-
推荐系统 推荐算法 (小红书为例) 笔记 2
推荐系统
标题结构
一、二、三、四、…
1、2、3、4、…
(1) (2) (3) (4)、…
黑体字
四、物品冷启
1、优化目标 & 评价指标
UGC(用户上传)、PGC(平台采购)。此探讨UGC
(1) 为什么要特殊对待新笔记
- 新笔记缺少与用户的交互,导致推荐的难度大、效果差。
- 扶持新发布、低曝光的笔记,可以增强作者发布意愿。
(2) 优化冷启的目标
- 精准推荐:克服冷启的困难,把新笔记推荐给合适的用户,不引起用户反感
- 激励发布:流量向低曝光新笔记倾斜,激励作者发布
- 挖掘高潜:通过初期小流量的试探,找到高质量的笔记,给与流量倾斜。
给新笔记曝光最能提高积极性。如果一篇笔记已经有1w点赞,再次曝光张到2w,发布新笔记的积极性也不是很高。每篇新笔记可以尝试100~200次曝光,进行试探。
(3) 评价指标
作者侧指标:
- 发布渗透率:当日发布人数 / 日活人数 (用户称为作者的比率,就是渗透率)
- 人均发布量:当日发布笔记数 / 日活人数
另外:
- 发布渗透率、人均发布量反映出作者的发布积极性。
- 冷启的重要优化目标是促进发布,增大内容池
- 新笔记获得的曝光越多,首次曝光和交互出现得越早,作者发布积极性越高。
用户侧指标:
- 新笔记的消费指标:点击率、交互率
- 大盘消费指标:类似北极星指标
另外:
- 反映出推荐是否精准,用户是否反感
- 大盘指标尽量持平
内容侧指标:
- 高热笔记占比
反映冷启笔记是否挖掘出优质笔记,帮助其成长为热门。高热笔记占比越高,说明冷启阶段优质挖掘优质笔记的能力越强。
2、简单的召回通道
(1) 双塔模型
改进方案1:新笔记使用 default embedding
