-
人工智能知识全面讲解:个体与集成
9.1.1 三个臭皮匠赛过诸葛亮
中国有句俗语叫“三个臭皮匠赛过诸葛亮”。意思是三个才能平庸的人,
若能同心协力,比诸葛亮还要厉害!这就是我们常说的“博采众长”。在机器
学习领域,也有这么一种算法,它本身不是一个单独的学习算法,而是一种构
建并结合多个学习器来完成学习任务的算法。这种算法被称为“集成学
习”(Ensemble Learning)。集成学习已经成为各类机器学习竞赛的首要选
择,也可以说是人工智能领域工业化应用最为广泛的模型。与单一模型相比,
集成学习往往能够获得更好的效果。
集成学习是一种使用多个“弱学习器”进行学习,并使用某种规则将各个
学习结果进行整合,从而获得更好的学习效果的机器学习方法。一般情况?,
集成学习采用的学习器都是同质的“弱学习器”。这种弱学习器由弱学习算法
构成,常见的弱学习算法有决策树、逻辑回归、简单神经网络和朴素贝叶斯
等。在通常情况?,这些算法的复杂度低,速度快,易展示结果,但单个弱学
习器的学习效果往往不是特别好,因此借助集成的方式放大弱学习算法的作
用。
集成在这里的意思就是把简单的算法组织起来,就像在现实生活中,我们
会通过投票与开会的方式,做出更加可靠的决策。每种算法都像一个普通的
人,单个人做决定时可能会犯错误,但是把大家的想法集合到一起再通过投票
的方式决策,往往会比一个人的判断更准确。从这个比喻你也能看出为什么我
们要采用水平相当的“弱分类器”来集成学习,因为一旦某个分类器太强了就
会造成后面的结果受其影响太大,从投票选择变成“一言堂”模式,严重时会
导致后面的分类器无法进行分类。
集成学习通常先产生一组“个体学习器”,再通过某种策略将它们结合起
来,最后输出判断结果,如图9-1所示。若集成中只包含同种类型的个体学习
器,则这种集成称为同质集成,例如,随机森林中全部个体学习器都是决策树
算法。同质集成中的个体学习器也称为“基学习器”。若其中的个体学习器不
全属于一个种类,则这种集成称为异质集成。例如一个分类问题,对训练集采
用支持向量机、逻辑回归和朴素贝叶斯三种算法共同学习,再通过某种结合策
略来确定最终的分类结果,这种场景就是异质集成。目前,同质个体学习器的
应用最广泛,一般我们说的集成学习方法都是指同质个体学习器。而同质个体
学习器使用最多的模型是CART决策树与神经网络。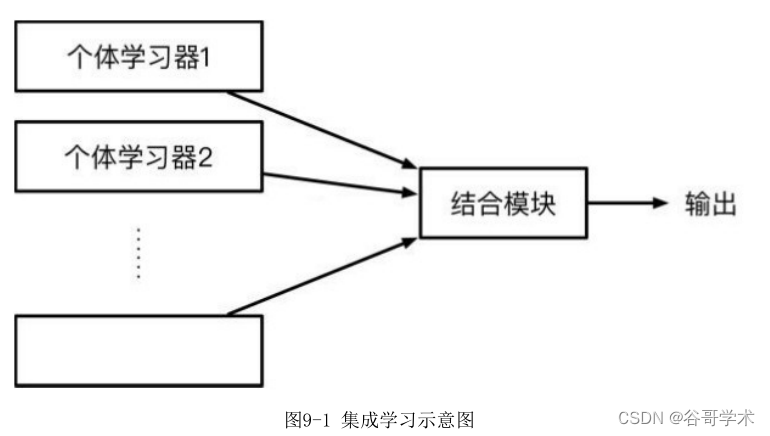
使用不同的算法或者使用相同的算法而使用不同的参数配置,肯定会导致
各个弱分类器的结果有差异。不同的分类器生成的分类决策边界不同,也就是
说它们在决策时会犯不同的错误。将它们结合后往往能得到更合理的边界,减
少整体错误,实现更好的分类效果,如图9-2所示。
9.1.2 人多一定力量大吗
并非三个臭皮匠一定能赛过诸葛亮。在现实生活中,如果我们请三个水平
相当的建筑工人一起装修房间与一个工人装修相比,三人一起装修在时间上会
快很多,但不见得三个工人装修的效果一定比一个工人装修的效果更好。就像
集成学习对多个学习器进行了结合,那它怎么保证整体的效果比最好的那个单
一学习器的效果更好呢?
我们可以挑选三个“各有所长”的建筑工人。工人 A 墙砌得平可以让他
负责砌墙的工作,工人B擅长批灰,工人C擅长刷墙,都让他们各自负责最擅长
的部分。这样三个人一起合作肯定比一个工人装修的效果要好。
然而在算法层面的论证过程并没有那么简单。因为个体学习器都是为解决
同一类问题而训练的,它们之间显然不可能相互独立,也就是说很难做到“各
有所长”。事实上,个体学习器的准确性和多样性本身就存在冲突。一般情况
?,在准确性很高的情况?,要想增加多样性就必须牺牲一部分准确性。
早在1984年,瓦兰特(Leslie Valiant)教授就提出了这个有趣的问题。
我们都知道任何“二分类问题”如果只有“是”“否”两个回答,按照古典概
率学来说,瞎猜一个答案也有 50%的正确率。因此,他定?了弱学习算法为识
别正确率略高于 50%的算法,即准确率仅比随机猜测略高的学习算法。强学习
算法为识别准确率很高并能在一定时间内完成的学习算法。
接?来瓦兰特教授提出另一个问题:弱学习器能否被“增强”为一个强学
习器?若回答是肯定的,那么我们只需寻找一个比随机猜测的结果稍微好一点
的弱学习算法,然后将其提升为强学习算法即可,也就是说不必费很大力气去
寻找构造强学习算法的方式,只需集成即可。
在这之后的很长一段时间里,都没有人能够证明这个问题,甚至一度让人
怀疑集成这种方法的可行性。最终还是夏皮尔(Robert E. Schapire)教授于
1989 年首次给出了肯定的答案。他主张的观点是:任一弱学习算法都可以通
过加强提升而成为一个能达到任意正确率的强学习算法,并通过构造一种多项
式级的算法来实现这一加强过程,这就是最初的Boosting算法的原型。
总而言之,集成学习的研究主要解决两个问题:第一是如何得到这些弱
学习器;第二是如何选择一种结合策略,将这些个体学习器集成为一个强学
习器 。根据个体学习器的生成方式,目前的集成学习方法大致可分成两大
类:一类是个体学习器间存在强依赖关系,是一种有先后顺序的串行化方法,
这类方法的典型代表是 Boosting算法;另一类是个体学习器间不存在强依赖
关系,可同时生成并行化方法,这类方法的典型代表是Bagging算法以及随机
森林算法。?面我们介绍这两大类算法的特点与区别。 -
相关阅读:
Java核心技术卷Ⅰ-第四章对象和类
实用SQL语句
原生js预览ofd文件
LeetCode刷题复盘笔记—一文搞懂完全背包之377. 组合总和 Ⅳ问题(动态规划系列第十二篇)
Hadoop高手之路3-Hadoop集群搭建
三款“非主流”日志查询分析产品初探
HC32_HC32F072FAUA_DAC的使用
【开源教程4】疯壳·开源编队无人机-OPENMV 脚本烧写
UnityShader-深度纹理(理解以及遇到的问题)
高项 风险管理论文
- 原文地址:https://blog.csdn.net/tysonchiu/article/details/125503163