7. dws 层建设(大宽表)
需求:
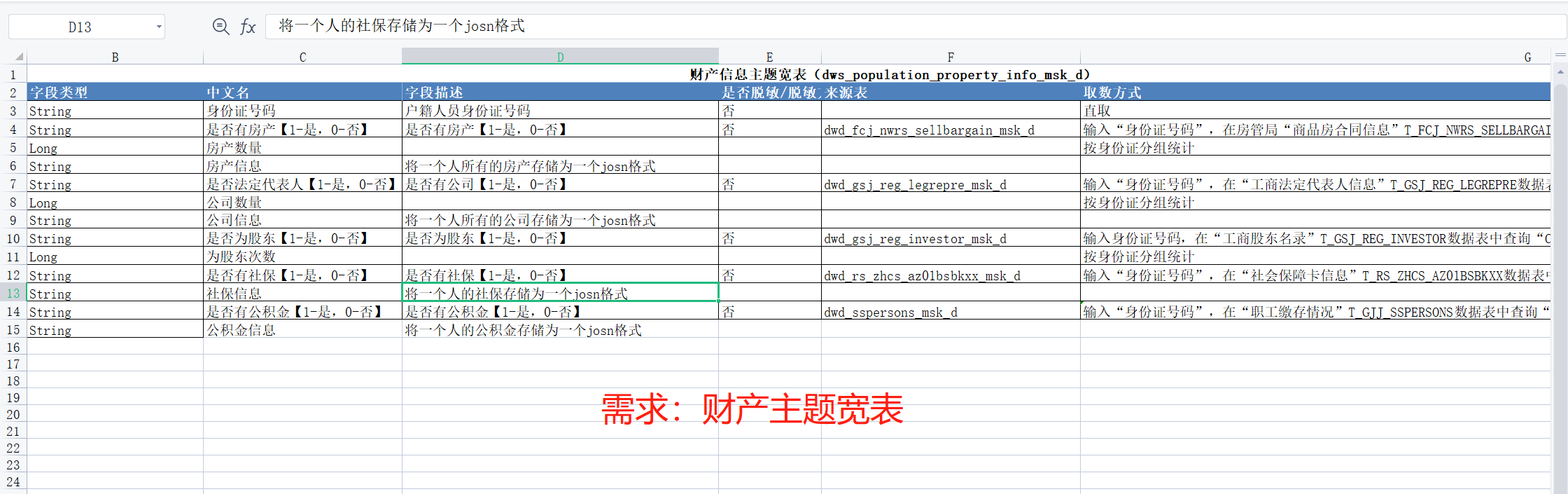
dws层的层结构如下:
7.1注意事项:
学习两个新的函数 named_struct() 将字段和字段的值变成一个kv格式的类型,数据和结果如下:
D71FBB5BF8922508B8FEA72BFA556294 {"r_fwzl":"富强路东侧壹号公馆A*******","htydjzmj":"117.2900","tntjzmj":"96.8700","ftmj":"20.4200","time_tjba":"2011-11-04 10:19:26","htzj":"499670.0000"}
collect_list() 将很多的数据转变成一个集合, to_json()将这个集合转变称为一个json格式

7.2 在dws层的建表语句如下:
- CREATE TABLE IF NOT EXISTS dws.dws_population_property_info_msk_d(
- id String comment '身份证号码',
- sfyfc String comment '是否有房产【1-是,0-否】',
- sfyfc_num BIGINT comment '房产数量',
- sfyfc_info String comment '房产信息',
- sfygc String comment '是否法定代表人【1-是,0-否】',
- sfygc_num BIGINT comment '公司数量',
- sfygc_info String comment '公司信息',
- sywgd String comment '是否为股东【1-是,0-否】',
- sywgd_num BIGINT comment '为股东次数',
- sfysb String comment '是否有社保【1-是,0-否】',
- sfysb_num BIGINT comment '交社保的数量',
- sfysb_info String comment '社保信息',
- sfygjj String comment '是否有公积金【1-是,0-否】',
- sfygjj_num BIGINT comment '交公积金次数',
- sfygjj_info String comment '公积金信息'
- )
- PARTITIONED BY (
- ds string comment '分区'
- )
- ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
- STORED AS TEXTFILE
- location'/daas/motl/dws/dws_population_property_info_msk_d';