- 物品塔做 ID embedding 时,让所有新笔记共享一个 ID,而不是用自己真正的ID
- Default embedding :共享的 ID 对应的 embedding 向量。
- 到下次棋型训练的时候,新笔记才有自己的 ID embedding 向量。
Default embedding 是学出来的,不是随机初始生成的。
改进方案2:利用相似笔记embedding向量
- 查找top k 内容最相似的高曝光笔记
- 把 k 个高曝光的 embedding 向量取平均,作为新笔记的 embedding 。
另外:
多个向量召回池(根据时间进行召回)
1小时,6小时,24小时,30天等。
(2) 类目召回
用户画像
- 感兴趣的类目:美食、科技数码、电影······
- 感兴趣的关键词:纽约、职场、搞笑、大学······
基于类目的召回
-
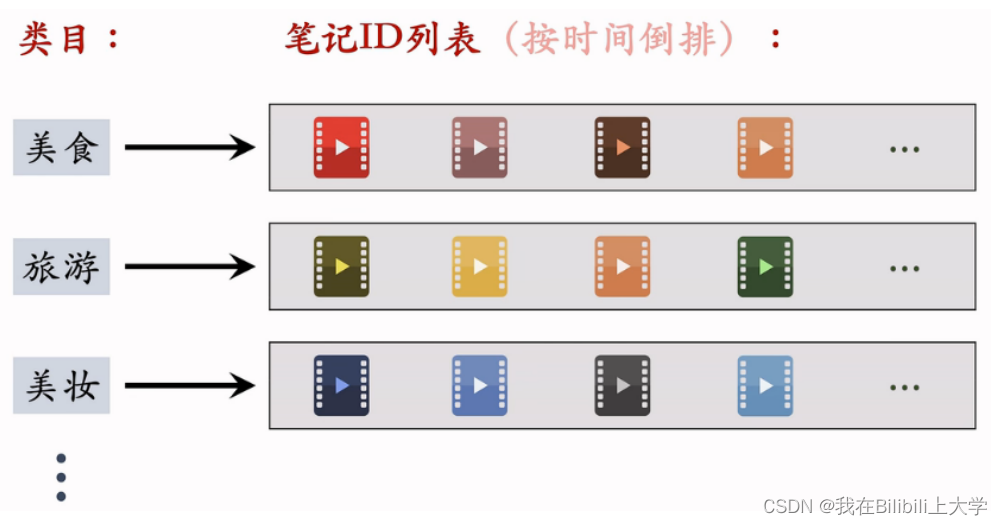
系统维护类目索引:
类目 —> 笔记列表
-
用类目索引做召回:
用户画像 —> 类目 —> 笔记列表
-
取回笔记列表上钱K篇笔记(即最新的K篇)
(3) 基于关键词的召回
-
系统维护关键词索引:
关键词 —> 笔记列表
-
根据用户画像上的关键词做召回
(4) 类目召回和关键词召回的缺点
缺点 1:只对刚刚发布的新笔记有效。
-
取回某类目/关健词下最新的 k 篇笔记。
-
发布几小时之后,就再没有机会被召回。
缺点 2 :弱个性化,不够精准。
3、聚类召回
(1) 基本思想
- 如果用户喜欢一篇笔记,那么他会喜欢内容相似的笔记。
- 事先训练一个神经网络,基于笔记的类目和图文内容,把笔记映射到向量。
