-
阿里云 ACK 容器服务生产级可观测体系建设实践
作者:冯诗淳(行疾)
ACK 可观测体系介绍
全景概要介绍
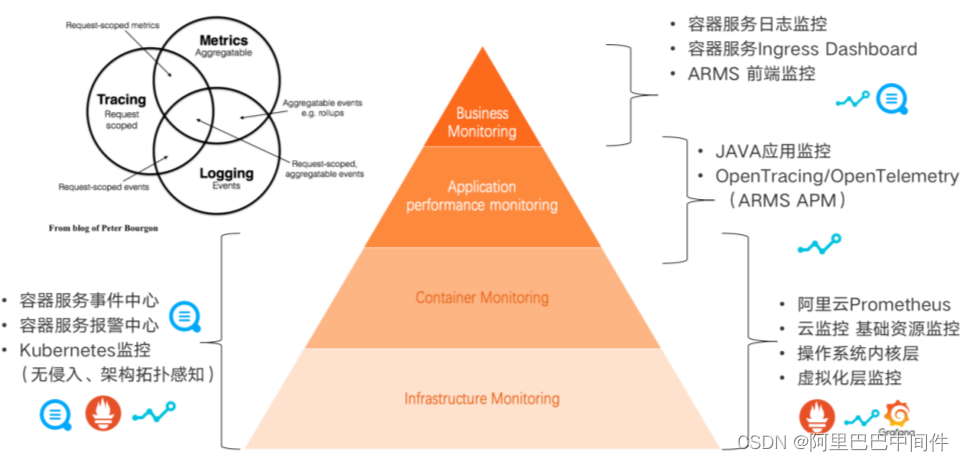
上图为 ACK 可观测体系全景图金字塔,从上至下可分为四层:
最上层是最接近用户业务的 Business Monitoring,包括用户业务的前端的流量、PV、前端性能、JS 响应速度等监控。通过容器服务的 IngressDashboard 来监测 Ingress 的请求量以及请求的状态,用户可以定制业务日志,通过容器服务的日志监控来实现业务的自定义监控。
第二层是 Application Performance Monitoring,包括用户的应用监控,由 ARMS APM 产品提供用户Java Profiling 和 Tracing等能力,也支持 OpenTracing和 OpenTelemetric 协议的多语言监控方案。
第三层是 Container Monitoring,包括容器的集群资源、容器 runtime 层、容器引擎以及容器集群的稳定性。使用阿里云 Prometheus 在一张 Global view 的大盘中展示不同集群层面的资源应用,包括性能、水位、云资源,也包括事件体系和日志体系,由事件中心和日志中心覆盖。
最下层是 Infrastructure Monitoring,包括不同的云资源、虚拟化层、操作系统内核层等。容器层和基础架构层都可以使用基于 eBPF 的无侵入式架构和 K8s 监控能力做网络和调用的 tracing。
可观测体系的每一层都和可观测的三大支柱 Logging、Tracing、Metrics 有不同程度的映射。
- 场景一:异常诊断场景的可观测能力实践

用户的异常诊断案例
早上 9 点多业务流量激增时出现了异常诊断,收到容器报警提示某 Pod Down 影响业务流量。用户收到报警后快速反应,对核心业务的 Pod 进行重启或扩容,查找问题根因。首先通过 IngressDashboard 从入口流量自上而下分析,发现对外业务的访问成功率下降以及出现 4XX 返回码的请求,说明这次异常影响了用户业务。再从资源以及负载层面分析,可以发现是由于朝九晚五的流量导致水位负载,在当天早上 9 点时存在与故障对齐的明显水位飙升,这也是故障所在。
