-
第3.1章:StarRocks数据导入——Insert into 同步模式
一、概述
在StarRocks中,insert的语法和mysql等数据库的语法类似,并且每次insert into操作都是一次完整的导入事务。
主要的 insertInto 命令包含以下两种:
- insert into tbl select ...
- insert into tbl (col1, col2, ...) values (1, 2, ...), (1,3, ...);
其中第二种命令仅用于demo,不要使用在测试或生产环境中。在StarRocks中,例如使用JDBC或者insertInto导入时,插入1000条左右时很快有类似报错:close index channel failed,主要原因是导入太频繁了,需要降频率攒批导入。
二、高频insert 报错的原因
StarRocks中的数据组织图如下:
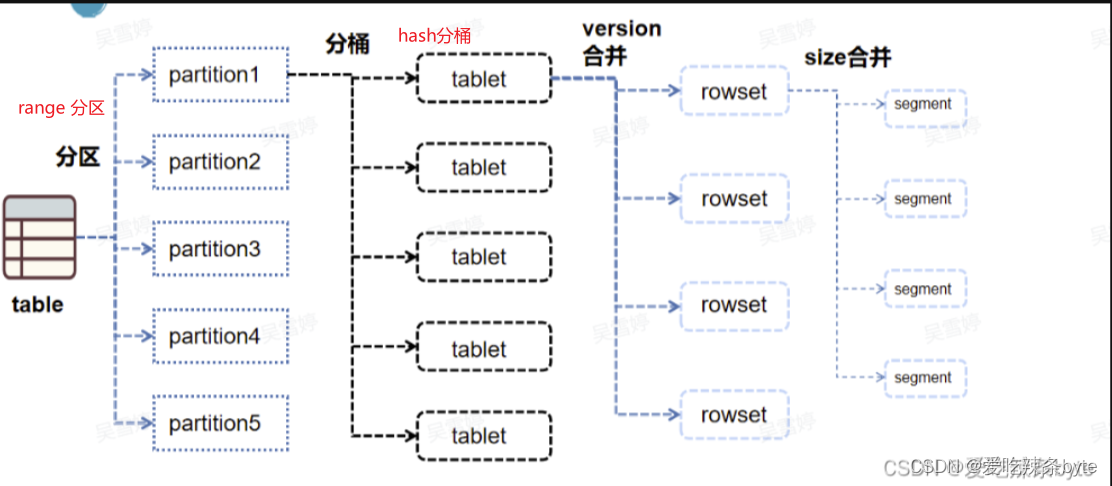

StarRocks中的分区分桶与tablet之间的关系为: table -- > partition --> tablet(物理描述,tablet数据分片是数据划分的最小逻辑单元)
分区是逻辑上的概念,只记录在表的元数据中,每个分区的数据会按照分桶键进行hash分桶,表中的数据经过分区分桶后,就会形成一个个的tablet,且尽量均匀分布在集群的各个BE中。 tablet是StarRocks中数据均衡的最小单位,默认的三副本是指同一个 tablet会在集群中保留三份,每个tablet之间的数据没有交集,在物理上独立存储。集群的副本修复或磁盘均衡,均是以tablet为单位移动或者克隆的。且每次的数据导入、更新或者删除,本质上也是对一个个tablet中的数据进行操作。
StarRocks中的分区分桶见:
一个tablet中包含若干连续的rowset(rowset是逻辑概念),rowset代表tablet中一次数据变更的数据集合(数据变更包括了数据新增,更新或删除等),它是按版本信息进行记录的,每次变更就会生成一个新版本的rowset。一个rowset底层可能会包含多个segment,执行数据导入时,每成功写入一个segment就会增加一个文件块对应。
Segment的概念比较底层(这里不展开),可以借鉴Doris底层存储结构:
对上文提到的数据导入报错close index channel failed进一步解析。在StarRocks中,每次insert into本质都是一次完整的导入事务,即:insert into实际上会在tablet内部生成一个个连续版本号的rowset,对于新增的rowset,起始版本和终止版本是一样的,表示为[ 6-6]、[ 7-7]....[999-999]等。多个 rowset经过compaction会形成一个大的rowset。合并后的起始版本和终止版本是多个版本的并集,如[ 6-6]、[ 7-7]、[8-8]合并后变成 [6-8]。一旦表的某个tablet中同时存在rowset个数达到1000,就会到达阈值,即触发上述报错。
三、降低导入频率
单个tablet中的rowset版本个数过多会什么影响?主要影响两个方面,一个是内存的占用,当rowset的版本过多时,be节点的table_meta部分(主要是其中的rowset元数据部分)占用的内存可能非常多。同时compaction合并消耗内存也会比较大,容易引起oom,影响集群稳定性;二是查询会变慢,因为查询的过程中是需要对tablet中的数据进行解压的,当rowset版本很多,解压会变慢,导致查询scan的耗时增加。综上考虑,StarRocks设置了单表中每个tablet最大阈值为1000的限制。
针对insert into 数据频繁导入引发的rowset版本过多的问题,StarRocksc是利用compaction解决的。compaction可以认为是一个后台的常驻线程,不断的将tablet中的rowset版本进行合并,将小文件合并成有序的大文件。
StarRocks中的compaction操作,分为base compaction(BC) 和cumulative compaction
(CC)。其中cumulative compaction(简称CC)负责将多个最新导入的增量数据进行合并,当增量数据合并后的大小达到一定阈值后,base compaction(简称BC)将基线版本(起始版本start version为0的数据)和与该增量数据版本合并。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。
BC和CC之间的分界线是cumulative point (cp),它是一个动态变化的版本号,比cp小的数据版本只能触发BC,而比CP大的数据版本,只会触发CC。如下图:
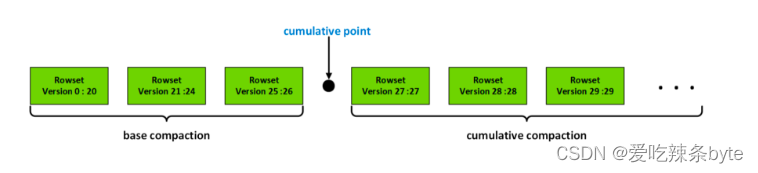
上述分析得出,在StarRocks集群运行时,对表的数据变更操作会不断地产生新版本rowset,后台的常驻线程compaction负责将tablet中的rowset版本进行合并,进而保证集群的整体稳定高效。
综上,快速insert into导致报错:close index channel failed的原因可以总结为:短时间内生成的rowset版本太快,如果compaction不及时,就会造成大量版本堆积,导致累计版本超过了超过了1000,进而触发阈值报错。故为了保障集群的稳定运行及查询效率,需要确保整体的compaction效率要大于rowset的生成速率。容易想到的解决思路一是:部分场景下通过调整compaction的几个参数来加速compaction,例如在be.conf中配置以下参数(配置后需重启BE):
- #==每个磁盘 Cumulative Compaction 线程的数目(默认是1)
- cumulative_compaction_num_threads_per_disk = 4
- #==每个磁盘 Base Compaction 线程的数目(默认是1)
- base_compaction_num_threads_per_disk = 2
- #==Cumulative Compaction 线程轮询的间隔(单位是秒,默认值是1)
- cumulative_compaction_check_interval_seconds = 2
弊端是:compaction任务本身比较耗费cpu,内存和磁盘IO资源,compaction开启的过多会占用过多的机器资源,也会影响查询性能,还可能会造成OOM。上述报错还是需要从数据导入频率这个入手。
理论上,每次导入操作,不论是只导入一条还是十万、百万条,对于StarRocks来说,都是只生成一个新的roswet版本。那么在compaction效率有限的情况下,完全可以通过“攒微批+降频率”来规避roswet版本过多的问题。实际上,若业务实时性要求不高,在机器内存充足的情况下,攒批越大、导入频率越低,对StarRocks集群的稳定性及查询性能的影响就越小。
ps:在StarRocks中有更快的攒批导入方式,即Stream Load
compaction合并机制见文章:
四、insert替代用法
可以概括总结为以下几点:
- 高频率小数据:insert into或者JDBC的executeUpdate()方法就完全不要用;
- 低频率小数据:insert into导入几条测试数据可以用,但注意频率;
- 低频率较大数据:insert into tbl values(data1),(data2)……或者类似JDBC executeBatch()方法,可以用,但不推荐,因为有更快的实现方式;
- StarRocks系统内部进行ETL,推荐使用 insert into select 语法;
- 便捷导入其他系统的数据,推荐使用外部表,例如:先构建mysql外部表去映射mysql系统中的数据,通过 insert into select 语法将外部表中的数据导入到 StarRocks表中。
五、insert使用与调优
5.1严格模式
insert into是一种同步的导入方式,导入成功会直接显示导入结果。如果导入失败,insert也会返回错误信息,例如我们导入错误时间格式的数据(数据漏加引号):