- 对笔记向量做聚类,划分为 1000 cluster ,记录每个 cluster 的中心方向。( k-means 聚类,用余弦相似度。)
(2) 聚类索引
- 一篇新笔记发布之后,用神经网络把它映射到一个特征向量。
- 从 1000 个向量(对应 1000 个 cluster )中找到最相似的向量,作为新笔记的 cluster
- 索引: cluster —> 笔记ID列表(按时间倒排)
(3) 线上召回
- 给定用户 ID ,找到他的 last-n 交互的笔记列表,把这些笔记作为种子笔记。
- 把每篇种子笔记映射到向量,寻找最相似的 cluster 。(知道了用户对哪些 duster 感兴趣。)
- 从每个 cluster 的笔记列表中,取回最新的 m 篇笔记。最多取回 mn 篇新笔记。
(4) 内容相似度模型
提取图文特征:
图片通过CNN,文字通过BERT,分别得到特征向量。输入全连接层,得到笔记的特征向量。

两篇笔记内容相似度:
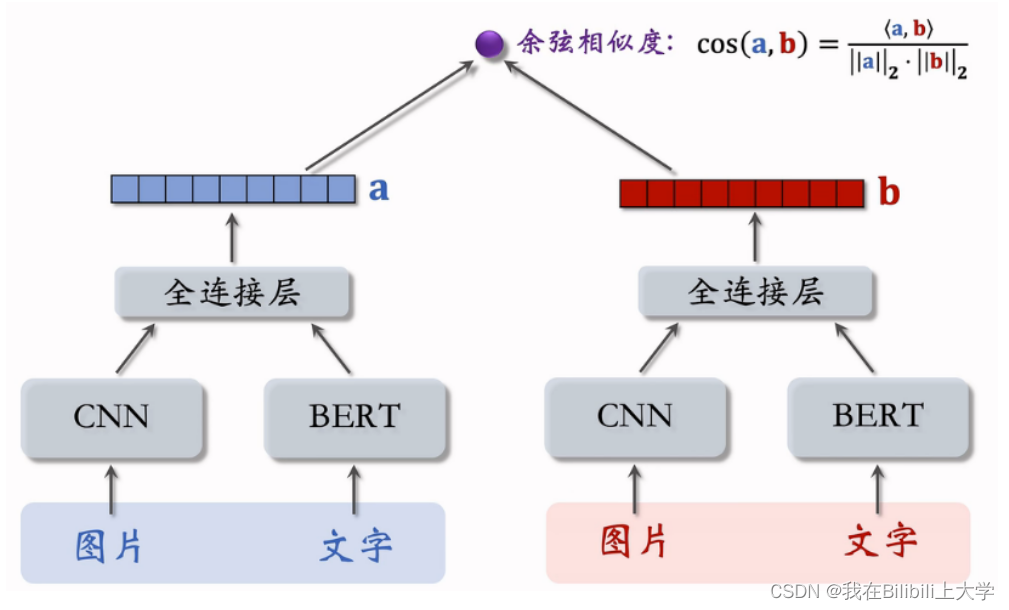
CNN和CERT是预先训练好的。
(5) 模型的训练
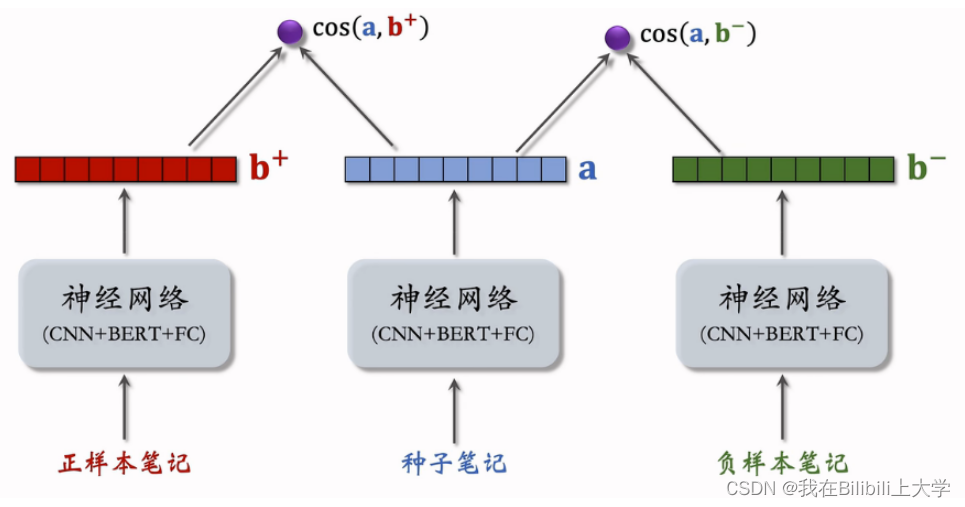
基本思想
估计 cos(a,b+) 大于 cos(a,b-) 。
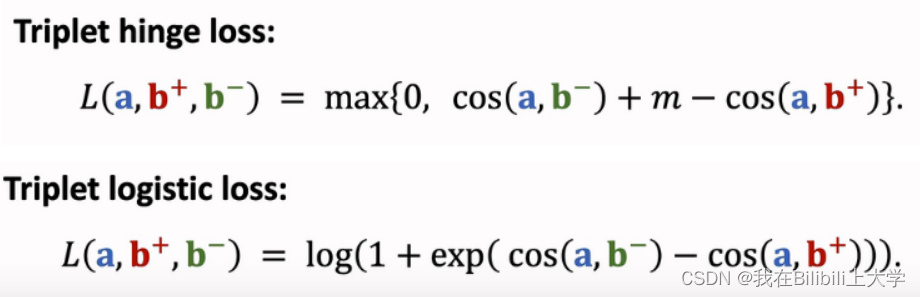
(6) 正负样本的选取
正样本:相似度高的笔记。
<种子笔记,正样本>
-
方法一:人工标注二元组的相似度
-
方法二:算法自动选正样本
-
筛选条件:
-
只用高曝光笔记作为二元组(因为有充足的用户交互信息)
-
两篇笔记有相同的二级类目,比如都是“莱谱教程”。
-
-
