-
centos7 crash调试内核
前言
Linux 应用层可以用gdb调试应用程序和出现段错误时产生的coredump文件,那么在内核层了,调试内核的工具是crash,使用方法和gdb类似,接下来我就在centos7 安装crash调试环境,并进行一些demo测试。
我当前的环境:
一、kdump
1.1 kdump定义
来自维基百科的定义:
kdump 是 Linux 内核的一项功能,可在kernel crash(内核崩溃)时创建 crash dumps。 触发时,kdump 会导出一个内存映像(也称为 vmcore),可以对其进行分析,以用于调试和确定崩溃原因。 主内存的转储映像,作为可执行和可链接格式 (ELF) 对象导出,可以在处理 kernel crash 期间直接通过 /proc/vmcore 访问,或者它可以自动保存到本地可访问的文件系统、原始设备或可通过网络访问的远程系统。
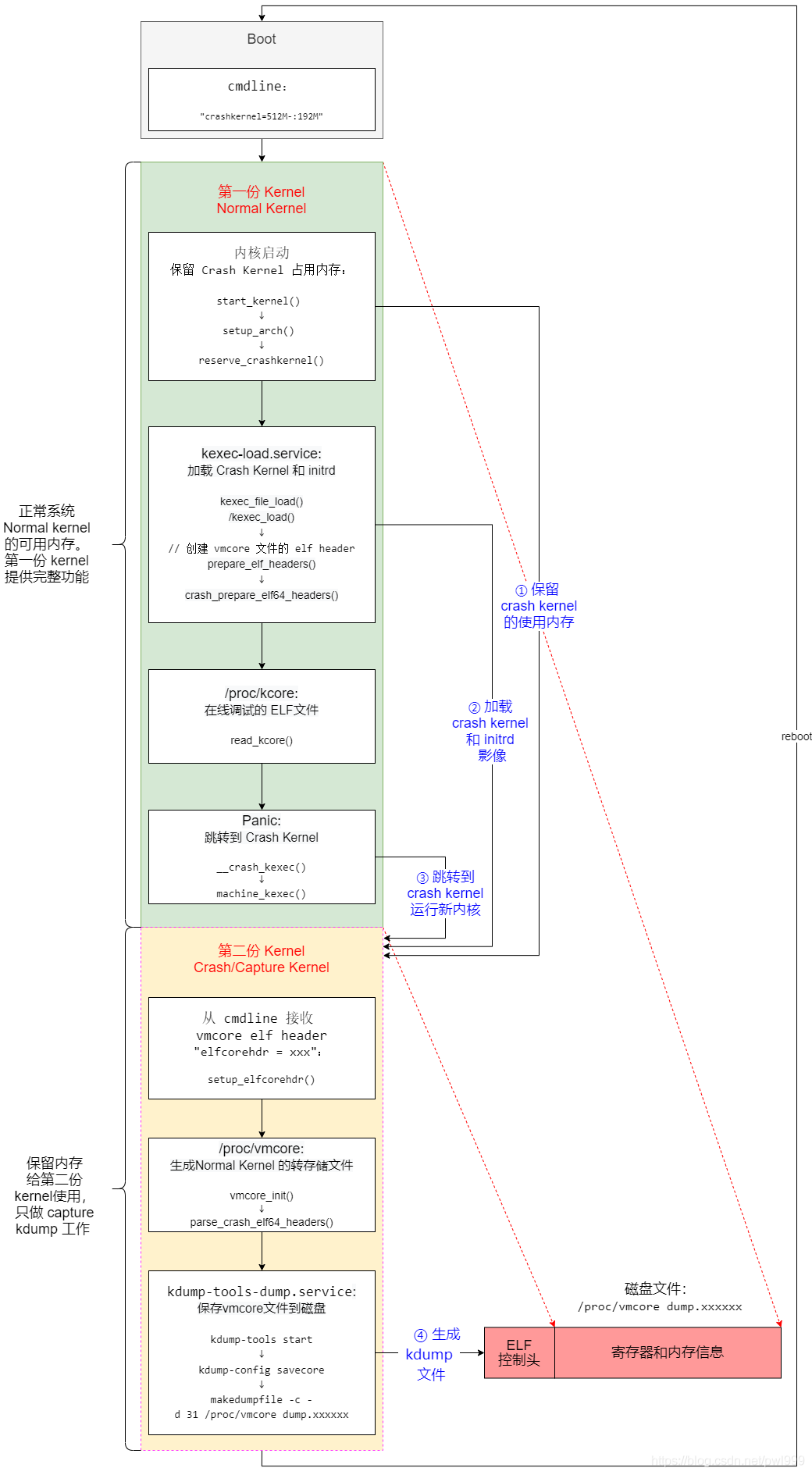
在内核崩溃的情况下,kdump 通过启动另一个 Linux 内核(称为 dump-capture kernel,)并使用它来导出和保存内存转储来保持系统一致性。 系统引导到一个干净可靠的环境,而不是依赖可能导致各种问题的已经崩溃的内核。kdump 使用 kexec 在内核崩溃后立即"warm"引导到dump-capture kernel,使用 kexec 的“引导”当前运行的内核的能力,同时避免执行引导加载程序和系统固件(BIOS 或 UEFI)。dump-capture kernel 可以是专门为此目的构建的独立Linux内核映像,也可以在支持可重定位内核的体系结构上重用主内核映像。
在引导并运行dump-capture kernel时,通过提前预留少量RAM来保留主内存(RAM)的内容,dump-capture kernel预加载到其中,因此在处理内核崩溃时不会覆盖主内核使用的任何 RAM,此保留的 RAM 量仅由 dump-capture kernel 使用,在正常系统操作期间不会使用该保留的 RAM。
对于x86架构 需要一小部分固定位置的 RAM 来引导内核,而不管它加载到哪里; 在这种情况下,kexec 创建该部分 RAM 的副本,以便dump-capture kernel也可以访问它。RAM 保留部分的大小和可选位置通过内核启动参数 crashkernel 指定,并且在主内核启动后使用 kexec 命令行程序( command-line utility )将dump-capture kernel image 及其关联的 initrd image 预加载到保留的那小部分内存。
