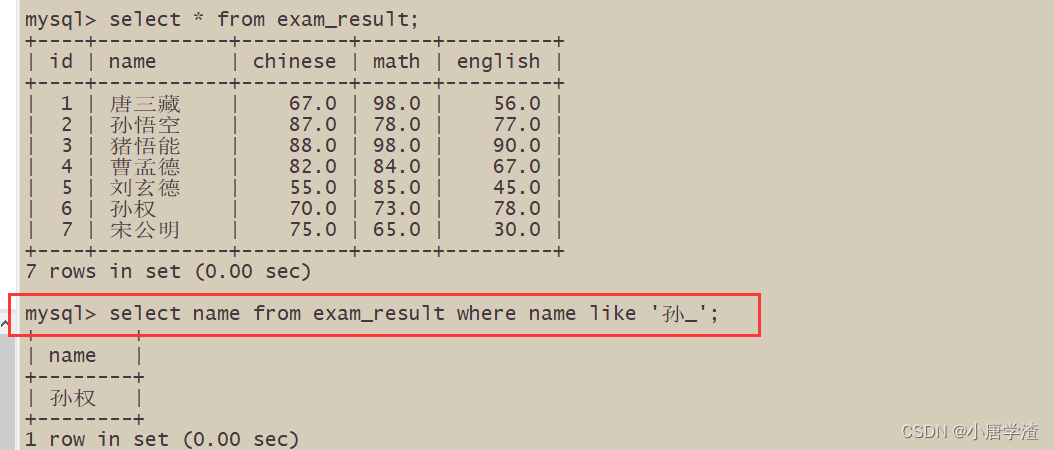
2.2.4 姓孙的同学 及 孙某同学
– % 匹配任意多个(包括 0 个)任意字符

– _ 匹配严格的一个任意字符
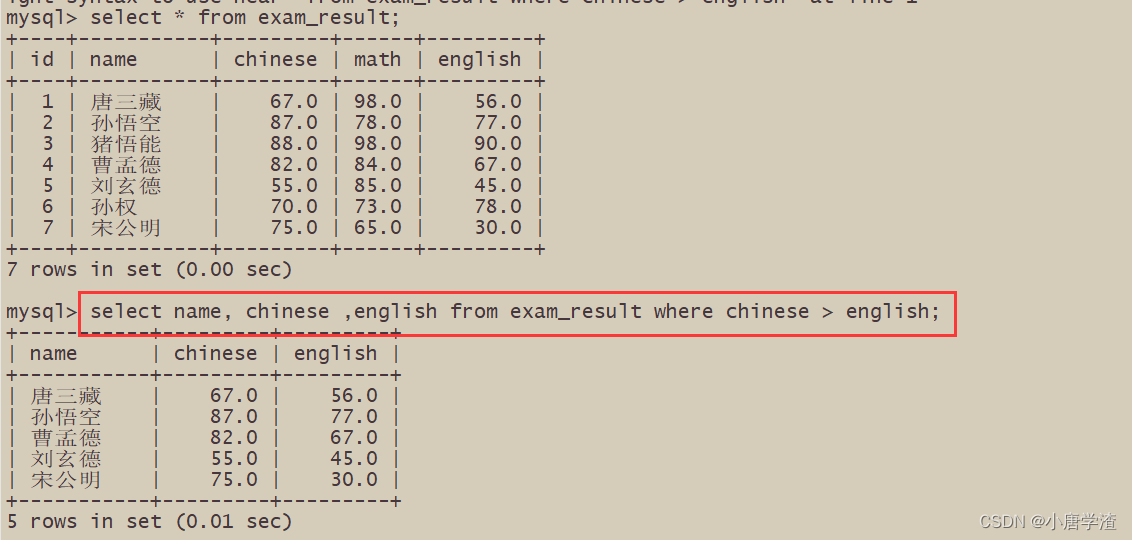
2.2.5 语文成绩好于英语成绩的同学
– WHERE 条件中比较运算符两侧都是字段
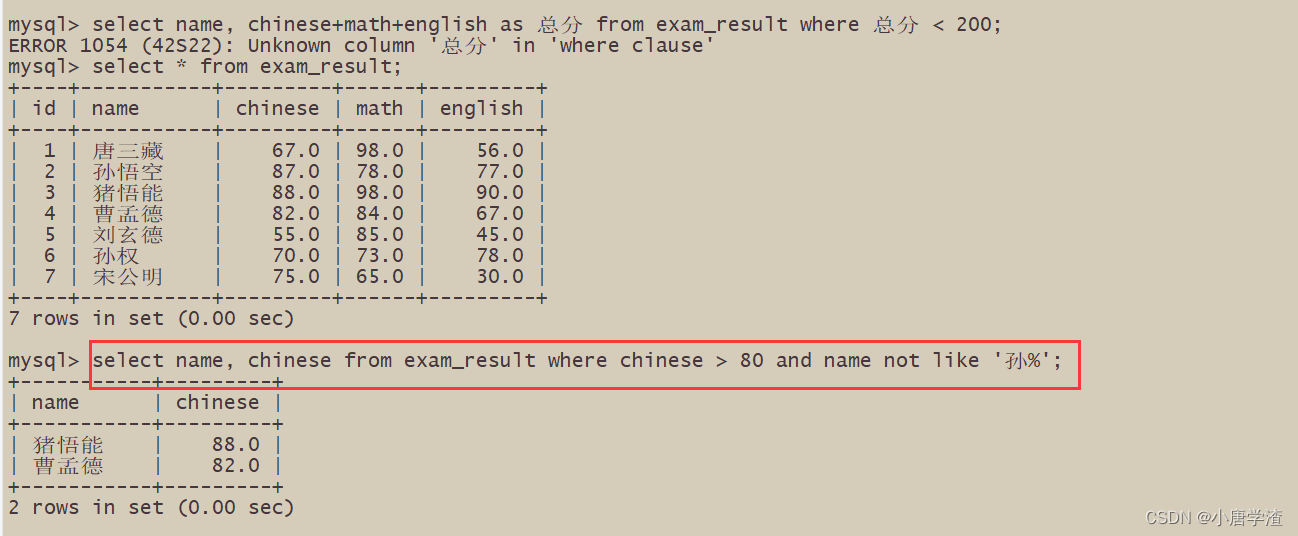
2.2.6 总分在 200 分以下的同学
– WHERE 条件中使用表达式
– 别名不能用在 WHERE 条件中

2.2.7 语文成绩 > 80 并且不姓孙的同学
– AND 与 NOT 的使用
2.2.8 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
– 综合性查询

