-
SparkSql批量插入或更新,保存数据到Mysql中
在sparksql 中,保存数据到数据,只有 Append , Overwrite , ErrorIfExists, Ignore 四种模式,不满足项目需求 ,此处大概说一下我们需求,当业务库有数据发生变化,需要更新、插入、删除数仓中ods层的数据,因此需要改造源码。
现依据 spark save 源码,进行进一步的改造, 批量保存数据,存在则更新 不存在 则插入
- import com.sun.corba.se.impl.activation.ServerMain.logError
- import org.apache.spark.SparkContext
- import org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils.getCommonJDBCType
- import org.apache.spark.sql.jdbc.{JdbcDialect, JdbcDialects, JdbcType}
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
- import java.sql.{Connection, DriverManager, PreparedStatement}
- import java.util.Properties
- object TestInsertOrUpdateMysql {
- val url: String = "jdbc:mysql://192.168.1.1:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowMultiQueries=true&autoReconnect=true&failOverReadOnly=false"
- val driver: String = "com.mysql.jdbc.Driver"
- val user: String = "123"
- val password: String = "123"
- val sql: String = "select * from testserver "
- val table: String = "testinsertorupdate"
- def main(args: Array[String]): Unit = {
- val spark = SparkSession.builder()
- .master("local[*]")
- .appName("testSqlServer").getOrCreate()
- val dbtable = "(" + sql + ") AS Temp"
- val jdbcDF = spark.read
- .format("jdbc")
- .option("driver", driver)
- .option("user", user)
- .option("password", password)
- .option("url", url)
- .option("dbtable", dbtable)
- .load()
- jdbcDF.show()
- //普通写入数据库
- //commonWrite(jdbcDF)
- //saveorupdate
- insertOrUpdateToMysql("id", jdbcDF, spark)
- println("======================程序结束======================")
- }
1.先看一下普通的插入怎么写的
- def commonWrite(jdbcDF: DataFrame): Unit = {
- val properties = new Properties()
- properties.put("user", user)
- properties.put("password", password)
- properties.put("driver", driver)
- jdbcDF.write.mode(SaveMode.Append).jdbc(url, table, properties)
- }
这种方式比较局限,只能做一些简单的插入(追加或覆盖等SaveMode.Append)
那么新的写法是什么呢,首先写出mysql的更新或插入的语法规则:
- INSERT INTO t_name ( c1, c2, c3 )
- VALUES
- ( 1, '1', '1')
- ON DUPLICATE KEY UPDATE
- c2 = '2';
需要注意的是一定要有主键,没主键没法更新;
2.看一下insertorupdate的写法
- //写入数据库,批量插入 或更新 数据 ,该方法 借鉴Spark.write.save() 源码
- // 规则如下:
- //没有关键主键字段即为插入,有即为更新
- def insertOrUpdateToMysql(primaryKey: String, jdbcDF: DataFrame, spark: SparkSession): Unit = {
- val sc: SparkContext = spark.sparkContext
- spark.conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
- //1.加载驱动程序
- Class.forName(driver);
- //2. 获得数据库连接
- val conn: Connection = DriverManager.getConnection(url, user, password);
- val tableSchema = jdbcDF.schema
- val columns = tableSchema.fields.map(x => x.name).mkString(",")
- val placeholders = tableSchema.fields.map(_ => "?").mkString(",")
- val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders) on duplicate key update "
- val update = tableSchema.fields.map(x =>
- x.name.toString + "=?"
- ).mkString(",")
- //ON DUPLICATE KEY UPDATE
- //on conflict($primaryKey) do update set
- val realsql = sql.concat(update)
- conn.setAutoCommit(false)
- val dialect = JdbcDialects.get(conn.getMetaData.getURL)
- val broad_ps = sc.broadcast(conn.prepareStatement(realsql))
- val numFields = tableSchema.fields.length * 2
- //调用spark中自带的函数,获取属性字段与字段类型
- val nullTypes = tableSchema.fields.map(f => getJdbcType(f.dataType, dialect).jdbcNullType)
- val setters = tableSchema.fields.map(f => makeSetter(conn, f.dataType))
- var rowCount = 0
- val batchSize = 2000
- val updateindex = numFields / 2
- try {
- jdbcDF.foreachPartition(iterator => {
- //遍历批量提交
- val ps = broad_ps.value
- try {
- while (iterator.hasNext) {
- val row = iterator.next()
- var i = 0
- while (i < numFields) {
