-
linux基础
一 文件系统

/根目录的FHS定义/根目录与开机系统有关
/bin:放置常用指令,如:cat, chmod, chown, date, mv, mkdir, cp, bash等。存放了很多系统启动需要的命令以及单人维护模式也可使用的命令。
/boot:放置开机会用到的文件。
/dev:放置设备文件,如:/dev/null, /dev/zero等。
/etc:放置系统配置,只有root有权限修改,其他用户只读。如/etc/init.d/放置预设启动。
/home:用户目录的根目录,如/home/kkk
/lib:函数库
/media:软盘,光盘等的挂在目录,如: :/media/floppy, /media/cdrom
/mnt:临时挂在目录。
/opt:软件安装目录
/root:root用户的目录
/sbin:放置开机、修复、还原系统所需要的命令,通常是系统管理员才会用到的命令,如fdisk, fsck, ifconfig, init, mkfs等。
/srv:作为服务器时放置的文件,如:/srv/www/里面放置网页文件等。
/tmp:放置临时文件。
/lost+found:放置系统发生错误时的dump文件。
/proc:虚拟文件系统,里面的文件都放在内存中,所以本身不占用硬盘空间
/sys:类似/proc,也是虚拟文件系统,记录核心资料。
/selinux:类似/proc,也是虚拟文件系统,存放程序存取权限。
/usr目录的FHS定义
/usr与软件安装、执行有关,usr不是user的缩写,而是Unix Software Resource的缩写,unix软件资源。
/usr/bin:放置常用指令,通常是软件提供的指令,与系统启动无关
/usr/include:放置C、C++的头文件。
/usr/lib、/usr/lib64:放置函数库
/usr/local:放置系统管理员自行安装的软件,在不想删除系统自带的软件,又希望安装新软件时,就安装到这里。
/usr/sbin:系统管理员所用指令,但不是系统正常运行必须的,例如作为服务器时的指令。
/usr/share:放置共享文档,如:
/usr/share/man:线上说明文件
/usr/share/doc:软体杂项的文件说明
/usr/share/zoneinfo:与时区有关的时区档案
/usr/src:放置源码/var目录的FHS定义
/var与系统运行有关。
/var/cache:程序运行缓存
/var/lib:程序所需的函数库,如: /var/lib/mysql、/var/lib/rpm
/var/lock:上锁的文件或目录,如刻录光碟写时不能读取。
/var/log:登录日志,如/var/log/messages、/var/log/wtmp
/var/mail:邮件,通常跟/var/spool/mail是链接
/var/run:放置已启动服务的PID
/var/spool:放置排队资料,通常使用以后就会被删除
-
/bin: 命令和应用程序。
-
/boot: 这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。
-
/dev : dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。
-
/etc: etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。
-
/home: 用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。
-
/lib: lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。
-
/lost+found: 这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
-
/media: linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。
-
/mnt: 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。
-
/opt: opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
-
/proc: proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
-
/root: 该目录为系统管理员,也称作超级权限者的用户主目录。
-
/sbin: s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的系统管理程序。
-
- /selinux: 这个目录是 Redhat/CentOS 所特有的目录,Selinux 是一个安全机制,类似于 windows 的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
-
/srv: 该目录存放一些服务启动之后需要提取的数据。
-
/sys:
这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。
sysfs 文件系统集成了下面3种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
-
/tmp: tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。
-
/usr: usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。
-
/usr/bin: 系统用户使用的命令和应用程序。
-
/usr/sbin: 超级用户使用的比较高级的管理程序和系统守护程序。
-
/usr/src: 内核源代码默认的放置目录。
-
/var: var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
-
/run: 是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
二 启动过程

1、BIOS启动
BIOS是写入到主板上的一个韧体(韧体就是写入到硬件上的一个软件程序)。开机的时候,BIOS是计算机系统会主动执行的第一个程序。BIOS主要的一个功能就是存储了磁盘的启动顺序,它会按照启动顺序去读取能够开机的硬盘的第一个扇区的MBR信息
2、读取MBR
磁盘的第一个扇区(大小为512bytes)主要记录两个信息:主引导分区(MBR)和分区表。其中,MBR大小为446bytes用于存储引导加载程序(BootLoader),分区表大小为64bytes记录硬盘分区状态,最后2bytes用于MBR的有效性检查。BIOS启动的目的就是让MBR中引导加载程序启动
3、引导加载程序(Boot loader)
目前常用的引导加载程序就是grub,它是一支可读取内核文件并让其执行的软件。grub程序会根据/boot/grub/grub.conf文件查找Kernel的信息,然后开始加载Kernel程序,当Kernel程序被检测并在加载到内存中,grub就将控制权交接给了Kernel程序
4、Kernel加载
内核(Kernel)是Linux系统最主要的程序,它的作用就是进行硬件检测并加载驱动程序。由于Kernel为了精简且以压缩的文件形式存储在硬盘中,故只保留了最基本的模块,并没有各种硬件的驱动程序,也就无法识rootfs所在的设备,故产生了initrd这个文件。该文件是在安装系统时产生的,是一个临时的根文件系统(rootfs)。它装载了必要的驱动模块,当Kernel启动时,可以从initrd文件中装载驱动模块,直到挂载真正的rootfs,然后将initrd从内存中移除。硬件驱动成功后,Kernel会主动调用init进程
5、启动Init进程
init是系统启动的第一个进程,是所有进程的父进程。init会根据/etc/inittab中设定的动作进行脚本的执行,init执行第一个脚本/etc/rc.d/rc.sysinit来准备软件执行的操作环境(如网络、时区、设定主机名,挂载文件系统等)。系统的操作环境准备好之后,接下来就是系统服务的启动
6、根据Run-level 进行服务启动
runlevel,系统运行级别(Linux系统有7个级别,哪7个请自行百度),不同的级别会启动的服务不一样,init会根据定义的级别去执行相应目录下(/etc/rc.d/rcN.d)的脚本,该目录下的脚本只有K和S开头的文件,K开头的文件为开机需要执行关闭的服务,S开头的文件为开机需要执行开启的服务
7、用户自定义开机启动程序
完成默认runlevel指定的各项服务的启动后,系统最后会自动执行/etc/rc.d/rc.local这个脚本(该脚本的作用请看大标题),至此,系统启动完成,你可以看到登录界面啦
三 文件与目录操作
liux一切皆文件
cd 切换目录
pwd 显示当前所在目录
mkdir 创建目录
rmdir 删除空目录
ls 查看
cp 复制文档
rm 删除
mv 移动
cat查看
touch 创建文件,修改文件时间
查看文件类型 file
搜索命令 which
基于索引搜索whereis和 locate四 硬盘

硬件对应的文件:

第一个扇区MBR整个硬盘的第一个扇区也叫引导扇区(硬盘引导扇区不属于任何一个分区),记录了特殊的内容,512Byte中:
前446Byte叫MBR段,(MBR段可以安装boot loader,即开机管理程序, 广义的MBR包含整个扇区)。
后面64Byte记录分区信息,也叫分区表,一共记录了4个分区,每个分区记录占16Byte,分为柱面开始位置和柱面结束位置,各8Byte
因此一块IDE硬盘的4个分区名为, /dev/hda1、/dev/hda2、/dev/hda3、/dev/hda4
每个分区都有引导扇区,叫DBR,里面也用于安装boot loader
分区
1个硬盘最多分为4个区,主分区和扩展分区加起来最多4个。
扩展分区最多只能有1个
扩展分区可以再分成多个逻辑分区(),IDE硬盘最多有59个逻辑分割(5号到63号,1、2、3、4号为系统保留), SATA硬盘最多有11个逻辑分割(5号到15号,1、2、3、4号为系统保留)。
能格式化的有主分区、逻辑分区,而扩展分区本身不能直接格式化。
分区的最小单位是柱面。
分区和目录

五 EXT2 文件系统
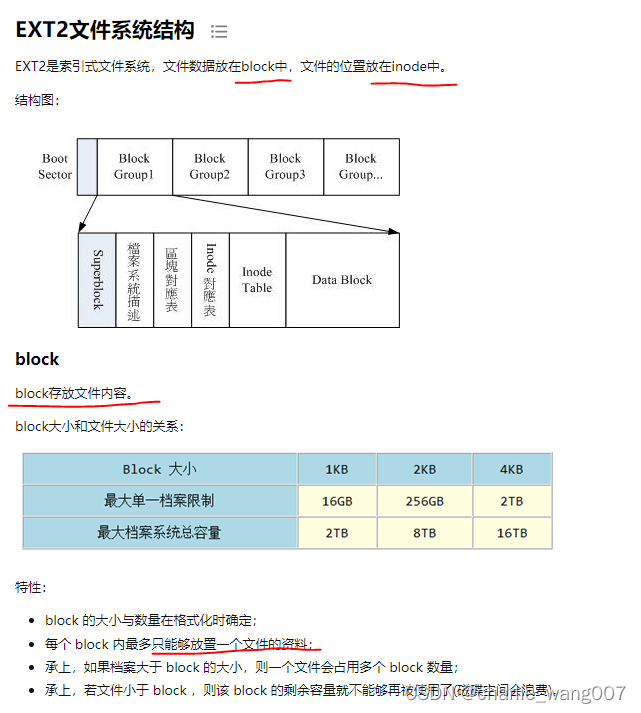
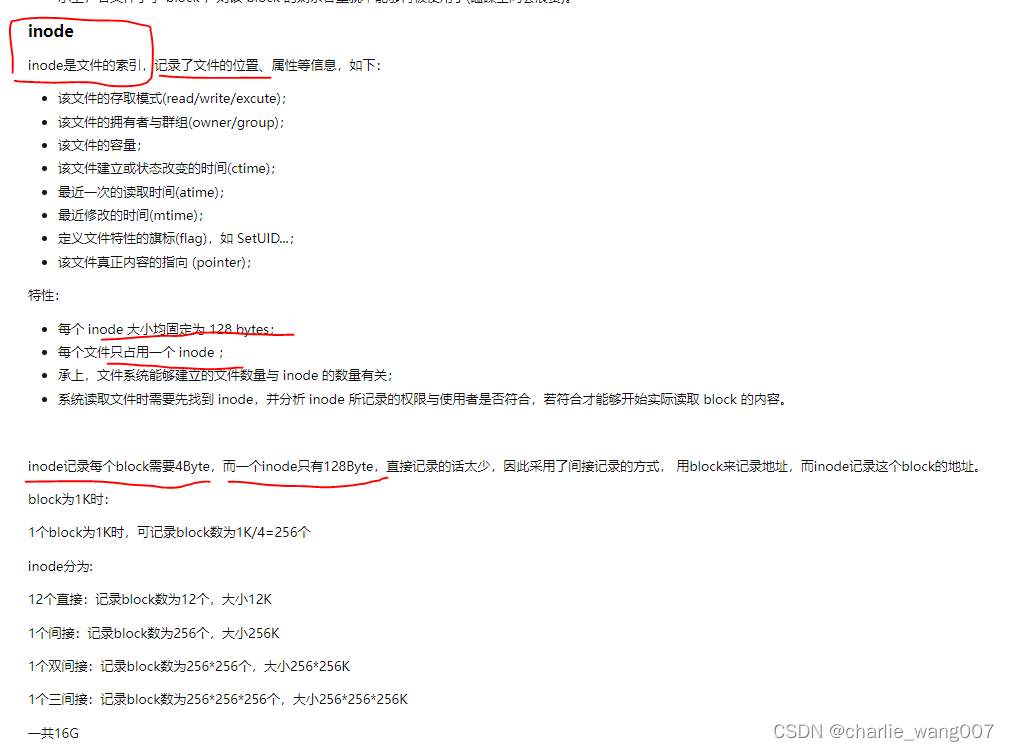
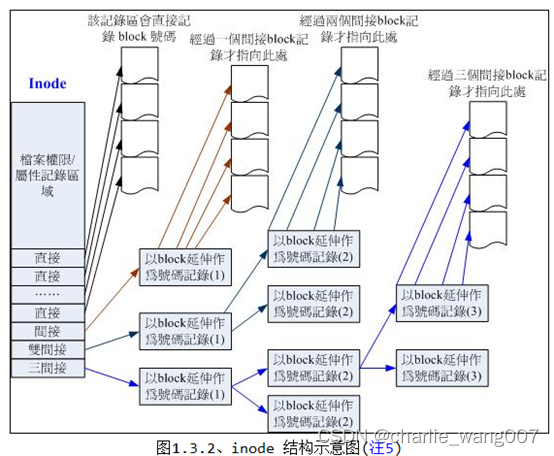
block bitmap (区块对照表)
记录了哪些block是空的。inode bitmap (inode 对照表)
记录了哪些inode是空的。新建文件的流程
检查权限–找空闲innod–找空闲block----写入数据----建立innod与block指向–更新两个bitmap
1、先确定使用者是否有该所在目录的w和x权限
2、根据 inode bitmap 找到没有使用的 inode 号码,并将新档案的权限/属性写入;
3、根据 block bitmap 找到没有使用中的 block 号码,并将实际的资料写入 block 中,且更新 inode 的 block 指向资料;
4、将刚刚写入的 inode 与 block 资料同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
inode bitmap、block bitmap、superblock由于经常改变,所以也叫metadata,中介资料
六 日志式档案系统 Ext3
在某些情况下,metadata的数据可能跟实际资料存放不一致,比如新建过程中断电等,这就需要对所有文件进行检查,很费时。
Ext3采用日志记录的方式,新建文件前记录日志,文件创建或更新后再写入日志,这样只用检查日志即可发现有没有问题。
七 VFS虚拟文件系统
linux通过VFS管理文件系统,比如不同分区的文件系统不同时,不需要手动指定文件系统读取,而由VFS自动转换

查看容量df

分析容量du

八 硬链接和软链接
硬链接(同一变量两个名字)
由于目录的block块中存了文件名与文件的inode,如果2个文件名的inode相同,则它们互为硬链接(也叫实体链接),都指向了同一个文件(其实并没有什么硬链接,只是两个地址指向了同一个文件)。
ln /tmp/1.txt /tmp/aaa/a
创建/tmp/aaa下的硬链接a,链接到/tmp/1.txt
ln /tmp/1.txt b.txt
在当前目录创建硬链接1.txt,链接到/tmp/1.txt
软链接(指针变量)
软链接也叫符号链接,其实是一种类型的文件,文件的内容指向了另一个文件,类似于快捷方式。
九 压缩工具
压缩工具
tar,gzip的使用方法如下:
压缩一组文件为tar.gz后缀: #tar cvf backup.tar /ect。 #gzip -q backup.tar或tar cvfz backup.tar.gz /etc。
释放一个后缀为tar.gz的文件:#gunzip backup.tar.gz。 #tar xvf backup.tar或 #tar xvfz backup.tar.gz。
用一个命令完成压缩:#tar cvf -/etc/ |gzip -qc > backup.tar.gz。
用一个命令完成释放:# gunzip -c backup.tar.gz | tar xvf -。
如何解开tar.Z的文件? #tar xvfz backup.tar.Z 或 #uncompress backup.tar.Z 。 #tar xvf backup.tar。
如何解开.tgz的文件?#gunzip backup.tgz。
如何压缩和解压缩.bz2的包?#bzip2 /etc/smb.conf,这将压缩文件smb.conf成smb.conf.bz2。#bunzip2 /etc/smb.conf.bz2这将在当前目录下还原smb.conf.bz2为smb.conf。十 安装工具
本地 -RPM
安装工具
RPM是世界著名的Red Hat公司推出的一种软件包安装工具,全称为Redhat Package Manager。RPM的出现提供了一种全新的软件包安装方法,在方便性上甚至超过了微软的Windows。下面我就介绍一下RPM的基本使用方法。
安装一个包:# rpm -ivh < rpm package name>
升级一个包:# rpm -Uvh < rpm package name>
移走一个包:# rpm -e < rpm package name>
安装参数:–force 即使覆盖属于其它包的文件也强迫安装 。–nodeps 如果该RPM包的安装依赖其它包,即使其它包没装,也强迫安装。
查询一个包是否被安装:# rpm -q < rpm package name>
得到被安装的包的信息:# rpm -qi < rpm package name>
列出该包中有哪些文件:# rpm -ql < rpm package name>
列出服务器上的一个文件属于哪一个RPM包:#rpm -qf 文件名称
可综合好几个参数一起用:# rpm -qil < rpm package name>
列出所有被安装的rpm package: # rpm -qa < rpm package name>在线-YUM
1、yum check-update:列出所有可更新的软件清单命令;
2、yum update:更新所有软件命令;
3、yum install :仅安装指定的软件命令;
4、yum update :仅更新指定的软件命令;
十一 重定向
我们知道,Linux 中标准的输入设备默认指的是键盘,标准的输出设备默认指的是显示器。而本节所要介绍的输入、输出重定向,完全可以从字面意思去理解,也就是:
输入重定向:指的是重新指定设备来代替键盘作为新的输入设备;
输出重定向:指的是重新指定设备来代替显示器作为新的输出设备。通常是用文件或命令的执行结果来代替键盘作为新的输入设备,而新的输出设备通常指的就是文件。
注意:如果重定向操作符右边是fd,前面要加上&(固定语法)
如果重定向操作符右边是 f d ,前面要加上 & \color{#A0A}{如果重定向操作符右边是fd,前面要加上\&} 如果重定向操作符右边是fd,前面要加上&
eg:
[root@localhost ~]# cat /etc/passwd
#这里省略输出信息,读者可自行查看
[root@localhost ~]# cat < /etc/passwd
#输出结果同上面命令相同
eg:创建一个文件8,输入输出来自dev/tcp/百度linux会自动创建一个socket连接

十二 管道
1.管道概念
管道是Linux中的最古老的通信方式;我们把一个进程链接到另一个进程的一个数据流称为一个"管道";- 1

1 匿名管道
1创建匿名管道
int ret=pipe(fd) fork() 父进程共享管道给子进程- 1
- 2
在linux中 bash遇到管道 | ,会自动启动两个子进程分别执行管道左右两侧的命令:


2 利用管道 实现进程之间的通信(匿名管道)

实现过程:


3 管道的本质:在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。

4.匿名管道读写规则1 当没有数据可读时O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。 2 当管道满的时候O_NONBLOCK disable: write调用阻塞,直到有进程读走数据O_NONBLOCK enable:调用返回-1,errno值为EAGAIN如果所有管道写端对应的文件描述符被关闭,则read返回0 3 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出 4 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。 5 当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5 .匿名管道特点
1 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信; 2 通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。 3 管道提供流式服务一般而言,进程退出,管道释放,所以管道的生命周期随进程一般而言,内核会对管道操作进行同步与互斥管道是半双工的; 4 数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;- 1
- 2
- 3
- 4
- 5
- 6
- 7
两个需要注意的坑:

1,进程4398定义一个变量a=1
{令a=9;输出一串字符} 管道连接cat输出
再查看变量a的值,并没有重新赋值成9
因为bash是命令解释,遇到管道的时候,会启动两个子进程分别执行管道左右两边的命令 会启动两个子进程分别执行管道左右两边的命令 \color{#A0A}{会启动两个子进程分别执行管道左右两边的命令} 会启动两个子进程分别执行管道左右两边的命令
而父进程与子进程之间有隔离,新的赋值并不会改变父进程的变量a
2,$$的优先级高于管道 |
的优先级高于管道 \color{#A0A}{的优先级高于管道} 的优先级高于管道
第一个命令用$$,进程先拿到pid,在输出,输出的是父进程
第二个命令先执行管道,启动子进程,再输出,输出的就是子进程2 命名管道
管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。 命名管道是一种特殊类型的文件- 1
- 2
- 3
- 4
- 5
创建:
1.创建一个命名管道
$ mkfifo pipe12.命名管道的打开规则
如果当前打开操作是为读而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO O_NONBLOCK enable:立刻返回成功如果当前打开操作是为写而打开FIFO时 O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO O_NONBLOCK enable:立刻返回失败,错误码为ENXIO- 1
- 2
- 3
- 4
- 5
- 6
- 7
3 FIFO管道特点
命名管道(FIFO)和管道(pipe)基本相同,但也有一些显著的不同,其特点是:
1、半双工,数据在同一时刻只能在一个方向上流动。
2、写入FIFO中的数据遵循先入先出的规则。
3、FIFO所传送的数据是无格式的,这要求FIFO的读出方与写入方必须事先约定好数据的格式,如多少字节算一个消息等。
4、FIFO在文件系统中作为一个特殊的文件而存在,但pipe中的内容却存放在内存中。
5、管道在内存中对应一个缓冲区。不同的系统其大小不一定相同。
6、从FIFO读数据是一次性操作,数据一旦被读,它就从FIFO中被抛弃,释放空间以便写更多的数据。
7、当使用FIFO的进程退出后,FIFO文件将继续保存在文件系统中以便以后使用。
8、FIFO有名字,不相关的进程可以通过打开命名管道进行通信。操作FIFO文件时的特点
系统调用的I/O函数都可以作用于FIFO,如open、close、read、write等。
打开FIFO时,非阻塞标志(O_NONBLOCK)产生下列影响:
》 特点一:
不指定O_NONBLOCK(即open没有位或O_NONBLOCK)
1、open以只读方式打开FIFO时,要阻塞到某个进程为写而打开此FIFO
2、open以只写方式打开FIFO时,要阻塞到某个进程为读而打开此FIFO
3、open以可读可写方式打开FIFO时不会阻塞,调用read函数从FIFO里读数据时read也会阻塞。
4、通信过程中若写进程先退出了,则调用read函数从FIFO里读数据时不阻塞;若写进程又重新运行,则调用read函数从FIFO里读数据时又恢复阻塞。
5、通信过程中,读进程退出后,写进程向命名管道内写数据时,写进程也会(收到SIGPIPE信号)退出。
6、调用write函数向FIFO里写数据,当缓冲区已满时write也会阻塞。
》特点二:
指定O_NONBLOCK(即open位或O_NONBLOCK)
1、先以只读方式打开:如果没有进程已经为写而打开一个FIFO, 只读open成功,并且open不阻塞。
2、先以只写方式打开:如果没有进程已经为读而打开一个FIFO,只写open将出错返回-1。
3、read、write读写命名管道中读数据时不阻塞。
4、通信过程中,读进程退出后,写进程向命名管道内写数据时,写进程也会(收到SIGPIPE信号)退出》注意:
open函数以可读可写方式打开FIFO文件时的特点:
1、open不阻塞。
2、调用read函数从FIFO里读数据时read会阻塞。
3、调用write函数向FIFO里写数据,当缓冲区已满时write也会阻塞。十三 内核空间 用户空间
内核空间与用户空间是对 虚拟内存(0-4G) 的分配,对运行起来的系统中 虚拟内存的分配
当不运行时,内核空间和用户空间是不存在的.
当运行时,内核空间指的是(3-4G),这段内存中存在了 内核镜像的各个段,各种页表,内核申请的内存
当运行时,用户空间指的是(0-3G),每个用户进程有一个用户空间,这段内存中存在了 应用程序的各个段,应用程序申请的内存内核空间与用户空间的界限就是 异常(对于ARM,包括系统调用和中断)等
对于系统调用,一般我们认为 int指令(不包括)之后 iret(包括)之前的路径都是运行在(3-4G)内核空间
对于中断, 进入中断与返回之间也运行在内核空间从其他的角度分析:
内核代码路径肯定运行在内核空间
用户代码路径肯定运行在用户空间十四 协处理器CP15
为什么linux会发展成这个样子,这当然是程序员对程序的要求决定的,
为了满足这些要求,提出了 进程地址空间抽象(1) , 其中 硬件上增加了新的模块MMU(2), 软件上根据MMU的使用手册(3)更新了系统
另外在 进程地址空间抽象 的基础上, 软件上更新了很多新的内存特性(4).这当中并没有提到硬件做的其他工作.例如为了管理MMU,ARM核心上还增加了CP15
我们可以通到代码来通过控制 CP15,从而来控制 MMU

十五 PageCache
一)pagecache是由内核维护的,提供给应用程序使用的中间层
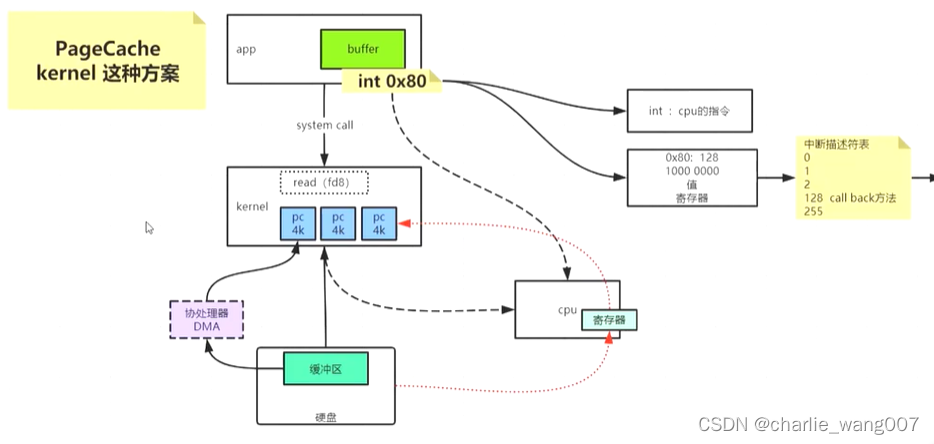
正常关机,系统会将pagecache脏页落盘,意外断电,pagecache数据会丢失
1 程序申请内存,会拿到逻辑地址与物理地址的映射,在程序看来,这些地址是连续的,在使用内存的时候也是以page为单位
2 当程序通过逻辑地址找不到物理地址的时候会发生内存缺页,此时kernel会分配对应的内存给程序
3 内存的映射关系硬件上有由MMU完成逻辑到物理转换,转换之后的映射存在寄存器快表当中
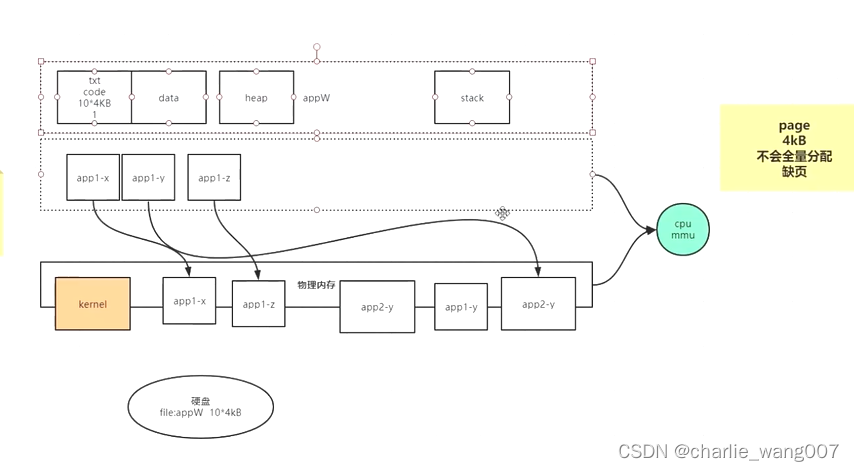
程序的内存分配:
1 程序以文件的形式存储在硬盘,运行时加载到内存中,程序在内存中分为四个部分:代码段,数据段,堆,栈

2 程序要访问磁盘上的文件,也要有内核先加载到pagecache,程序才能访问二)pagecahce有多大
先看看linux的pagecache的配置

vm.dirty_background_ratio
脏页的阈值 (加入内存有10G,脏页占用到9G的时候才落盘)后台也就是非阻塞,当达到阈值的时候内核会启动线程触发LRU落盘数据,内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,我有32G内存,那么有3.2G(10%的比例)的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。vm.dirty_rati
分配的内存的阈值,相当于前台,如果达到阈值程序会阻塞,也会触发LRU刷盘,一般程序的脏页先达到backgroundratio,后台刷盘的进度跟不上程序持续写入的进度,可能会导致ditry_ratio以上这两个值与redis RDB刷盘,和mysql binlog redolog的刷盘都有关联,vm.dirty_background_ratio:这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存磁盘上;
vm.dirty_ratio:这个参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存磁盘上);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
之前一直错误的以为dirty_ratio的触发条件不可能达到,因为每次肯定会先达到vm.dirty_background_ratio的条件,后来才知道自己理解错了。确实是先达到vm.dirty_background_ratio的条件后触发flush进程进行异步的回写操作,但是这一过程中应用进程仍然可以进行写操作,如果多个应用进程写入的量大于flush进程刷出的量那自然会达到vm.dirty_ratio这个参数所设定的阈值,此时操作系统会转入同步地处理脏页的过程,阻塞应用进程。
dirty_writeback_centisecs
控制周期回写进程的唤醒时间,默认值为500,单位是厘秒,实际内核中是*10使用,即5s,也就是每隔5秒唤醒脏页回写进程,降低这个值可以把尖峰的写操作削平成多次写操作。dirty_expire_centisecs
控制dirty inode实际回写的等待时间,默认值是3000,即30s,只有当超过这个值后,内核回写进程才会将dirty数据回写到磁盘在实际业务中,依赖这几个参数来调整磁盘IO,以提高性能
详细十六 异常与中断
1 IRQ:
为 Interrupt ReQuest的缩写,中文可译为中断请求。因为计算机中每个组成组件都会拥有一个独立的IRQ,除了使用PCI总线的PCI卡之外,每一组件都会单独占用一个 IRQ,且不能重复使用。
由于在计算机运行中,CPU是持续处于忙碌状态,而当硬件接口设备开始或结束收发信息,需要CPU处理信息运算时,便会透过IRQ对CPU送出中断请求讯号,让CPU储存正在进行的工作,然后暂停手边的工作,先行处理周边硬件提出的需求,这便是中断请求的作用。
一个中断请求(IRQ,interrupt request)的价值就在于电脑中有个特殊的装置当装置发送关于它运行的信号时可以在指定位置中断它。例如,当打印机完成了打印任务时,它就发送一个中断信号到计算机,信号即刻中断计算机以至于它能够判断下一个进程。如果多个信号同样发送到计算机请求中断,那么计算机可能不能理解,所以每个装置必须设定一个唯一值以及它到达计算机的路径。在即插即用(PnP)设备之前,当添加一个新的设备到计算机时,用户经常不得不用手动设置IRQ值(或者已经意识到这一点2 中断
中断通常被定义为一个事件,该事件改变处理器执行的指令顺序。
中断通常分为同步中断和异步中断。
同步中断(中断)是当前指令执行时由CPU控制单元产生的,之所以称为同步,是因为只有在一条指令终止执行后CPUT才会发出中断。
异步中断(异常)是由其他硬件设备依照CPU时钟信号随机产生的。
分类:中断:分为可屏蔽中断(控制单元会忽略屏蔽的中断)和非屏蔽中断(由CPU辨认)。
异常:处理器探测异常,故障,陷阱,异常中止,编程异常向量:每个中断和异常是由0~255之间的一个数来标识。Intel把这个8位的无符号整数叫做一个向量。非屏蔽中断的向量和异常的向量是固定的,而可屏蔽中断的向量可以通过对中断控制器的编程来改变。
IRQ:每个能够发出中断请求的硬件设备控制器都有一条名为IRQ的输出线。所有现有的IRQ线都与一个名为可编程中断控制器的硬件电路的输入引脚相连。
IRQ线从0开始编号,与IRQn关联的Intel的缺省向量是n+32。3 linux中断请求执行过程:

4 APIC
apic:Advanced Programmable Interrupt Controller高级可编程中断控制器。
1
APIC 是装置的扩充组合用来驱动 Interrupt 控制器 。在建置中,系统的每一个部份都是经由 APIC Bus 连接的。“本机 APIC” 为系统的一部分,负责传递 Interrupt 至指定的处理器;举例来说,当一台机器上有三个处理器则它必须相对的要有三个本机 APIC2 因此CPU内部必须内置APIC单元。Intel多处理规范的核心就是高级可编程中断控制器(Advanced Programmable Interrupt Controllers–APICs)的使用。
3 多处理器的CPU通过彼此发送中断来完成它们之间的通信。通过给中断附加动作(actions),不同的CPU可以在某种程度上彼此进行控制。
4 每个CPU有自己的APIC(成为那个CPU的本地APIC),并且还有一个I/O APIC来处理由I/O设备引起的中断,这个I/O APIC是安装在主板上的,但每个CPU上的APIC则不可或缺,否则将无法处理多CPU之间的中断协调。
5 一条APIC总线把"前端"I/O APIC连接到本地APIC。来自外部设备的IRQ线连接到I/O APIC,因此,相对于本地APIC,I/O APIC起到路由器的作用。

5 中断描述符表(IDT)
1 中断描述符表是一个系统表,它与每一个中断或异常向量相联系,每一个向量在表中有相应的中断和异常处理程序的入口地址。表中的每一项对应一个中断或异常向量,每个向量由8个字节组成。因此,最多需要256*8=2048字节来存放IDT。
2 idtr CPU寄存器使IDT可以位于内存的任何地方,它指定IDT的线性基址及其限制,在允许中断之前,必须用lidt汇编指令初始化idtr。
3 Linux利用中断门处理中断,利用陷阱门处理异常。
- 任务门:当中断信号发生时,必须取代当前进程的那个进程的TSS选择符存放在任务门中。
- 中断门:包含段选择符和中断或异常处理程序的段内偏移量。当控制权转移到一个适当的段时,处理器清IF标志,从而关闭将来会发生的可屏蔽中断。
- 陷阱门:与中断门相似,只是控制权传递到一个适当的段时处理器不修改IF标志。
6 初始化IDT表
初始化中断描述符表
内核启动中断以前,必须把IDT表的初始化地址撞到idtr寄存器,并初始化表中的每一项。
int指令允许用户态进程发出一个中断信号,其值可以是0~255的任意一个向量。
在少数情况下,用户态进程必须能发出一个编程异常,为此,只要把中断或陷阱门描述符的DPL字段设置成3,即特权级尽可能一样高就足够了。


7 异常处理
CPU产生的大部分异常都由LInux解释为出错条件,当其中一个异常发生时,内核就向引起异常的进程发送一个信号向它通知一个反常条件。
异常处理程序有一个标准的结构,由一下三部分组成:
在内核堆栈中保存大多数寄存器的内容(这部分用汇编语言实现)
用高级的C函数处理异常
通过ret_from_exception()函数从异常处理程序退出
为了利用异常,必须对IDT进行适当的初始化,使得每个被确认的异常都有一个异常处理程序。trap_init()函数的工作是将一些最终值(即处理异常的函数)插入到IDT的非屏蔽中断及异常表项中。8 中断处理
中断有三种类型
I/O中断
时钟中断 和
处理器间的中断I/O 中断处理
一般来说,I/O中断处理程序必须足够灵活以给多个设备同时提供服务。
几个设备可以共享同一个IRQ线,这就意味着仅仅中断向量不能说明所有问题。
中断处理程序的灵活性实现:IRQ共享,IRQ动态分配。
当一个中断发生时,并不是所有的操作都具有相同的紧迫性,因为当一个终端处理程序正在运行时,相应的IRQ线上发出的信号就被暂时忽略,因此,终端处理程序不能执行任何阻塞过程。中断处理程序可以分为
IRQ共享 IRQ 动态分配: 中断处理程序是代表进程执行的,他所代表的进程总是处在TASK_RUNNING 状态,不能出现僵死状态。- 1
- 2
- 3
linux把紧随中断要执行的操作分为三类:
紧急的: 必须在禁止可屏蔽中断的情况下。 非紧急的: 必须在开中断的情况下。 非紧急可延迟的:- 1
- 2
- 3
- 4
- 5
所有I/O 中断处理程序必须执行四个形同的基本步骤
1 在内核态堆栈中保存IRQ 的值和寄存其中的内容。
2 为正在给IRQ线服务的PIC发送一个应答,这将允许PIC进一步发出中断。
3 执行共享这个IRQ的所有设备的中断服务例程
4 跳到 ret_from_intr()的地址后终止。
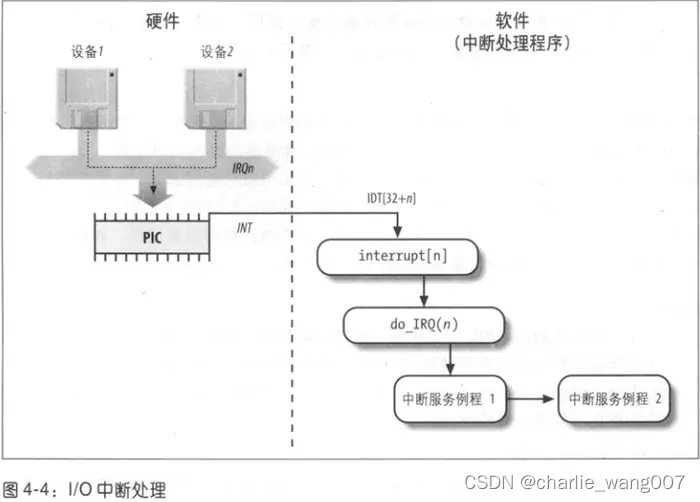
9 中断向量
内核必须在启用中断前发现IRQ号与I/O设备之间的对应,IRQ号与I/O设备之间的对应是在初始化每个设备驱动程序时建立的。
IRQ数据结构(支持中断处理的数据结构):IQR数据结构
每个中断向量都有它自己的irq_desc_t描述符,所有的这些描述符组织在一起形成irq_desc数组:

0~19 (0x0~0x13) 非屏蔽中断和向量
20~31 (OX14~0X1F) intel保留
32~127 (0x20~0x7f) 外部中断(IRQ)
128 (0x80) 系统调用
129~238(0x81=0xee) 外部中断(IRQ)
239 (0XEF) 本地APIC时钟中断
240-250(0xf0~0xfa) 由linux留做将来使用
251255(0xfb0xff) 处理器间中断

-
-
相关阅读:
基于FTP协议的文件上传与下载
React组件之间的通信方式总结(下)
深入浅出MySQL-03-【MySQL中的运算符】
JavaScript之事件
1.3.8 利用三层交换机实现 VLAN 间路由
11. Container With Most Water
C语言:static,volatile,const,extern,register,auto, 栈stack结构
ChatGPT私有数据结合有什么效果?它难吗?
15:00面试,15:06就出来了,问的问题有点变态。。。
vue elementui 实现从excel从复制多行多列后粘贴到前端界面el-table
- 原文地址:https://blog.csdn.net/weixin_41479678/article/details/126103769