Onehouse 创始人/首席执行官 Vinoth Chandar 于 2022 年 3 月在奥斯汀数据委员会发表了这一重要演讲。奥斯汀数据委员会是“世界上最大的独立全栈数据会议”,这是一个由社区驱动的活动,包括数据科学、数据工程、分析、机器学习 (ML)、人工智能 (AI) 等。
Vinoth Chandar 在 Uber 工作期间发起了数据湖仓一体架构,他是 Apache Hudi 项目的项目管理委员会 (PMC) 主席。Hudi 最初被描述为“事务性数据湖”,现在被认为是 Databricks 在 2020 年引入该术语后的第一个,也是三个领先的数据湖仓一体项目之一。
在本次演讲中 Vinoth 比较了数据仓库、数据湖和数据湖仓一体的过去、现在和未来用途。最后呼吁采用开放的、湖仓一体优先的架构,大多数工作负载直接由统一的数据湖仓一体提供服务。在此体系结构中,湖仓一体服务于多个不同的引擎,这些引擎专注于报告、商业智能、预测分析、数据科学和 ML/AI 等领域。
我们将演讲分为两篇博文:
- 第一篇博文(这篇文章)描述了数据仓库和数据湖仓一体的演变,并指出了两者之间的架构差异。
- 第二篇文章比较了数据仓库和数据湖仓一体架构的功能和性价比特征。最后描述一种面向未来的、湖仓一体优先的架构。
目标
Hudi 是我在 Uber 工作时开始的一个项目,在过去的五年里一直在与 Apache 软件基金会一起发展社区。有了 Onehouse,我们做了更多与我在 Uber 工作时相同的分布式数据仓库/数据库类型的工作。
Hudi 有很多很好的材料,我们总是可以通过 Hudi Slack 进行连接。今天不谈 Hudi,而是列出每个人都熟悉的数据仓库与数据湖和数据湖仓一体之间的区别,后者较新。我将描述整体架构,如何思考问题,以及应该留在当前的架构中还是继续演进。
演讲的目标包括:
- 描述数据仓库和数据湖的融合
- 澄清常见问题和争论点
- 指出细微但重要的技术差异
那么为什么现在要做这样的演讲呢?几个原因:
- 多元化的背景。数据社区拥有具有非常多样化背景的人。我有一个更面向数据库的背景;我相信你们中的许多人都来自 Spark 世界、流、Flink、Python 等。
- 很多选择。现代数据基础架构有很多选择,其中包括数据仓库,然后是数据湖,以及最近的数据湖仓一体。
- 了解权衡取舍。这给了我们一个很好的机会来了解我们如何挑选,以及我们如何一起理解权衡。
首先,我们将勾勒出这些技术的演变以及我们是如何走到这一步的弧线。然后我们将尝试从这三个不同的方面来理解和研究它们:架构、功能和性价比。最后我将给大家描述我所看到的模式,提炼我在 Hudi 社区中看到的模式,以一种更平衡、更面向未来的方式来构建核心数据基础设施和架构。