2.2.9 NULL 的查询
– 查询 students 表

– NULL 和 NULL 的比较,= 和 <=> 的区别

<=>可以用来null比较,<=!> ,=不可以用来null比较,所以建议比较null的时候用is not null和is null。2.3 结果排序
语法:
-- ASC 为升序(从小到大) -- DESC 为降序(从大到小) -- 默认为 ASC SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];- 1
- 2
- 3
- 4
- 5
- 6
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
案例:2.3.1 同学及数学成绩,按数学成绩升序显示
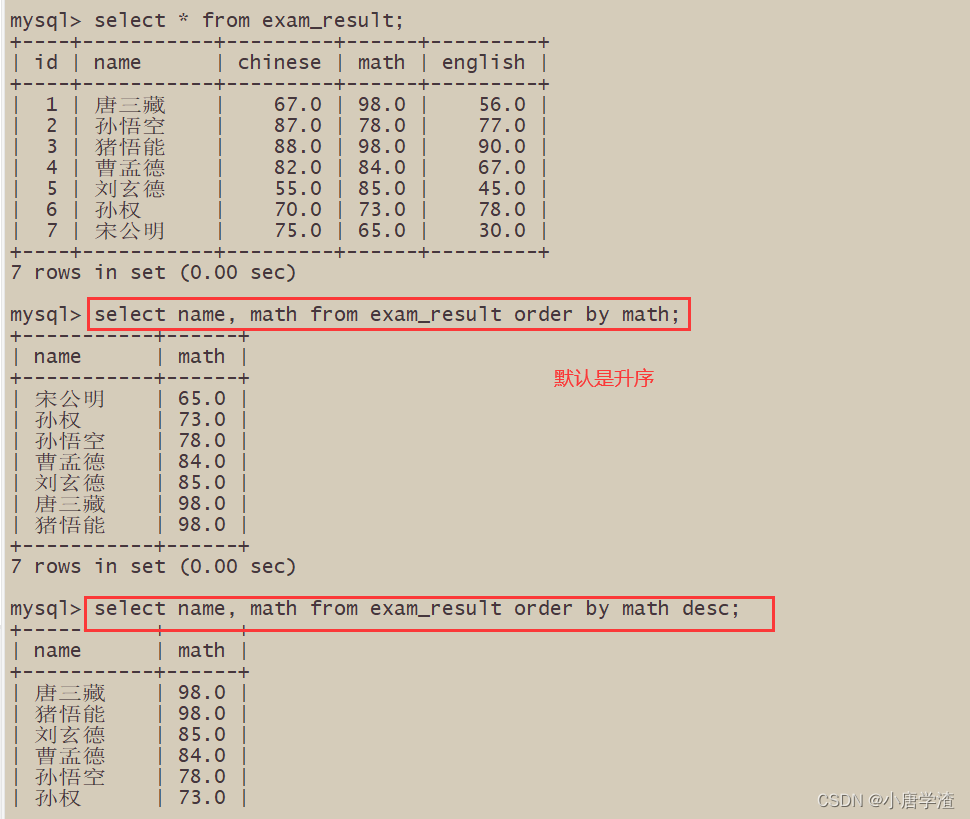
ascending order–升序
