-
LruCache源码解析
今天我们来聊聊缓存策略相关的内容,LruCache应该说是三级缓存策略会使用到的内存缓存策略。今天我们就来扒一扒这里面的原理,同时也温故温故我们的数据结构方面的知识。
目标
我们今天讲的这个缓存策略,主要有几个目的:
1.了解缓存的策略;
2.巩固数据结构相关的知识;
3.自己能实现一个缓存策略。
源码解析
1.缓存策略
要来分析源码,我们首先要先明白有哪几种缓存淘汰算法,我们先来复习一下:
1.FIFO(First In First Out):先进先出;
2.LRU(Least Recently Used):最近最少使用;
3.LFU(Least Frequently Used):最不经常使用。
这些都是什么呢?我们举个例子,比如我们的缓存对象顺序为:(队尾)EDDCBABAEA(队头),那么如果这时候来了个A,这时候要淘汰一个对象,如果是
FIFO,这时候就会淘汰的E;如果是LRU的话,这时候就会淘汰的D,因为D被使用过之后接下来再也没有被使用过了;如果是LFU的话,那么淘汰的就是C了,因为C就被使用过一次。这些就是我们三个缓存淘汰算法,我们知道我们的缓存是有限的,所以我们必须在新的对象进来的时候选择一个优秀的替换策略来替换缓存中的对象,这样可以提高缓存的命中率,进而提高我们程序的效率。LinkedHashMap
我们知道,我们的LRU算法可以用很多方法实现,最常见的是用链表的形式,这里的LinkedHashMap就是双向链表实现的,所以我们的LruCache是用的LinkedHashMap来实现,我们首先看下LruCache的成员变量和构造函数:
public class LruCache- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
我们先来说说初始化容量和加载因子的关系,我们这里下来看下HashMap中的构造函数:
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) { initialCapacity = MAXIMUM_CAPACITY; } else if (initialCapacity < DEFAULT_INITIAL_CAPACITY) { initialCapacity = DEFAULT_INITIAL_CAPACITY; } if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); // Android-Note: We always use the default load factor of 0.75f. // This might appear wrong but it's just awkward design. We always call // inflateTable() when table == EMPTY_TABLE. That method will take "threshold" // to mean "capacity" and then replace it with the real threshold (i.e, multiplied with // the load factor). threshold = initialCapacity; init(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我们看到我们的初始容量为0的话,这里会使用默认的初始容量,然后如果我们进行扩容的时候会用到 float thresholdFloat = capacity * loadFactor即容量*加载因子来进行决定扩展后的容量,默认的加载因子0.75是实验后的最佳数据。接着我们来看看LinkedHashMap是怎么实现的LRU算法的,我们先来LinkedHashMap的变量和构造函数:
public class LinkedHashMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们看到LinkedHashMap里面主要有LinkedHashMapEntry,这个是双向链表的一个节点有前驱和后继,我们可以来看看这个LinkedHashMapEntry节点:
private static class LinkedHashMapEntry- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们看到这里的LinkedHashMapEntry继承的HashMapEntry,同时里面有before和after节点,这是为了扩展成双向链表做的准备。我们来看下添加新的节点的方法最终会调用到createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) { HashMapEntry- 1
- 2
- 3
- 4
- 5
- 6
- 7
看懂这个方法之前,我们必须明确一下hashmap的数据结构,我们看下下面这个图:

LinkedHashMap完整的数据结构
我们看到前面会有一个table数组用于存放各个entry链表的,然后LinkedHashMap又在此基础上面增加了当前节点上面增加before和after的前驱和后继节点的引用信息。为了大家更加清楚地知道这个双链表结构,我们把双链表抽取出来如下:
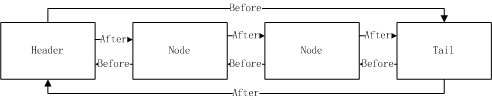
双向链表
所以添加一个新的节点的时候会调用addbefore来添加,这个方法做的东西就是在头部增加新的节点:

新增新的节点
private void addBefore(LinkedHashMapEntry- 1
- 2
- 3
- 4
- 5
- 6
这里的existingEntry就是我们的header。所以我们可以看到新增的节点被插入到了首节点前面变成了首节点。我们刚才看到LruCache构造函数里面LinkedHashMap的初始化的第三个参数accessOrder被赋值为true是什么意思呢?这个是为了记录访问的顺序的,如果被访问过了之后,这里true说明我们要把被访问过的节点掉到首节点去。具体代码可以看recordAccess()方法:
void recordAccess(HashMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个方法是在get方法中调用的,我们这里如果accessOrder为true的话,那么我们会先移除访问节点,然后把它添加到首节点,说明我这个节点刚访问过。到这里我们已经明白了LinkedHashMap的工作原理了,那么我们接下来就来看看LruCache的源码了。
LruCache源码
熟悉了LinkedHashMap的数据结构,我们就很容易知道怎么用这个来实现LRU算法了,我们先来看看LruCache的get()方法的源码:
public final V get(K key) { if (key == null) { throw new NullPointerException("key == null"); } V mapValue; synchronized (this) { //现在hashMap中查找有没有这个key对应的节点(这个地方只要是get一次就会把命中的节点往首节点排) mapValue = map.get(key); if (mapValue != null) { //如果命中的话那么命中+1,返回该值 hitCount++; return mapValue; } //如果没有命中的话那么没命中+1 missCount++; } /* * Attempt to create a value. This may take a long time, and the map * may be different when create() returns. If a conflicting value was * added to the map while create() was working, we leave that value in * the map and release the created value. */ //尝试去创建一个值,默认是空 V createdValue = create(key); if (createdValue == null) {//如果不为没有命名的key创建新值,则直接返回 return null; } // 接下来是如果用户重写了create方法后,可能会执行到 synchronized (this) { createCount++;//创建的数量增加 mapValue = map.put(key, createdValue););// 将刚刚创建的值放入map中,返回的值是在map中与key相对应的旧值(就是在放入new value前的old value) if (mapValue != null) { // There was a conflict so undo that last put map.put(key, mapValue);//如果不为空,说明不需要我们所创建的值,所以又把返回的值放进去 } else { size += safeSizeOf(key, createdValue);//为空,说明我们更新了这个key的值,需要重新计算大小 } } if (mapValue != null) {//上面放入的值有冲突 entryRemoved(false, key, createdValue, mapValue);// 通知之前创建的值已经被移除,而改为mapValue return mapValue; } else { trimToSize(maxSize);//没有冲突时,因为放入了新创建的值,大小已经有变化,所以需要修整大小 return createdValue; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
我们看到LruCahe是可能被多个线程访问的,所以读取时候要适当加上锁机制,当获取不到
key对应的value时候,他会调用create方法,这个方法默认是返回null的,除非我们重写了create方法,这个方法并没有加锁,所以在创建的过程中有可能其他线程已经添加进去了这个值,所以在后面的时候会进行判断是否已经不为空了,如果不为空即删除放入原来的值,没有冲突就放入新值调整大小变化。我们来看下最后调整大小的代码trimToSize方法:public void trimToSize(int maxSize) { while (true) { K key; V value; synchronized (this) { if (size < 0 || (map.isEmpty() && size != 0)) { throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!"); } if (size <= maxSize) { break; } Map.Entry- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
这个方法我们看到会判断size<=maxSize不,如果小于则不用调整,如果大于了那么我们就会取出最老的Entry,进行删除,然后置换的个数增加1。然后我们看下put的方法干了什么:
public final V put(K key, V value) { if (key == null || value == null) { throw new NullPointerException("key == null || value == null"); } V previous; synchronized (this) { putCount++; size += safeSizeOf(key, value); previous = map.put(key, value); if (previous != null) { size -= safeSizeOf(key, previous); } } if (previous != null) { entryRemoved(false, key, previous, value); } trimToSize(maxSize); return previous; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我们看到这个方法不难,主要的逻辑就是计算一下放入进去值的大小,然后加起来。同样地,放进去map中,然后看是不是更新旧的值,如果是则把刚才加上的大小再减去,然后删除旧的值跟maxSize调整一下总的大小。到这里我们大概已经讲完
LruCache的源码了,我们也大概了解了整体的设计,其实我们自己也是可以写出这样一套代码的,主要的还是数据结构方面的知识。总结
其实整体的LruCache的实现并不会非常难,主要就是数据结构的知识,我们可以根据这一套思想,我们也可以实现各种缓存策略
-
相关阅读:
在线人数统计功能怎么实现?
斯坦福NLP课程 | 第12讲 - NLP子词模型
143.如何个性化推荐系统设计-3
RocketMQ相关概念
红队隧道加密之MSF流量加密(二)
我常用的5个效率小工具,强烈推荐
史上最全JVM性能调优:线程+子系统+类加载+内存分配+垃圾回收
C++数组空初始化器简介以及对比测试
M3 MacBook Pro 能提效?程序员、产品经理自证后,CTO:你赢了,新电脑在路上了...
自定义容器控件之C#设计笔记(十五)
- 原文地址:https://blog.csdn.net/weixin__BJ050106/article/details/126331193