用 hcmCF 的物品相似度选正样本。
-
<种子笔记,负样本>
-
从全体笔记中随机选出满足条件的:
-
字数较多(神经网络提取的文本信息有效)
-
笔记质量高,避免图文无关。
-
(7) 聚类召回总结
基本思想:根据用户的点赞、收藏、转发记录,推荐内容相似的笔记。
线下训练:多模态神经网络把图文内容映射到向量。
线上服务:用户喜欢的笔记 —> 特征向量 —> 最近的 cluster —> 新笔记
4、Look-Alike人群扩散
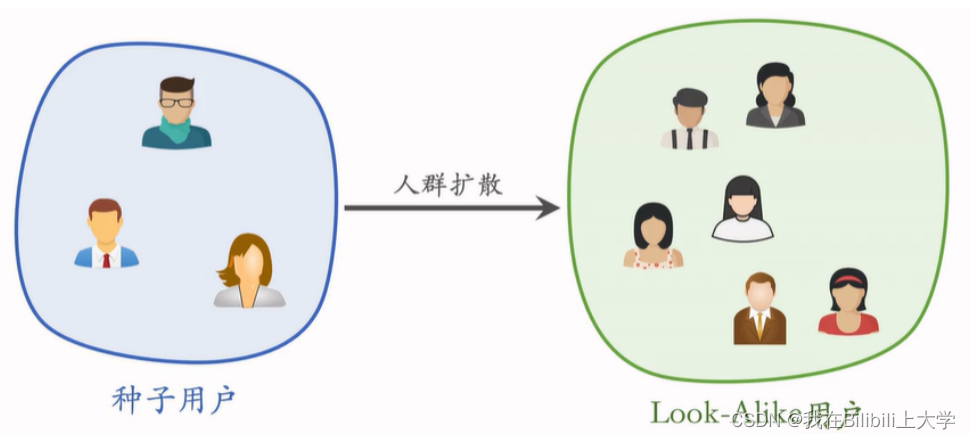
(1) Look-Alike人群扩散召回
- 点击点赞收藏转发—用户可能对新笔记感兴趣
- 把有交互的用户作为新笔记的种子用户
- 用Look-Alike在相似用户中扩散
根据种子用户,找出更多兴趣相似的用户。把新笔记扩散到更多Look-Alike用户。
(2) Look-Alike用于新笔记召回
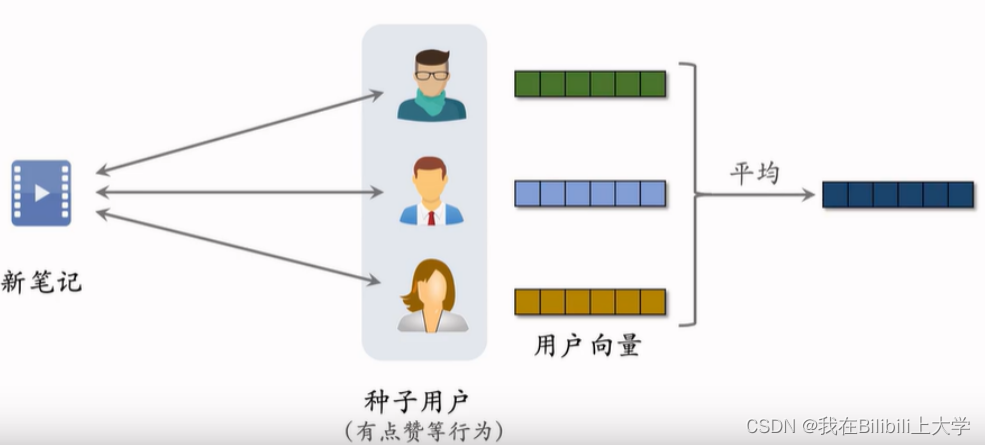
将得到的平均向量作为新笔记的表征,此向量反映出何种用户对此笔记感兴趣。
- 近线更新特征向量(近线:非实时更新,做到分钟级别更新便可以)
- 特征向量是有交互的用户向量取平均
- 每当有用户交互该物品,更新笔记的特征向量
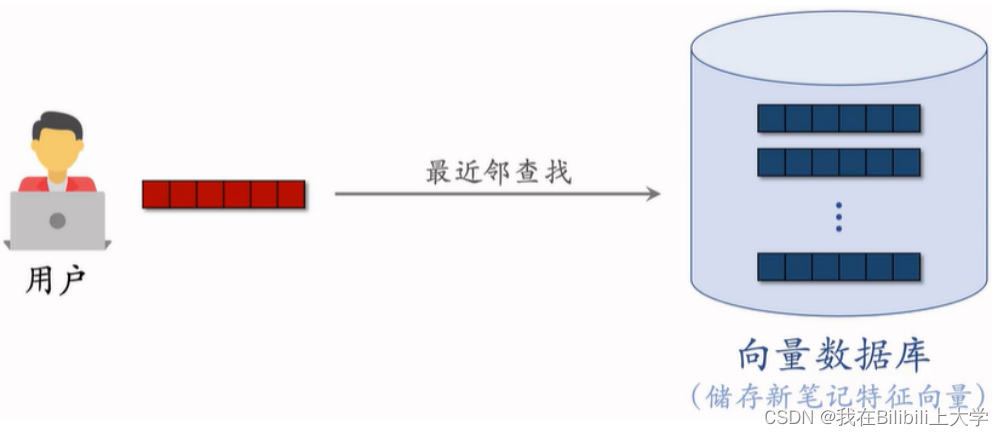
将用户的特征向量作为query,在向量数据库中做最近邻查找,取回N个物品,这个召回通道就是Look-Alike召回通道。
5、流量调控
(1) 冷启动的优化点
-
优化全链路(包括召回和排序)
每个环节都针对新笔记,保证走完链路被曝光
-
流量调控(流量怎么在新物品、老物品中分配)