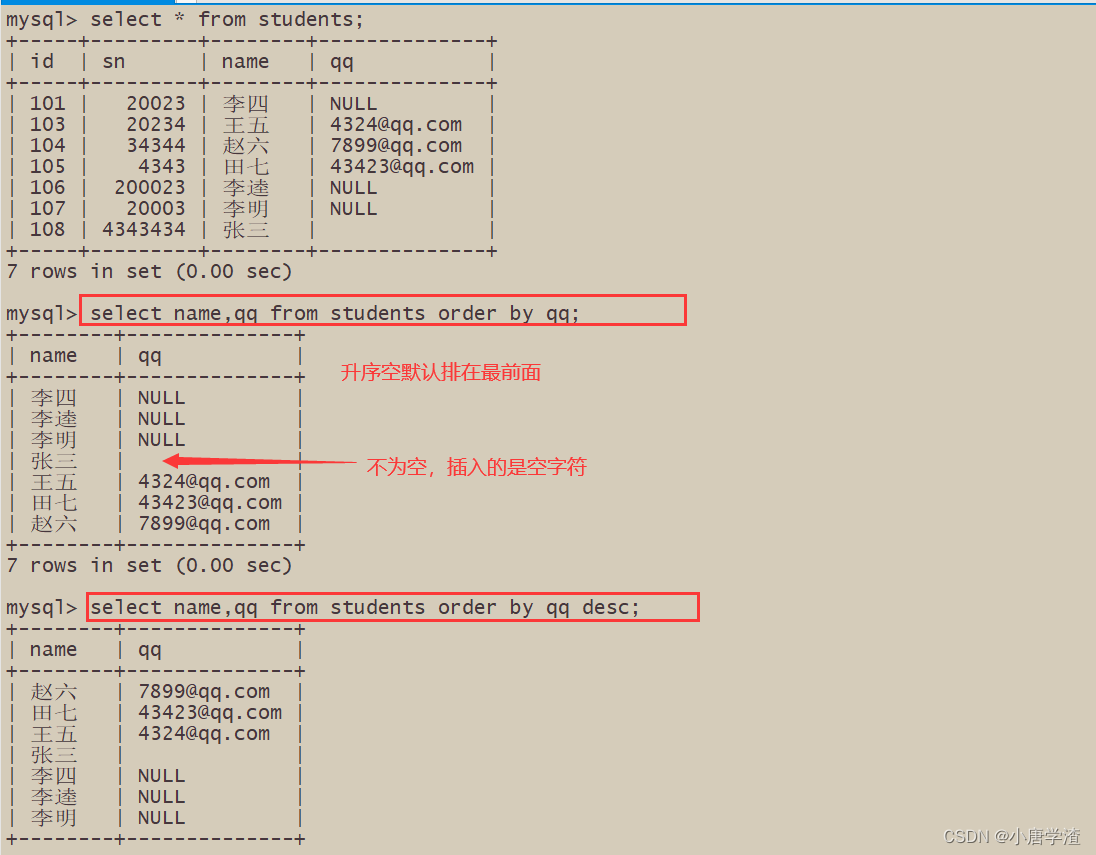
Descending–降序2.3.2 同学及 qq 号,按 qq 号排序显示
NULL 视为比任何值都小,升序出现在最上面,降序出现在最下面
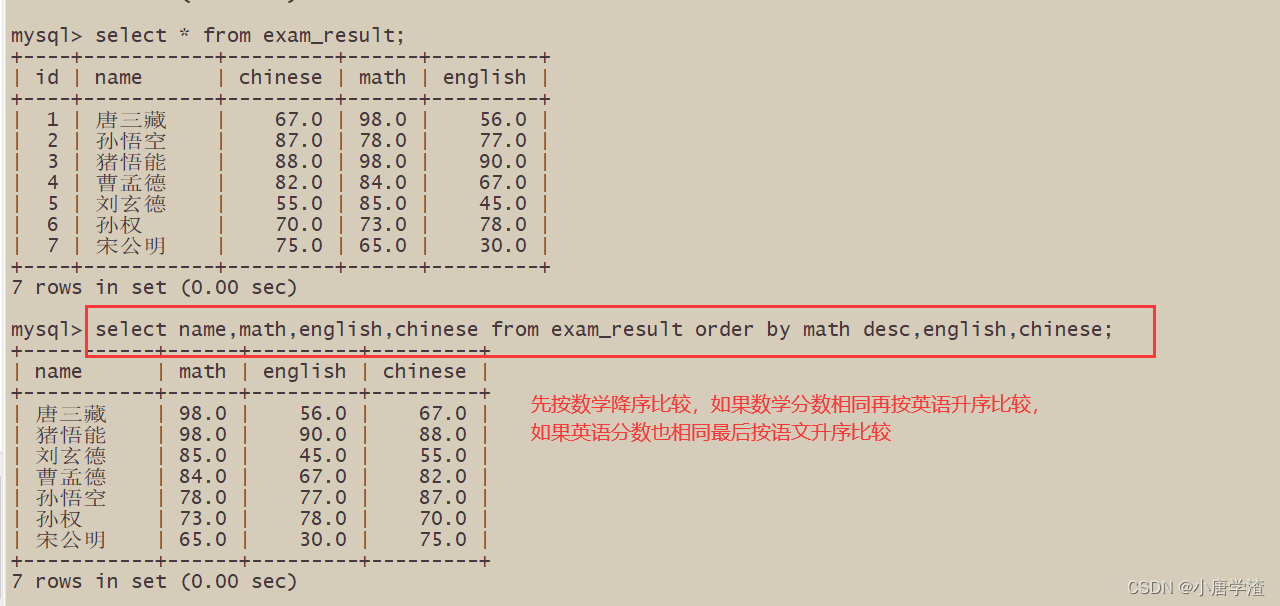
2.3.3 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
– 多字段排序,排序优先级随书写顺序
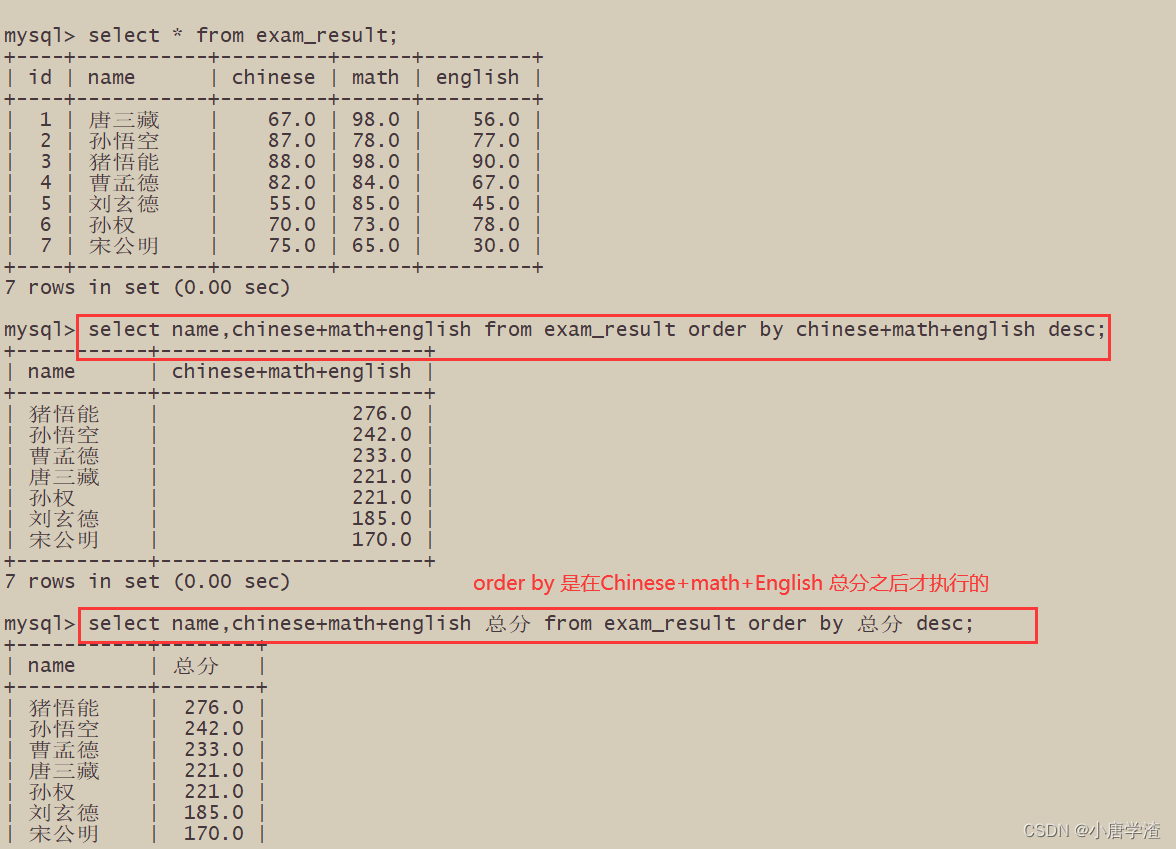
2.3.4 查询同学及总分,由高到低
– ORDER BY 中可以使用表达式
2.3.5 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
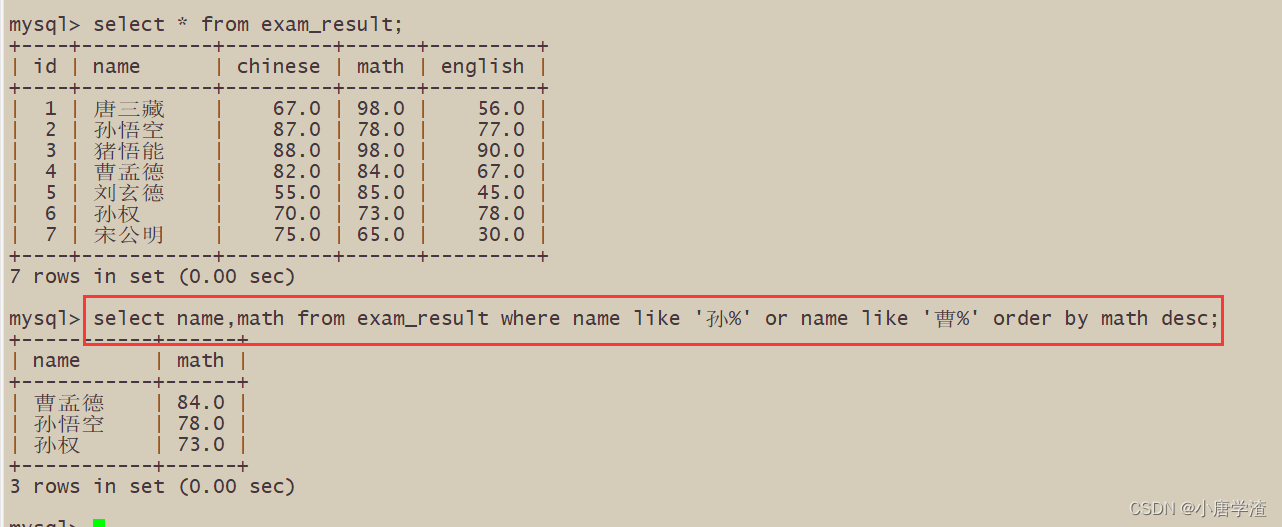
2.4 筛选分页结果
语法:
-- 起始下标为 0 -- 从 0 开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n; -- 从 s 开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n; -- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
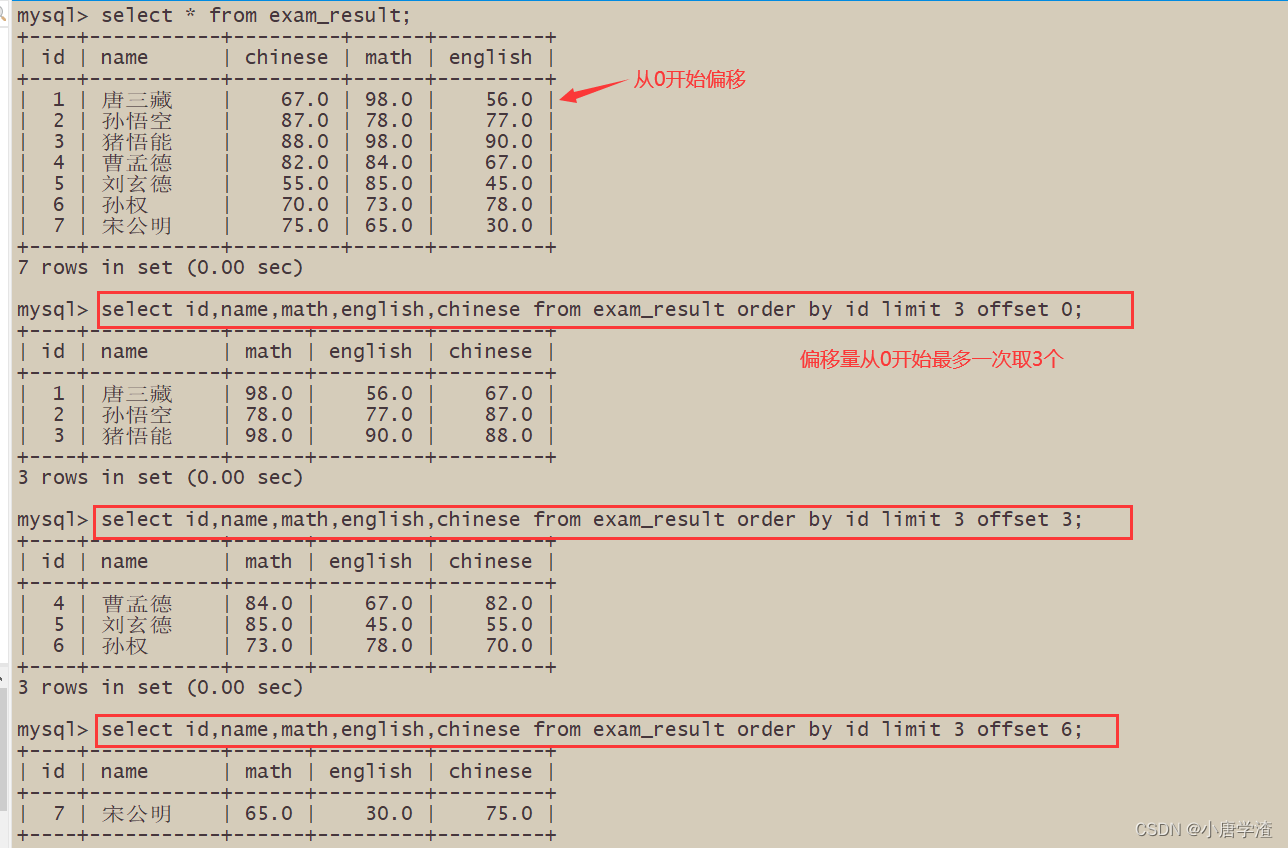
三、Update
语法:
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]- 1
- 2
对查询到的结果进行列值更新
案例:3.1 将孙悟空同学的数学成绩变更为 80 分
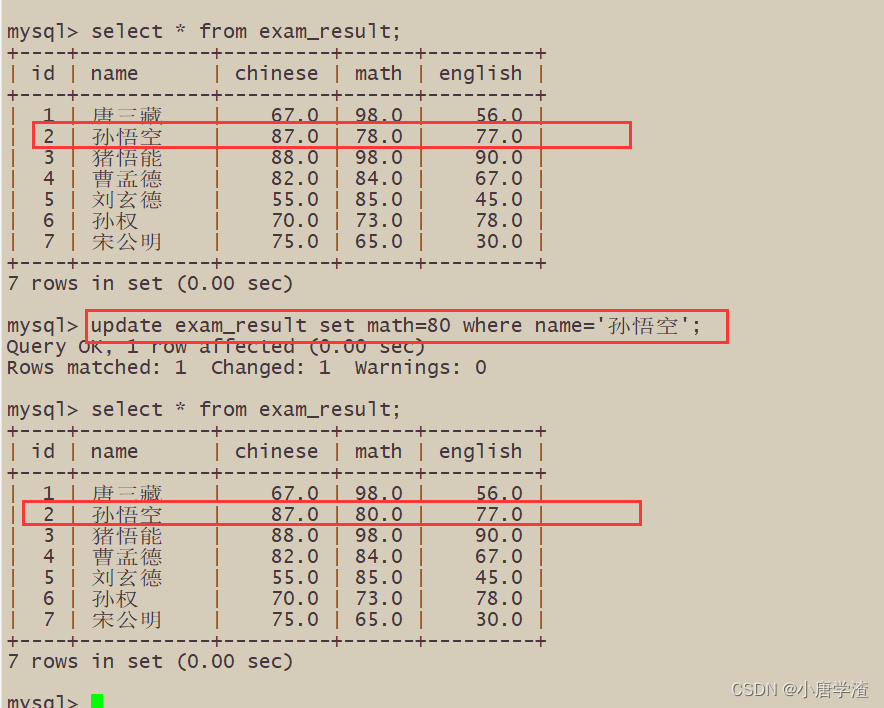
3.2 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分

