论文地址:DCCRN:用于相位感知语音增强的深度复杂卷积循环网络
论文代码:https://paperswithcode.com/paper/dccrn-deep-complex-convolution-recurrent-1
引用:Hu Y,Liu Y,Lv S,et al. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement[J]. arXiv preprint arXiv:2008.00264,2020.
摘要
语音增强得益于深度学习在可理解性和感知质量方面的成功。传统的时频域方法主要是通过朴素卷积神经网络(CNN)或递归神经网络(RNN)预测TF掩码或语音频谱。最近的一些研究使用复值谱图作为训练目标,但在实值网络中训练,分别预测幅值分量和相位分量或实部和虚部。特别是,卷积循环网络(CRN)集成了卷积编解码(CED)结构和长短期记忆(LSTM),已被证明对复杂目标有帮助。为了更有效地训练复杂目标,本文设计了一种新的模拟复杂值运算的网络结构——深度复杂卷积递归网络(Deep complex Convolution recurn,DCCRN),其中CNN和RNN结构都可以处理复杂值运算。提出的DCCRN模型在客观或主观度量上都比以前的其他网络具有很强的竞争力。在仅有3.7M参数的情况下,我们提交给Interspeech 2020深度噪声抑制(DNS)挑战的DCCRN模型在实时轨道中排名第一,在非实时轨道中排名第二。
关键词:语音增强,去噪,深度学习,复杂网络
1 引言
噪声干扰会严重降低言语交际中的感知质量和可理解性。同样,自动语音识别(ASR)等相关任务也会受到噪声干扰的严重影响。因此,语音增强是一项非常迫切的任务,它将噪声语音作为输入,产生增强的语音输出,以提高语音质量和清晰度,有时还能在下游任务中提供更好的标准(例如ASR中的较低错误率)。近年来,深度学习(DL)方法在语音增强方面取得了很好的效果,尤其是在处理非平稳噪声方面。DL可以受益于单通道(单耳)和多通道语音增强取决于具体的应用。在本文中,我们专注于基于dl的单通道语音增强,以获得更好的感知质量和可理解性,特别是针对低模型复杂性的实时处理。Interspeech 2020深度噪声抑制(DNS)挑战为这一目的提供了一个通用的测试平台[1]。
1.1 相关工作
作为一个有监督的学习问题,神经网络可以在时频域或直接在时域增强噪声语音。时域方法可以进一步分为直接回归方法[2,3]和自适应前端方法[4 6]两类。前者直接从语音-噪声混合的波形学习到目标语音的回归函数,而不需要明确的信号前端,通常是通过涉及某种形式的一维卷积神经网络(Conv1d)。后一种自适应前端方法将时域信号输入和输出,通常采用卷积编解码器(CED)或u-net框架,类似于短时傅里叶变换(STFT)及其反变换(iSTFT)。然后,在编码器和解码器之间插入增强网络,通常通过使用具有时间建模能力的网络,如时间卷积网络(TCN)[4,7]和长短期记忆(LSTM)[8]。
作为另一种主流,TF域方法[9 13]对声谱图进行研究,认为使用STFT后的TF表示可以更精确地分离语音和噪声的精细结构。卷积递归网络(CRN)[14]是一种最新的方法,它也采用了与时域方法相似的CED结构,但它提取了高层次的特征,以便通过二维CNN (Conv2d)更好地分离噪声语音谱图。具体来说,CED可以将复数谱图或实值谱图作为输入。复数谱图在极坐标下可分解为幅值和相位,在笛卡尔坐标下可分解为实部和虚部。很长一段时间以来,人们一直认为阶段是难以估计的。因此,早期的研究只关注与幅度相关的训练目标,而忽略相位[15 17],通过简单地将估计的幅度与带噪声的语音相位结合来重新合成估计的语音。这就限制了性能的上限,而在严重干扰的情况下,估计的语音相位会显著偏离。虽然最近有许多方法被提出用于相位重建来解决这个问题[18,19],但神经网络仍然具有实际价值。
