-
QWEN technical report

3万亿token,
2.pretraining
2.1 data
去重,精确匹配去重和使用MinHash和LSH模糊去重,过滤低质量的数据,采用了基于规则和基于机器学习的方法的组合,使用多个模型对内容进行评分,包括语言模型、文本质量评分模型以及用于识别有可能含有不合适的内容的模型。构建了一个高达3万亿个token的数据集。
2.2 tokenization
采用字节对编码BPE分词,使用tiktoken。在中文,增加了常用的汉字和词汇以及其它语言中的词汇,遵循llama系列的方法,将数字拆分成单个数字,最终词汇为152k。压缩率:一个汉字能够转成多少token,比如0.52个token,意味着一句话能够转成更少的token。
2.3 architecture
结构基本和llama对齐。

embedding和output project:对于embedding层和lm_head层不进行权重共享,是两个独立的权重。
positional embedding:RoPE
bias:在qkv中添加了偏差,以增强模型外推能力。
Pre-RMSNorm
激活函数:SwiGLU
2.4 training
上下文长度:2048,采用flash attention,AdamW,BFloat16
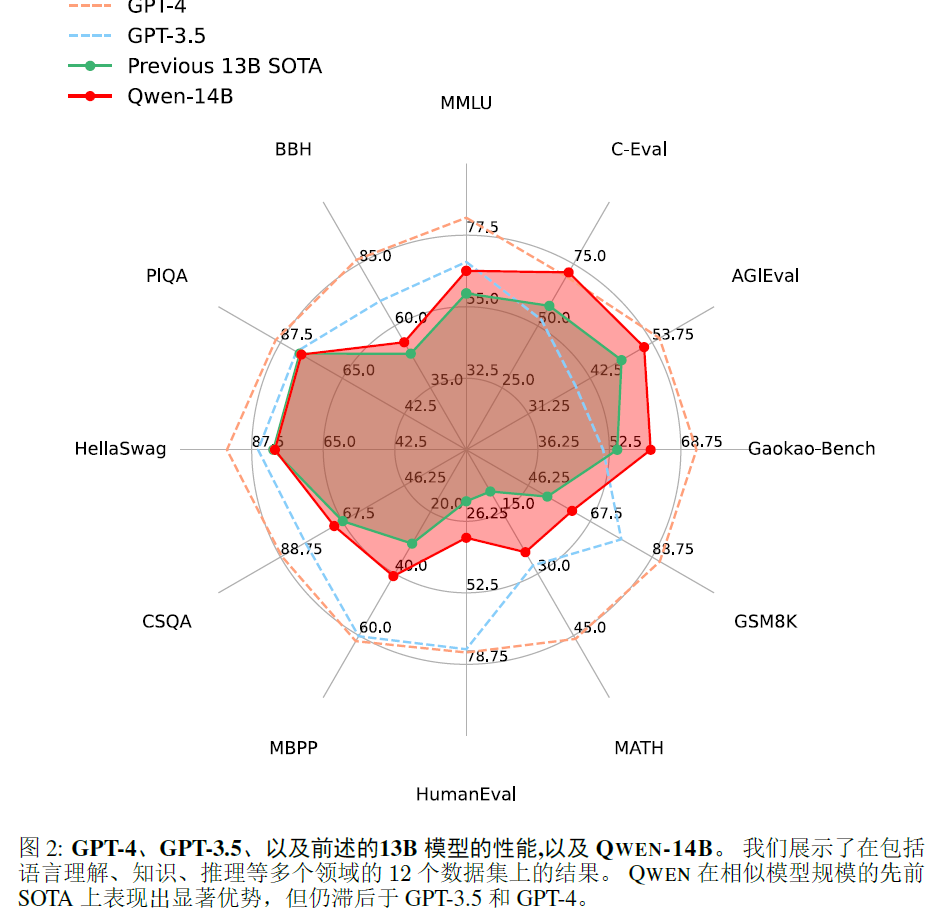
2.5 experimental results

-
相关阅读:
【C++】开源:rapidjson数据解析库配置与使用
JDBC 访问数据库
现如今大数据的框架
【Vue域名动态配置】
Azure Synapse Analytics上创建用户并赋予权限
(五)算法基础——分治
Ansys Zemax | 解像力仿真设计
excel自定义函数之汉字转为拼音及大写字母
公众号推送早安问候以及天气预报(JAVA)
[Kettle] 生成记录
- 原文地址:https://blog.csdn.net/u012193416/article/details/134061242
 https://zhuanlan.zhihu.com/p/658392609
https://zhuanlan.zhihu.com/p/658392609