以更平衡、更面向未来的方式来构建核心数据基础架构和架构
技术的演变
本地数据仓库(下面幻灯片中的第一个弧线)现在可以看作是用于分析的专用数据库。很长一段时间以来这就是我们所拥有的一切。然后2012年推出了BigQuery(无服务器查询),现在围绕仓储领域发生了许多创新。
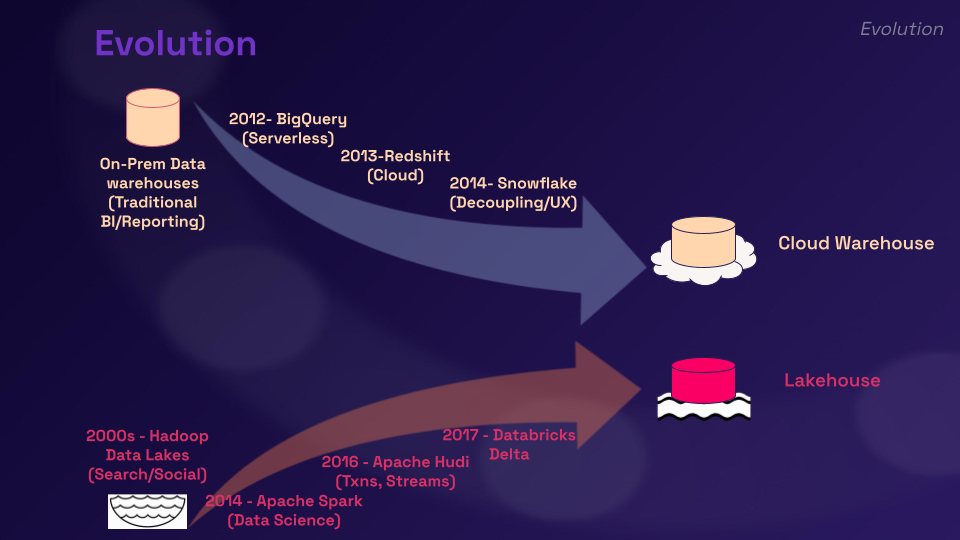
在我看来 Redshift 确实使云仓库成为主流,因为云而获得了很大的发展势头。当然 Snowflake 以分离存储和计算而闻名并且具有出色的可用性,因此今天云仓储非常成熟,它们为分析需求提供了稳定的资源。
如果看一下另一个弧线,数据湖实际上最初是一种架构模式,而不是可以下载和使用的有形软件,就像RDBMS或数据仓库一样。数据湖从支持搜索和社交开始:大规模数据用例。
我曾经在LinkedIn工作,当时我们使用所有这些方法来处理大量数据并构建数据驱动的产品。Spark 不断发展壮大彻底改变了数据处理方式。云增长 – 对于许多工作负载,云存储无处不在。数据湖逐渐成为云存储之上的文件的代名词。
在 2016 年的 Uber 我们试图构建一个教科书式的数据架构:一个数据湖架构,我们可以从数据库中获取运营数据,并将一些外部资源流式传输到原始层,然后能够进行任何类型的 ETL 或后处理,并从中派生出更多数据集。
需要的事务处理核心能力在数据湖上缺失
我们发现构建这种教科书式的架构几乎是不可能的,因为数据湖上缺乏我们需要的核心功能,例如事务,Hudi项目就是在这样的背景下诞生的。
我们添加了更新、删除、事务;我们甚至在数据湖之上添加了数据库 CDC 样式的变更流,这就是我们所说的事务性数据湖。

湖仓一体现已在技术上得到验证,包括以下公司用例:
技术基础 - 湖仓一体技术在现有数据湖之上添加的内容已经得到了充分的证明。因此只要通过这个镜头来观察 Apache Hudi 社区就可以看到这些是日常的服务,在这里可以看到大型企业,如果你把它们加在一起会看到EB级别数据是使用Apache Hudi等湖仓一体技术管理的。
使用 Apache Hudi 等湖仓一体技术管理 EB 级别数据
作为一个从观察数据库大战开始职业生涯的人发现一些有趣的头条新闻:
- Databricks 创下官方数据仓库性能记录
- Snowflake 声称与 Databricks 具有相似的性价比,但没有那么快! - databricks
- 行业标杆和诚信竞争 - Snowflake
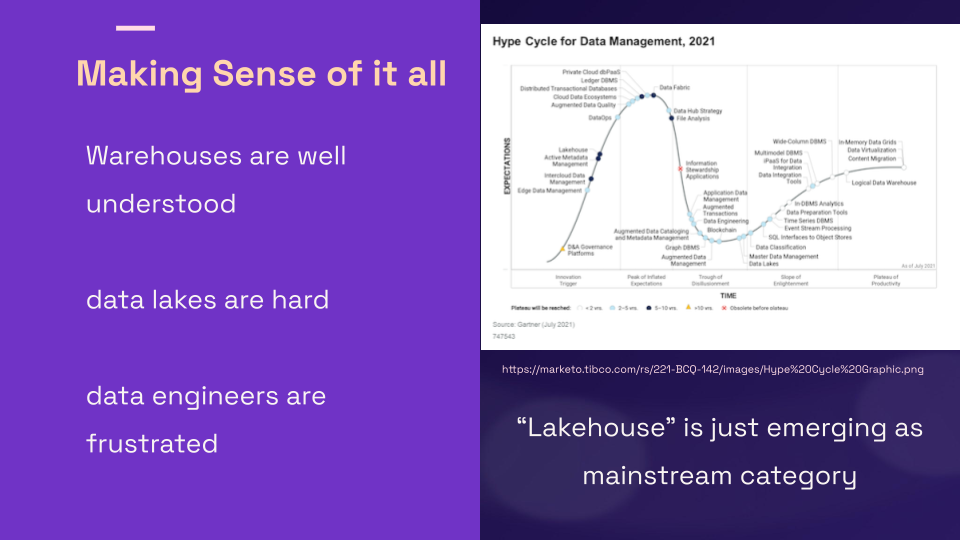
如何理解这一切?数据仓库已经非常容易理解也已经很成熟了。而从2018年到2020年,数据湖一直处于低谷。