通常情况下,TF域中定义的训练目标主要分为两类,一类是描述干净语音与背景噪声时频关系的掩模目标,另一类是对应于干净语音频谱表示的映射目标。在掩码族中,理想二进制掩码(IBM)[20]、理想比率掩码(IRM)[10]和谱幅值掩码(SMM)[21]只使用干净语音和混合语音之间的幅值,忽略了相位信息。相敏掩模(PSM)[22]是第一个利用相位信息显示相位估计可行性的掩模。在此基础上,提出了复合比掩码[23](complex ratio mask,CRM)算法,该算法通过同时增强纯语音和混合语音谱图分割的实成分和虚成分,可以很好地重构语音。随后,Tan等人提出了一种具有一个编码器和两个解码器的复杂谱映射(CSM)的CRN,以同时估计混合语音的实和虚谱图。值得注意的是,CRM和CSM包含了语音信号的全部信息,因此理论上它们可以获得最佳的oracle语音增强性能。
上述方法是在一个重估网络下学习的,但也考虑了相位信息。近年来,深度复杂u-net[25]结合了深度复杂网络[26]和u-net[27]的优点来处理复值谱图。特别是,DCUNET经过训练,估计CRM,并在iSTFT将输出tf域谱图转换为时域波形后,优化尺度不变的源噪声比(SI-SNR)损失[4]。在利用时间建模能力实现最先进性能的同时,采用多层卷积来提取重要的上下文信息,导致模型规模大、复杂性高,限制了其在效率敏感应用中的实际应用。
1.2 贡献
在本文中,我们在先前的网络架构的基础上,设计了一个新的复值语音增强网络,称为深度复杂卷积递归网络(DCCRN),以优化SI-SNR损耗。该网络有效地结合了DCUNET和CRN的优点,利用LSTM对时间上下文进行建模,显著降低了可训练参数和计算成本。在提出的DCCRN框架下,我们还比较了各种训练目标,复杂网络与复杂目标可以获得最佳的性能。在我们的实验中,我们发现所提出的DCCRN比CRN[24]的性能要好很多。DCCRN的计算复杂度仅为DCUNET[25]的1/6,在相似的模型参数配置下,其性能与DCUNET[25]相当。而针对实时语音增强,我们的模型仅使用3.7M参数,根据DNS挑战中的P.808主观评价,在实时轨道上实现了最佳MOS,在非实时轨道上次之。
2 DCCRN模型
2.1 卷积循环网络结构

图1 DCCRN 模型
卷积循环网络(CRN),最初在[14]中描述,本质上是因果CED架构,在编码器和解码器之间有两个LSTM层。在这里,LSTM专门用于建模时间依赖关系。该编码器由5个Conv2d块组成,旨在从输入特征中提取高级特征,或降低分辨率。随后,解码器将低分辨率特征重构为输入的原始尺寸,使得编解码器结构达到对称设计。具体来说,编码器/解码器Conv2d块由卷积/反卷积层、批处理归一化和激活函数组成。跳跃式连接通过集中编码器和解码器,有利于梯度的流动。
与原始的带幅值映射的CRN不同,Tan等人最近提出了一种带有一个编码器和两个解码器的改进结构,从输入混合到干净语音,对复杂STFT谱图的实部和虚部进行建模。与传统的仅震级目标相比,同时增强震级和相位得到了显著的改善。但是,他们将实部和虚部作为两个输入通道,只使用一个共享的实值卷积滤波器进行实值卷积运算,不受复乘法规则的限制。因此,网络可以在没有先验知识的情况下学习实部和虚部。针对这一问题,本文提出的DCCRN在编解码器中使用复杂的CNN和复杂的批处理归一化层对CRN进行了大量的修改,并考虑用复杂的LSTM来替代传统的LSTM。具体来说,复杂模块通过模拟复数乘法来模拟幅值和相位之间的相关关系。
2.2 带复数网络的编码和解码结构

图2 复数模块
复编码器块包括复Conv2d、复批归一化[26]和实值PReLU[28]。复杂批处理归一化和PReLU继承了原论文的实现。我们根据DCUNET[25]中复杂的Conv2d块进行设计。复杂的Conv2d包含四个传统的Conv2d操作,它们控制整个编码器的复杂信息流。将复值卷积滤波器$W$定义为$W = W_r+j*W_i$,其中实值矩阵$W_r$和$W_i$分别表示复卷积核的实部和虚部。同时定义输入复矩阵$X = X_r +j*X_i$。因此,我们可以通过$X\circledast W$的复卷积运算得到复输出$Y$:
$$公式1:F_{\text {out }}=\left(X_{r} * W_{r}-X_{i} * W_{i}\right)+j\left(X_{r} * W_{i}+X_{i} * W_{r}\right)$$
其中$F_{out}$表示一个复杂层的输出特征。