系统第一时间报警核心业务的 Pod 定位,结合业务日志进行分析,加上 ARMS Java 的 APM 应用监控,定位到产生缓存 bug 是由于早上 9 点钟业务流量飙升引发了 bug 最后造成频繁的数据库读写,调用链也反映可能出现了数据库的慢查询,最后通过修复 bug 彻底闭环整个异常。
上述流程是非常典型的贯穿了整个 ACK 可观测不同能力异常诊断的排查过程,能够帮助我们更好地理解 ACK 可观测体系如何相互协调完成工作。
事件体系介绍
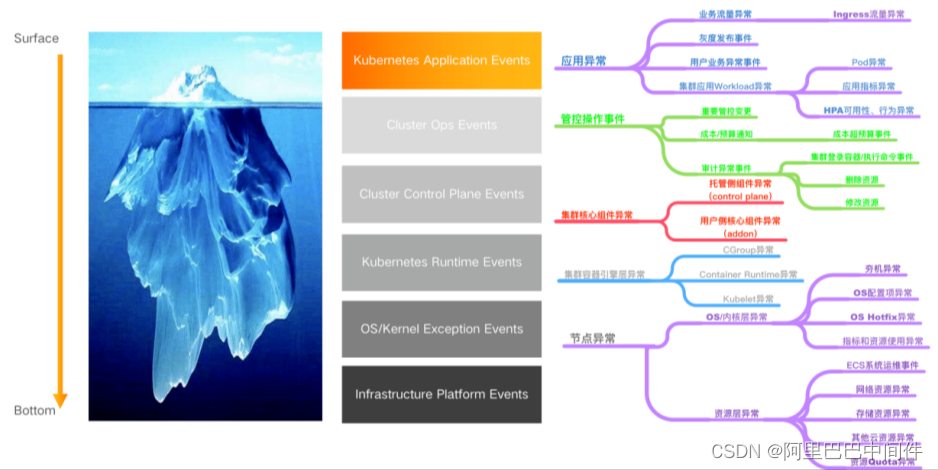
社区的 K8s 中包含了非常成熟的事件体系,提供了应用层的事件以及 runtime 层的事件。ACK 可观测体系在社区的事件体系之上,从表层到底层都进行了覆盖和增强,做到了可观测事件体系的全覆盖。
-
应用异常:对于 K8s 的应用事件提供了用户灰度发布以及 HPA 等异常行为的事件监控。
-
管控操作事件:增加了集群的管控事件、用户对集群的异常操作以及重要变更,甚至包括成本和预算超标等。
-
集群核心组件异常:集群的稳定性很大一部分由集群核心组件的健康来保证。对于集群核心组件包括 API server、ETCD、Scheduler、CCM 等都做了异常事件的增强,出现异常事件能够第一时间进行触达。此外,还包括用户侧核心组件 addon 事件,比如 Terway、存储等。
-
集群容器引擎层异常:对集群容器引擎层做了增强,包括了 Container Runtime、Kubelet、Cgroup 等异常。
-
节点异常:包括 OS/内核层异常,比如操作系统内核宕机、操作系统配置的异常等,也包括资源层异常比如网络资源异常、存储资源异常、其他云资源异常等,为容器服务的运维保障及功能更强的覆盖提供了支持。
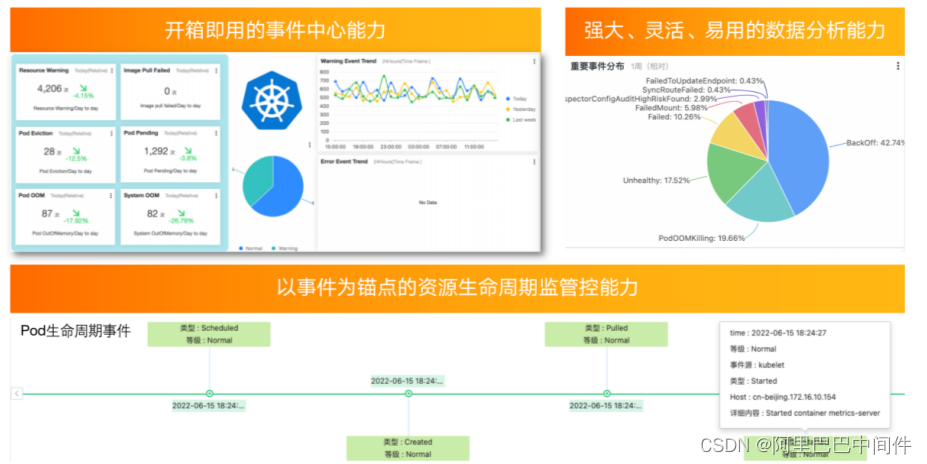