而围绕数据工程有很多挫败感,那里有太多的移动部件。湖仓一体是一个新兴的类别,它可以通过添加我所描述的一些核心缺失功能来挽回数据湖。
但我们需要谨慎,因为这不是我们第一次看到解决所有问题的灵丹妙药,不幸的是经历了Hadoop时代的承诺(Hadoop企业数据仓库将接管数据仓库)。
对我来说它有点超前于时代,重点不再是解决核心用户问题。在我看来像Hudi这样的东西应该早写五年。因此我们需要以谨慎乐观的态度对待这个问题。
因此我将分享我对当今情况的诚实评估以及如何看待演变。我们将涵盖三个方面:
- 体系结构设计注意事项。主要工作负载是什么?我们还将讨论开放性,因为每当谈论架构时,都会经常提到这一点。
- 核心技术能力。这些东西的平台化程度如何;管理层是什么样的?应该在团队建设中规划多少基础设施,而已经内置了多少基础设施?需要多大的灵活性,而解决方案中有多少是预构建的?诸如此类的事情。如今在DevOps和运营精益数据组织方面,这一点非常重要。
- 成本/性能杠杆。有各种各样的工作负载,工作负载的类型、设计选择以及它们在所有栈上的位置。
比较数据仓库和数据湖仓一体:体系结构
让我们快速了解一下基础知识,首先是:什么是本地仓库?

有一堆有强大的磁盘和CPU的节点,运行SQL,它在节点上运行并访问本地数据;它只是一个集群数据库架构。同样很难真正描绘封闭系统的架构 - 但我认为从高层次上讲,它们看起来像这样,另一方面拥有可无限扩展的云存储。
本地仓库的问题在于存储和计算是耦合的,因此无法独立扩展它们。但是在云仓库模型中他们很好地解决了这个问题 - 可以在云存储上存储任意数量的数据,随后可以启动按需计算。
这些是托管服务、平台服务,例如优化查询、事务管理、元数据,这些有助于服务更具弹性,可以做很多全局最优的处理,可能正在同一张表上启动虚拟仓库,并且可以通过这种方式进行大量交叉优化。这就是我们所看到的架构。

有趣的是传统的数据湖总是有存储和计算分离的。从字面上看他们就是这样出生的,但传统的数据湖上有很多文件,然后就混合了 JSON 和其他任何东西。有 SQL 引擎 - 本质上是一堆可以在它们之上执行 SQL 的节点 - 并且根据使用的引擎和供应商可能有缓存。
对于湖仓一体,我们真正做的是在中间插入一个层并跟踪更多元数据。然后会看到它变得更加结构化。现在LakeHouse中的世界更加结构化。
可以看到这些架构是如何相互接近的
从本质上讲,我们添加了一个事务管理层,一堆可以优化表的东西,类似于在仓库中找到的东西,比如对表进行聚簇,架构管理或统计信息,只是跟踪表的更具可扩展性的文件级统计信息,架构的其余部分几乎相同。可以从云仓库模型和湖仓一体模型中了解体系结构如何相互接近。
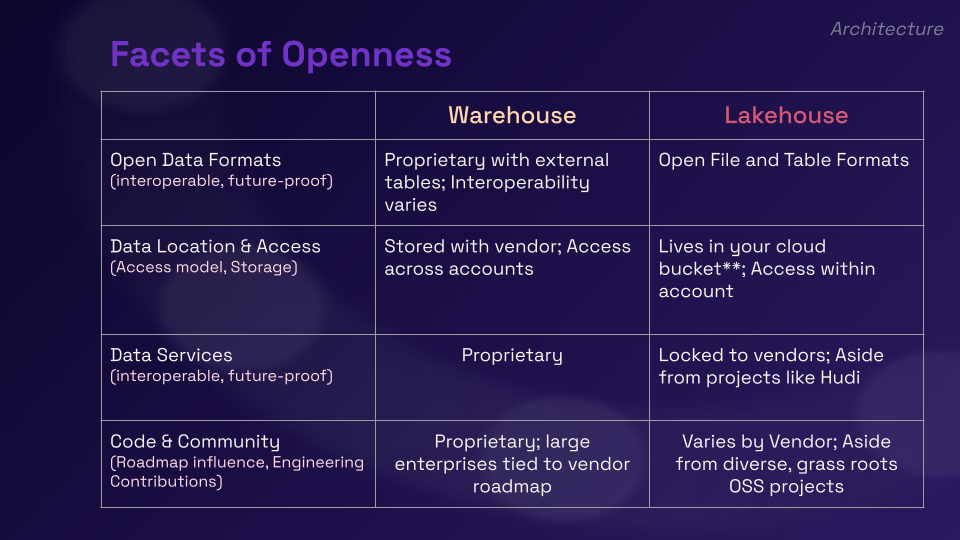
