-
基于Python实现的糖尿病预测系统
基于Python设计的预测糖尿病
摘要和关键词
本次实验的主要内容是使用回归分析和聚类分析来预测某人患糖尿病的可能性和身体的糖尿病指数。
关键词:糖尿病;线性回归;聚类分析
使用说明
数据来源:UCI 机器学习库 http://archive.ics.uci.edu/ml/datasets.html
配置相关: python3:pandas,numpy,matplotlib,seaborn
使用如图(1.1):
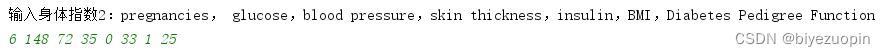
图 1.1 输入身体指数
结果如图(1.2):
图 1.2 返回预测结果
背景
根据美国预防疾病中心,现在美国有 1/7 的成年人患有糖尿病。根据增长趋势,到了 2050 年患糖尿病的人数将高达三分之一。我的父亲就常年受到糖尿病的困扰。但是根据专家研究,只要早点发现糖尿病的趋势,控制好饮食,就能杜绝糖尿病的加重甚至根治。
需求分析
用户可以在家里定时测量血压等身体数据,或者定期去医院体检获得数据后。 由医生或者病人自行把数据输入软件中,随后软件会根据数据分析预测后输出结果,判断是否患有糖尿病的风险,提醒患者到医院进行深度检查。
解决方案
从网上获取了两个数据集,一个是 age、 sex 、bmi、 map、 tc、 ldl、 hdl、 tch、 ltg、 glu 几个糖尿病专用指标与糖尿病指数的关系,因为这个数据集的预测结果不是二值,所以可以使用这个数据集训练线性回归预测。第二个数据集如图 2.1:

图 2.1 数据集部分
这几个指标,因为这个数据集结果是二值的——是否得了糖尿病,所以用聚类分析来预测。
线性回归方法:
首先验证数据的完整性。然后计算出相关系数矩阵系数越接近 1,数据集就越适合线性回归。

图 2.2 相关系数计算方法
接下来建立散点图来查看数据里的数据分析情况以及对相对应的线性情况,查看这些因素对 糖尿病指数有什么影响,将使用 seaborn 的 pairplot 来绘画。可以了解到不同的因素对糖尿病指数影响(置信度= 95 %),也可可以大致看出不同特征对于标签值的影响与相关关系在了解了数据的各种情况后需要对数据集建立模型
使用 train_test_split 函数来创建训练集和测试集,将训练集中的特征值与标签值放入 LinearRegression()模型中且使用 fit 函数进行训练,在模型训练完成之后会得到所对应的方程式(线性回归方程式)。然后使用测试集验证回归结果,发现拟合地很好。
之后只需要把用户传来地数据放到回归方程中然后得出糖尿病指数
聚类分析法:
数据分析,画出各特征值的直方图,看看有没有异常的数据。去掉异常数据(如血压等于零)
聚类分析不止一种,先测试看看哪种方法最好,这次实验使用了 7 种分类器,分别为:K-Nearest Neighbors, Support Vector Classifier, Logistic Regression, Gaussian Naive Bayes, Random Forest and Gradient Boost。
划分训练集和测试集,放入分类器中训练。然后用 K 折叠交叉验证(K-Fold Cross Validation)获得各分类器的准确率。
选用一个准确率最高的分类器,用 sklearn 的 GridSearchCV 调整参数,获得最优参数。最后使用最优参数获得分类器,处理用户输入的数据得到预测结果。
关键代码实现
线性回归:
检测数据和相关系数,判断是否适合线性回归。

图 5.1 计算相关系数矩阵代码
结果:
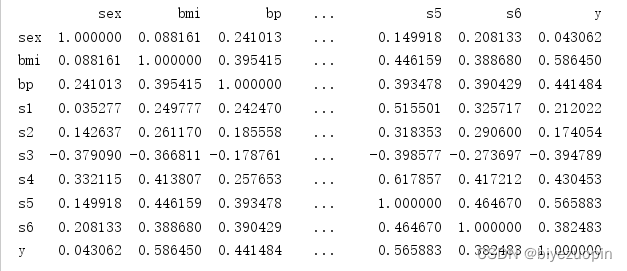
图 5.2 相关系数矩阵结果
训练集、测试集划分
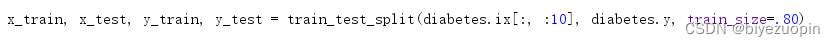
图 5.3 训练集、测试集划分代码
做散点图看特征值对标签值的影响

图 5.4 做散点图代码
结果(部分):
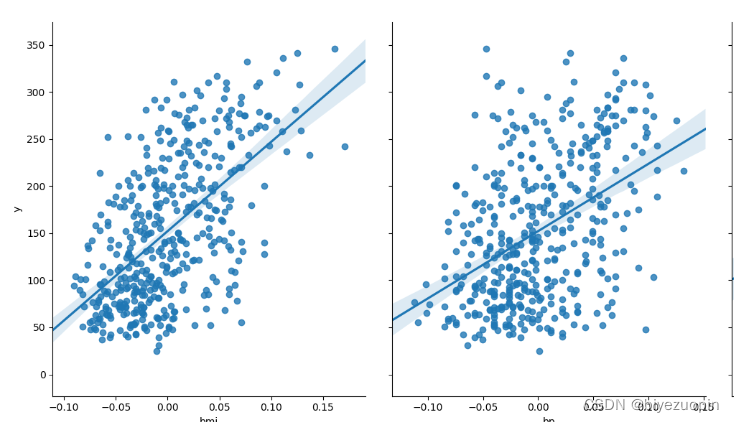
图 5.5 某两个标签的散点图
开始线性回归,测试准确率,并获得预测结果

图 5.6 线性回归代码
结果:

图 5.7 线性回归参数
聚类分析:
查看直方图,检测异常值并且去除异常值

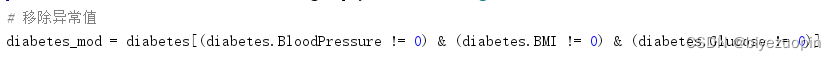
图 5.8 检查参数代码
使用 7 种分类器,并获得分类准确率:

图 5.9 配置 7 种聚类分析器的代码
结果:GB 准确率最高,用 GB 进行最终分类
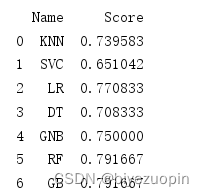
图 5.10 各类分类器的准确率
使用 GridSearchCV 调整 GradientBoostingClassifier()的参数:
图 5.11 使用 GridSearchCV 关键代码
结果:返回最佳参数,用这些参数做最终的分类器分类

-
相关阅读:
2014软专 P117
在数据框中如何把变量定义为整数型数据
Nodejs http模块常用方法
【esp32】xQueueReceive 函数调试踩坑记录
UG NX二次开发(C++)-CAM-根据刀具对程序组进行重新分组
四大组件---ContentResolver
unity urp 实现遮挡显示角色轮廓
Java面试
Java 集合知识点总结
IDEA自定义注释模版
- 原文地址:https://blog.csdn.net/sheziqiong/article/details/125991074