ACK 提供了开箱即用的事件中心能力,一键开启事件中心,即可享受复杂的事件体系带来的强大功能。它提供了预置的试验中心大盘,能够对重要的事件进行突出以及统计,也提供了强大、灵活易用的数据分析能力,为后面基于事件驱动的 OPS 体系提供了基础。ACK K8s 集群更多的是对资源的生命周期进行管控,事件中心也提供了以事件为锚点的资源生命周期的管控能力。可以对生命周期中最重要的几个时间点进行性能的调试优化以及对异常 Pod 状态快速反应。
日志体系介绍
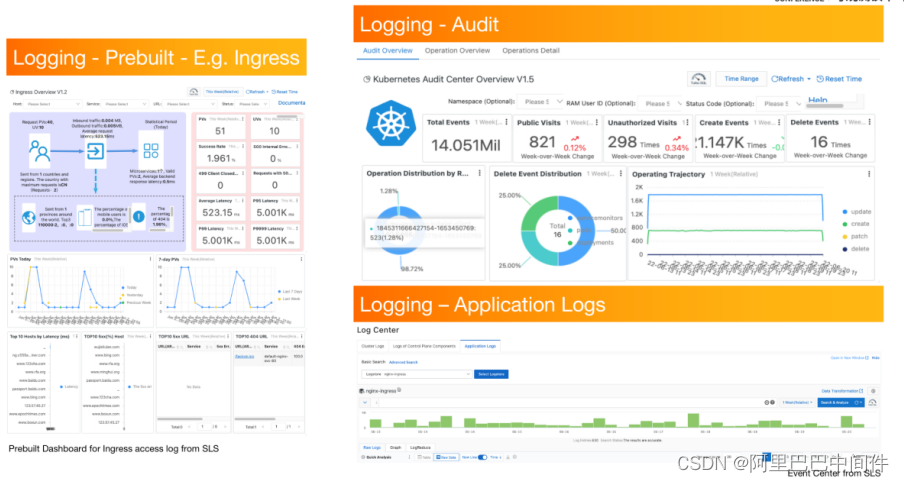
Logging 在 K8s 中的第一个使用场景是重要流量,如 Ingress 等。ACK 的日志中心默认提供了 Ingress 等重要场景的大盘,一键接入 Ingress 大盘后即可快速查看集群 Ingress 流量,此外还包括 PV、UV、应用的异常状态以及统计,快速清晰,易于应用。
第二个日志使用场景是审计。集群中的资源经常被不同的账号访问使用,集群的安全也迫切需要重点关注。我们提供了审计日志大盘,可以快速分析集群资源的访问和使用轨迹,针对未被授权的访问可进行报警和预警,为集群提供更安全的环境。
我们提供了云原生无侵入式的日志获取方式,用户只需通过简单的 CRD 或在 Pod 上打 annotation ,即可将日志采集到日志中心,并享受日志中心多维、强大的分析能力。
Metric 体系介绍
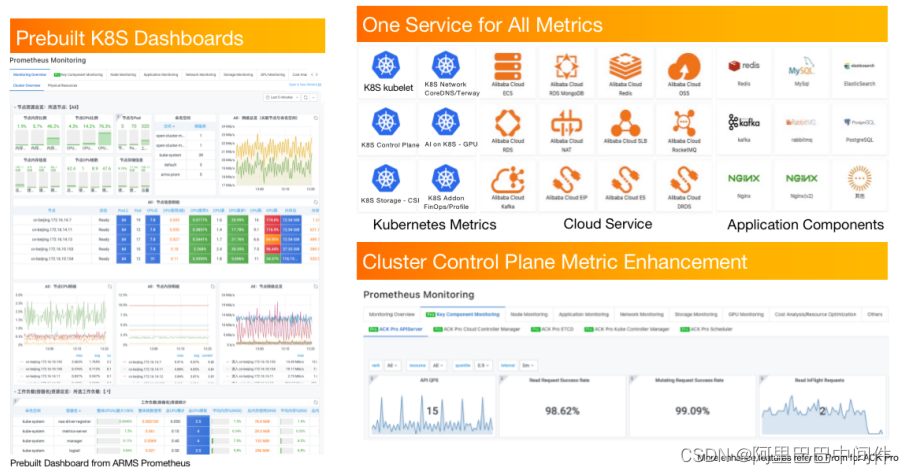
Metrics 体系是做稳定性保障和性能调优时最常用的体系,水位等关键指标都能通过大盘进行直观展示。产品侧预置了 ARMS Prometheus 大盘产品,购买了 ACK K8s 集群后,可以一键开启 Prometheus 大盘。此外,体系内预置了重要场景的 Prometheus 大盘,都是经过 K8s 上业务运维成熟经验的沉淀。Prometheus 方案涉及到不同的服务,不仅包括容器服务侧最核心的 K8s 应用、网络、核心控制面指标,还包括比如 AI 场景、 GPU 指标以及存储 CSI 等外部存储场景,以及资源的优化或成本的优化指标。