3.3 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
- 数据更新,不支持 math += 30 这种语法

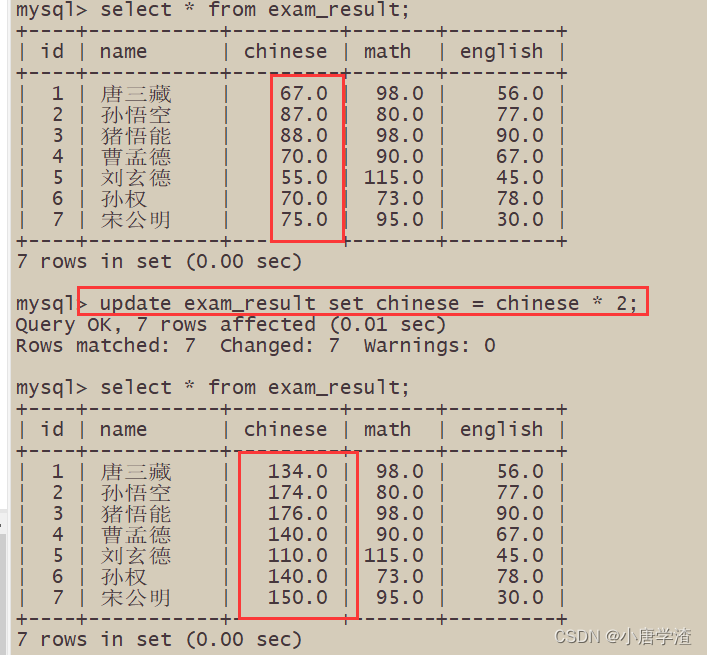
3.4 将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用
四、 Delete
4.1 删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]- 1
案例:
4.1.1 删除孙悟空同学的考试成绩
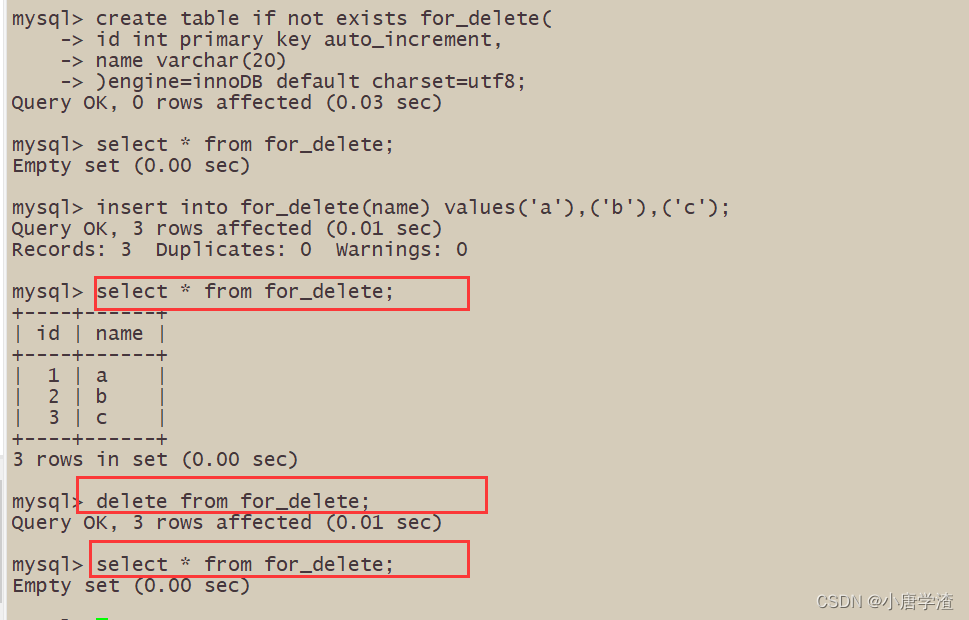
