-
pytorch-激活函数与GPU加速
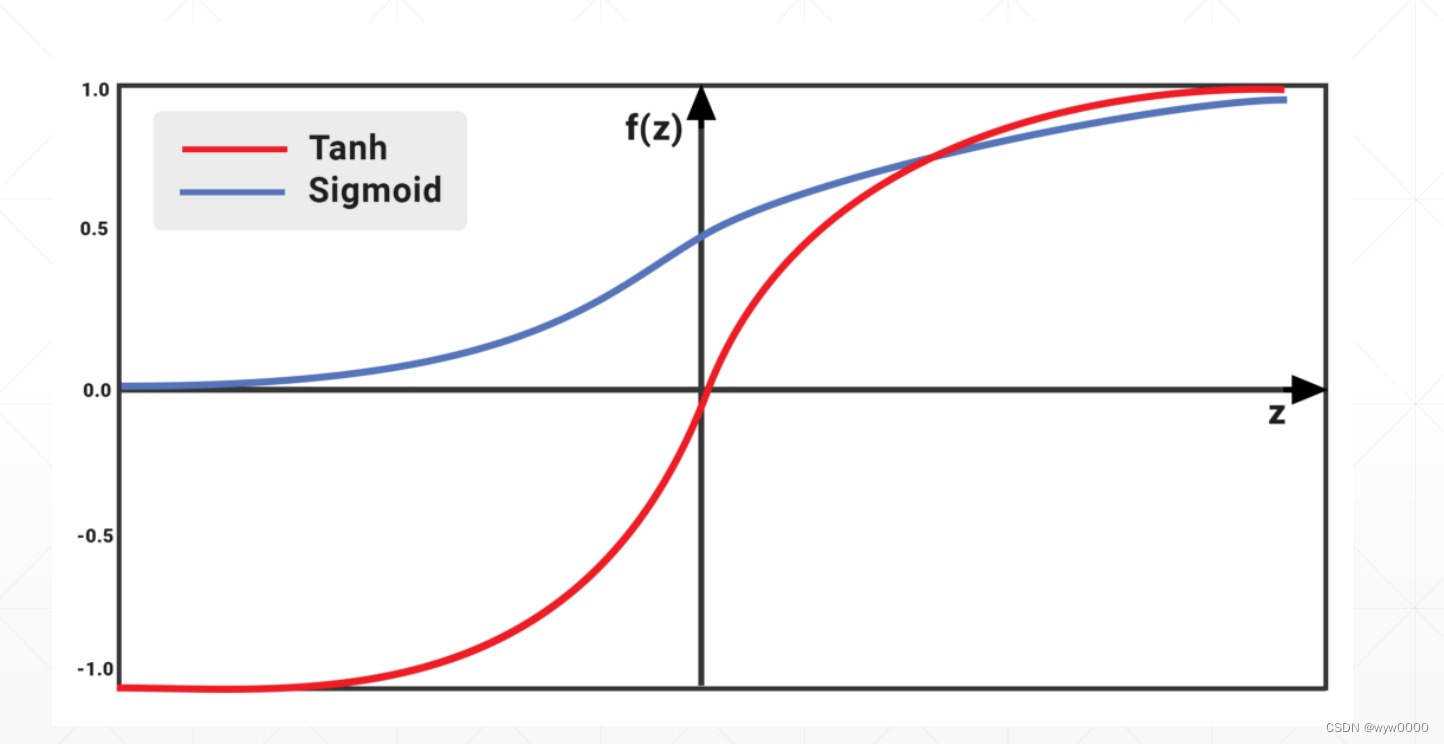
1. sigmod和tanh
sigmod梯度区间是0~1,当梯度趋近0或者1时会出现梯度弥散的问题。
tanh区间时-1~1,是sigmod经过平移和缩放而得到的,也存在梯度弥散的问题。
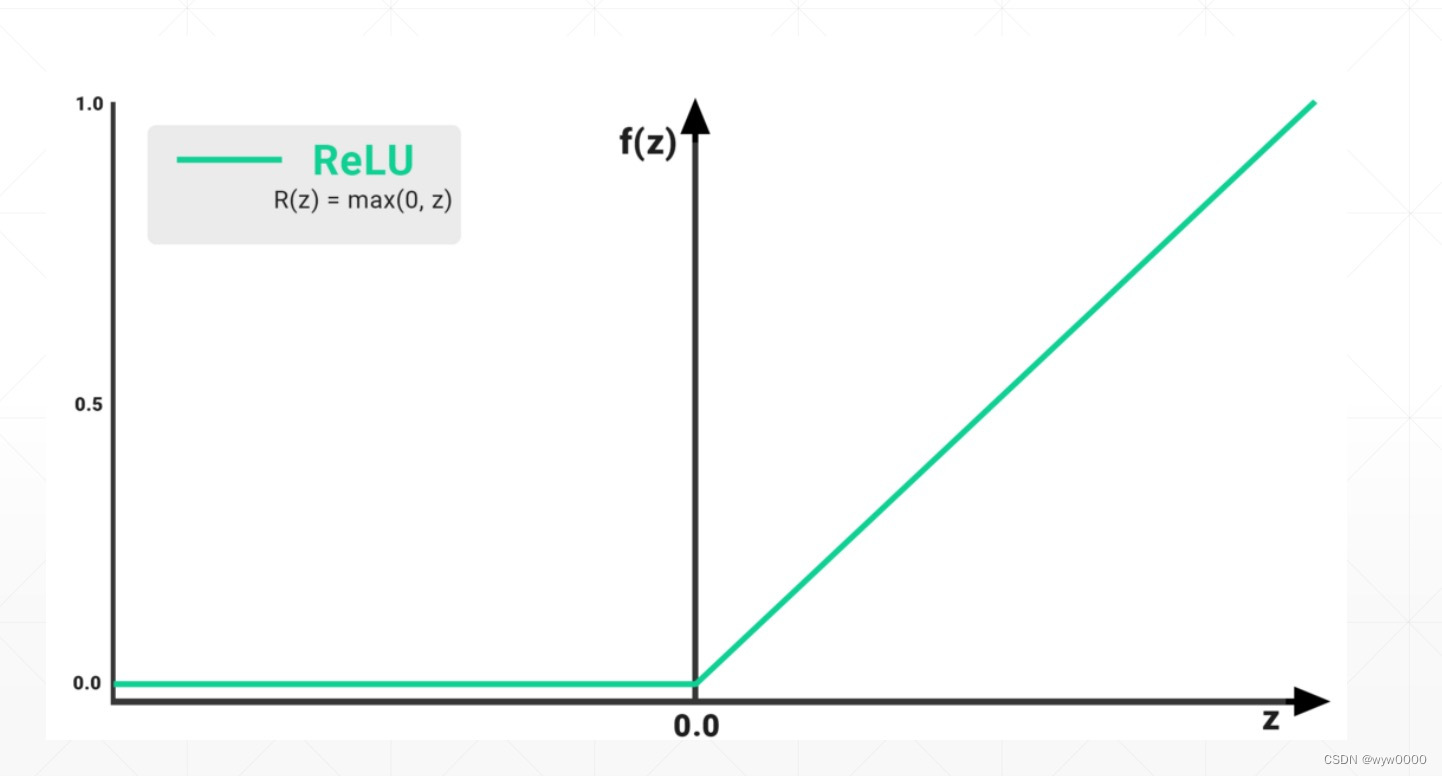
2. relu
relu函数当梯度<0时,梯度是0,梯度>0时梯度是1,不会出现梯度弥散和梯度爆炸,虽然relu函数使用广泛也不易出现梯度弥散和梯度爆炸,但是不代表它不会出现。
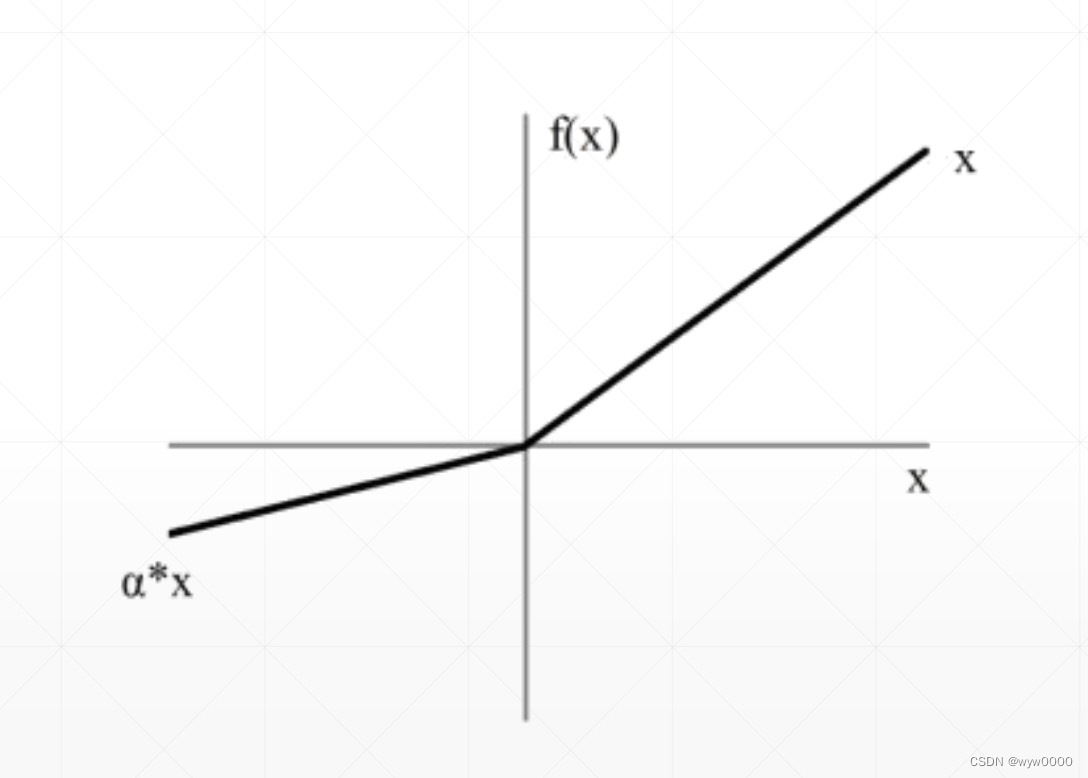
3. Leaky Relu
在梯度<0的时候,不在是等于0而是变成了a*x, a是一个比较小的系数,确保梯度小于0时不再是0
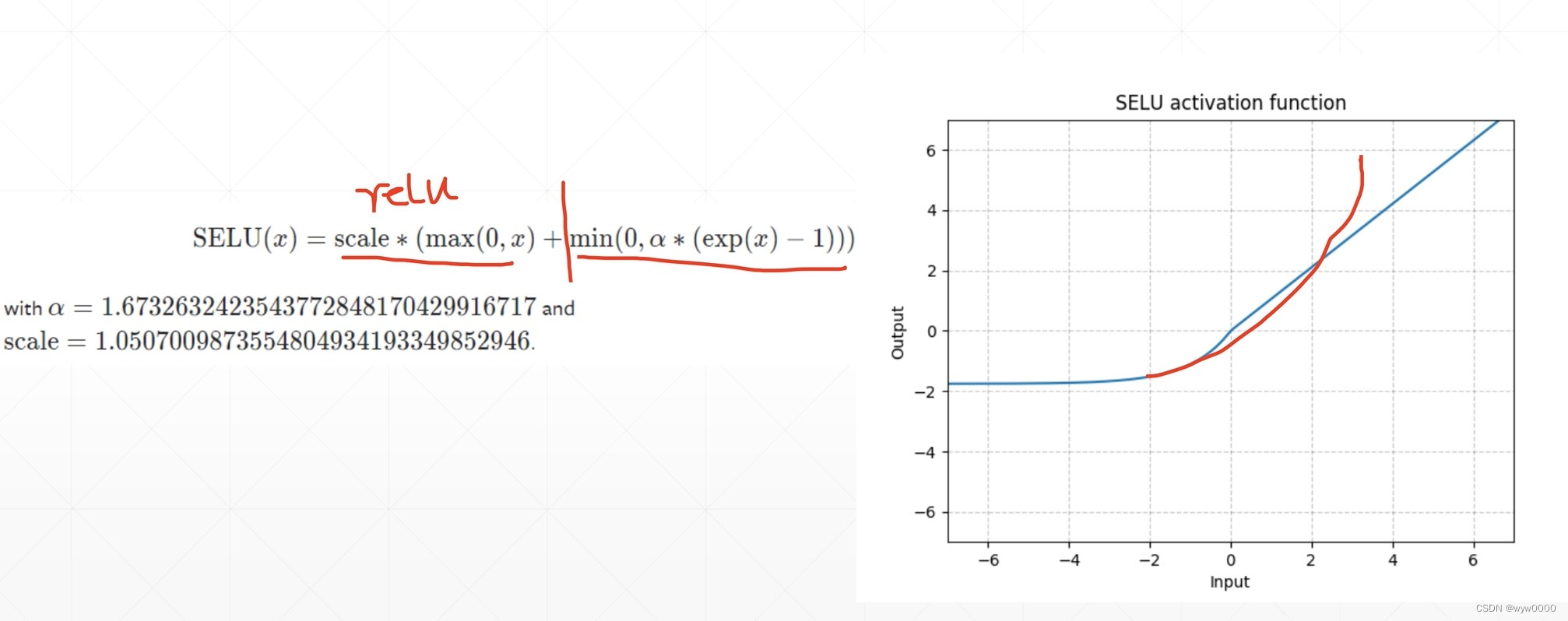
4. selu
由两部分组成一部分时Relu,另一部分是一个指数函数,从而使得selu在0点变成了连续的。
5. softplus
时relu的一个连续光滑的版本,在0处变得光滑而连续
总结:目前用的最大的sigmod、tanh、relu、leakyrelu,其他两种用的较少6. GPU加速