使用统一的 Prometheus 数据链路方案,不进能够支持容器场景的指标,也支持不同云产品的指标以及云产品上不同中间件的指标,可以将所有层级指标都在 Prometheus 数据链路中进行统一展示。
ACK 集群控制面的核心组件 API Server、ETCD 、scheduler 、CCM 等也做了指标加强。Pro 集群不只负责托管这部分核心组件、维护其 SLA,同时也会将透明指标性能暴露给用户,让用户使用安心。
- 场景二:稳定性保障 - 2022 冬奥会 ACK 助力圆满平稳举行

指标场景是稳定性保障的重要支持能力。ACK 非常荣幸地为 2022 年的冬奥会服务,助力冬奥系统圆满平稳运行。
ACK 集群中部署了冬奥会多个核心业务系统,包括冬奥的国际官网、比赛场馆、票务系统等,为多个核心系统保驾护航。核心系统多为 Java 系微服务架构,实际使用时有近千个 Deployment 实例。我们通过引入压测的方式进行容量评估,同时配合为冬奥定制的首屏运维大盘,实时进行应用和集群稳定性的保障,保证了冬奥访系统访问的顺滑。
- 场景三:生产级规模集群稳定性保障实践
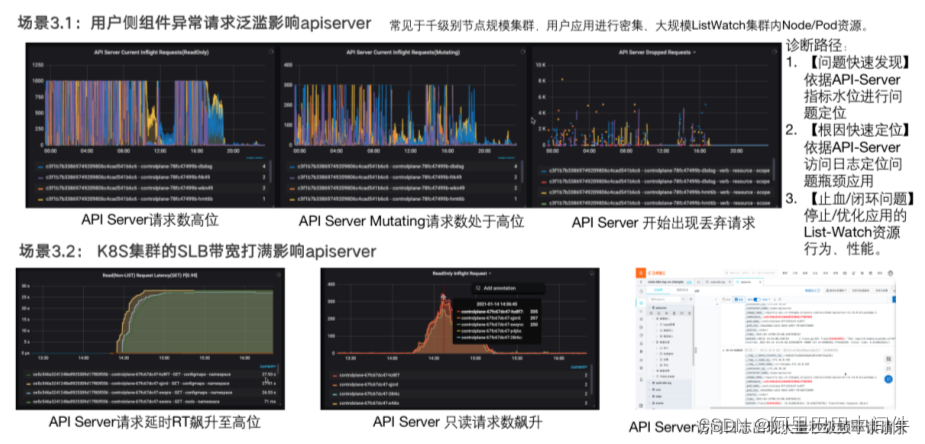
很多用户的生产系统规模很大,到达千级别节点的集群规模后,用户在集群上会进行密集、大规模的集群资源访问,极易出现集群稳定性问题。
比如,用户在大规模集群中频繁密集地访问集群资源,首先会使 API Server 的请求数较高,API ServerMutating 请求数也会处于高位。API Server 负载过高会导致出现丢弃请求的情况,这也是 API Server 的降级特性,会影响用户业务的发布或用户的变更。
再比如,密集的集群资源访问也可能打满 API Server 带宽,API Server 的请求延时 RT 会升至高位,一次 API 的访问可能需要几十秒,会严重影响用户的业务,API Server 的只读请求数也会飙升。
我们提供了 control plane 核心组件的监控大盘,可以快速发现 API Server 的水位和请求响应时间的延时问题,然后根据 API Server 的访问日志快速定位是哪个应用的什么动作导致 API Server 的水位和资源请求高,最终找到具体应用进行止血,解决问题。