4.1.2 删除整张表数据
注意:删除整表操作要慎用!
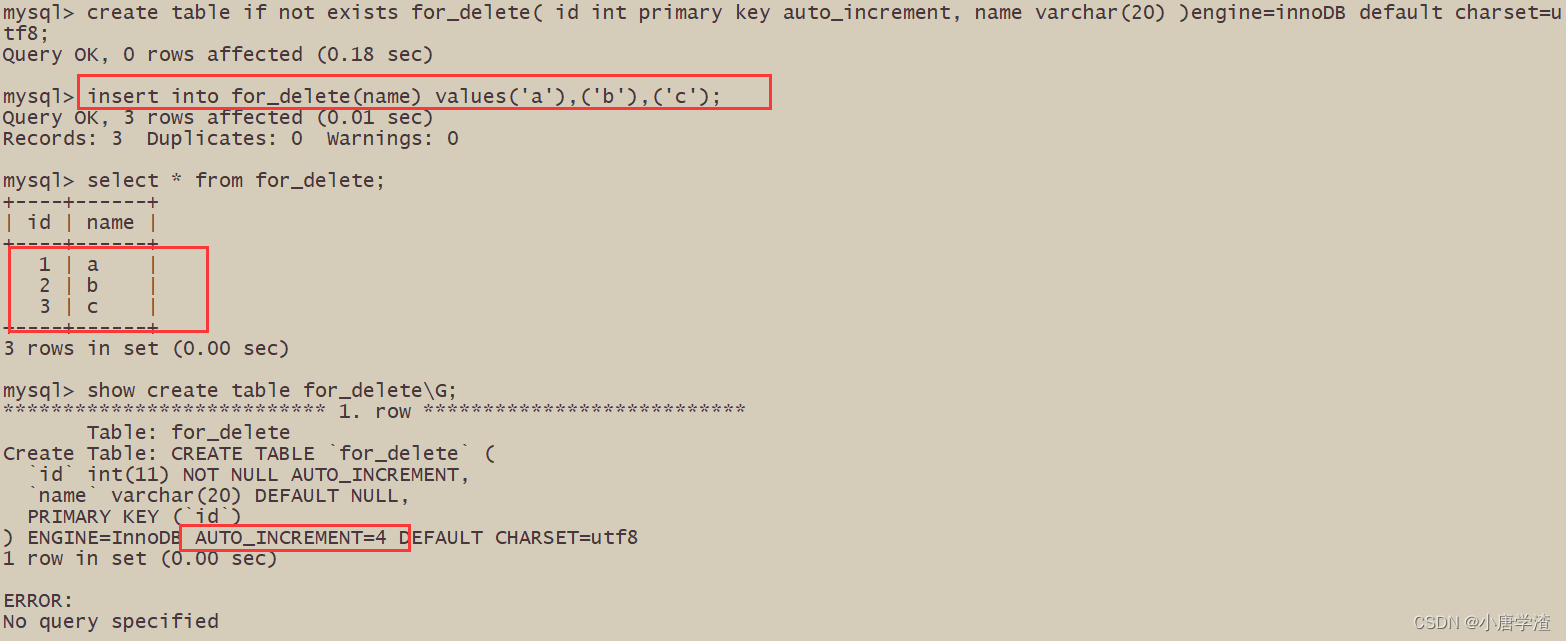
4.2 截断表
语法:
TRUNCATE [TABLE] table_name- 1
注意:这个操作慎用
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
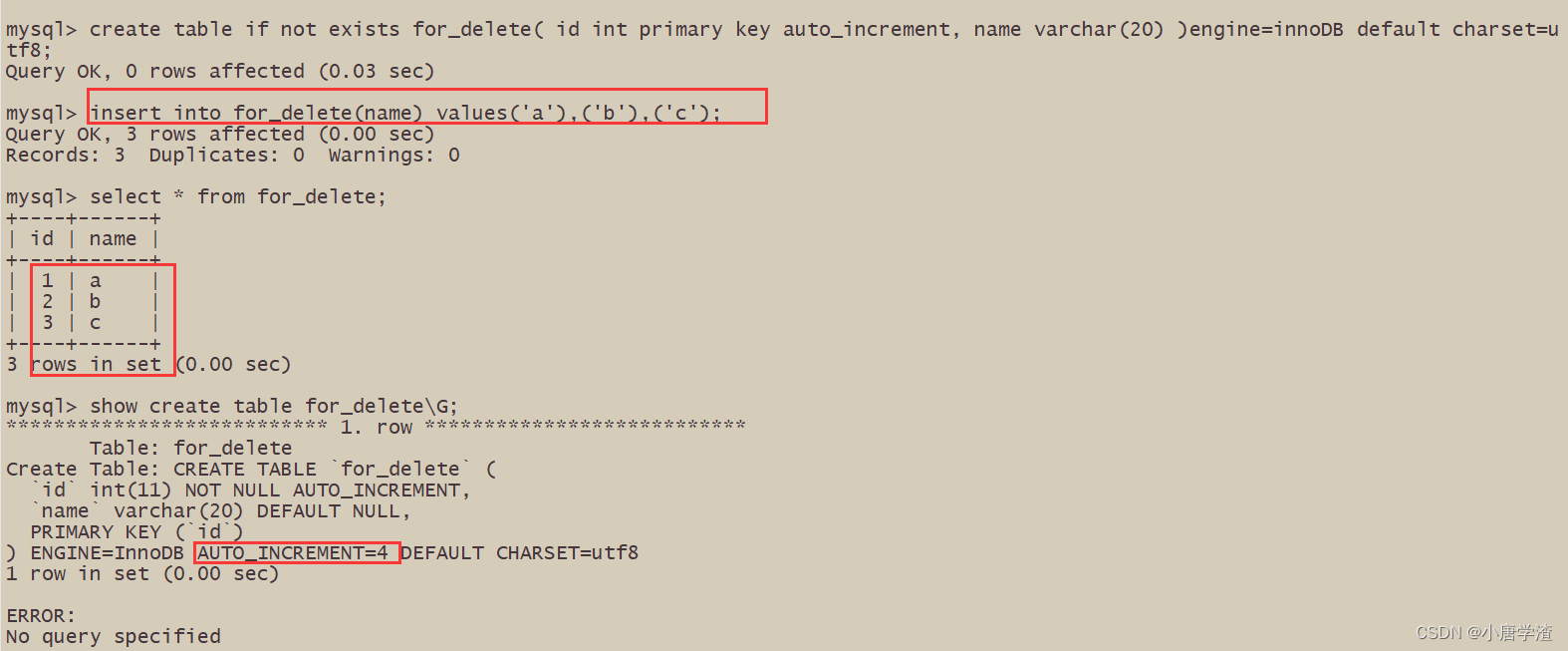
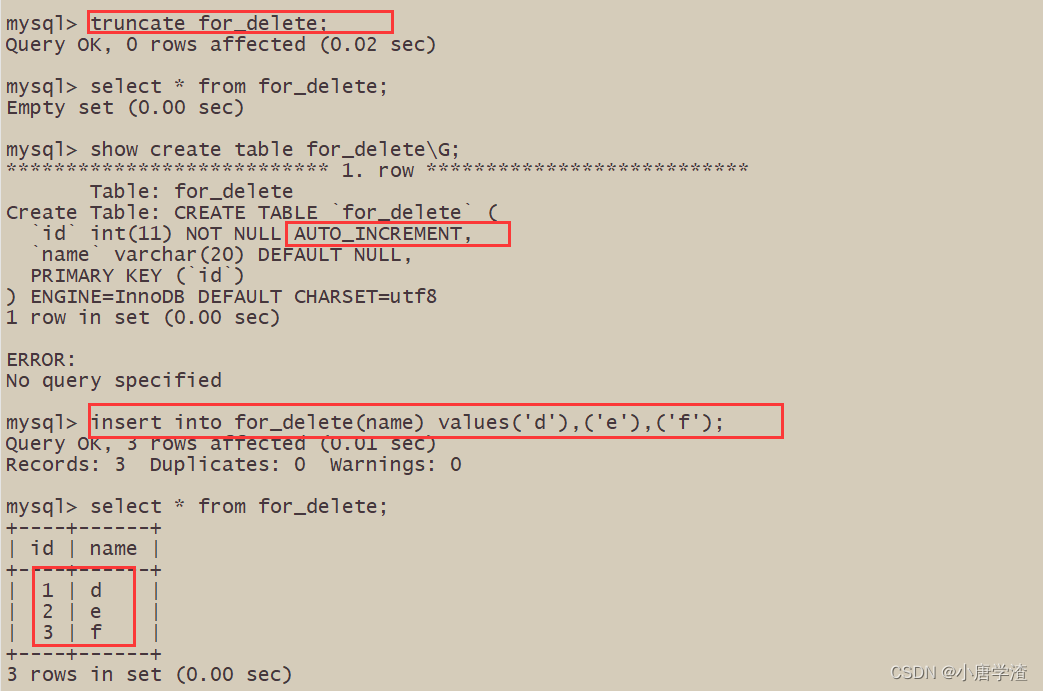
- 会重置 AUTO_INCREMENT 项
delete 删除 不会重置AUTO_INCREMENT 项