与复卷积类似,给定复输入$X_r$和$X_i$的实部和虚部,复LSTM输出$F_{out}$可以定义为:
$$公式2:F_{r r}=\operatorname{LSTM}_{r}(X_{r}) ; \quad F_{i r}=\operatorname{LSTM}_{r}(X_{i})$$
$$公式3:F_{r i}=\operatorname{LSTM}_{i}(X_{r}) ; \quad F_{i i}=\operatorname{LSTM}_{i}(X_{i})$$
$$公式4:F_{\text {out }}=(F_{r r}-F_{i i})+j(F_{r i}+F_{i r})$$
其中$LSTM_r$和$LSTM_i$代表两种传统的实部和虚部LSTM,$F_{ri}$是通过输入带有$LSTM_i$的$X_r$计算的。
2.3 训练目标
训练时,DCCRN估计CRM,并通过信号近似(SA)进行优化。给定干净语音S和有噪声语音Y的复值STFT谱图,可将CRM定义为
$$公式5:\mathrm{CRM}=\frac{Y_{r} S_{r}+Y_{i} S_{i}}{Y_{r}^{2}+Y_{i}^{2}}+j \frac{Y_{r} S_{i}-Y_{i} S_{r}}{Y_{r}^{2}+Y_{i}^{2}}$$
其中$Y_r$和$Y_i$分别表示带噪语音复数谱的实部和虚部。清洁复谱图的实部和虚部由$S_r$和$S_i$表示。量级目标SMM也可以用来比较:$SMM=\frac{|S|}{|Y|}$,其中$|S|$和$|Y|$分别表示干净语音和噪声语音的量级。我们采用信号近似的方法,直接将干净语音的幅值或复杂语谱图与使用掩码的噪声语音的幅值或复谱图之间的差异最小化。SA的损失函数变为$CSA=Loss(\tilde{M}*Y,S)$和$MSA=Loss(\tilde{M}*|Y|,|S|)$,其中CSA表示基于CRM的SA,MSA表示基于SMM的SA。或者,笛卡尔坐标表示$\tilde{M}=\tilde{M}_r+j\tilde{M}_i$也可以用极坐标表示。
$$公式6:\left\{\begin{array}{l}
\tilde{M}_{\text {mag }}=\sqrt{\tilde{M}_{r}{ }^{2}+\tilde{M}_{i}{ }^{2}} \\
\tilde{M}_{\text {phase }}=\arctan 2\left(\tilde{M}_{i},\tilde{M}_{r}\right)
\end{array}\right.$$
我们可以对DCCRN使用三种乘法模式,稍后将与实验进行比较。具体来说,估计的纯净语音$\tilde{S}$可以计算如下:
DCCRN-R:
$$公式7:\tilde{S}=\left(Y_{r} \cdot \tilde{M}_{r}\right)+j\left(Y_{i} \cdot \tilde{M}_{i}\right)$$
DCCRN-C:
$$公式8:\tilde{S}=\left(Y_{r} \cdot \tilde{M}_{r}-Y_{i} \cdot \tilde{M}_{i}\right)+j\left(Y_{r} \cdot \tilde{M}_{i}+Y_{i} \cdot \tilde{M}_{r}\right)$$
DCCRN-E:
$$公式9:\tilde{S}=Y_{\text {mag }} \cdot \tilde{M}_{\text {mag }} \cdot e^{Y_{\text {phase }}+\tilde{M}_{\text {phase }}}$$
DCCRN-C采用CSA方法得到$\tilde{S}$,DCCRN-R分别估计$\tilde{Y}$的实部和虚部掩码。此外,DCCRN-E在极坐标下执行,它在数学上与DCCRN-C相似。不同之处在于DCCRN-E使用tanh激活函数将掩模幅值限制在0到1之间。
2.4 损失函数
模型训练的损失函数是SI-SNR,它已经被普遍用来代替均方误差(MSE)作为评价指标。SI-SNR定义为