流量向新笔记倾斜,帮助新笔记的曝光机会
(2) 扶持新笔记的目的
-
目的 1:促进发布,增大内容池。
-
新笔记获得的曝光越多,作者创作积极性越高
-
反映在发布渗透率、人均发布童
-
-
目的 2 :挖掘优质笔记。
-
做探索,让每篇新笔记都能获得足够曝光
-
挖掘的能力反映在高热笔记占比。
-
(3) 流量调控技术的发展
-
在推荐结果中强插新笔记。
-
对新笔记的排序分数做提权(boost)。
-
通过提权,对新笔记做保量。
保障新笔记在前24小时获得至少100次曝光,保量提权的计算和策略更加精细复杂
-
差异化保量。
根据质量决定曝光次数
(4) 新笔记提权
-
目标:让新笔记有更多机会曝光。
-
如果做自然分发,24小时新笔记占比为1/30。
-
做人为干涉,让新笔记占比大幅提升。
-
-
干涉粗排、重排环节,给新笔记提权。
优缺点:
-
优点:容易实现,投入产出比好。
-
缺点:
-
曝光量对提权系数很敏感。
-
很难精确控制曝光量,容易过度曝光和不充分曝光。
-
(5) 新笔记保量
- 保量:不论笔记质量⾼低,都保证 24 ⼩时获得 100 次曝光。
- 在原有提权系数的基础上,乘以额外的提权的系数,
权重的系数需要经过大量测验。
(6) 动态提权保量

蓝色数越大,红色数越小,提权系数就越大。
(7) 保量的难点
- 保量成功率远低于 100%
- 很多笔记在24⼩时达不到100次曝光。
- 召回、排序存在不⾜。
- 提权系数调得不好。
- 线上环境变化会导致保量失败
- 线上环境变化:新增召回通道、升级排序模型、 改变重排打散规则……
- 线上环境变化后,需要调整提权系数,很麻烦
- 给新笔记分数 boost 越多,对新笔记越有利?
