-
Gitee 图床被屏蔽后,我搭建了一个文件系统并封装成轮子开源
前言
前段时间Gitee图床突然"暴雷",导致许多写作者笔记、博客、网站等图片全部无法访问,一时间哀怨四起,大家也纷纷意识到图片备份的重要性,博主也在上面许多作者的行列中,花费了一天时间恢复博客、以及个人网站的图片,同时迁移到腾讯OSS上,也开始着手搭建个人的文件系统平台。
在日常业务开发中,文件存储无处不在,小到图片存储访问,大到svg、zip、视频、音频等文件上传下载,如何将这些文件进行存储,并提供访问呢?此时就离不开文件系统了。
本篇文章内容:详细介绍如何在海量文件系统中选择合适的文件系统、完成自己的文件系统搭建、并使用程序完成文件的上传下载功能。
阅读说明: 如果只是了解如何搭建和使用程序实现文件上传、下载,可直接通过目录跳转到对应章节,无需阅读完全文。

数据类型划分
在引入文件系统之前,先来认识下相关的概念,可以更好地帮助了解后续的文件系统。在计算机世界中,数据可以简单分为:结构化数据、半结构化数据、非结构化数据三大类。
结构化数据:
指的是能够根据预定义的模型结构化或者预定义的方式组织的数据。 简单来说,能够将信息使用某种统一的结构(如数字、文字、符号等)加以表示,该种数据可以被称为结构化数据。
通常结构化数据可以通过关系型数据库进行存储和管理,具体表现为二维形式,以行为单位,每行可以表示一个实体的信息,每行的数据属性都是相同的。
示例图片:

非结构化数据:
与结构化数据相反,该类型的数据没有一定预定义好的数据模型或者没有一个预定义的方式来组织的数据,如音频、视频、图片、邮件等。该种类型的数据没有一个固定的结构,格式可能是多种多样的。
示例图片:

半结构化数据:
介于结构化(如关系型数据库中的数据)和非结构数据(音频、视频、图片等)之间的一种数据,它可以是自描述的(即结构可以是自定义,格式并不固定,如相同的键值下存储的数据可能是数值、字符、列表等,结构和内容是混在一起的,无明显区分),常见的如JSON、XML,HTML文档等。
示例图片:

分布式文件系统
在上文谈到了数据类型的划分,通常结构性数据都可以通过关系型数据进行存储和管理,而如果想管理非结构性数据,则需要使用到文件系统。
文件系统又可以分为:一般(本地)文件系统和分布式文件系统,具体特点如下:

根据存储需求,我们还可以将文件系统简单划分为“第三方文件系统”和“己方文件系统”。
“第三方文件系统”:即可以通过购买第三方厂商已经搭建好的文件系统,实现非结构类型数据存储,常见的有阿里云的OSS、腾讯云的OSS等,这种类型特点就是简单,能够购买即可使用,缺点就是数据需要存储在第三方,对于一些敏感数据可能会存在风险。
“己方文件系统”:即可以通过开源或者第三方组件,在自己服务器中搭建属于自己的文件系统,常见用于搭建文件系统的框架有:Seaweedfs、FastDfs、MinIO、Ceph、HDFS、TFS等。 这类型的特点就是数据能够存储在自己的服务器,能够最大程度控制安全问题,许多国企项目有这种强制要求,缺点就是搭建过程比直接购买第三方的服务更复杂,需要成本更高,且需要自己维护。
两种类型对比:
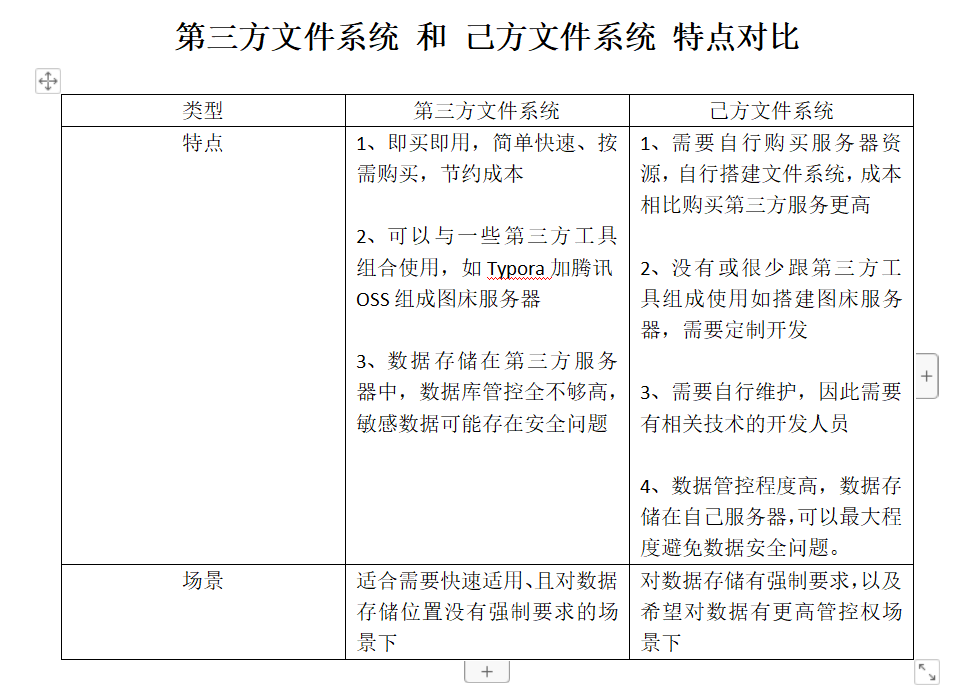
简单地对文件系统类型进行了分析后,下面就开始对搭建“己方文件系统”时技术选型因素做一个详细介绍,以便最大程度选择适合自己的文件系统组件。
技术选型
在搭建文件系统时,主要考虑了以下几个纬度指标进行技术选型:
- 易用性: 该文件系统主要用于博客图片等海量小文件存储,对应文件系统应该是轻量级的,且易于搭建和管理
- 可靠性: 使用文件系统进行统一文件管理,那么就要保证考虑单点故障问题,保障文件的高可用性
- 拓展性: 随着时间积累,小文件的累计也会变成"大文件",因此文件系统的是否易于拓展也是选型中一重要考虑指标
- 社区活跃度: 社区活跃度高的第三方组件,社区的文档、采坑经验、更新迭代等会更加完善,能够帮助快速集成,定位问题,减少风险。
- 节约成本: 存储海量文件,占用的磁盘空间大小、访问时需要的资源也不容小觑,节约成本也是选型需要考虑的又一重要因素
Seaweedfs
一款Apache基金会开源项目,基于go语言开发的高度可拓展开源的分布式存储系统、它支持基于Restful API风格进行增、删、查操作,非常适用于处理小文件。 设计之初是为了对Facebook的一篇论文的实现,用于优化内部图片的存储和获取,后来在此基础上进行不同迭代,从而得出seaweedfs产品。
官方描述,它具有以下特点:
- 存储数十亿的文件(storeage billions of files)
- 快速获取文件(serve the files fast)
- O(1)磁盘读取速度

Seaweedfs组成
说明:图源网络(侵联删)

Seaweedfs核心概念介绍
- Node: 系统抽象节点,具体实现有DataCenter、Rack、DataNode,可以理解成编程语言中的接口。
- DataCenter: 数据中心,对应现实生活中的机房,可以存在多个。
- Rack: 机架,对应现实生活中机房存放服务器的机架,一个DataCenter中可以存在多个Rack,但是一个Rack只能属于一个DataCenter。
- DataNode: 具体的存储节点,用于管理、存储逻辑卷(Volume)
- Master: 用于管理文件卷与服务器磁盘的映射(即管理存储文件和fid之间的映射关系)
- Volume: 逻辑卷,存储的逻辑结构,在它之下是使用Needle来存储具体的文件
- Needle: 逻辑卷中实际的存储对象,存储真实文件
- Collection: 文件集,可以分布在多个逻辑卷上,如果在存储文件的时候没有指定collection,则默认使用""