$$公式10:\begin{cases}s_{\text {target }} & :=(\langle\tilde{s},s\rangle \cdot s) /\|s\|_{2}^{2} \\ e_{\text {noise }} & :=\tilde{s}-s_{\text {target }} \\ \text { SI-SNR } & :=10 \log 10\left(\frac{\left\|s_{\text {target }}\right\|_{2}^{2}}{\left\|e_{\text {noise }}\right\|_{2}^{2}}\right)\end{cases}$$
其中$s$和$\tilde{s}$分别为干净的和估计的时域波形。$<·,·>$表示两个向量之间的点积,$||·||_2$为欧几里得范数(L2范数)。详细地,我们使用STFT内核初始化卷积/反卷积模块对波形[29]进行分析/合成,然后发送到网络并计算损耗函数。
3 实验
3.1 数据集
在我们的实验中,我们首先在WSJ0[30]上模拟的数据集上评估了提出的模型以及几个基线,然后在Interspeech2020 DNS Challenge数据集[1]上进一步评估了表现最好的模型。对于第一个数据集,我们从WSJ0[30]中选择24500个话语(大约50个小时),其中包括131位发言者(66位男性和65位女性)。我们将训练集、验证集和评估集分别分解为20000、3000和1500个话语集。噪声数据集包含6.2小时的自由声音噪声和来自MUSAN[31]的42.6小时的音乐,其中41.8小时用于培训和验证,其余7小时用于评估。训练和验证中的语音-噪声混合是通过从语音集和噪声集中随机选择话语,并在-5 ~ 20 dB的随机信噪比下混合而产生的。评估集在5个典型信噪比(0 dB,5 dB,10 dB,15 dB,20 dB)下生成。
第二个大数据集是基于DNS挑战提供的数据。180小时的DNS挑战噪声集包括150个类别和65,000个噪声剪辑,干净的演讲集包括来自2150个扬声器的超过500小时的剪辑。为了充分利用数据集,我们在模型训练过程中采用动态混合的方法模拟语音-噪声混合。在细节,每个培训时代,我们rst语音和噪声的房间脉冲响应卷积(RIR)随机选择从一个模拟3000 - RIR形象设定的方法[32],然后是语言噪声混合动态生成的随机混合混响语音和噪声信噪比5至20分贝。经过10次训练后,模型所看到的总数据超过5000小时。我们使用官方测试集进行客观评分和最终的模型选择。
3.2 训练步骤和基线
所有模型的窗长和帧移分别为25 ms和6.25 ms,FFT长度为512。我们使用Pytorch来训练模型,优化器是Adam。初始学习率设置为0.001,当验证损失增加时,学习率将衰减0.5。所有的波形在16k Hz重新采样。通过早期停止选择模型。为了选择DNS挑战的模型,我们比较了WSJ0模拟数据集上的几个模型,如下所述。
- LSTM:半因果模型包含两个LSTM层,每层800个单元;我们添加了一个Conv1d层,其中krenel size=7在时间维度上卷积,look-ahead为6帧,以实现半因果关系。输出层是一个257单元的全连接层。输入和输出分别是噪声谱图和MSA估计的干净谱图。
- CRN:半因果模型包含一个编码器和两个解码器,它们在[24]中具有最佳配置。输入和输出是噪声和估计STFT复谱图的实部和虚部。两个解码器分别处理实部和虚部。在频率和时间维度上,kernel size也是(3,2),stride被设置为(2,1)。对于编码器,我们在通道维度中连接实部和虚部,因此输入特征的形状是[BatchSize,2,Frequency,Time]。编码器中每一层的输出通道为{16,32,64,128,256,256}。隐藏的LSTM单元为256个,在最后一个LSTM之后出现了1280个单元的密集层。由于跳跃连接,实解码器或虚解码器的输入通道每一层为{512,512,256,128,64,32}。
- DCCRN:四种模型由DCCRN- r、DCCRN- c、DCCRN- e和DCCRN- cl(掩蔽像DCCRN- e)组成。所有这些型号的直流电元件都去掉了。前三个DCCRN的通道数为{32,64,128,128,256,256},而DCCRN- cl的通道数为{32,64,128,256,256,256}。kernel size和stride分别设置为(5,2)和(2,1)。前3个DCCRN的实LSTM为2层,256个单元,DCCRN- cl的实部和虚部分别使用128个单元的复LSTM。在最后一个LSTM之后是1024个单元的密集层。