除了作为 Linux 内核一部分的功能之外,其他用户空间实用程序支持 kdump 机制,包括上面提到的 kexec 实用程序。除了作为 kexec 用户空间实用程序套件的补丁提供的官方实用程序之外,一些 Linux 发行版 提供额外的实用程序来简化 kdump 操作的配置,包括自动保存内存转储文件的设置。 可以使用 GNU Debugger (gdb) 或使用 Red Hat 的专用crash utility 来分析创建的内存转储文件(memory dump files,即:vmcore)。
kdump 功能与 kexec 在内核版本 2.6.13 中合并到 Linux 内核主线中。
简单点来说就是:在主内核的保留一块内存区域,这块内存用来存放dump-capture kernel (我们暂且称它为捕获内核),当主内核发生crash(崩溃)的时候,通过kexec 运行保留在内存区域的 捕获内核 dump-capture kernel ,再由dump-capture kernel 负责把主内核发生故障时完整信息 - 包括CPU寄存器、堆栈数据等转储到指定位置的文件 vmcore(elf core 文件)中。
可见kdump 需要两个不同目的的内核,主内核(也叫生产内核)和捕获内核。主内核是捕获内核服务的对像。捕获内核会在生产内核崩溃时启动起来,与相应的 ramdisk 一起组建一个微环境,用以对生产内核下的内存进行收集和转存。
1.2 原理架构图
1.3 kdump配置
(1)kexec-tools
在centos7 中,kexec-tools都是已经默认安装的,我们可以用以下命令查看:kexec -v- 1
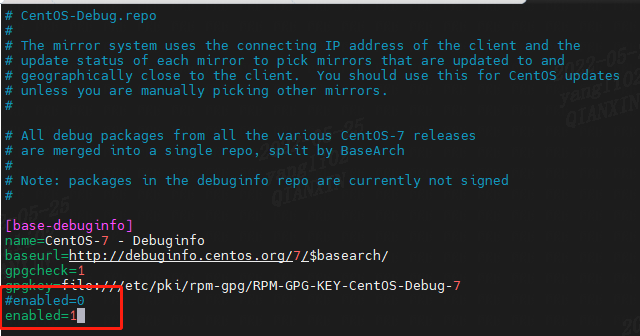
(2)安装 debuginfo-install
(如果调试的出现 :Missing separate debuginfos, use: debuginfo-install … 等错误,需用debuginfo-install安装各种调试包)vim /etc/yum.repos.d/CentOS-Debuginfo.repo- 1
将enabled参数由0改为1
yum install nss-softokn-debuginfo –nogpgcheck yum-utils -y- 1
然后就可以用 debuginfo-install 命令安装各种调试依赖了。
(3)kernel-debuginfo包
要调式内核故障时产生的vmcore文件,我们需要带有调试信息的内核,需要安装对应版本的kernel-debuginfo包。
如下所示:yum install -y kernel-debuginfo-$(uname -r)- 1
kernel-debuginfo-common
kernel-debuginfo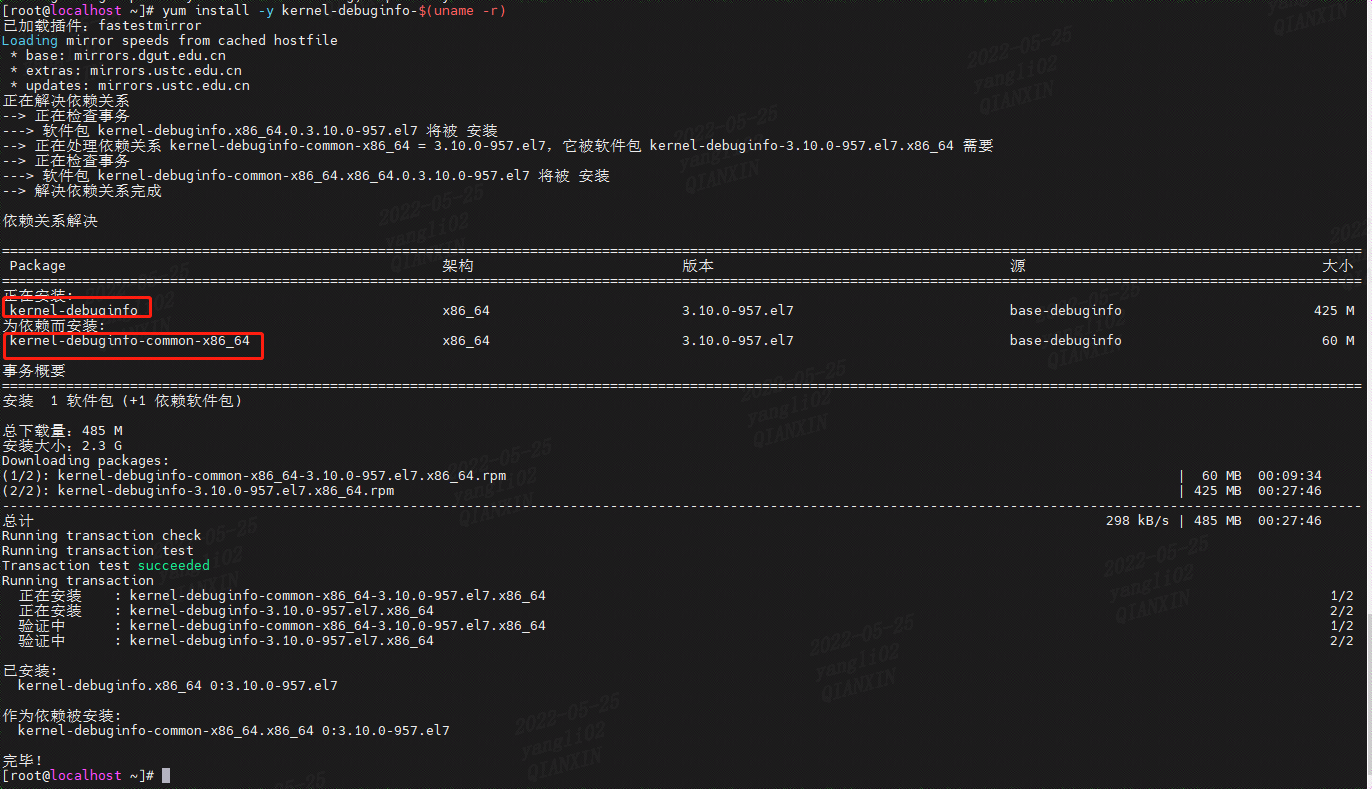
(4)捕获内核