(1)针对tracking_url,使用web或者curl命令访问tracking_url,可以查看更详细的错误信息:显示报错原因是:格式不对,强转为null引起的问题,接着可以去排查数据格式。

(2)严格模式enable_insert_strict:当该参数为false时(关闭严格模式),表示一次insert任务只要有一条或以上数据被正确导入,就返回成功。当该参数设置为true时,表示但凡有一条数据错误,则任务整体失败,该参数默认为true。例如:set global enable_insert_strict = false;
ps:当关闭严格模式后,insert即使有错误数据,但只要有一条数据是正常可用的,就会忽视脏数据,保证可用数据的正常导入。此外,enable_insert_strict参数是session参数(当前会话生效),断开当前session后,该参数就会失效,若需要全局修改,可以加上global。
5.2并行度
insert导入语句本质上还是sql,可以通过设置合适的并行度来进行加速。例如可以设置全局并行度为单个BE节点的cpu核数的一半。假设部署的BE服务器core数是16C,那set global parallel_fragment_exec_instance_num = 8。注意:有些场景下,例如:insert into select语句进行StarRocks系统内部的ETL或者通过外部表来拉取数据,当速度过快。一方面可能导致源库压力过大影响源库中的业务,另一方面会导致StarRocks BE的load内存和ColumnPool内存占用较高,影响集群稳定性。所以需要结合实际情况,来设置合适的并行度控制导入速率
5.3超时时间
与insert相关的超时参数有两个:
- query_timeout
可以通过show variables like '%query_timeout%' 语句查看, 该参数是session变量,通过增加global关键词设置全局生效。可以通过set query_timeout = xxx 来增加超时时间,单位是秒(默认为300秒)
- insert_load_default_timeout_second
该参数是fe.conf中的参数,表示导入任务的超时时间(以秒为单位,默认是3600秒,即1小时)。如果导入任务在设定的超时时间内未完成则会被系统取消,变成cancelled。
参考文章:
第3.1章:StarRocks数据导入--Insert into_starrocks insert into-CSDN博客
-
相关阅读:
数据仓库(7)数仓规范设计
蓝桥杯 奇偶覆盖 模拟
《MySQL高级篇》十六、主从复制
FlinkCDC基础篇章1-安装使用
【小程序】集成echarts问题记录
3.1依赖注入
等保测评 —— 安全控制点
后端程序员对于 Docker 要掌握多少才行?我的答案是
【ZeloEngine】OpenGL升级Vulkan
About Significance Tests
- 原文地址:https://blog.csdn.net/SHWAITME/article/details/136158133