- DCUNET:我们使用DCUNET-16进行比较,将时间维度stride设置为1,以适应DNS挑战规则。另外,编码器中的信道设置为[72,72,144,144,144,1600,1600,180]。
对于半因果卷积[33]的实现,与实践中常用的因果卷积只有两个不同之处。首先,我们在编码器的每个Conv2ds的时间维度前填充0。其次,对于解码器,我们在每个卷积层中向前看一帧。这最终导致了6帧的抬头,总共66:25 = 37:5毫秒,限制在DNS挑战限制40毫秒内。
3.3 实验结果和讨论
模型性能首先由PESQ1在模拟的WSJ0数据集上评估。表1给出了测试集上的PESQ分数。在每种情况下,最好的结果都用黑体数字突出显示。
表1 在模拟WSJ0数据集上的PESQ
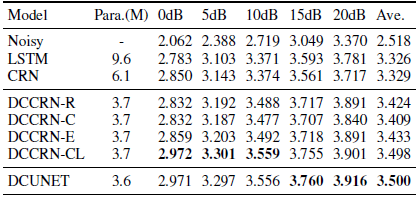
在模拟的 WSJ0 测试集上,我们可以看到四个 DCCRN 的性能优于基线 LSTM 和 CRN,这表明复杂卷积的有效性。 DCCRNCL 实现了比其他 DCCRN 更好的性能。 这进一步说明复杂LSTM也有利于复杂目标的训练。 此外,我们可以看到全复值网络 DCCRN 和 DCUNET 在 PESQ 中是相似的。 值得注意的是,根据我们的运行时测试,DCUNET 的计算复杂度几乎是 DCCRN-CL 的 6 倍。
在DNS挑战中,我们使用DNS数据集评估了两个最好的DCCRN模型和DCUNET。表2显示了测试集中的PESQ分数。类似地,一般来说,DCCRN-CL比DCCRN-E实现更好一点的PESQ。但在我们的内部主语听力后,我们发现DCCRN-CL可能会对某些片段的语音信号进行过度抑制,导致不愉快的听力体验。DCUNET在合成无混响装置上得到了较好的PESQ,但在合成混响装置上其PESQ会明显下降。我们相信,当不同系统的客观分数接近时,主观听力变得非常重要。基于这些原因,DCCRN-E最终被选择用于实时轨道。为了提高混响集的性能,我们在训练集中增加了更多的RIRs,得到了一个名为DCCRN-E-Aug的模型,它被选择用于非实时跟踪。从表3中最终盲测集的结果可以看出,DCCRN-E-Aug的MOS比混响集有小幅提高0.02。表3总结了竞赛组织者提供的两个轨道几个顶级系统的最终P.808主观评价结果。我们可以看到,我们提交的模型总体上表现良好。DCCRN-E实现了平均MOS 3.42在所有设置和4.00在无混响设置。我们的DCCRN-E的PyTorch实现(由ONNX导出)的一帧处理时间是3.12毫秒,在Intel i5-8250U PC上进行了经验测试。一些增强的音频剪辑可以从https:// huyanxin.github.io/DeepComplexCRN找到。
表2:DNS挑战测试集上的PESQ(仅模拟数据)。
T1和T2表示轨道1(实时轨道)和轨道2(非实时轨道)。

表3 MOS对DNS挑战盲测试集

4 总结
在这项研究中,我们提出了一个深度复杂卷积循环网络语音增强。DCCRN模型利用复杂网络进行复值频谱建模。由于具有复杂的乘法规则约束,在模型参数配置相似的情况下,DCCRN在PESQ和MOS方面的性能优于其他模型。在未来,我们将尝试在边缘设备等低计算场景中部署DCCRN。我们还将启用DCCRN,提高混响条件下的噪声抑制能力。
参考文献
[1] C. K. Reddy,V. Gopal,R. Cutler,E. Beyrami,R. Cheng,H. Dubey,S. Matusevych,R. Aichner,A. Aazami,S. Braun et al.,The interspeech 2020 deep noise suppression challenge: Datasets,subjective testing framework,and challenge results,arXiv preprint arXiv:2005.13981,2020.
