-
语音合成:概述【不等长序列关系建模的生成任务】
一、什么是语音合成?
语音合成是一个“不等长序列关系建模的生成任务”
- 输入:【tex len 】;输入:【frequency dim, spectrum length】
- 输入形状:文本token序列长度;输出形状:(频率维度, 频谱序列长度)

“七百三十九”5个“token”对应着20多个语音“帧”不能单独建模 “七”与X帧的关系,“百”与Y帧的关系,。。。。,然后拼接起来,这样是违反人类发音的本质的。
二、语音合成基本训练框架
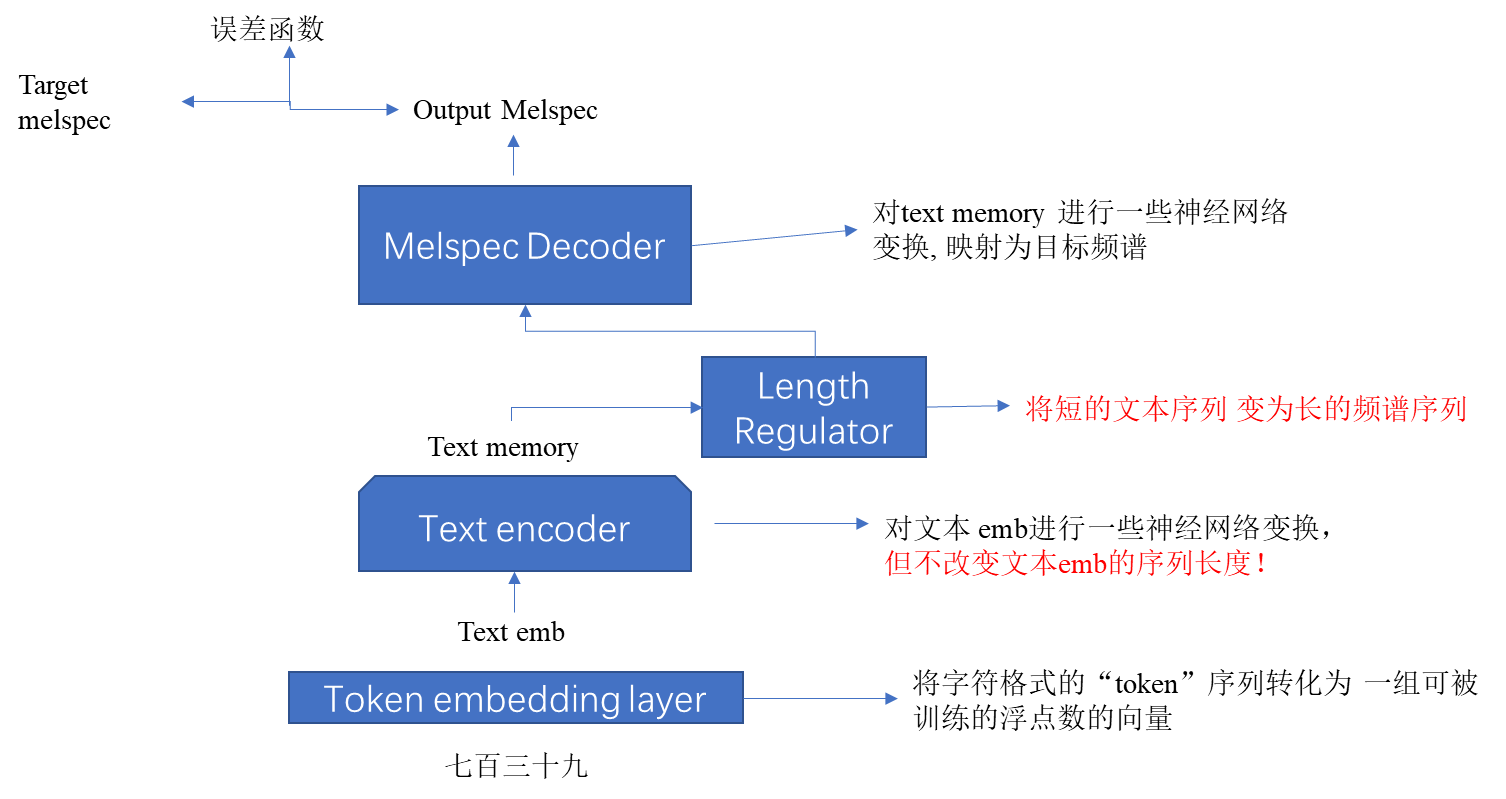
1、训练数据介绍
采样率 = 16000

2、Token Embedding Layer

为了将字符映射为浮点数,pytorch采取了“可训练查询表”的方式,设数据集中含有的token 数量&
-
相关阅读:
【C++】【Opencv】cv::warpAffine()仿射变换函数详解,实现平移、缩放和旋转等功能
python+vue+elementui在线打印系统
SQL中怎么将行转成列?
python爬虫入门教程(非常详细):如何快速入门Python爬虫?
[篇五章二]_使用 USB 系统安装盘在真机上安装激活 Windows 10 LTSC 2021 中文企业版系统
Spring Security 如何维持单点状态
基于C++QT框架的地铁换乘可视化查询系统
pyspark使用xgboost做模型训练
java 01 -环境配置
C++ Vector的概念和原理和构造
- 原文地址:https://blog.csdn.net/u013250861/article/details/125511116