TRUNCATE删除 会重置AUTO_INCREMENT 项
五、插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...- 1
案例:删除表中的的重复复记录,重复的数据只能有一份

六、聚合函数
函数 说明 COUNT([DISTINCT] expr) 返回查询到的数据的 数量 SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义 AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义 MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义 MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义 案例:
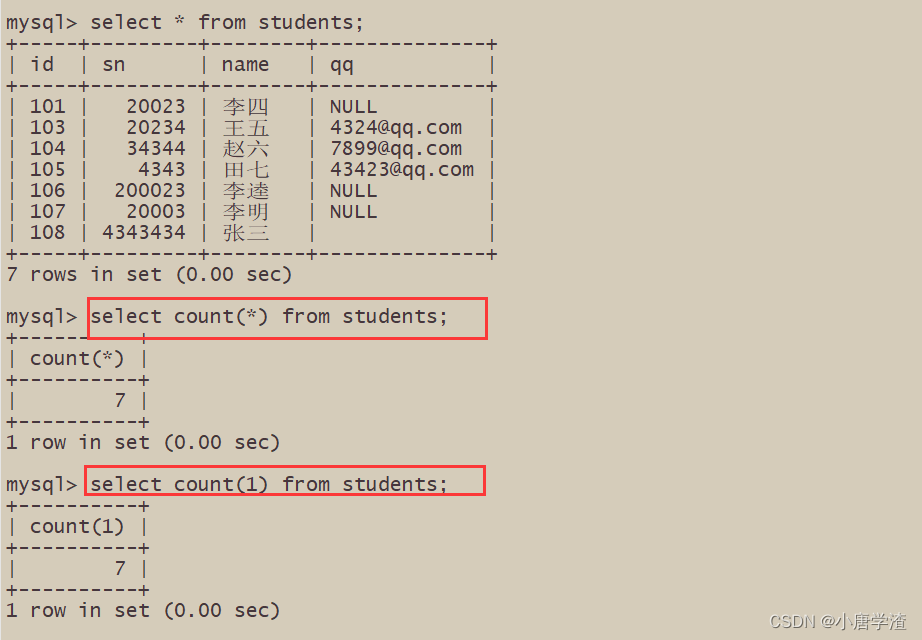
6.1 统计班级共有多少同学
– 使用 * 做统计,不受 NULL 影响
– 使用表达式做统计
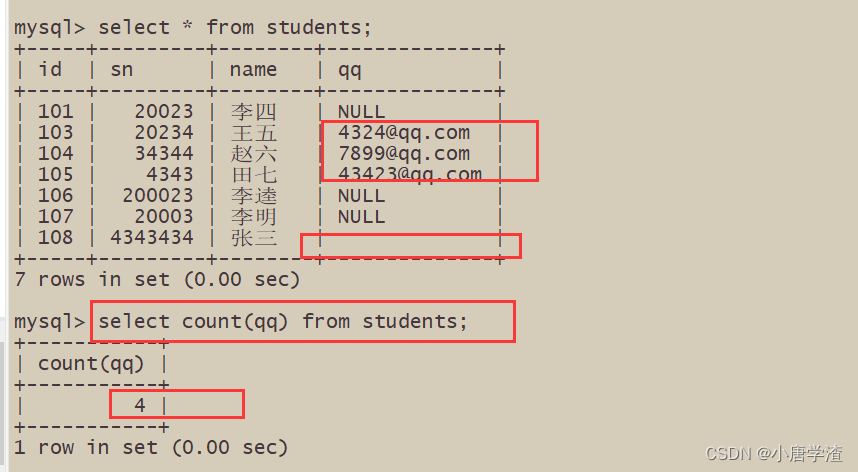
6.2 统计班级收集的 qq 号有多少
– NULL 不会计入结果
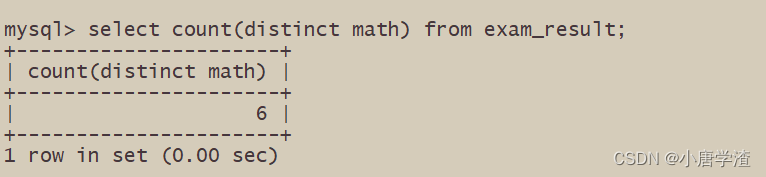
6.3 统计本次考试的数学成绩分数个数
– COUNT(math) 统计的是全部成绩

- COUNT(DISTINCT math) 统计的是去重成绩数量
6.4 统计数学成绩总分
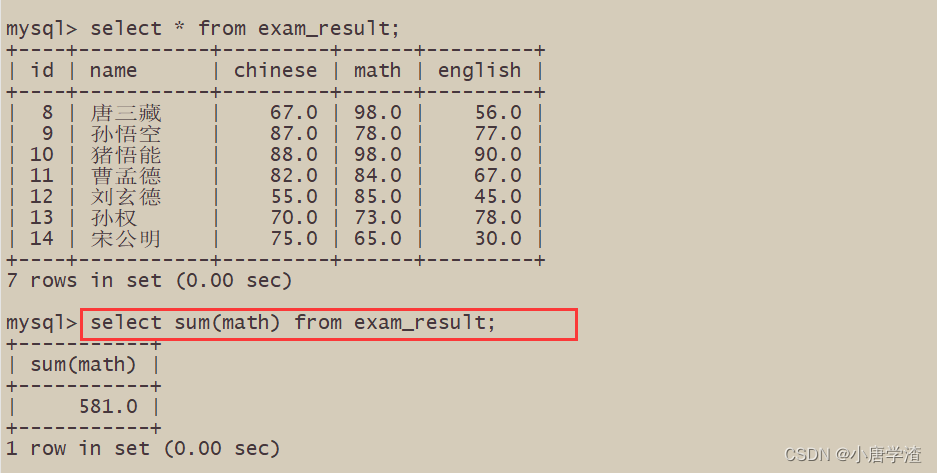
- 不及格 < 60 的总分,没有结果,返回 NULL