-
好处:分数提升越多,曝光次数越多。
-
坏处:把笔记推荐给不太合适的受众。
- 点击率、点赞率等指标会偏低。 - 长期会受推荐系统打压,难以成长为热门笔记。- 1
- 2
- 3
(8) 差异化保量
保量和差异化保量
保量:不论新笔记质量⾼低,都做扶持,在前 24 ⼩ 时给 100 次曝光。
差异化保量:不同笔记有不同保量⽬标,普通笔记 保 100 次曝光,内容优质的笔记保 100~500 次曝光。差异化保量
- 基础保量:24 ⼩时 100 次曝光。
- 内容质量:⽤模型评价内容质量⾼低,给予额外保 量⽬标,上限是加 200 次曝光。
- 作者质量:根据作者历史上的笔记质量,给予额外 保量⽬标,上限是加 200 次曝光。
- ⼀篇笔记最少有 100 次保量,最多有 500 次保量。
达到扶持目标后,不再进行扶持。让新笔记自然成长,和老笔记竞争。
(9) 总结
- 流量调控:流量怎么在新⽼笔记之间分配。
- 扶持新笔记:单独的召回通道、在排序阶段提权。
- 保量:帮助新笔记在前 24 小时获得 100 次曝光。
- 差异化保量:根据内容质量、作者质量,决定保量 ⽬标。
6、AB测试
(1) 推荐系统标准的AB测试
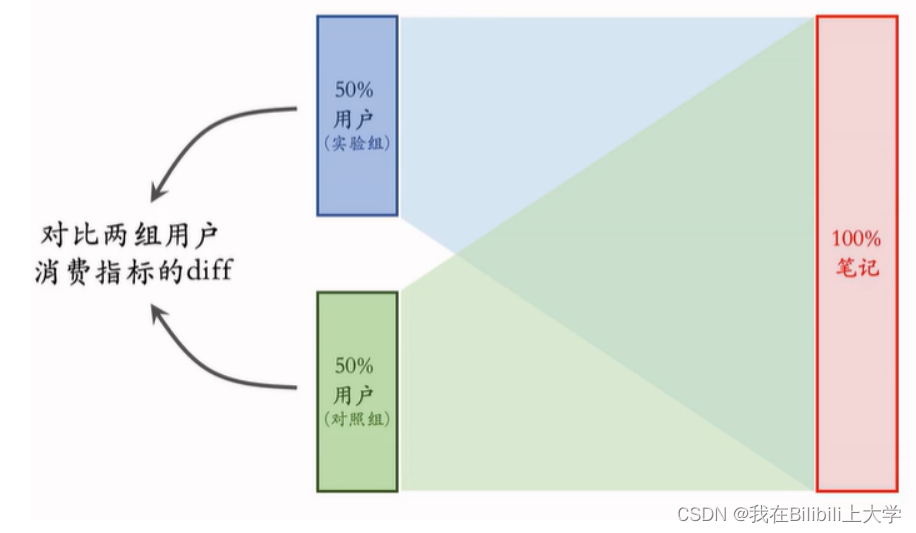