7.3 构建大款表 的语句如下
- insert overwrite table dws.dws_population_property_info_msk_d partition(ds=${ds})
-
- select
- -- /*+ broadcast(b),broadcast(c),broadcast(d),broadcast(e),broadcast(f) */
- a.id,
- case when b.id is null then 0 else 1 end sfyfc,
- case when b.id is null then 0 else b.sfyfc_num end sfyfc_num,
- b.sfyfc_info as sfyfc_info,
- case when c.id is null then 0 else 1 end sfygc,
- case when c.id is null then 0 else c.sfygc_num end sfygc_num,
- c.sfygc_info as sfygc_info,
- case when d.id is null then 0 else 1 end sywgd,
- case when d.id is null then 0 else d.sywgd_num end sywgd_num,
- case when e.id is null then 0 else 1 end sfysb,
- case when e.id is null then 0 else e.sfysb_num end sfysb_num,
- e.sfysb_info as sfysb_info,
- case when f.id is null then 0 else 1 end sfygjj,
- case when f.id is null then 0 else f.sfygjj_num end sfygjj_num,
- f.sfygjj_num as sfygjj_info
- from
- (
- select id from dwd.dwd_ga_hjxx_czrkjbxx_msk_d
- group by id
- ) as a
- left join
- (
- select id,
- count(1) as sfyfc_num,
- to_json(collect_list(named_struct( -- 将一个人所有的房产信息合并成一个json字符串
- "r_fwzl",r_fwzl,
- "htydjzmj",htydjzmj,
- "tntjzmj",tntjzmj,
- "ftmj",ftmj,
- "time_tjba",time_tjba,
- "htzj",htzj
- ) )) as sfyfc_info
- from dwd.dwd_fcj_nwrs_sellbargain_msl_d
- where ds=${ds}
- group by id
- ) as b
- on a.id=b.id
-
- left join
-
- (
- select
- id,
- count(1) as sfygc_num ,
- to_json(collect_list(named_struct(
- "position",position,
- "tel",tel,
- "appounit",appounit,
- "accdside",accdside,
- "posbrmode",posbrmode,
- "offhfrom",offhfrom,
- "offhto",offhto,
- "stufftype",stufftype
- ) )) as sfygc_info
- from dwd.dwd_gsj_reg_legrepre_msk_d
- where ds=${ds}
- group by id
- ) as c
- on
- a.id=c.id
-
- left join
- (
- select id,count(1) as sywgd_num
- from dwd.dwd_gsj_reg_investor_msk_d
- where ds=${ds}
- group by id
- ) as d
- on
- a.id=d.id
-
- left join
- (
- select id,
- count(1) as sfysb_num,
- to_json(collect_list(named_struct(
- "citty_id",citty_id,
- "ss_id",ss_id,
- "fkrq",fkrq,
- "yxqz",yxqz,
- "aaz502",aaz502,
- "aae008",aae008,
- "aae008b",aae008b,
- "aae010",aae010,
- "aae010a",aae010a,
- "aae010b",aae010b
- ) )) as sfysb_info
- from
- (
- select distinct *
- from dwd.dwd_rs_zhcs_az01bsbkxx_msk_d
- where ds=${ds}
- ) as t
- group by id
- ) as e
- on
- a.id=e.id
-
- left join
-
- (
- select id,count(1) as sfygjj_num,
- to_json(collect_list(named_struct(
- "spcode",spcode,
- "hjstatus",hjstatus,
- "sncode",sncode,
- "spname",spname,
- "spcard",spcard,
- "sppassword",sppassword,
- "zjfdm",zjfdm,
- "spkhrq",spkhrq,
- "spperm",spperm,
- "spgz",spgz,
- "spsingl",spsingl,
- "spjcbl",spjcbl,
- "spmfact",spmfact,
- "spmfactzg",spmfactzg,
- "spjym",spjym,
- "ncye",ncye,
- "splast",splast,
- "dwbfye",dwbfye,
- "grbfye",grbfye,
- "spmend",spmend,
- "splastlx",splastlx,
- "spout",spout,
- "spin",spin,
- "bnlx",bnlx,
- "nclx",nclx,
- "dwhjny",dwhjny,
- "zghjny",zghjny,
- "btyje",btyje,
- "btye",btye,
- "btbl",btbl,
- "bthjny",bthjny,
- "spxh",spxh,
- "spzy",spzy,
- "spxhrq",spxhrq,
- "splr",splr,
- "spoldbankno",spoldbankno,
- "spdk",spdk,
- "spdy",spdy,
- "zhdj",zhdj,
- "spnote",spnote,
- "modifytime",modifytime,
- "status",`status`,
- "cbank",cbank,
- "bcyje",bcyje,
- "bcye",bcye,
- "bcbl",bcbl,
- "bchjny",bchjny,
- "zjzl",zjzl
- ) )) as sfygjj_info
- from
- dwd.dwd_gjj_sspersons_msk_d
- where ds=${ds}
- group by id
- ) as f
- on a.id=f.id
脚本如下:
在提交spark任务时,必须指定executer 的数量,然后指定核数和内存,然后就是分区数(避免生成很多的小文件)
- # 分区
- ds=$1
-
- # 执行任务
- # num-executor 在项目现场一般50-100个
- spark-sql \
- --master yarn-client \
- --num-executors=1 \
- --executor-cores=2 \
- --executor-memory=4G \
- --conf spark.sql.shuffle.partitions=2 \
- -f dws_population_property_info_msk_d.sql \
- -d ds=$ds
7.4 提交任务
因为在dwd层我的分区搞错了,所以有两张表没有数据,如下:

当我把分区统一一致后,重新跑数据之后,再次执行任务。如下:
将小表广播出去,提高效率


还有一个就是分区问题,如果不指定分区默认就是200 个分区,到时候在hdfs中就会生成200个左右的小文件,但是指定分区数后,如下:
