-
MYSQL数据库学习
从现在开始我是一个MYSQL学习者,接下来的日子我将用几天的时间学习MYSQL数据库的用法,本文章持续更新
ps
基础阶段
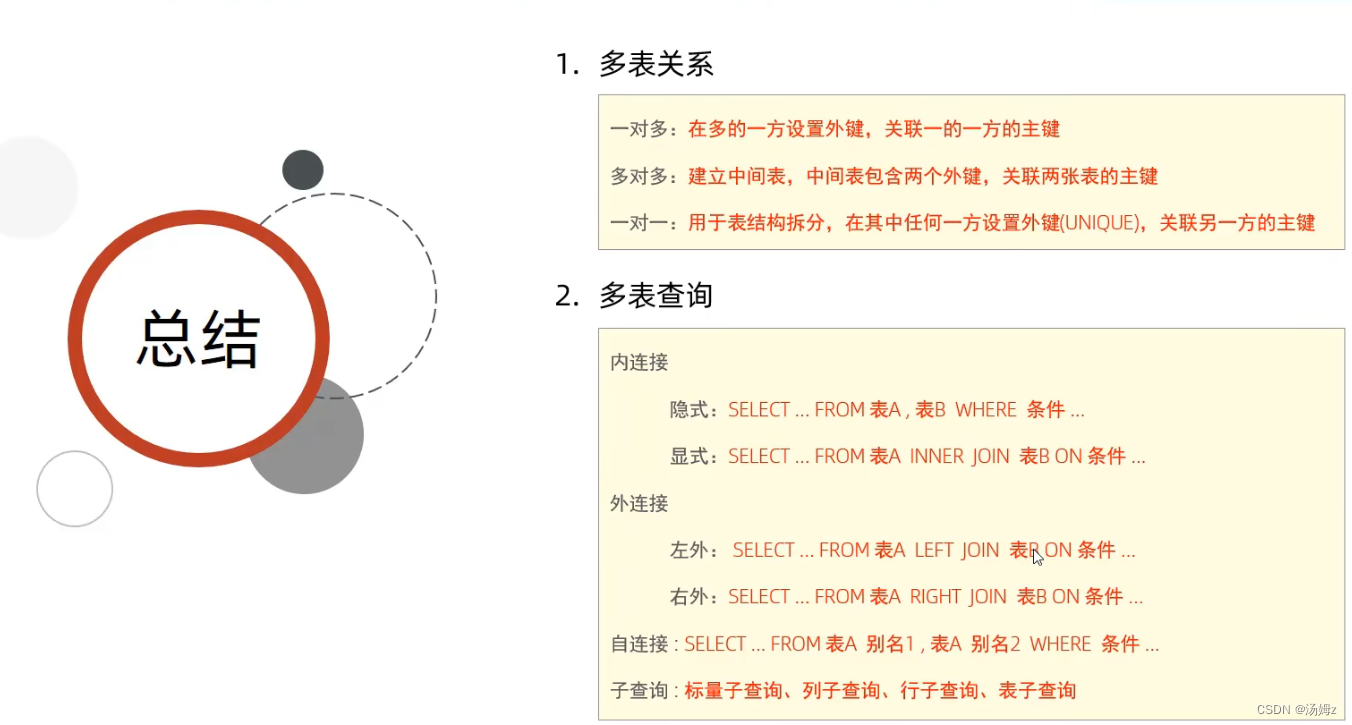
基本概念
数据库:存储数据的仓库
数据库管理系统:操纵和管理数据库的大型软件
SQL:操纵关系型数据库的编程语言,是一种标准 ps:一句话通过表来存储数据的就是关系型数据库
ps:一句话通过表来存储数据的就是关系型数据库
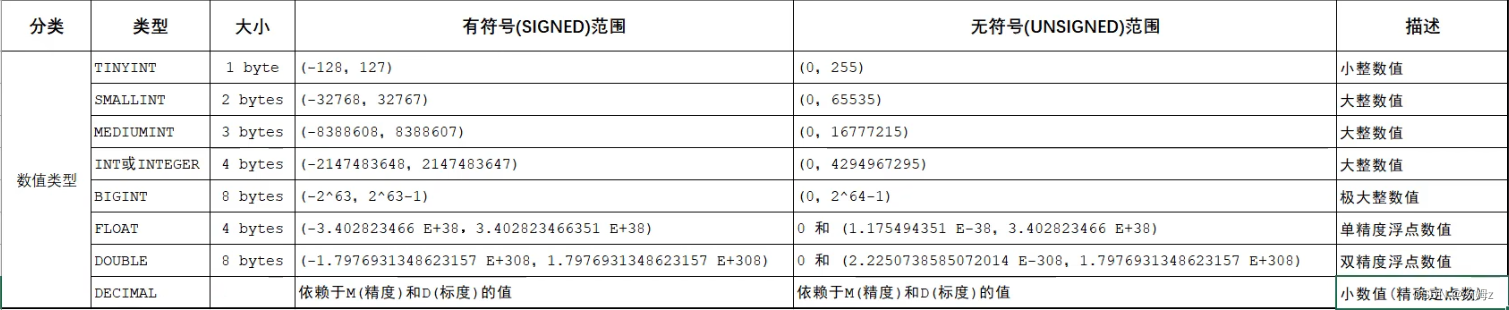


基本操作
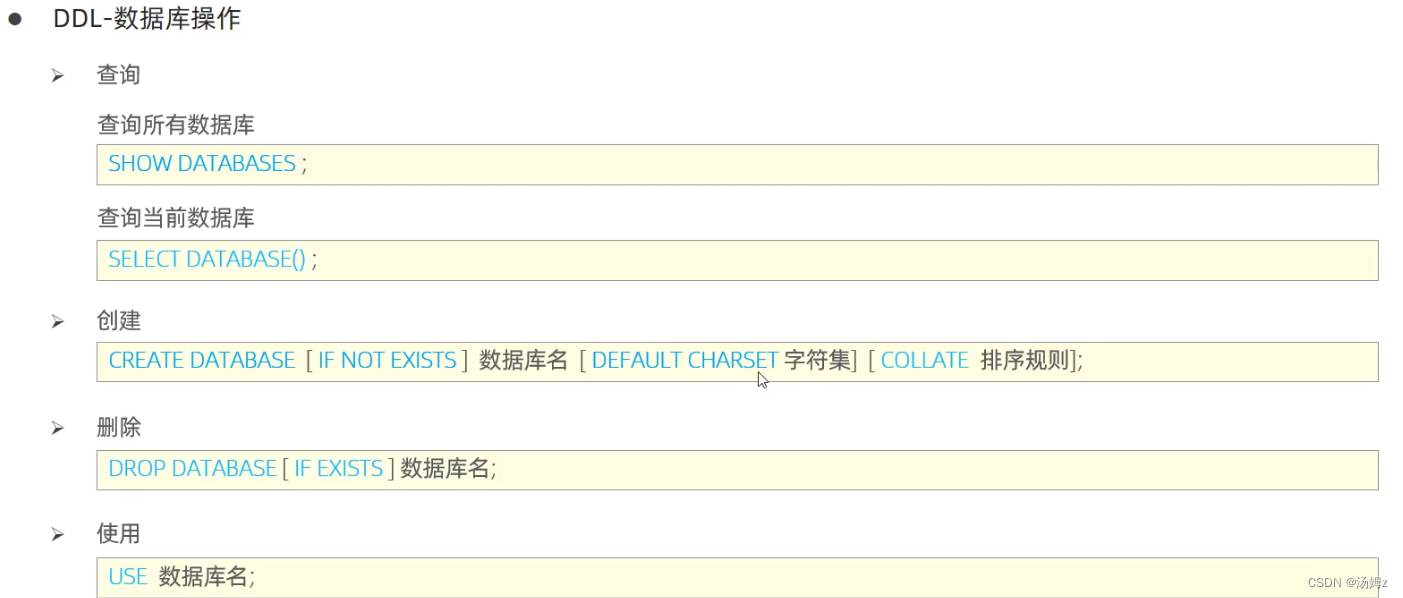
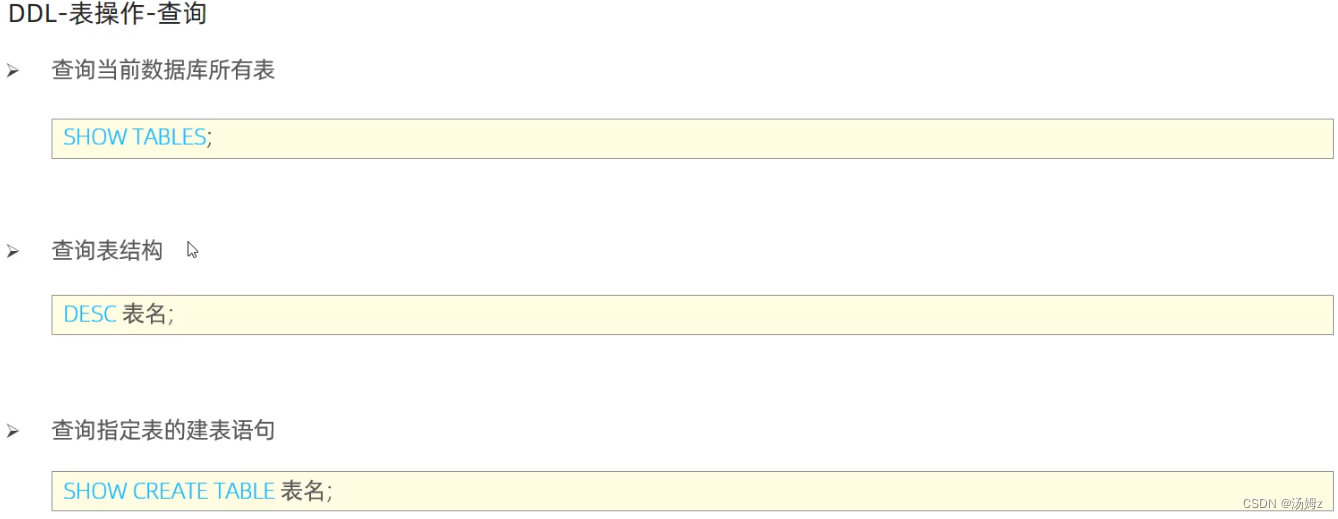
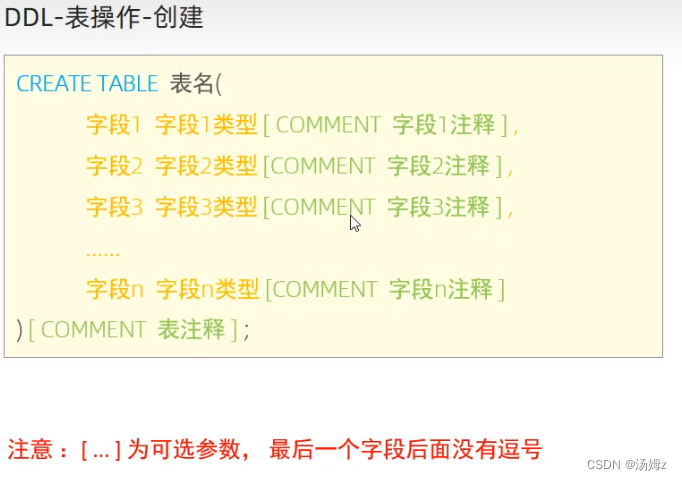
 ps:定操查控
ps:定操查控






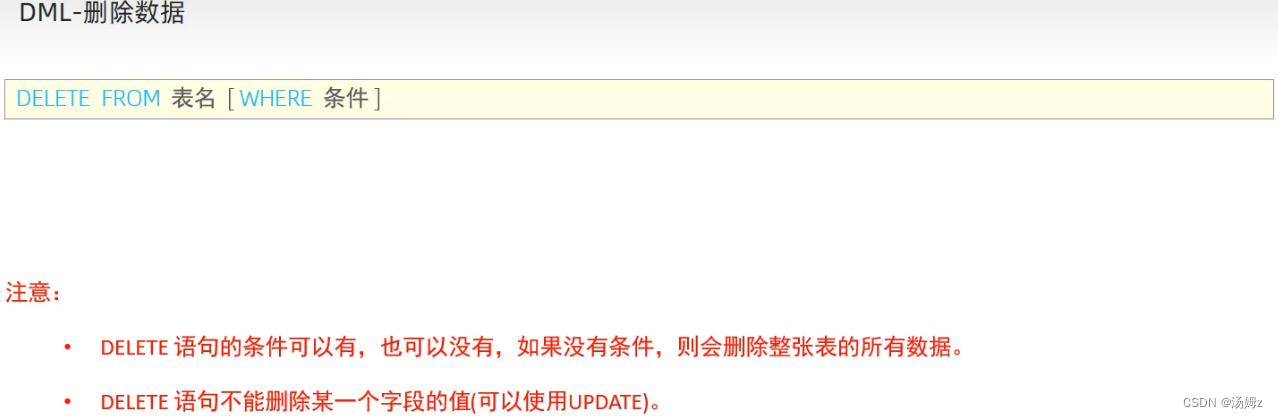



 ps:所有的null值不参与运算
ps:所有的null值不参与运算
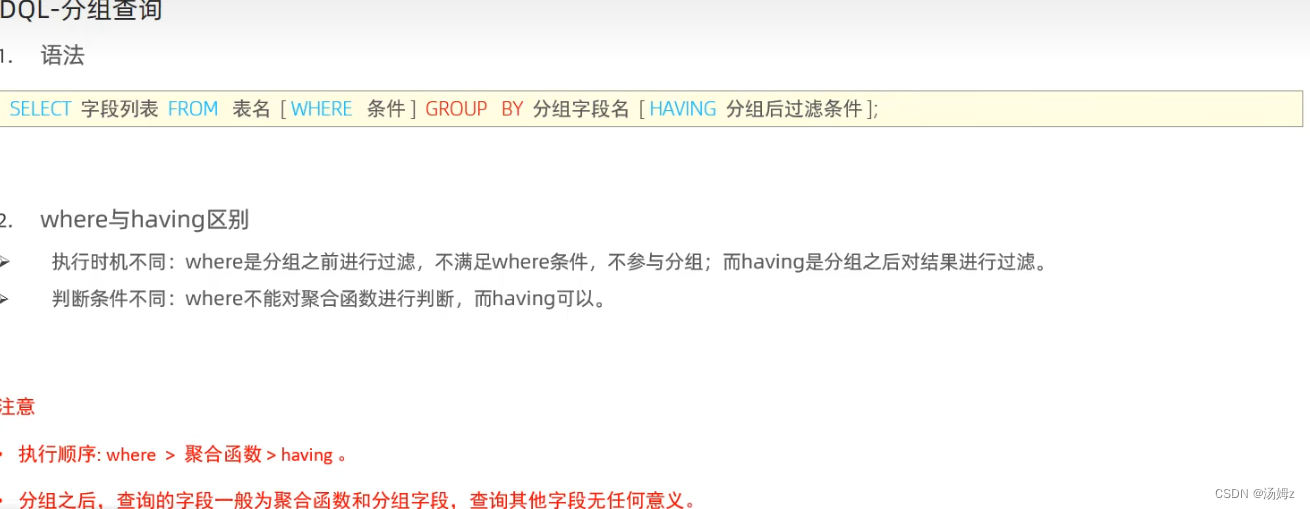


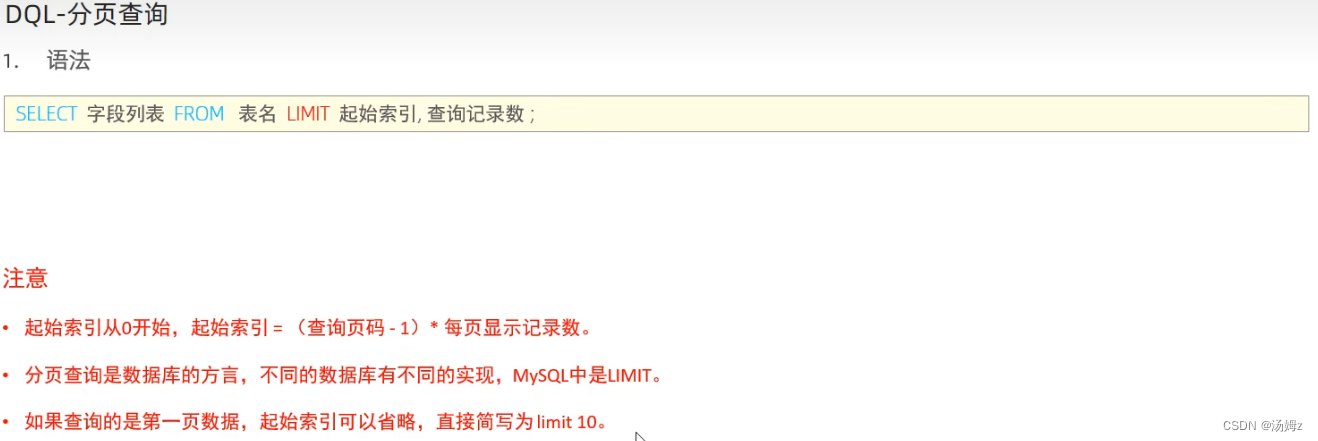 ps:如查询前五个人员,那么就是分页,limit永远放语句的最后
ps:如查询前五个人员,那么就是分页,limit永远放语句的最后
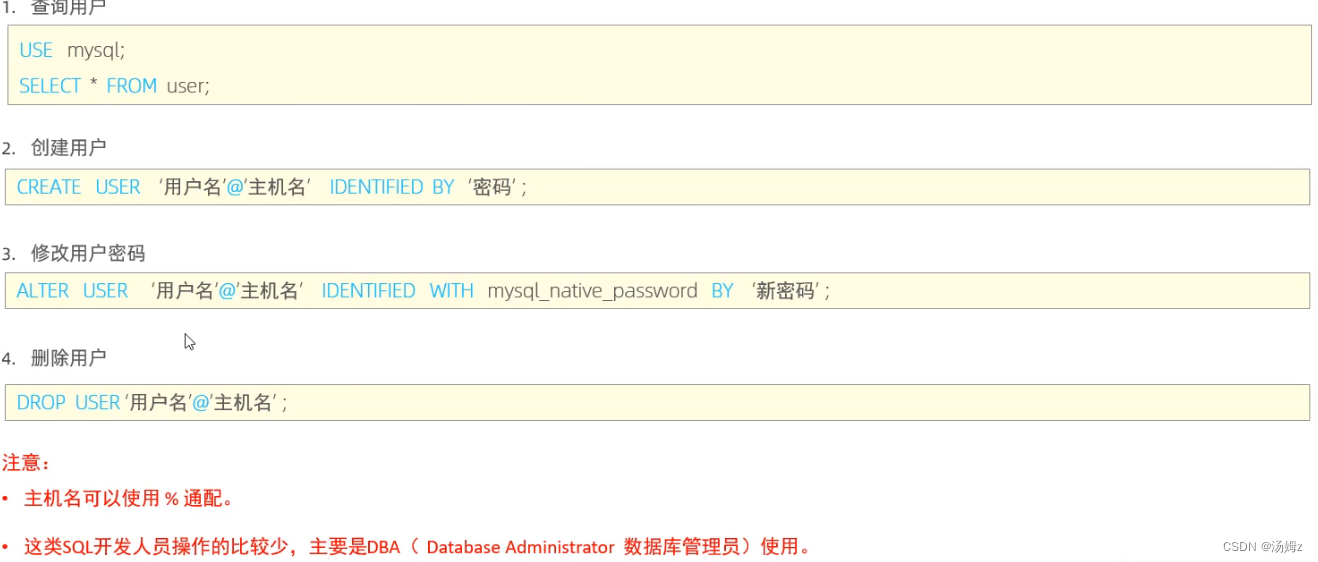
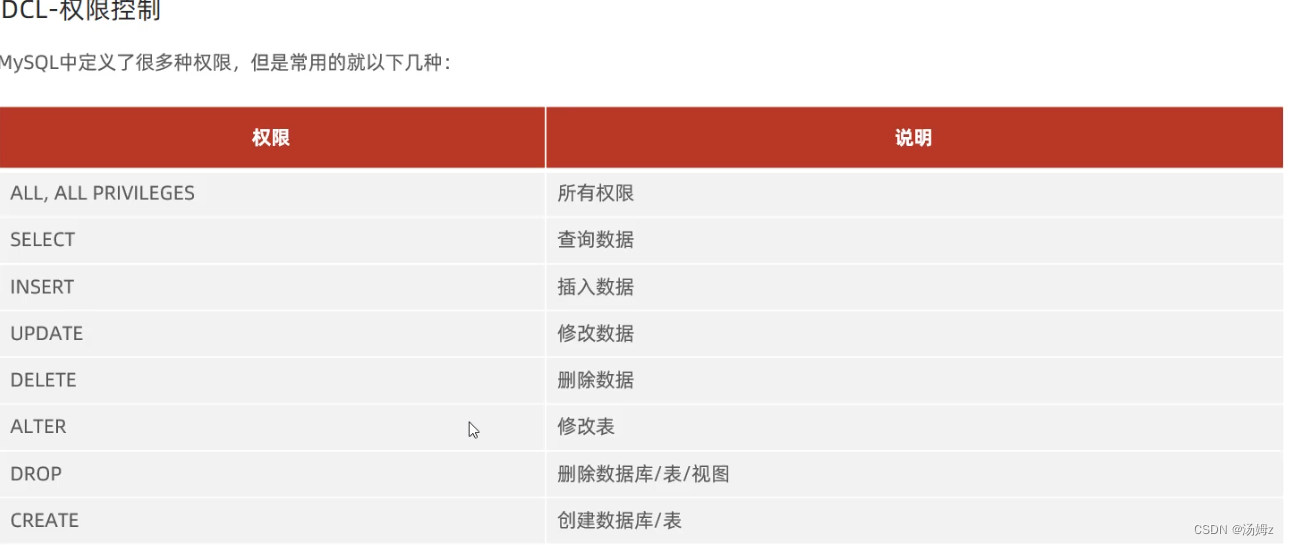

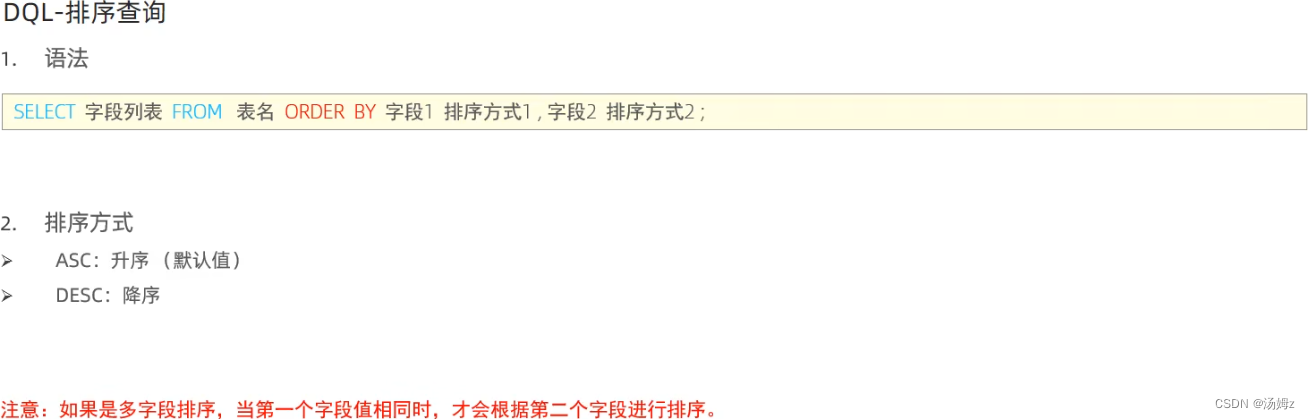
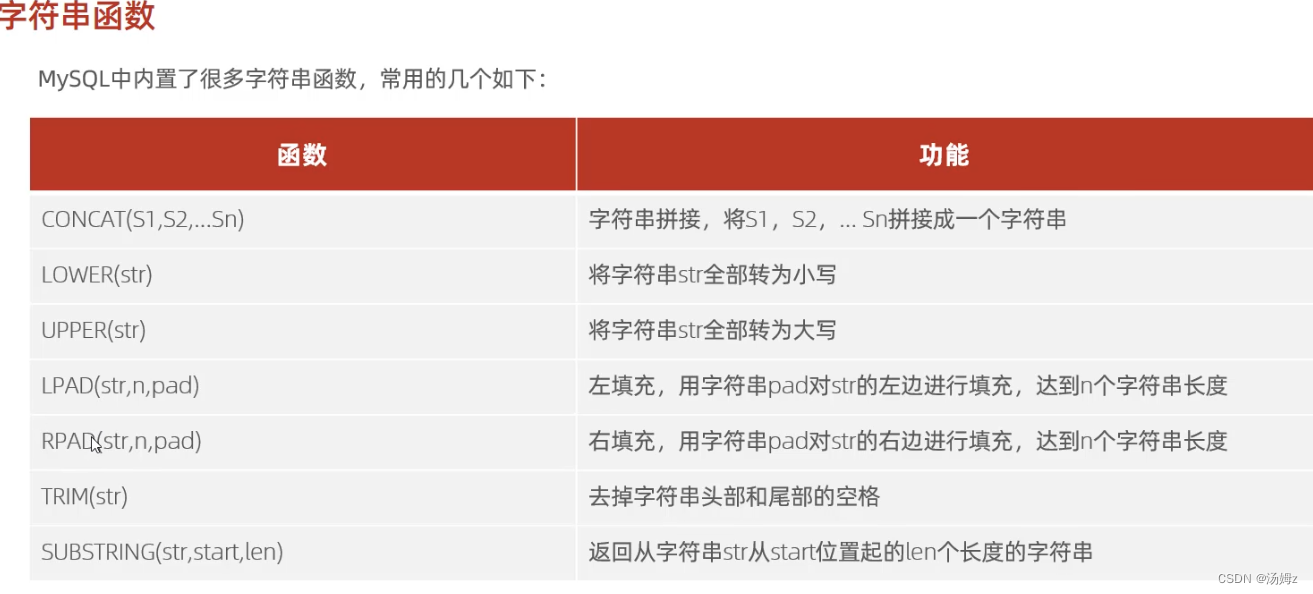 ps:select 函数(参数)
ps:select 函数(参数)

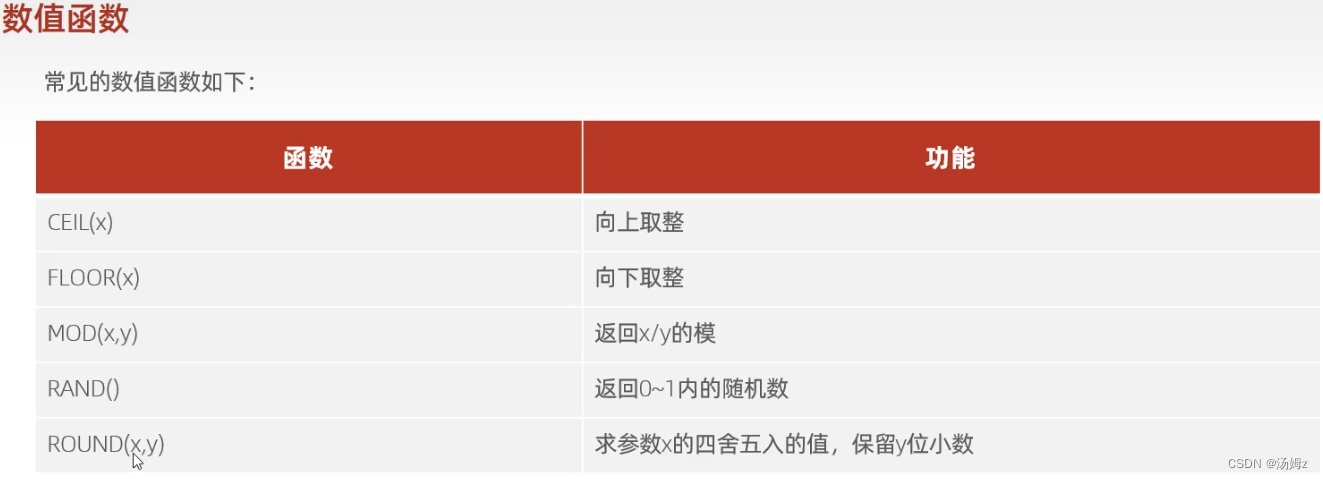

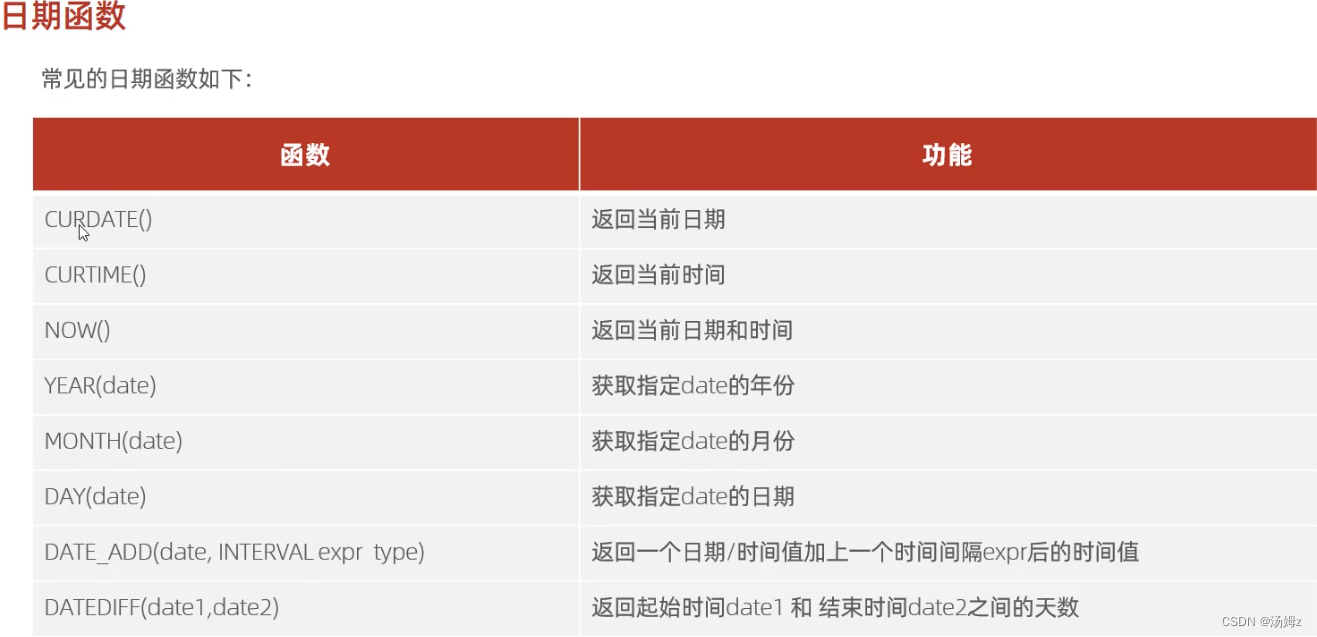



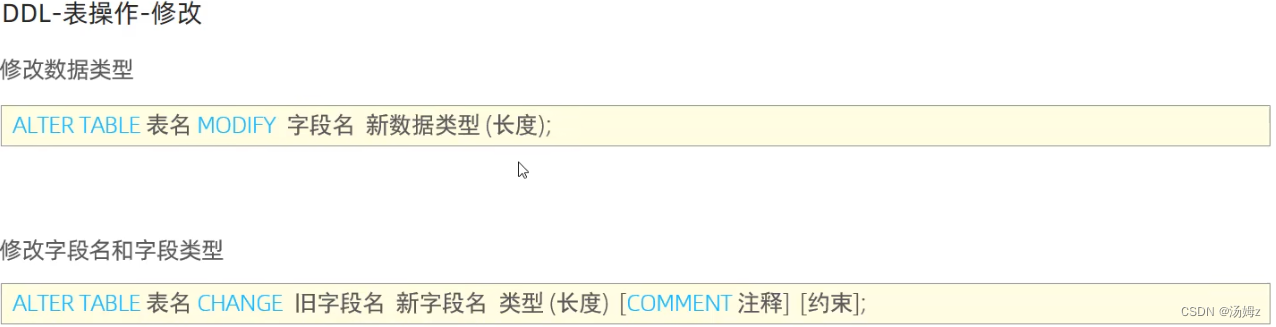
约束
 ps:约束是作用于表中字段上的,可以在创建,修改表时添加约束
ps:约束是作用于表中字段上的,可以在创建,修改表时添加约束

ps:黄主蓝外,外键保证数据的一致性和完整性

多表查询
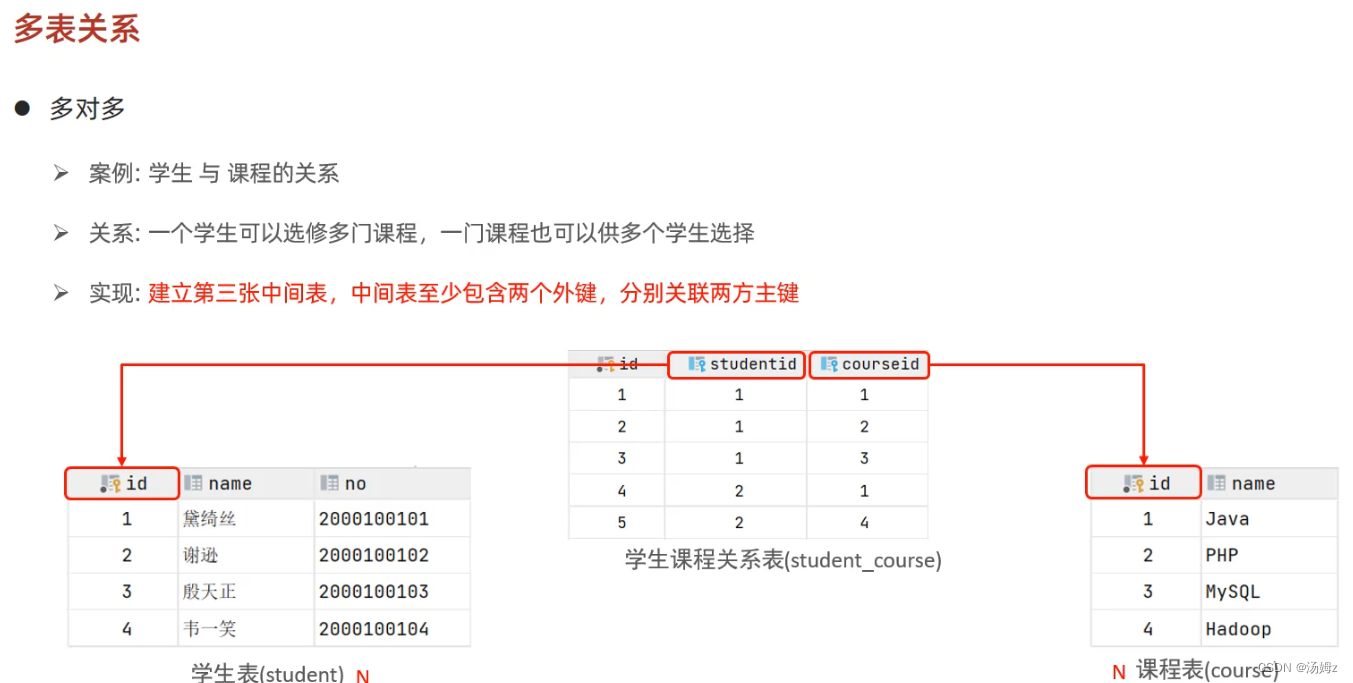
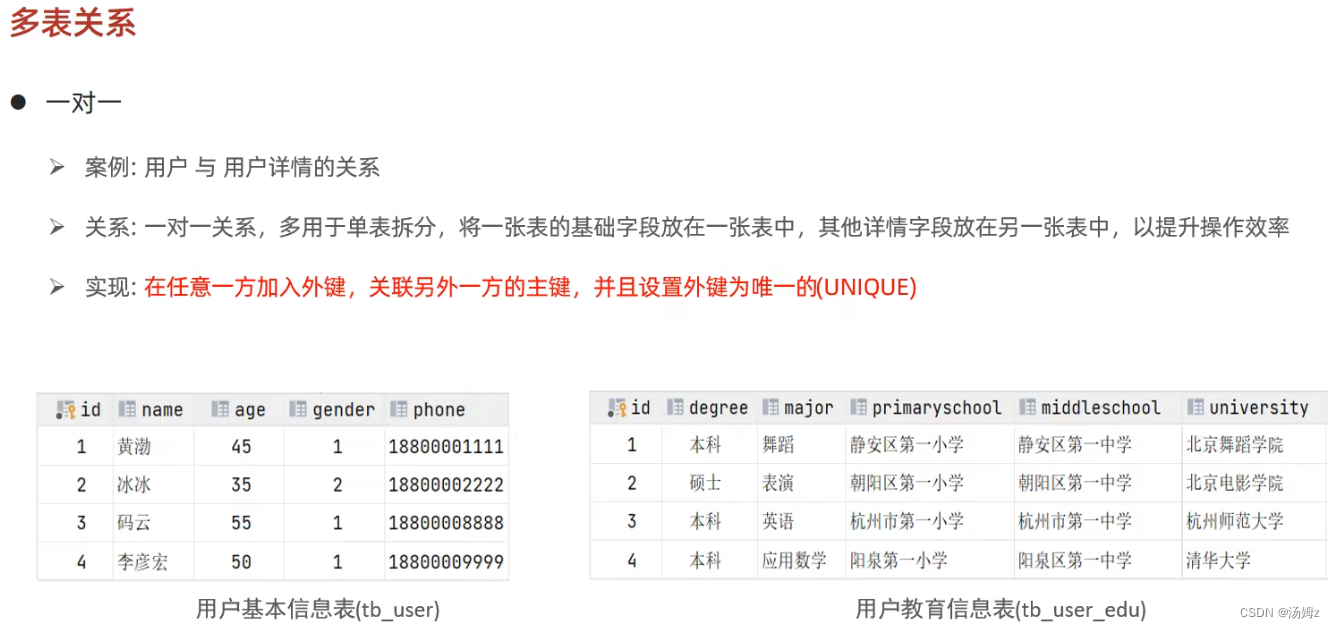

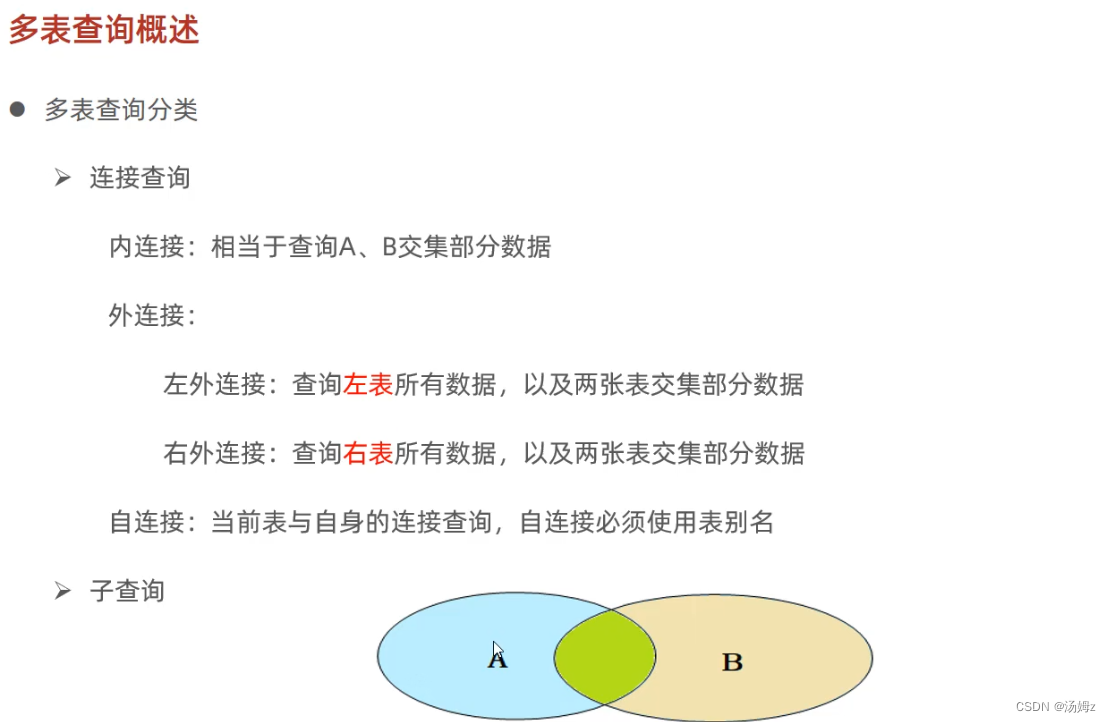
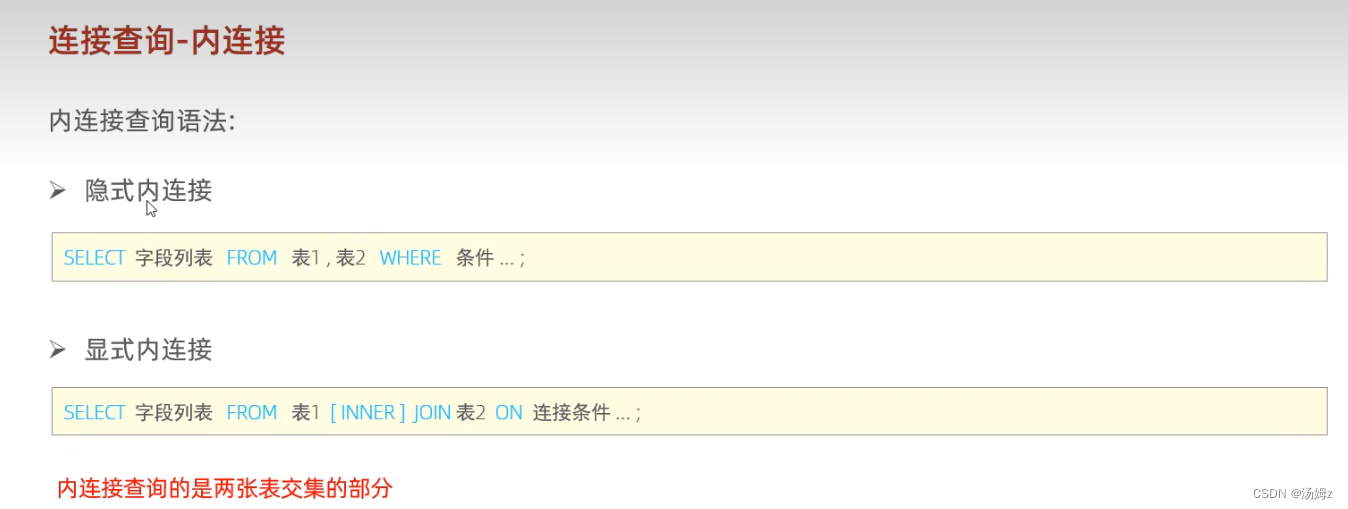
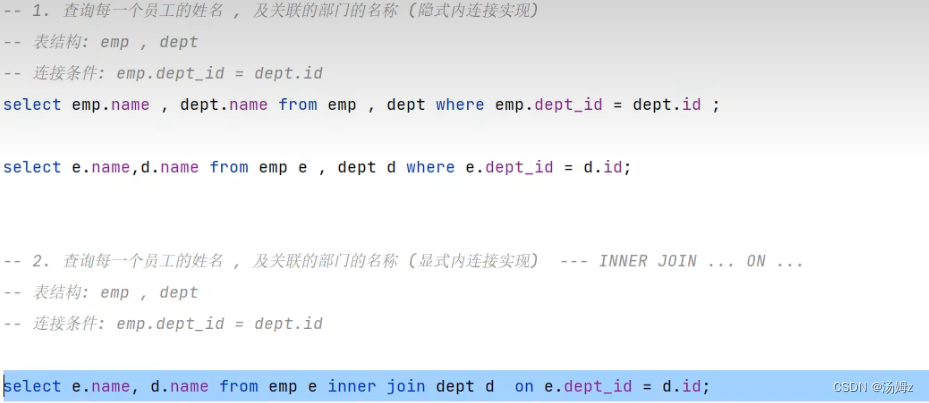
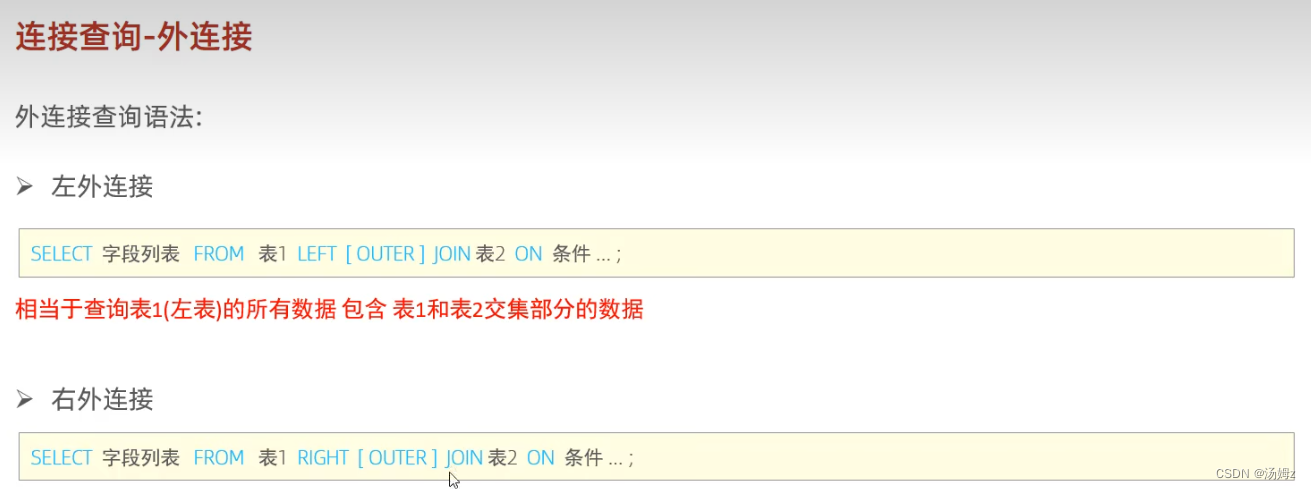
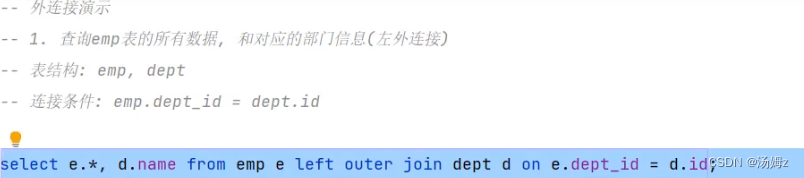
PS:左右可以互换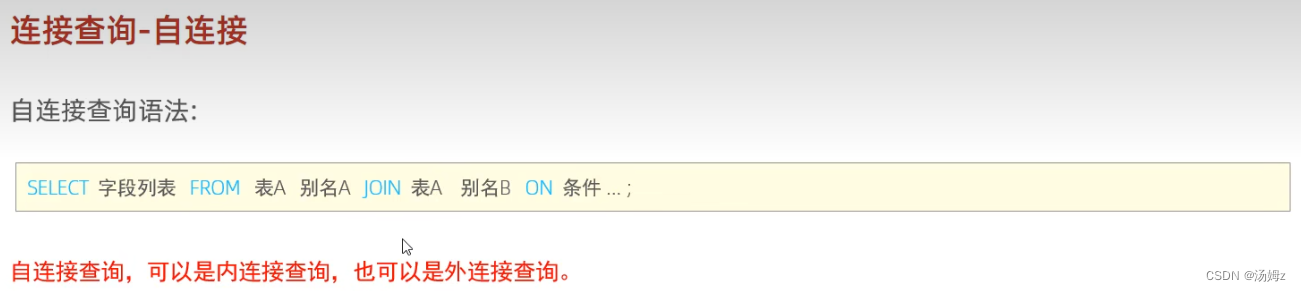 PS:自己连接自己,比如一个员工表查询自己的领导,同时领导也属于公司的员工
PS:自己连接自己,比如一个员工表查询自己的领导,同时领导也属于公司的员工PS:左右连接的好处在于可以把对应值为null的数据也展现出来
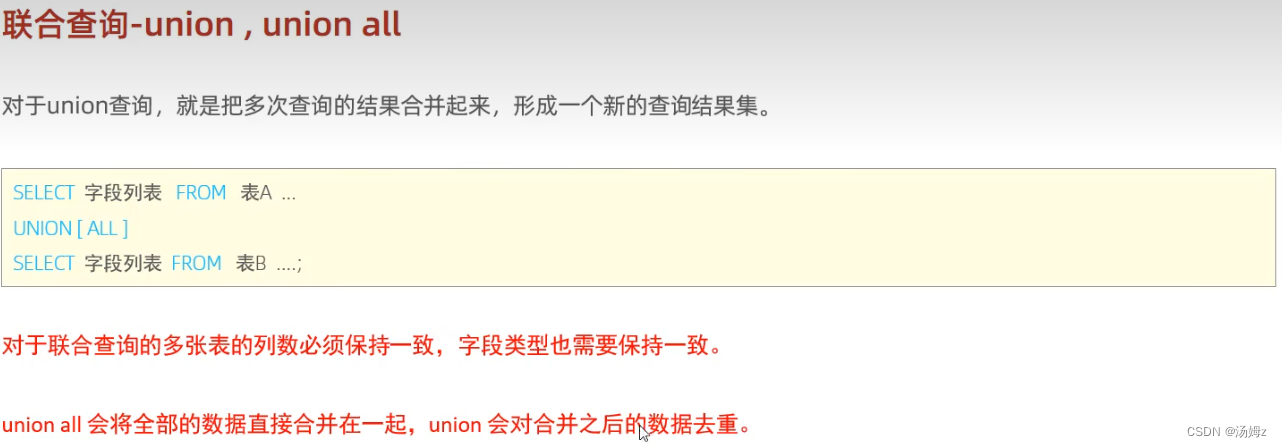






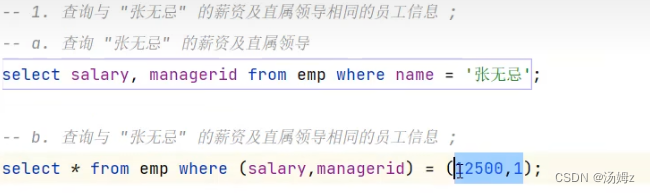




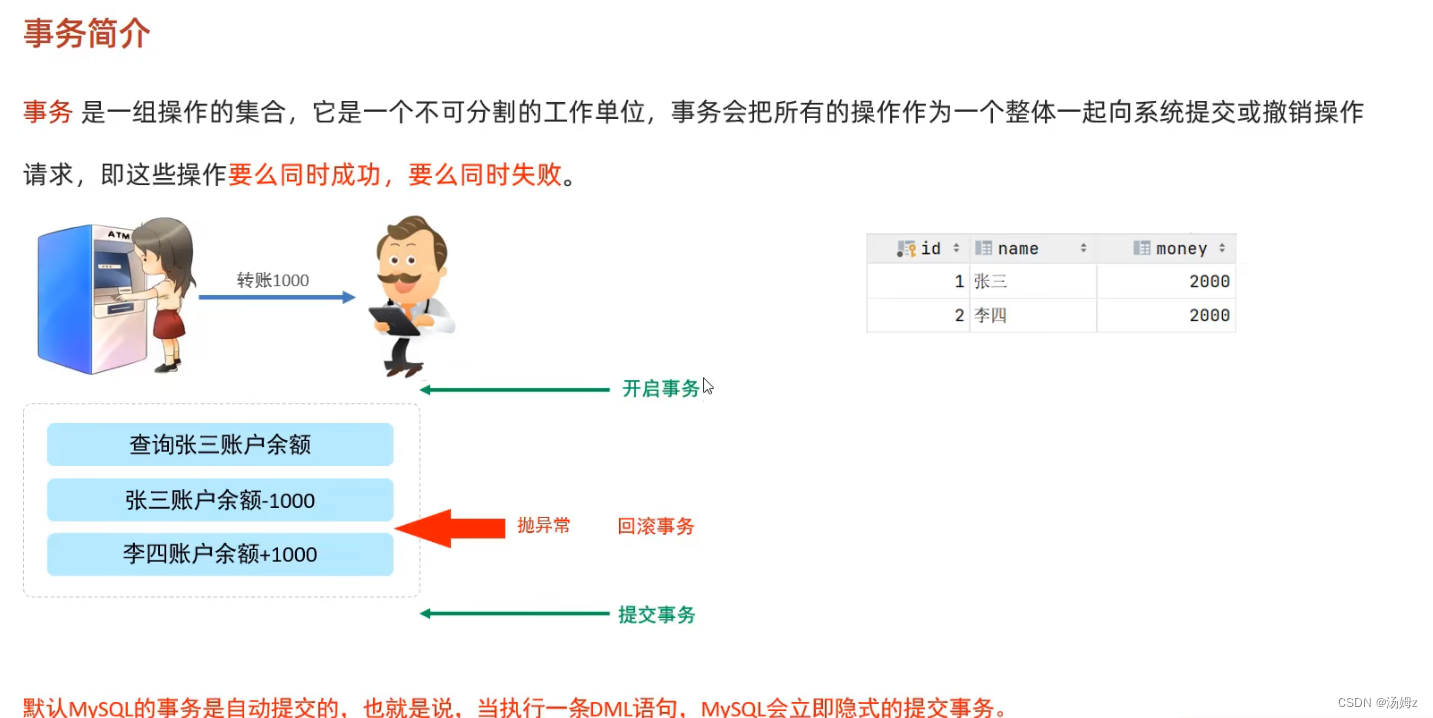
事务
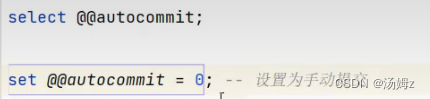
 方式一
方式一
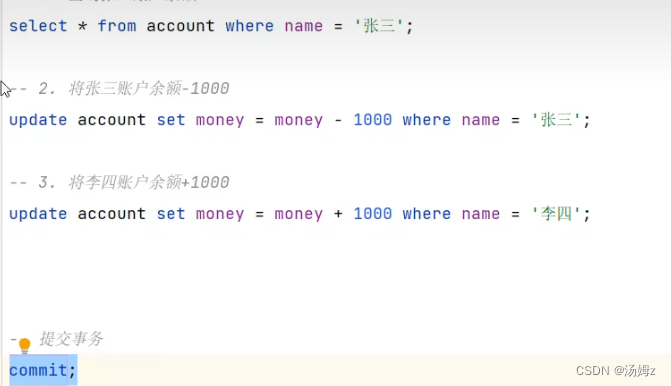

方式二
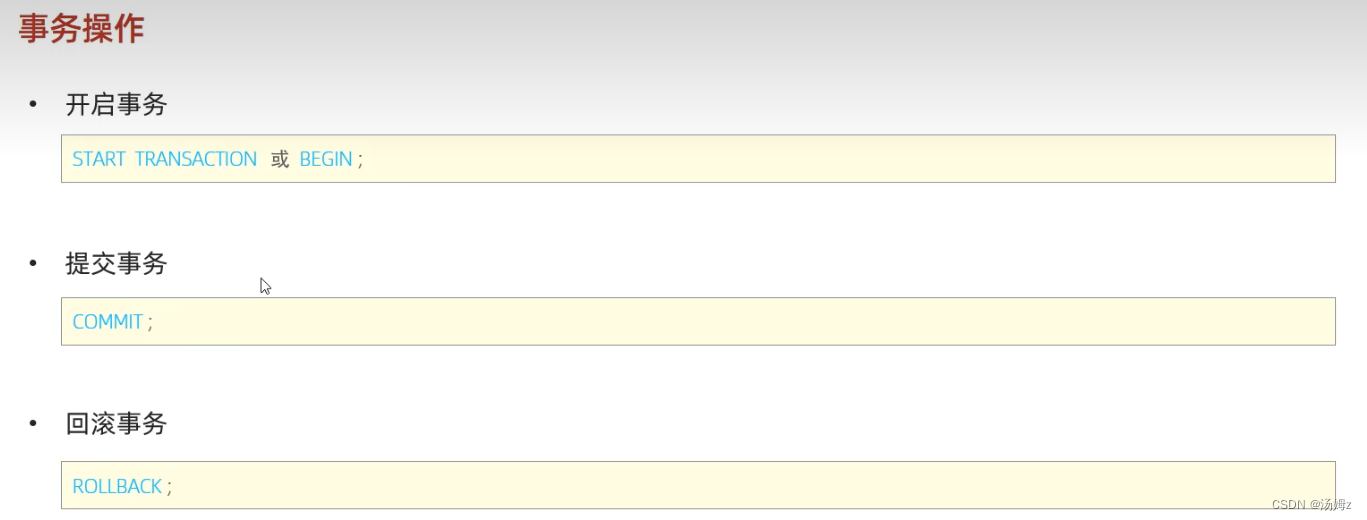


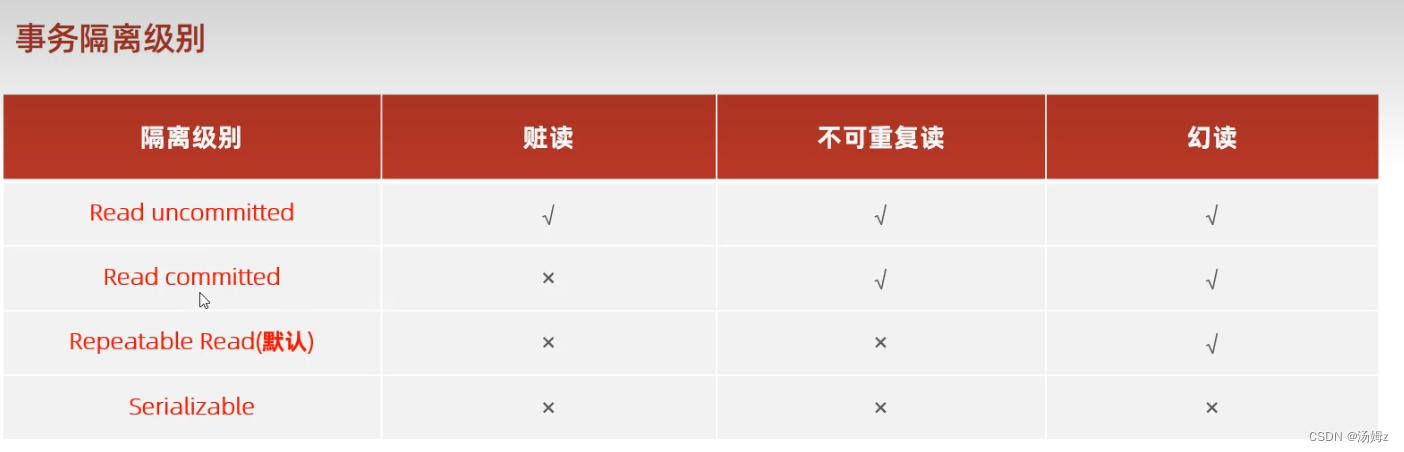
PS:从上往下性能降低
进阶阶段
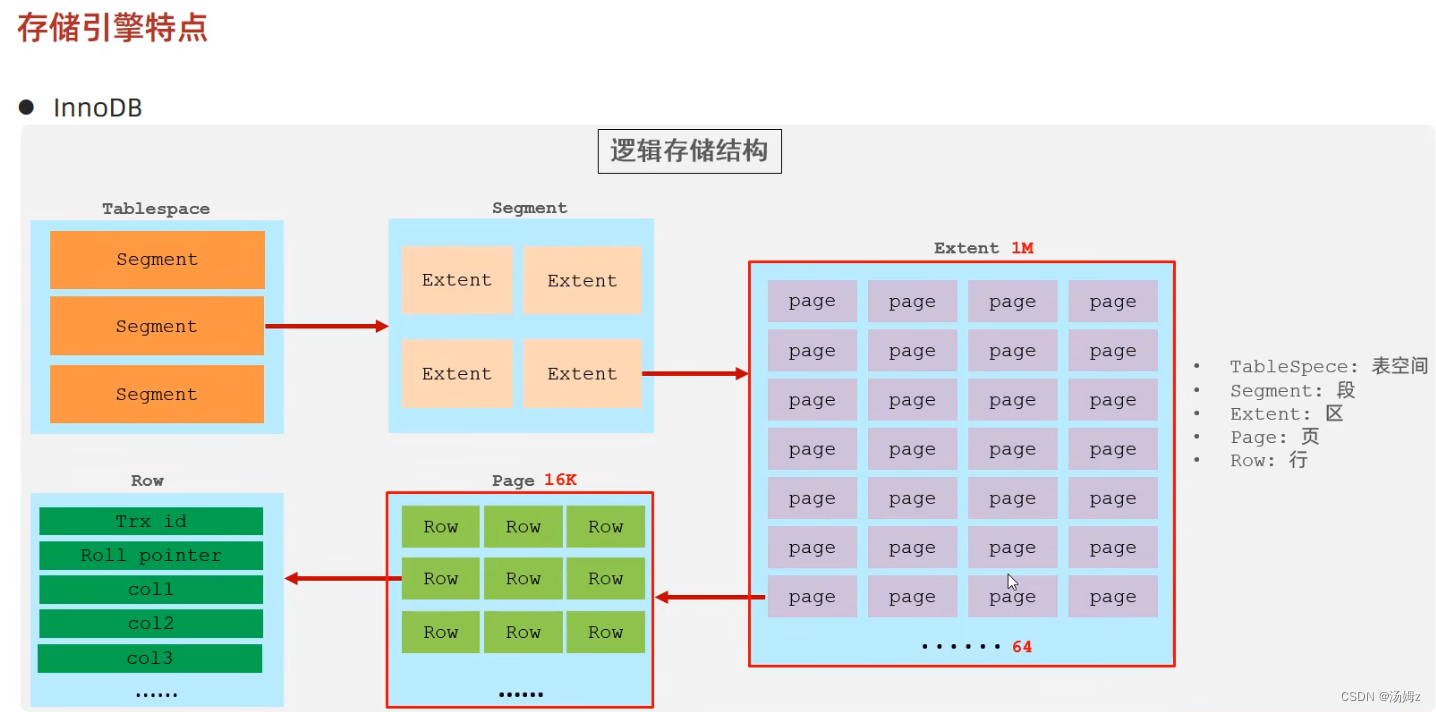
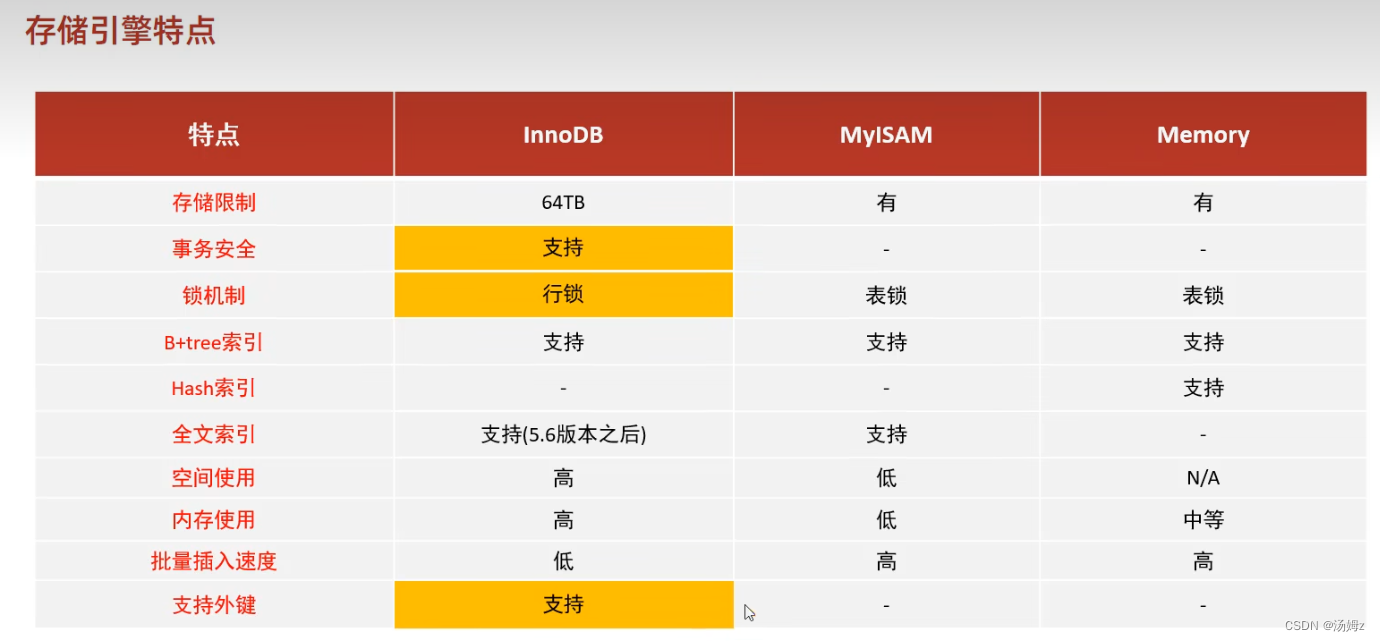
存储引擎
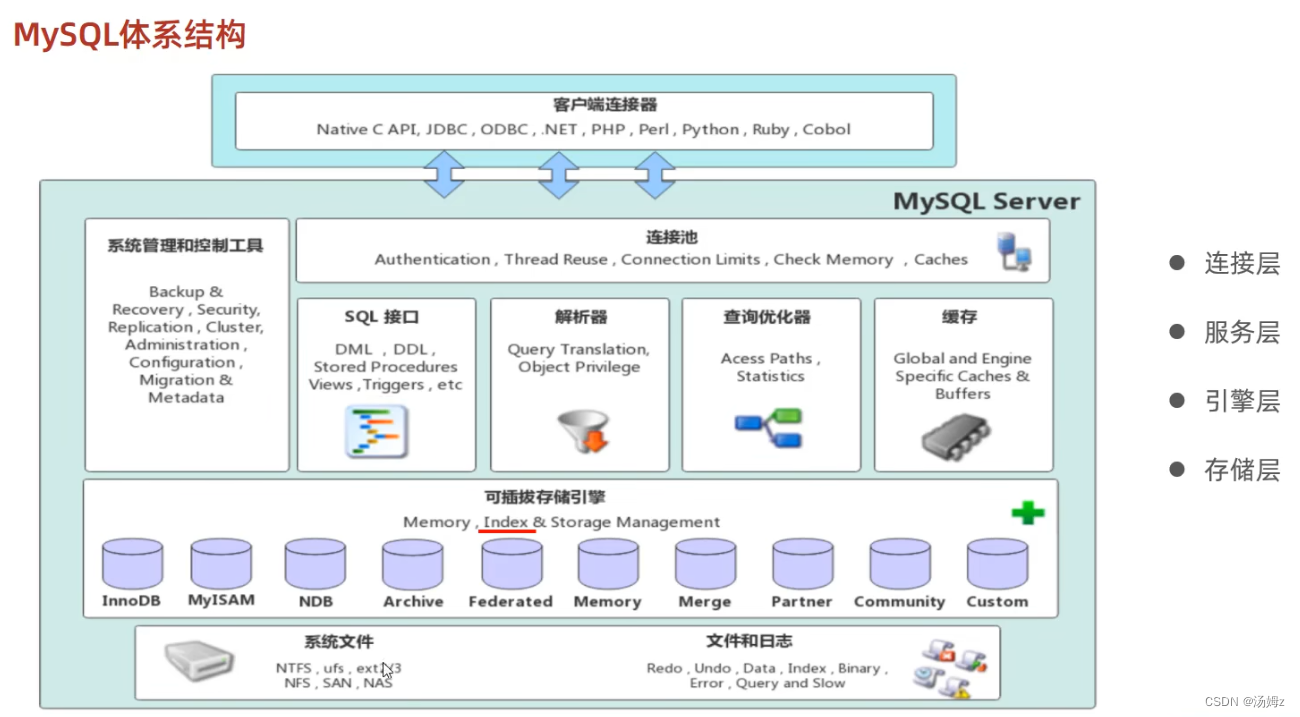