Prometheus For ACK Pro

阿里云近期推出了 Prometheus for ACK Pro ,它是 Prometheus 的升级服务,能够在同一张大盘上看到多个数据源,包括集群事件日志、基于 eBPF 的无侵入式的应用指标、网络指标等,提供一致性的体验。用户可以通过一张大盘的关联分析逻辑,从总览到细节,通过多数据源、多角度的可观测能力进行不同角度的排查。
Tracing 体系介绍
- 应用层 Trace

在 ACK 可观测体系里, Tracing 体系提供了最终定位根因的能力,它分为两部分:
第一部分是应用层的 Tracing,提供 ARMS APM 能力,支持 OpenTracing、OpenTelemetric 协议,可以支持多种语言的应用。针对 Java 也提供了无侵入式的 APM 能力,只需要在 Pod 上打上 annotation, Java 应用的 Pod 即可享受实时的监控数据服务,可以查看实时的应用水位、 JVM 的性能指标、应用上下游分布式和微服务的全局调用 top 图等,也支持 Profiling 以及代码堆栈级的调用监控能力。不同语言可以汇聚成同一张分布式调用追踪大图,自上而下地查看一次分布式调用,从而定位、诊断问题。
- 集群网络、调用 Trace
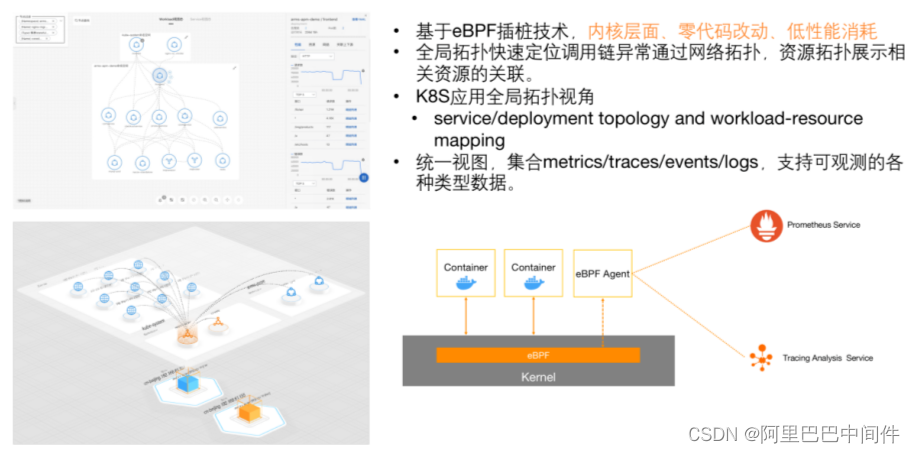
第二部分是集群网络和调用 Trace。
近期我们推出了基于 eBPF 网络层面的 Tracing 能力。通过 eBPF 插桩技术,在内核层面实现了零代码改动且非常低性能消耗的网络 Tracing 能力。提供了全局拓扑、快速定位问题调用链的网络拓扑展示以及资源层面展示,也支持在统一的全局架构视图中集合 Metrics、Tracing 和 Logging 多个角度进行可观测能力观察。
基于 ACK 可观测能力建设 AIOps体系
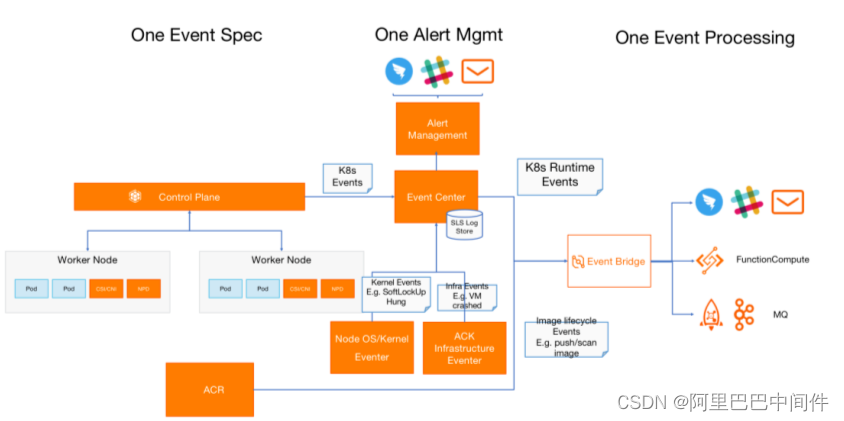