Seaweedfs特点分析
-
易用性: Seaweedfs支持使用二进制(解压运行即可)、Docker、编译源码等方式部署,支持Restful API风格完成增删改等操作,简单方便,且提供了可视化界面,方便运维和管理。
-
可靠性: Seaweedfs支持多Master节点和备份机制,能够有效避免单点故障
-
拓展性: Seaweedfs一个Master节点下可挂载多个Volume节点,空间不足时,可以添加磁盘或者机器启动新的Volume实现拓展存储。
-
社区活跃性: Seaweedfs作为Apache基金会下的开源项目,在Github上已经14.9K的star,且官方提供了详细的项目介绍文档和部署文档,社区活跃度相比同类产品也是非常不错。
-
节约成本: Seaweedfs官方描述,每个文件的元数据只有40字节的磁盘存储开销。O(1)磁盘读取,且对大数据量的小文件存储进行了优化,意味着能用更少的空间存储更多的资源,节省开支成本。

综上分析,可以发现Seaweedfs具有的特点能够完美契合我们在技术选型时考虑的因素,因此,使用Seaweedfs框架搭建文件系统是相对合适的,下面就开始实战篇章-完成对Seaweedfs的搭建和使用。
实战-使用Seaweedfs搭建文件服务器
在开始搭建之前,先简单介绍下Seaweedfs中不同模块的具体作用:
- Weed master : 开启一个master服务器
- Weed volume : 开启一个volume 服务器
- Weed filer : 开启一个指向一个或多个master服务器的file服务器
- Weed upload: 上传一个或多个文件
- Weed server: 启动一个服务器,包括一个volume服务器和自动选举一个master服务器
搭建Seaweedfs文件服务器
说明:Seaweedfs是基于Go语言开发,它支持通过weed进行源码编译安装(需有go环境,该方式主要是对seaweedfs有自定义拓展的时候使用),同时它也提供已经编译好的二级制包,可以直接解压使用(无需依赖Go环境,演示使用该种方式)
本次演示的Seaweedfs版本为:0.99,目的是方便后续使用JAVA程序集成Seaweedfs,因为使用Seaweedfs较高的版本,第三方提供的Seaweedfs客户端会有一些问题。
一、上传压缩包并解压
- rz -be xx.seaweedfs.tar.gz 上传文件
- tar -zxvf seaweedfs-0.99.tar.gz 解压文件

二、启动Master和Volume服务
说明:因为本篇文章篇幅较长,所以不在此处详细介绍启动参数的具体含义,有需要的可以参考官方网站或者下面这篇博客,都已经描述得非常清楚。
-
/usr/local/seaweedfs0.99/seaweedfs/sbin/weed master -mdir=/usr/local/seaweedfs0.99/seaweedfs/data/master -port=9333 -defaultReplication=000 -ip=xxx主服务IP地址 启动master主服务
-
/usr/local/seaweedfs0.99/seaweedfs/sbin/weed volume -dataCenter=dataCenter1 -rack=rack1 -dir=/usr/local/seaweedfs0.99/seaweedfs/data/volume -max=5 -mserver=主服务IP地址:9333(端口) -port=9040 -ip=服务ip地址- 启动volume服务