开放性是一个很大的话题 - 它并不止于开放数据格式,远远超出了架构。因此开放数据格式当然是可互操作且面向未来的,但是数据仓库或多或少使用专有数据格式。
互操作性是另一回事,如果解决方案真的很受欢迎,那么很多工具都会集成,但是对于开放的文件和表格格式真正得到的是:生态系统可以自行发展。不必依赖供应商添加对 X、Y、Z 格式的支持。这就是拥有开放数据格式的关键力量。
不需要供应商增加对 X、Y、Z 格式的支持
数据位置和访问实际上因供应商而异,甚至在仓库之间也是如此。在某些情况下将数据存储在仓储供应商处,在某些方面它就像云提供商/运营商仓库,所以它各不相同。数据湖主要将数据存储在自己的存储桶中,但需要注意一些注意事项 - 如何在存储桶上设置权限,以便可以保持已写入对象的所有者。
数据服务是关键差异所在
数据服务是主要区别所在,在仓库中维护或管理表的大多数东西都是专有的。即使在湖上也有一种模式可以保留开放数据格式,但将其他所有内容锁定到供应商运行时,这是我们在 Hudi 项目上做得更好的地方,在那里可以获得摄取服务、表优化能力——所有这些服务都是开源的。至少在我们看来这种组合锁定了开放性,因为这样一来格式就是一种被动的东西。问题是你用它做什么?
那么在代码和社区方面,你能影响这个项目吗?即使有一个团队,大型企业也要与供应商的路线图联系在一起。即使在数据湖上也因项目而异,无论是草根开源项目还是由一家公司驱动的供应商。
关于数据网格:很多人告诉我,“我正在构建一个网格,而不是一个数据湖”。这是一个非常正交的概念。如果你还记得我说过数据湖是一个架构概念。它主要讨论如何组织数据,而不是数据基础架构。如果你看一下关于这个主题的介绍性文章,它主张将数据基础设施标准化作为我们如何实现数据网格的关键点。

总结一下我们的架构讨论:我今天看到的是数据仓库实际上是为商业智能 (BI) 而构建,其中的问题在于扫描尽可能少的数据量。那是因为他们有高性能的元数据管理,长时间运行的服务器。通常数据仓库旨在更好地支持这些更具交互性的工作负载。
如果看一下数据湖就会发现这些湖支持可扩展的 AI。这真正意味着它们是经过扫描优化的,他们可以扫描大量数据,因为它们都在云存储上——也就是说没有中间服务器,所以它们可以直接访问云存储。开放格式意味着我们刚才在主题演讲中谈到的那种生态系统,这些生态系统可以发展得更快,因为可以出现更小的项目,它们可以建立在这些数据之上,而且很容易做到,作为一个社区发展和迭代。
从某种意义上说 LakeHouse 试图将两者融合在一起,但挑战也存在,这些进步是必要的。如果在谷歌上搜索任何“数据湖与数据仓库”的比较,它会告诉你区别在于非结构化数据与结构化数据——但湖仓一体仍然主要处理结构化数据,还有很多标准化的数据管理工作要做,这些都是需要解决的挑战。