实验组用新策略,对照组用旧策略。
冷启动的测试需要测两类指标,一类是用户侧的消费指标,另一类是作者侧的发布指标。
(2) 用户侧实现
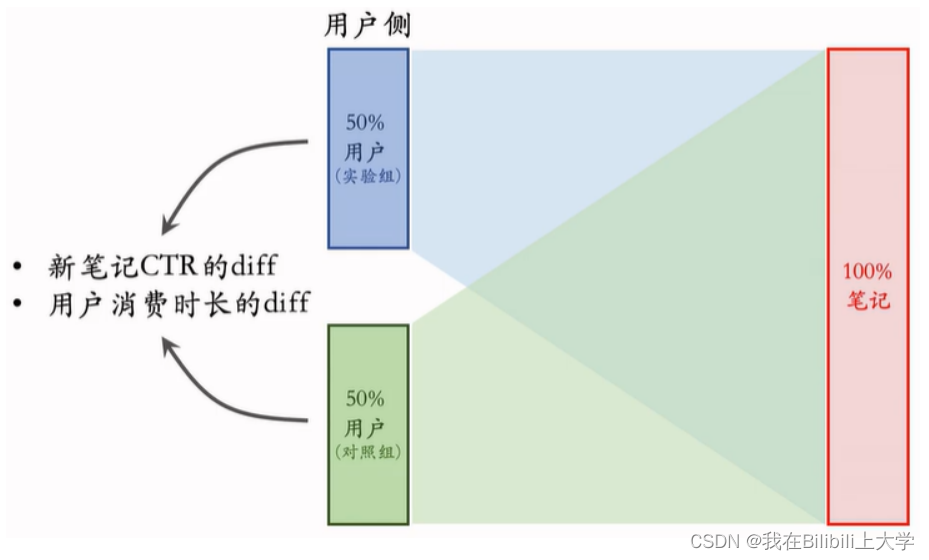
缺点
- 限定:保量 100 次曝光。
- 假设:新笔记曝光越多,⽤户使⽤APP时长越低。
- 新策略:把新笔记排序时的权重增⼤两倍。
- 结果(只看消费指标):
- AB测试的diff是负数(策略组不如对照组)。
- 如果推全,diff会缩⼩(⽐如 −2% —> −1%)。
(3) 作者侧实验
方案一:
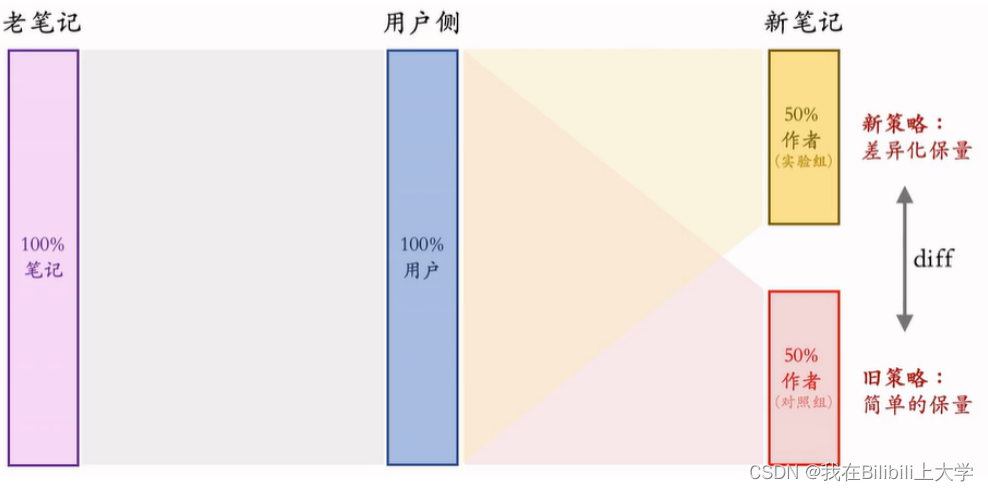
将新笔记分组,调查作者发布积极性。
缺点:
- 新笔记之间会抢流量
- 新笔记和⽼笔记抢流量
方案二:
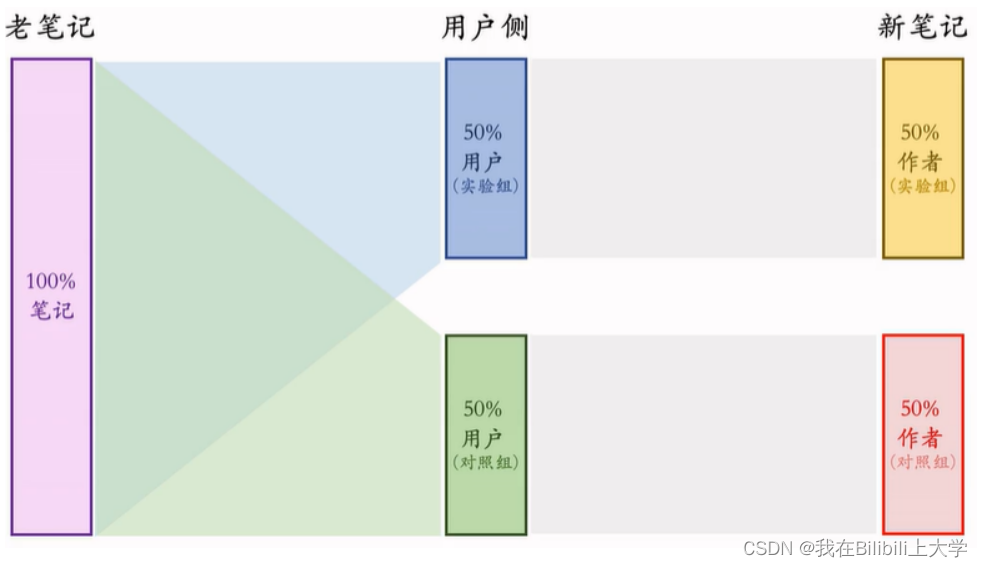
方案二比方案一的优缺点:
- 优点:新笔记的两个桶不抢流量,作者侧实验结 果更可信。
- 缺点:新笔记池减⼩⼀半,对⽤户体验造成负⾯ 影响。
- 相同:新笔记和⽼笔记抢流量,作者侧AB测试结 果与推全结果有些差异。
方案三:
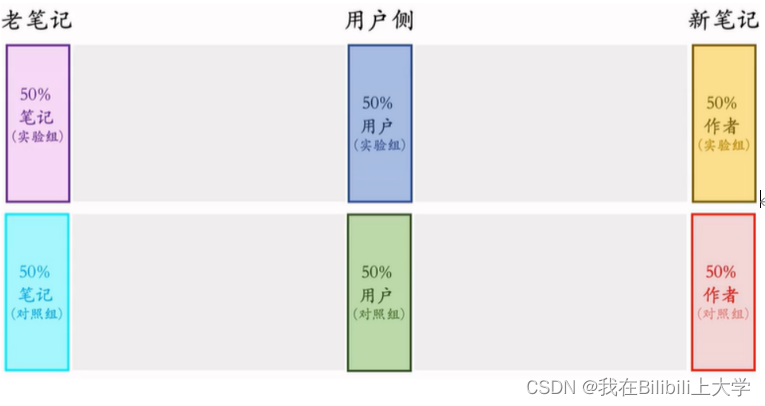
可能导致消费指标大跌。
(4) 总结
-
冷启的AB测试需要观测作者发布指标和用户消费指标。
-
各种AB测试的方案都有缺陷。
-
设计方案的时候,问自己几个问题:
- 实验组、对照组新笔记会不会抢流量?
- 新笔记、老笔记怎么抢流量?
- 同时隔离笔记、用户,会不会让内容池变小?
- 如果对新笔记做保量,会发生什么?
本文是在观看此系列视频做出的笔记,我觉得讲的超级好,干货满满
本文仅供学习参考
-
相关阅读:
记一次排查线上OOM详细过程和解决思路
Writing Tools I Use To Get More Views And Engagement On My Post
upload-labs通关(Pass01-Pass05)
后端八股笔记-----mysql
Linux 网络编程 TCP/UDP编程
nginx的location中配置路径讲解
elasticsearch、Kibana 与logstash分布式使用方案(珍藏版)
【简单的留言墙】HTML+CSS+JavaScript
22-9-17学习笔记
vue当中的mixin混入、插件使用
- 原文地址:https://blog.csdn.net/qq_43693424/article/details/126179046