三、浏览器访问可视化界面
- http://ip地址:9333/

JAVA程序集成Seaweedfs完成程序操作文件系统
说明:因为文字篇幅原因,演示只放部分核心代码,全部源码已经开发到【轮子之王】开源项目中,欢迎大家到下面地址访问获取(如有帮助,可给star哦)。
一、引入客户端依赖和配置
// 依赖 <dependency> <groupId>org.lokra.seaweedfs</groupId> <artifactId>seaweedfs-client</artifactId> <version>0.7.3.RELEASE</version> </dependency> // seaweedfs文件服务器信息 seaweedfs: host: 127.0.0.1 port: 9333- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
二、封装操作系统工具类
/** * @description: 上传单个文件到文件服务器 * @param: file * @return: 文件的fid + 文件的请全访问地址 * @author: it */ public String uploadFile(MultipartFile file) throws Exception { FileSource fileSource = getFileSource(); FileTemplate fileTemplate = new FileTemplate(fileSource.getConnection()); // 上传文件 FileHandleStatus handleStatus = fileTemplate.saveFileByStream(file.getOriginalFilename(), file.getInputStream(), contentType); // 获取上传文件的访问地址 String fileUrl = fileTemplate.getFileUrl(handleStatus.getFileId()); // 关闭当前连接 fileSource.shutdown(); return handleStatus.getFileId() + StrUtil.DASHED + fileUrl; } /** * @description: 根据文件ID删除文件 * @author: it */ public void deleteFileByFid(String fileId) throws Exception { FileSource fileSource = getFileSource(); FileTemplate fileTemplate = new FileTemplate(fileSource.getConnection()); fileTemplate.deleteFile(fileId); fileSource.shutdown(); } /** * @description: 根据文件下载文件 * @param: fid * @param: response * @param: fileName * @author: it */ public void downloadFileByFid(HttpServletResponse response, HttpServletRequest request, String fid, String fileName) throws Exception { FileSource fileSource = getFileSource(); FileTemplate fileTemplate = new FileTemplate(fileSource.getConnection()); StreamResponse fileStream = fileTemplate.getFileStream(fid); // 设置响应头 response.setContentType(CommonConstant.CONTENT_TYPE); response.setCharacterEncoding(CommonConstant.UTF_8); String encodeFileName = buildingFileNameAdapterBrowser(request, fileName); response.setHeader(CommonConstant.CONTENT_DISPOSITION, CommonConstant.ATTACHMENT_FILENAME + encodeFileName); // 读取并写入到响应输出 InputStream inputStream = fileStream.getInputStream(); byte[] fileByte = new byte[inputStream.available()]; inputStream.read(fileByte); response.getOutputStream().write(fileByte); response.getOutputStream().flush(); fileSource.shutdown(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
三、测试结果
说明:每次文件成功上传后都会给对应的文件生成唯一的fid,对文件的删、查都通过该fid实现。
1、上传文件

2、下载文件
3、删除文件

写在最后
至此,从文件系统的选型、搭建到程序集成都已完成,但该文件系统与第三方OSS服务还有一个小的区别,就是无法使用类似PicGo的工具将它做成对应的图床,这个有需要的话后续再研究做个开源插件吧。
“冰冻三尺非一日之寒”,从了解一门技术到真正使用它,需要用非常多的时间去认识熟悉。写作也是如此,希望后续能够输出更多优质的文章帮助大家,大家有任何想法也可以在文章下方留言,
如果觉得文章有帮助,欢迎给博主点赞、关注。文章中所有源码已开源到轮子之王项目,有需要者可通过下方链接跳转:
-
相关阅读:
10月12日
简单三招,就能将ppt翻译成英文,快来学习
Threejs 3D模型入门项目
【牛客SQL必知必会 3天热身】01. 基本的检索、排序、过滤
缺少d3dx9_43.dll怎么解决 win系统如何运行dll文件?
Win10系统- 远程桌面使用及出现的 问题
ruoyi框架中添加sharding sphere5.0.0分表(通过spi添加自定义分表策略)
字符/字符串算法专题-思维新解(1)
openssl升级
JS—函数相关例题解析
- 原文地址:https://blog.csdn.net/qq_40891009/article/details/126114259