事件驱动的 AIOps 体系,用户可以将事件作为统一的驱动数据源进行问题的发现、触达以及 AI 智能化运维操作的桥梁。以 ACK 事件中心为核心,构造了统一的事件格式规范,K8s 的事件会以统一的事件配置格式提供给用户,最后以事件中心为核心,通过统一的事件处理流提供给用户。用户可以通过订阅事件做事件的智能化运维以及构建其体系。用户可以通过某个应用的业务进行业务事件推送,并对业务事件进行智能化运维处理,比如智能的扩容或缩容等。
此外,我们也提供了 ACK 报警中心,通过统一的报警配置为用户构建 AIOps 的体系,帮助用户快速建立运维的订阅、收发和问题排障、处理体系。
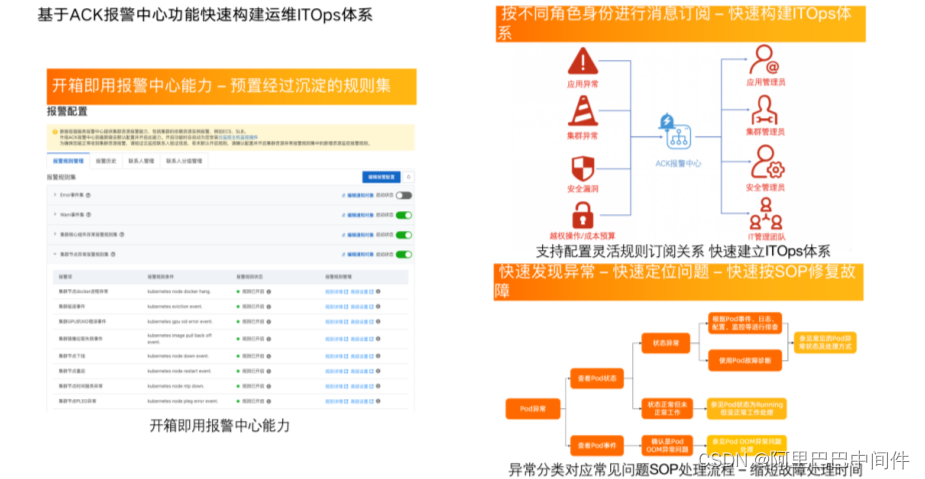
报警中心会为用户提供统一的配置,帮助用户快速建立 ACK 场景上异常诊断的异常规则集。ACK 报警中心提供了开箱即用的报警能力,沉淀了常用的容器场景异常规则集,开箱即用。其次,可以通过报警消息的细粒度订阅关系构建 ITOps 体系,不同的异常可以通过报警中心的订阅配置关系投递到真正能够解决异常的人手里。ACK 也沉淀了标准的异常以及对应标准异常处理的 SOP 手册,发现报警时,会提示异常类型,以及为用户提供处理异常的标准 SOP 修复流程。
基于 ACK 可观测能力建设 FinOps 体系
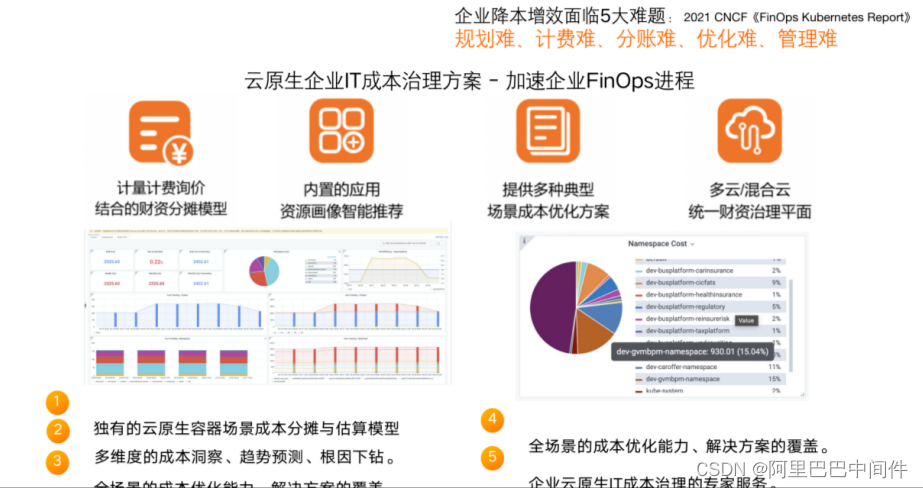
越来越多的用户面临了上云阶段或上云后治理阶段的降本增效问题,主要存在以下几个方面的痛点:
-
上云之前——如何上云,难规划;
-
上云之后——云产品种类丰富,集群资源类型也丰富,计费难;
-
高度 SaaS 化的应用部署在同一个集群中进行共享,成本分账难;
-
每年都会有新的业务生成和下线,集群和资源的使用关系是动态的,难以进行持续的优化和治理;
-
此前一般使用 Excel 表对能力进行管理,在云原生的场景下有丰富的用户应用和有丰富的账单资源类型,难以管理。