捕获内核是一个未压缩的ELF映像文件,查看捕获内核是否加载到内存中:cat /sys/kernel/kexec_crash_loaded- 1

可见捕获内核已经加载到内存中了。(5)kdump配置
可以修改内核引导参数,为启动捕获内核预留指定内存:vim /etc/default/grub- 1
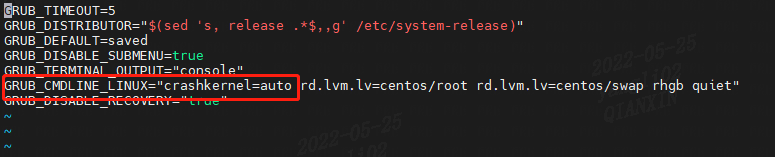
可以把 GRUB_CMDLINE_LINUX="crashkernel=auto 改为 GRUB_CMDLINE_LINUX="crashkernel=256M,这里我没有改。
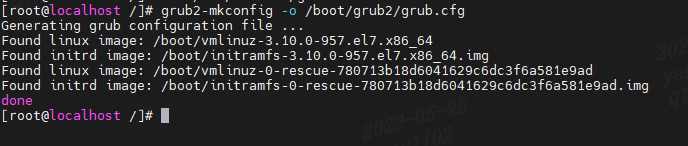
修改/etc/default/grub文件后就要grub配置:grub2-mkconfig -o /boot/grub2/grub.cfg reboot- 1
- 2
修改配置文件:vim /etc/kdump.conf- 1
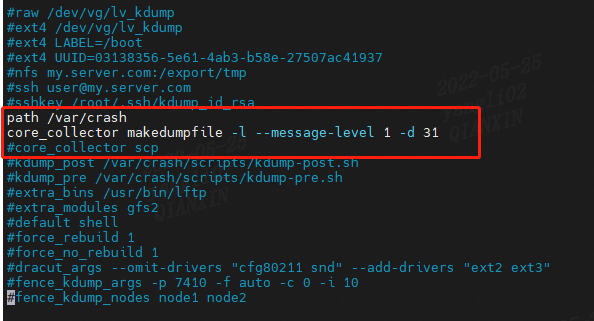
自己根据实际情况修改。二、crash
2.1 crash简介
上文说到 kdump 可在内核崩溃时创建 crash dumps,kdump 会导出一个内存映像( vmcore),我们可以对其进行分析,以用于调试和确定崩溃原因,分析的工具就是crash。
crash -:Analyze Linux crash dump data or a live system。可以看出crash既可以分析崩溃时产生的vmcore,又可以分析实时的系统内存。

crash要求调试内核vmlinux在编译时带有-g选项,即带有调试信息,在上面我们已经下载对应的安装包了。
yum install crash- 1
按crash命令直接就可以调试 live system 了。

/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux 是未压缩的可执行的内核映像文件。
(1)crash 支持的命令
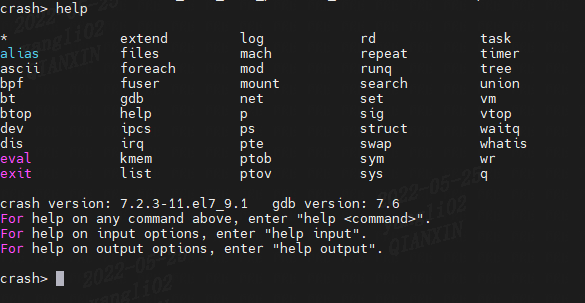
(2)dis命令
dis - disassemble
来举个例子说明dis的使用: dis address :starting hexadecimal text address.查看符号sk_load_half_positive_offset的地址:
cat /proc/kallsyms | grep "\<sk_load_half_positive_offset\>"- 1

dis ffffffff91e8f541- 1
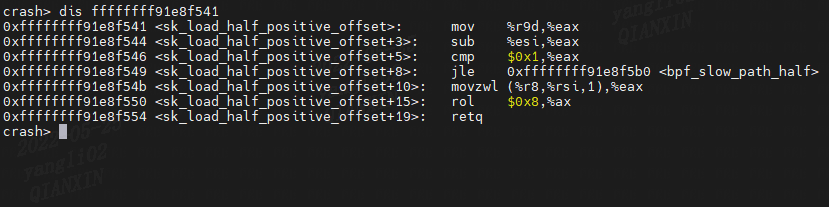
然后我们再看看内核源码关于该函数的代码:
内核版本3.10.1 ,文件位置arch/x86/net/bpf_jit.S ,是一个汇编文件//arch/x86/net/bpf_jit.S sk_load_half_positive_offset: .globl sk_load_half_positive_offset mov %r9d,%eax sub %esi,%eax # hlen - offset cmp $1,%eax jle bpf_slow_path_half movzwl (SKBDATA,%rsi),%eax rol $8,%ax # ntohs() ret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看出我们通过crash dis反汇编出来的代码与源码一样。
2.2 crash调试 vmcore
我们手动触发一次 panic:
echo c > /proc/sysrq-trigger- 1

触发后,系统直接重启。由前面我们可以知道:当系统崩溃时,kdump 使用 kexec 启动到第二个内核,即捕获内核,以很小内存启动以捕获转储镜像。第一个内核保留了内存的一部分给第二内核启动用。由于 kdump 利用 kexec 启动捕获内核,绕过了 BIOS,所以第一个内核的内存得以保留。
内存转储文件vmcore,默认位于/var/crash/%HOST-%DATE/vmcore,由kdump生成。
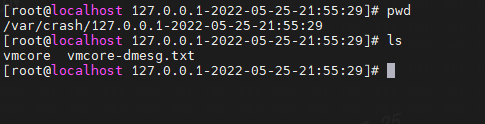
在这个目录下我们看到了两个文件vmcore 和 vmcore-demsg.txt
现在我们用crash调试这个vmcore:crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux vmcore- 1

其中一些参数解释:
KERNEL:系统崩溃时运行的 kernel 文件
DUMPFILE:内核转储文件
TASKS:系统崩溃时内存中的任务数
PANIC:崩溃类型,常见的崩溃类型包括:
(1)SysRq(System Request):通过组合键导致的系统崩溃,通常是测试使用。通过 echo c > /proc/sysrq-trigger,就可以触发系统崩溃。
c :Crashes the system without first unmounting file systems or syncing disks attached to the system.(2)oops:可以看成是内核级的 Segmentation Fault,比如内存访问越界或者非法指令(最常见的就是使用空指针)。应用程序如果进行了非法内存访问或执行了非法指令,会得到 Segfault 信号,一般行为是 coredump,应用程序也可以自己截获 Segfault 信号,自行处理。如果内核自己犯了这样的错误,则会弹出 oops 信息。