6.5 统计平均总分

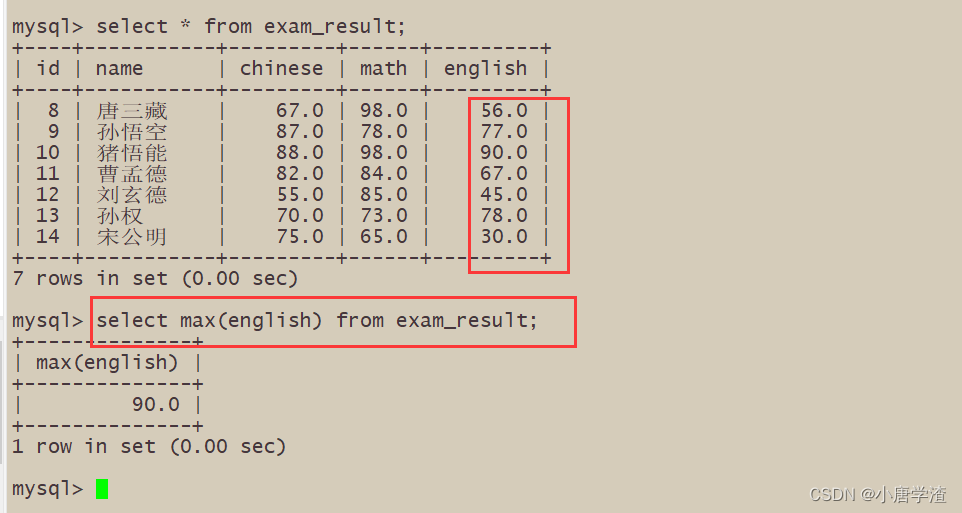
6.6 返回英语最高分
6.7 返回 > 70 分以上的数学最低分
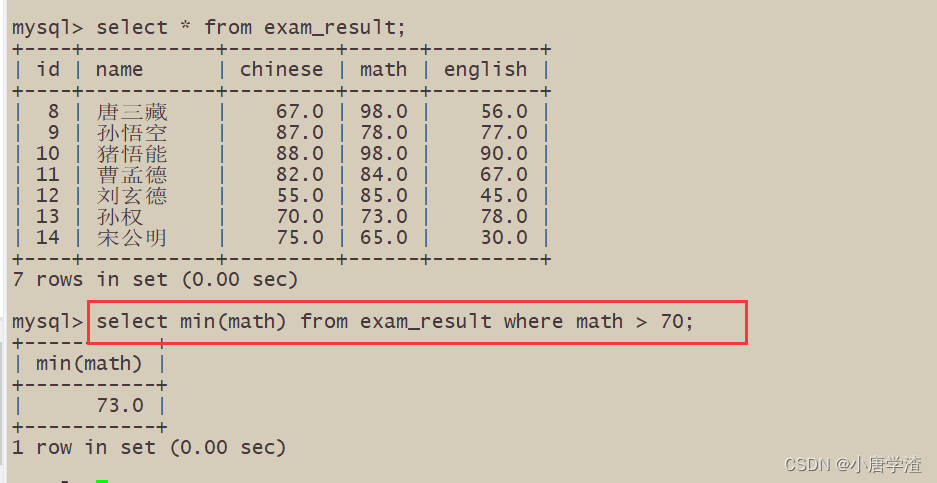
七、group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
- select column1, column2, … from table group by column;
案例:
-
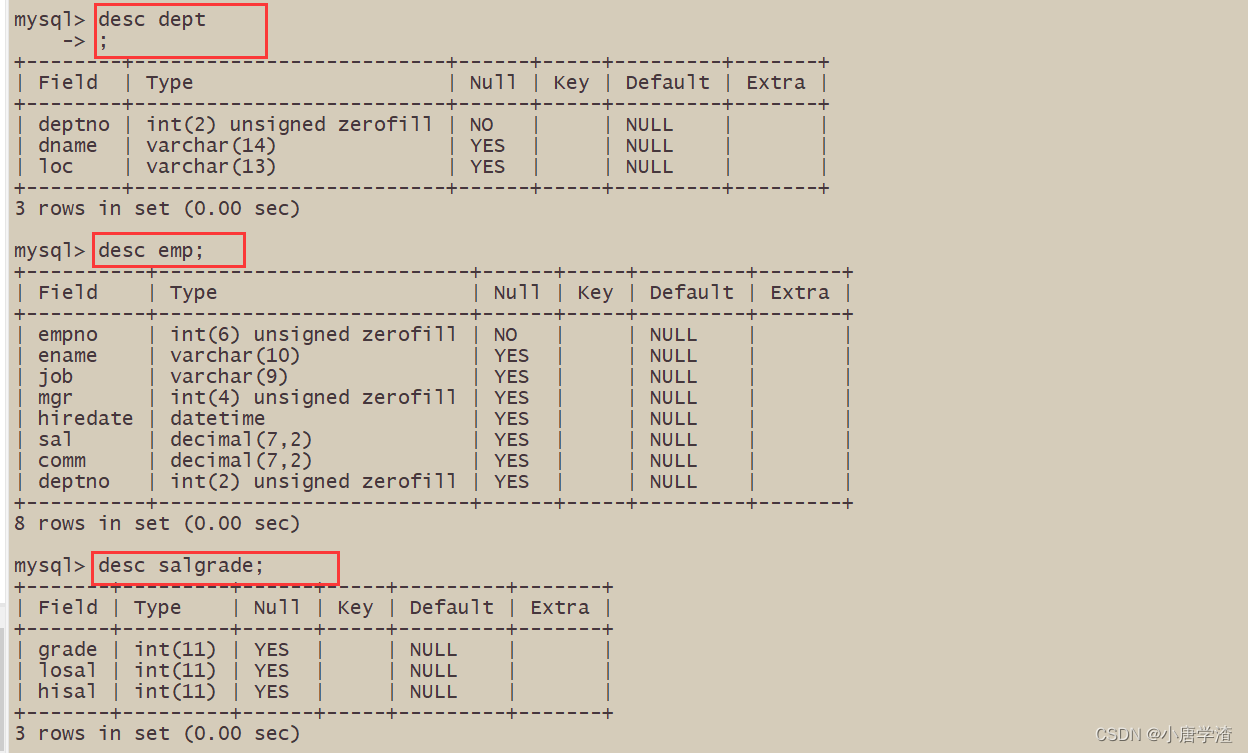
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
-
EMP员工表
DEPT部门表
SALGRADE工资等级表
-
如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;

-
显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;

-
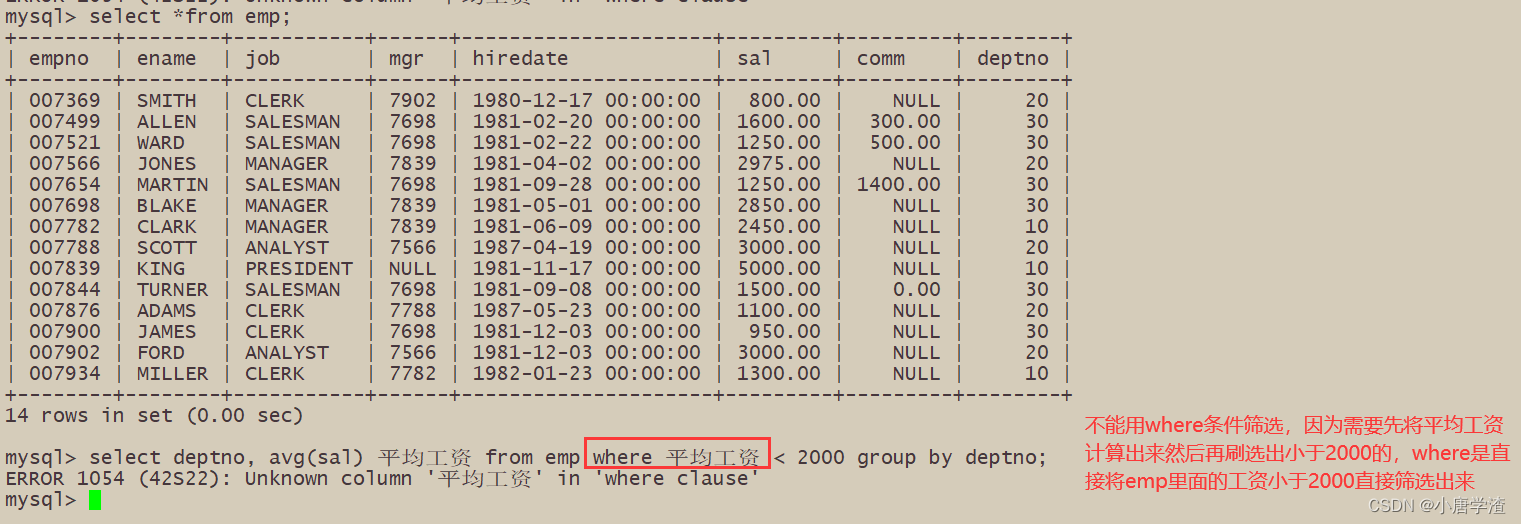
显示平均工资低于2000的部门和它的平均工资
统计各个部门的平均工资
having和group by配合使用,对group by结果进行过滤

-
相关阅读:
Linux网络编程- ioctl()结合struct ifreq使用案例
python科研绘图:圆环图
redis 事务,深入解读
HttpURLConnection 接收长字符串时出现中文乱码出现问号��
国科大-计算机算法设计与分析-卜东波作业3
写一个flutter程序2
微信小程序 --- 简易双向绑定
阿里云·短信发送
外包干了2个月,感觉技术明显退步...
蓝牙协议文档下载
- 原文地址:https://blog.csdn.net/qq_52809807/article/details/126479986