torch.device(‘cuda:0’)中的cuda:0代表第几块显卡,如果使用CPU那么就是torch.device(‘cpu’)
使用.to(device)就把模块或者数据搬到了GPU上,然而模块和数据是有一些区别的,模块执行.to(device)返回一个reference和不使用初始化是完全一样的属于一个inplace操作,但是data就不一样了,比如:data2=data.to(device),data2和data是完全不一样的,data2是gpu数据,data是cpu数据。
注意:.cuda()方法已经不推荐使用了

7. 使用GPU加速手写数据训练
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms batch_size=200 learning_rate=0.01 epochs=10 train_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( nn.Linear(784, 200), nn.LeakyReLU(inplace=True), nn.Linear(200, 200), nn.LeakyReLU(inplace=True), nn.Linear(200, 10), nn.LeakyReLU(inplace=True), ) def forward(self, x): x = self.model(x) return x device = torch.device('cuda:0') net = MLP().to(device) optimizer = optim.SGD(net.parameters(), lr=learning_rate) criteon = nn.CrossEntropyLoss().to(device) for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28*28) data, target = data.to(device), target.cuda() logits = net(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() # print(w1.grad.norm(), w2.grad.norm()) optimizer.step() if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in test_loader: data = data.view(-1, 28 * 28) data, target = data.to(device), target.cuda() logits = net(data) test_loss += criteon(logits, target).item() pred = logits.data.max(1)[1] correct += pred.eq(target.data).sum() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
从代码中可以看到网络、loss函数和数据都搬到了GPU上,激活函数改成了LeakyRelu
-
相关阅读:
001计算机网络基础习题+答案+解析
python 无监督生成模型
通过构造函数中设置_前端培训
第十八章:Swing自述
VUE el-select Select 选择器 选项是对象,显示是一个值name ,但是绑定的对象值是id方案
【Flutter】FlutterChannel详解
【Java初阶】Array详解
Spring Boot基础面试问题(一)
【Jetson】Jetson TX2 ubuntu18.04从0安装 jupyterLab
useGeneratedKeys=“true“ keyProperty=“id“
- 原文地址:https://blog.csdn.net/wyw0000/article/details/137988031