[2] S.-W. Fu,T.-W. Wang,Y. Tsao,X. Lu,and H. Kawai,End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks,IEEE/ACM Transactions on Audio,Speech,and Language Processing,vol. 26,no. 9,pp. 1570 1584,2018.
[3] D. Stoller,S. Ewert,and S. Dixon,Wave-u-net: A multi-scale neural network for end-to-end audio source separation,arXiv preprint arXiv:1806.03185,2018.
[4] Y. Luo and N. Mesgarani,Conv-tasnet: Surpassing ideal time frequency magnitude masking for speech separation,IEEE/ACM transactions on audio,speech,and language processing,vol. 27,no. 8,pp. 1256 1266,2019. [5] Y. Luo,Z. Chen,and T. Yoshioka,Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,arXiv preprint arXiv:1910.06379,2019.
[6] L. Zhang,Z. Shi,J. Han,A. Shi,and D. Ma,Furcanext: Endto- end monaural speech separation with dynamic gated dilated temporal convolutional networks,in International Conference on Multimedia Modeling. Springer,2020,pp. 653 665.
[7] S. Bai,J. Z. Kolter,and V. Koltun,An empirical evaluation of generic convolutional and recurrent networks for sequence modeling,arXiv preprint arXiv:1803.01271,2018.
[8] F. Weninger,H. Erdogan,S. Watanabe,E. Vincent,J. L. Roux,J. R. Hershey,and B. Schuller,Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr,Latent Variable Analysis and Signal Separation Lecture Notes in Computer Science,p. 9199,2015.
[9] S. Srinivasan,N. Roman,and D. Wang,Binary and ratio time-frequency masks for robust speech recognition,Speech Communication,vol. 48,no. 11,pp. 1486 1501,2006.
[10] A. Narayanan and D. Wang,Ideal ratio mask estimation using deep neural networks for robust speech recognition,in 2013 IEEE International Conference on Acoustics,Speech and Signal Processing. IEEE,2013,pp. 7092 7096.
[11] Y. Zhao,D. Wang,I. Merks,and T. Zhang,DNN-based enhancement of noisy and reverberant speech,in 2016 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2016,pp. 6525 6529.
[12] Y. Xu,J. Du,L.-R. Dai,and C.-H. Lee,An experimental study on speech enhancement based on deep neural networks,IEEE Signal processing letters,vol. 21,no. 1,pp. 65 68,2013.
[13] D. Yin,C. Luo,Z. Xiong,and W. Zeng,Phasen: A phase-andharmonics- aware speech enhancement network,arXiv preprint arXiv:1911.04697,2019.
[14] K. Tan and D. Wang,A convolutional recurrent neural network for real-time speech enhancement. in Interspeech,vol. 2018,2018,pp. 3229 3233.
[15] P.-S. Huang,M. Kim,M. Hasegawa-Johnson,and P. Smaragdis,Deep learning for monaural speech separation,in 2014 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2014,pp. 1562 1566.