备注:oops在中断上下文发生时,内核无法继续运行,系统就死机了。如果oops发生在idle进程(0号进程)和init进程(1号进程)时,系统也会死机,因为内核缺少这两个重要的进程根本无法工作。不过,要是oops在其它进程运行时发生,内核就会尝试杀死该进程并尝试继续执行。
内核发布oops时。会像终端上输出错误信息,输出寄存器中保存的信息并输出可供跟踪的回溯资料。通过发送完oops后,内核会处于一种不稳定状态,系统死机重启。
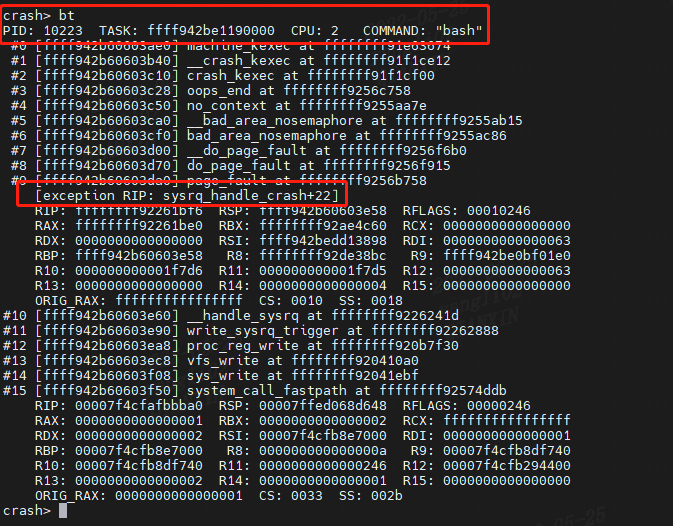
用bt命令查看:显示一个内核堆栈回溯。如果没有给出参数,则将显示当前上下文的堆栈跟踪。
RIP为造成内核崩溃的指令。
总结
本文知识简单的描述了kdump和crash的原理,安装以及使用方法。
参考资料
https://en.wikipedia.org/wiki/Kdump_(Linux)
https://blog.csdn.net/zhangskd/article/details/38084337
https://blog.csdn.net/pwl999/article/details/118418242
https://www.jianshu.com/p/ad03152a0a53
https://blog.csdn.net/rikeyone/article/details/105991074
https://zhuanlan.zhihu.com/p/104384020
https://blog.csdn.net/lx555222/article/details/110198405
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/4/html/reference_guide/s3-proc-sys-kernel -
相关阅读:
【腾讯云】推广者专属福利,新客户无门槛领取总价值高达2860元代金券,每种代金券限量500张,先到先得。
推荐搜索中各类排序算法综述
【RHCE】作业:firewall-cmd操作&ansible自动化运维入门
Shiro-全面详解(学习总结---从入门到深化)
布局与打包
Element ui table表格内容超出隐藏显示省略号
一招解决 | IP地址访问怎么实现https
机器学习8线性回归法Linear Regression
40 - 前置操作符和后置操作符
如果使用Vue要做根据已有的图形填入到指定的单元格中,你会怎么做?
- 原文地址:https://blog.csdn.net/weixin_45030965/article/details/124960224