- i < updateindex match {
- case true => {
- if (row.isNullAt(i)) {
- ps.setNull(i + 1, nullTypes(i))
- } else {
- setters(i).apply(ps, row, i, 0)
- }
- }
- case false => {
- if (row.isNullAt(i - updateindex)) {
- ps.setNull(i + 1, nullTypes(i - updateindex))
- } else {
- setters(i - updateindex).apply(ps, row, i, updateindex)
- }
- }
- }
- i = i + 1
- }
- ps.addBatch()
- rowCount += 1
- if (rowCount % batchSize == 0) {
- ps.executeBatch()
- rowCount = 0
- }
- }
- if (rowCount > 0) {
- ps.executeBatch()
- }
- } finally {
- ps.close()
- }
- })
- conn.commit()
- } catch {
- case e: Exception =>
- logError("Error in execution of insert. " + e.getMessage)
- conn.rollback()
- // insertError(connectionPool("OuCloud_ODS"),"insertOrUpdateToPgsql",e.getMessage)
- } finally {
- conn.close()
- }
- }
几个源码包
- private def getJdbcType(dt: DataType, dialect: JdbcDialect): JdbcType = {
- dialect.getJDBCType(dt).orElse(getCommonJDBCType(dt)).getOrElse(
- throw new IllegalArgumentException(s"Can't get JDBC type for ${dt.catalogString}"))
- }
- private type JDBCValueSetter_add = (PreparedStatement, Row, Int, Int) => Unit
- private def makeSetter(conn: Connection, dataType: DataType): JDBCValueSetter_add = dataType match {
- case IntegerType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setInt(pos + 1, row.getInt(pos - currentpos))
- case LongType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setLong(pos + 1, row.getLong(pos - currentpos))
- case DoubleType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setDouble(pos + 1, row.getDouble(pos - currentpos))
- case FloatType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setFloat(pos + 1, row.getFloat(pos - currentpos))
- case ShortType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setInt(pos + 1, row.getShort(pos - currentpos))
- case ByteType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setInt(pos + 1, row.getByte(pos - currentpos))
- case BooleanType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setBoolean(pos + 1, row.getBoolean(pos - currentpos))
- case StringType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setString(pos + 1, row.getString(pos - currentpos))
- case BinaryType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - currentpos))
- case TimestampType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - currentpos))
- case DateType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - currentpos))
- case t: DecimalType =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- stmt.setBigDecimal(pos + 1, row.getDecimal(pos - currentpos))
- case _ =>
- (stmt: PreparedStatement, row: Row, pos: Int, currentpos: Int) =>
- throw new IllegalArgumentException(
- s"Can't translate non-null value for field $pos")
- }
这里面有个属性比较关键我列出来,不加会报错 Exception in thread "main" java.io.NotSerializableException: com.mysql.jdbc.JDBC42PreparedStatement:
spark.conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")添加下这个配置 这个第三方序列化 用默认的javaSerializer 不行
结果如下,这块有一些坑,有需要的朋友,我们可以交流
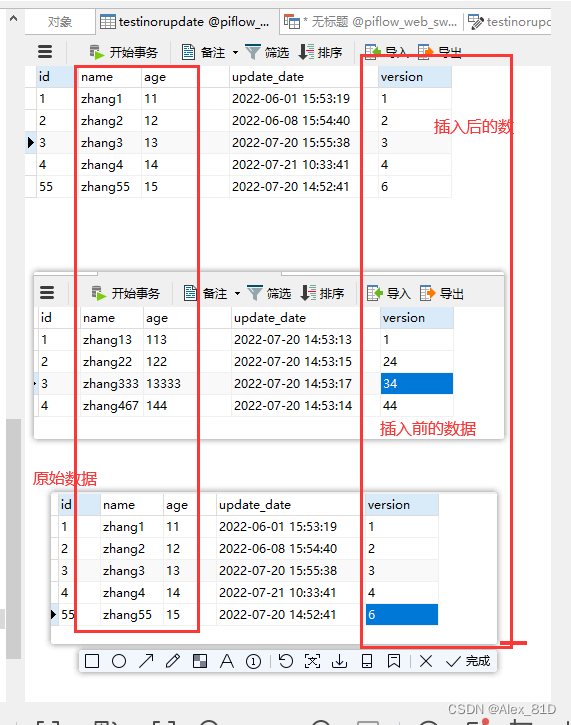
附postgreesql的更新或插入语法:
- INSERT INTO test_001 ( c1, c2, c3 )
- VALUES( ?, ?, ? )
- ON conflict ( ID ) DO
- UPDATE SET c1=?,c2 = ?,c3 = ?;
MySQL的on duplicate key update 的使用_厄尔尼诺的夏天的博客-CSDN博客
博主qq:907044657,欢迎大家一起交流学习,有问题请指出,转载麻烦注明出处,多谢啦
-
相关阅读:
docker安装
在实施 360 反馈流程之前要考虑的 6 个问题
JVM虚拟机详解
Zookeeper基本使用(新增,修改,查看,删除节点)
使用EasyCV Mask2Former轻松实现图像分割
Transformers x SwanLab:可视化NLP模型训练
如何鉴别一个成功的Scrum 教练?
着手开发属于自己的第一个Intellij-platform plugin插件程序(三)
2022年保健品行业研究报告
区块链架构下,智慧城市加速发展
- 原文地址:https://blog.csdn.net/Alex_81D/article/details/125893271
