-
redis6主从复制及集群
目录
主从复制
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主,可实现读写分离,性能扩展。容灾快速回复。
主机做写操作,从机做读操作。
搭建过程
(1)在Linux系统中新建一个文件夹,复制一份配置文件redis.conf到该文件夹下。将复制过去的配置文件中的 appendonly 设置为 no。

(2)在第一步创建的文件中,创建多个redis配置文件,引入redis.conf,设置端口号 port ,pid文件名称 pidfile ,持久化文件名称 dbfilename 。三个文件当中只有数字不同,其余相同。

(3)启动创建的redis服务器,三个会话窗口分别连接3个redis服务器。

查看系统进程,三个redis服务器已启动并且建立了三个连接。

(4)在连接中输入 info replication 查看三台主机的运行情况,发现并没有建立主从关系,每一个redis服务器都是主机。
info replication
(5)建立主从关系,输入 slaveof 主机IP 端口号。
slaveof <主机IP> <端口号>再次查看从机信息,发现已经有主机IP和端口

查看主机信息,显示从机连接数2个。

(6)主机进行写操作,从机能够同步数据,并且从机不能进行写操作。

复制原理
全量复制:从机接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:主机将所有新收集到的修改命令依次传送给从机,完成同步。
一主多仆
顾名思义,一个主机连接多个从机。

复制过程:(1)从机和主机建立主从关系时,从机向主机发送数据同步请求(2)主机接收请求后将当前数据持久化,然后将持久化后的文件发送给从机,从机读取完成同步。(3)主机新增数据之后,主机将新增数据发送给从机进行数据同步,从机只有连接时申请了一次数据同步,其余时间都是主机主动发送。
薪火相传
主机的从机也可以是其他服务器的主机。

复制过程:主机连接从机,从机也可以是其他服务器的主机。类似于java当中的继承关系。当主机修改信息后,从机来更新其他服务器的数据。
反客为主
主机宕机,从机上位。

当主机宕机之后,从机可以升级为主机,通过在从机中输入下面一行代码实现。
slaveof no one可以通过设置哨兵来实现自动监控主机,当主机宕机后从机自动晋升为主机,不需要人工设置。
问题分析
从机宕机
(1)从机挂掉之后,重新启动从机,从机是以主机的形式存在的,并不是之前的主机的从机。
(2)如果主机在从机挂掉这段时间内添加了新的数据,当重启从机并建立主从关系后,从机的数据仍然和主机保持一致。
(3)从机重启之后,还没有和主机建立主从关系前添加的数据将会在建立关系后消失,并且之后保留的将会是主机的数据。
主机宕机
(1)主机挂掉之后,从机显示信息中主机仍然不变,只是状态变为了down。
(2)重启主机,仍然是主服务器。
集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
搭建集群
(1)在搭建主从关系中新建的文件夹下,修改redis6379.conf文件的内容,添加如下信息。并且复制5份。
- cluster-enabled yes 打开集群模式
- cluster-config-file nodes-6379.conf 设定节点配置文件名
- cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。

将每一份的数据中的数字都进行修改。

(2)启动这6个redis服务,并且合成一个集群。

进入到redis安装目录下的src文件夹中,执行如下命令,命令表示以最简单的方式建立集群,即一个主节点,一个从节点一一对应。分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
redis-cli --cluster create --cluster-replicas 1 <ip>:<端口> <ip>:<端口>集群搭建成功

(3)连接集群,查看集群信息。
使用下面的指令连接集群
redis-cli -c -p 6379使用下面的指令查看集群节点信息
cluster nodes
集群操作
集群搭建成功后,redis会显示这个集群的插槽数目,即slot。

一个 Redis 集群包含 16384 个插槽(hash slot),数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
存储数据
测试案例一:添加数据

我们在6379端口对应的redis服务器添加数据,最终添加到了6381端口下,在6381端口下添加的数据,又是在6379下添加。
这是因为redis将key通过CRC16语句计算了校验和,根据校验和与16384来取余的结果,来选择不同的服务器进行添加数据。
测试案例二:多键操作

slot键值不同,是不能使用mget,mset等多键操作。
测试案例三:分组存放

可以使用{}来定义组的概念,让key中{}内相同内容的键值对放到同一个slot中。
读取数据
测试案例一:读取数据
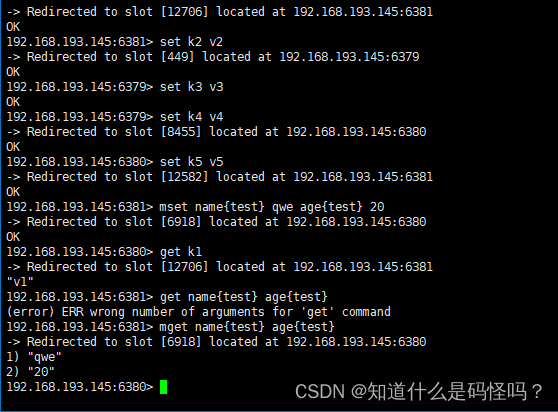
不同的key,需要到对应的节点当中去取数据。
测试案例二:有关key和slot的操作
查看 key 对应的 slot
cluster keyslot <key>查看 slot 对应了多少个 key(只能看当前节点范围内的slot)
cluster countkeysinslot <slot>返回 count 个 slot 槽中的键(只能看当前节点范围内的slot)
cluster getkeysinslot <slot> <count>
故障恢复
(1)如果某一台主机宕机,其对应的从机将会升级为主机。
(2)如果再次启动之前的主机,将会成为从机。(可以理解为风水轮流转,老大轮流当)
(3)如果主机和从机都宕机,集群不一定挂掉。如果 redis.conf 中的参数 cluster-require-coverage 设置为 yes ,那么集群挂掉。如果设置为 no ,那么这个节点对应的插槽数据全都不能使用,也无法存储。
-
相关阅读:
一个开源的汽修rbac后台管理系统项目,基于若依框架,实现了activiti工作流,附源码
2023 年高教社杯全国大学生数学建模竞赛获奖名单(初稿)公示
AD9164配置与数据使用指南
代码随想录算法训练营第六十二天| 84.柱状图中最大的矩形
数据库复习
Navicat连接postgresql时出现‘datlastsysoid does not exist‘报错
PB从入坑到放弃(六)动态SQL应用
云架构的一些核心概念
广电大数据用户画像及营销推荐策略(四)——Python实现
C++语言深度解析--类型系统和类型安全--const和volatile
- 原文地址:https://blog.csdn.net/weixin_41746479/article/details/125597297