[16] Y. Xu,J. Du,L.-R. Dai,and C.-H. Lee, A regression approach to speech enhancement based on deep neural networks,IEEE/ACM Transactions on Audio,Speech,and Language Processing,vol. 23,no. 1,pp. 7 19,2014.
[17] N. Takahashi,N. Goswami,and Y. Mitsufuji,Mmdenselstm: An efficient combination of convolutional and recurrent neural networks for audio source separation,in 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC). IEEE,2018,pp. 106 110.
[18] Y. Wang and D. Wang,A deep neural network for time-domain signal reconstruction,in 2015 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2015,pp. 4390 4394.
[19] Y. Liu,H. Zhang,X. Zhang,and L. Yang,Supervised speech enhancement with real spectrum approximation,in ICASSP 2019-2019 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2019,pp. 5746 5750.
[20] D. Wang,On ideal binary mask as the computational goal of auditory scene analysis,in Speech separation by humans and machines. Springer,2005,pp. 181 197.
[21] Y. Wang,A. Narayanan,and D. Wang,On training targets for supervised speech separation,IEEE/ACM transactions on audio,speech,and language processing,vol. 22,no. 12,pp. 1849 1858,2014.
[22] H. Erdogan,J. R. Hershey,S. Watanabe,and J. Le Roux,Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks,in 2015 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2015,pp. 708 712.
[23] D. S. Williamson,Y. Wang,and D. Wang,Complex ratio masking for monaural speech separation,IEEE/ACM transactions on audio,speech,and language processing,vol. 24,no. 3,pp. 483 492,2015.
[24] K. Tan and D. Wang,Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement,in ICASSP 2019-2019 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2019,pp. 6865 6869.
[25] H.-S. Choi,J.-H. Kim,J. Huh,A. Kim,J.-W. Ha,and K. Lee,Phase-aware speech enhancement with deep complex u-net,arXiv preprint arXiv:1903.03107,2019.
[26] C. Trabelsi,O. Bilaniuk,Y. Zhang,D. Serdyuk,S. Subramanian,J. F. Santos,S. Mehri,N. Rostamzadeh,Y. Bengio,and C. J. Pal,Deep complex networks,arXiv preprint arXiv:1705.09792,2017.
[27] O. Ronneberger,P. Fischer,and T. Brox,U-net: Convolutional networks for biomedical image segmentation,in International Conference on Medical image computing and computer-assisted intervention. Springer,2015,pp. 234 241.
[28] K. He,X. Zhang,S. Ren,and J. Sun,Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,in Proceedings of the IEEE international conference on computer vision,2015,pp. 1026 1034.
[29] R. Gu,J. Wu,S.-X. Zhang,L. Chen,Y. Xu,M. Yu,D. Su,Y. Zou,and D. Yu,End-to-end multi-channel speech separation,arXiv preprint arXiv:1905.06286,2019.
[30] J. Garofolo,D. Graff,D. Paul,and D. Pallett,Csr-i (wsj0) complete ldc93s6a,Web Download. Philadelphia: Linguistic Data Consortium,vol. 83,1993.
[31] D. Snyder,G. Chen,and D. Povey,MUSAN: A Music,Speech,and Noise Corpus,2015,arXiv:1510.08484v1.
[32] J. B. Allen and D. A. Berkley,Image method for efficiently simulating small-room acoustics,The Journal of the Acoustical Society of America,vol. 65,no. 4,pp. 943 950,1979.
[33] F. Bahmaninezhad,S.-X. Zhang,Y. Xu,M. Yu,J. H. Hansen,and D. Yu,A unified framework for speech separation,arXiv preprint arXiv:1912.07814,2019.
[34] Y. Xia,S. Braun,C. K. A. Reddy,H. Dubey,R. Cutler,and I. Tashev,Weighted speech distortion losses for neural-networkbased real-time speech enhancement,in ICASSP 2020 - 2020 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),2020,pp. 871 875.
作者:凌逆战
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
本文章不做任何商业用途,仅作为自学所用,文章后面会有参考链接,我可能会复制原作者的话,如果介意,我会修改或者删除。