ACK 提供了云原生企业 IT 成本治理方案,通过多维度的成本分摊和估算模型,为集群的资源进行成本估算和分摊。可以通过根因的下钻和趋势的预测进行成本洞察,集群上多个应用业务的成本可以细粒度下钻,进行成本拆分。对多集群场景上的成本提供了成熟的解决方案覆盖,以及提供企业云原生 IT 成本治理的专家服务。
此外,我们还推出了内置的应用资源画像以及应用资源的智能推荐,可以为资源推荐合适的成本以及进行预算控制,最后会根据不同的场景进行成本优化,如大数据、AI、游戏等。
最后,支持多样化场景,包括多云和混合云等都能在统一的平面进行展示和管理。
客户案例

中华财险作为互联网金融的头部公司,有千核级别的集群规模,同时管理运维多个 SaaS 化线上业务,具有高度多租化、对业务稳定性要求高、对业务资源/成本趋势敏感度高等行业特点。
中华财险从传统 IT 架构到云原生化的过程中,面临着容量规划难、算清成本难、闲置资源难发现以及成本优化和业务稳定性难以平衡的挑战。
我们通过 ACK 的成本治理解决方案为它进行了压测、容量规划,通过 ACK 成本分析进行业务分账的账单管理和分析,解决了闲置资源的优化,为其提供了分配资源的优化策略,最后通过容器服务提供了细粒度的容器部署以及弹性策略等优化手段。
上云前,客户集群的资源分配闲置率高达 30%+,而通过我们提供的成本治理方案,闲置率降至 10% 以下,为行业领先水平。
了解更多可观测能力,点击此处。
-
相关阅读:
Linux 重定向、管道命令 、环境变量PATH、权限理解
Python语言基础与应用-北京大学-陈斌-P29-28-计算和控制流:控制流:上机:基本计算程序-给定一个英文数字字符串,打印相应阿拉伯数字字符串-上机代码
PDO:插入示例
sqoop连接MYSQL报错处理
Spring之概念和工作流程
Shell编写规范和变量
SAP MM模块业务流程
LeetCode-169. 多数元素【计数,哈希表,排序,随机化,分治】
360的chromesafe64.dll动态链接库导致chrome和edge浏览器闪退崩溃关闭
Java collections framework
- 原文地址:https://blog.csdn.net/weixin_39860915/article/details/126500484