-
机器学习——集成算法原理
1.Ensemble learning
目的:训练多个模型,让机器学习效果更好
Bagging:训练多个分类器取平均

Boosting:从弱学习器开始加强,通过加权来进行训练
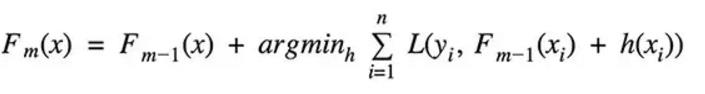 (加入一棵树,要比原来强)
(加入一棵树,要比原来强)Stacking:聚合多个分类或回归模型(可以分阶段来做)
2.Bagging模型
最典型的代表就是随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起

3.随机森林
构造树模型:

由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样
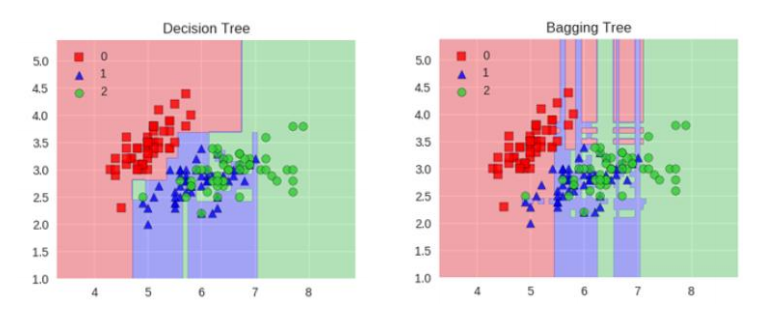
之所以要进行随机,是要保证泛化能力,如果树都一样,那就没意义了
随机森林优势
它能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,它能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以进行可视化展示,便于分析

4.Boosting模型
典型代表:AdaBoost, Xgboost
Adaboost会根据前一次的分类效果调整数据权重
解释:如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重
最终的结果:每个分类器根据自身的准确性来确定各自的权重,再合体
5.Stacking模型
堆叠:训练多个分类器,将其得到的结果堆叠起来,最后再训练一个模型对前面堆叠的结果进行训练。可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
 堆叠在一起确实能使得准确率提升,但是速度是个问题,集成算法是竞赛与论文神器,当我们更关注于结果时不妨来试试!
堆叠在一起确实能使得准确率提升,但是速度是个问题,集成算法是竞赛与论文神器,当我们更关注于结果时不妨来试试! -
相关阅读:
ubunut搭建aarch64 cuda交叉编译环境记录
JDK下载、安装与配置
【无标题】多卡聚合路由器在消防领域的应用
C# 实现基于exe内嵌HTTPS监听服务、从HTTP升级到HTTPS 后端windows服务
Nodejs的Express之同路由HEAD请求却执行GET函数问题
C++学习笔记(三十一)
在 Mac 上通过“启动转换助理”安装 Windows 10
深度学习DAY1:神经网络NN;二元分类
Reactor 测试-响应式编程-007
[PAT练级笔记] 03 Basic Level 1004
- 原文地址:https://blog.csdn.net/qq_52053775/article/details/126082165