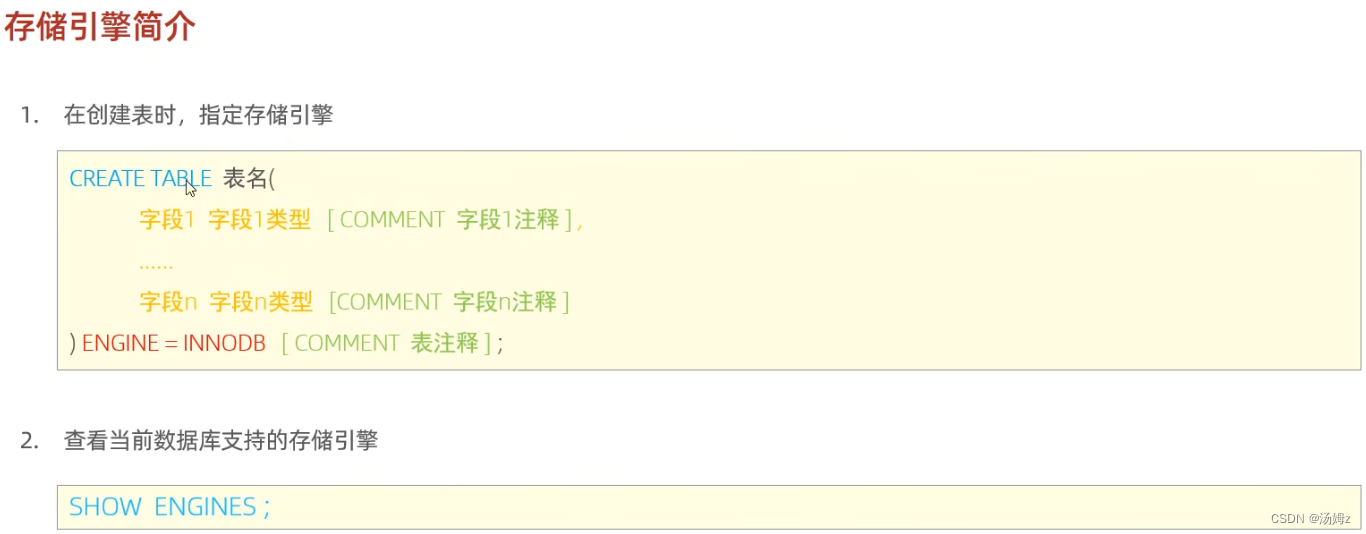 PS:默认InnoDB引擎
PS:默认InnoDB引擎
 PS:每一个表都对应着一个ibd文件,存储着表结构和数据
PS:每一个表都对应着一个ibd文件,存储着表结构和数据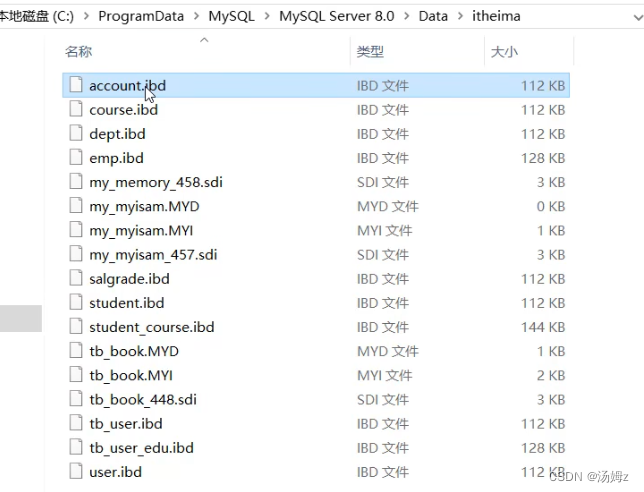



索引

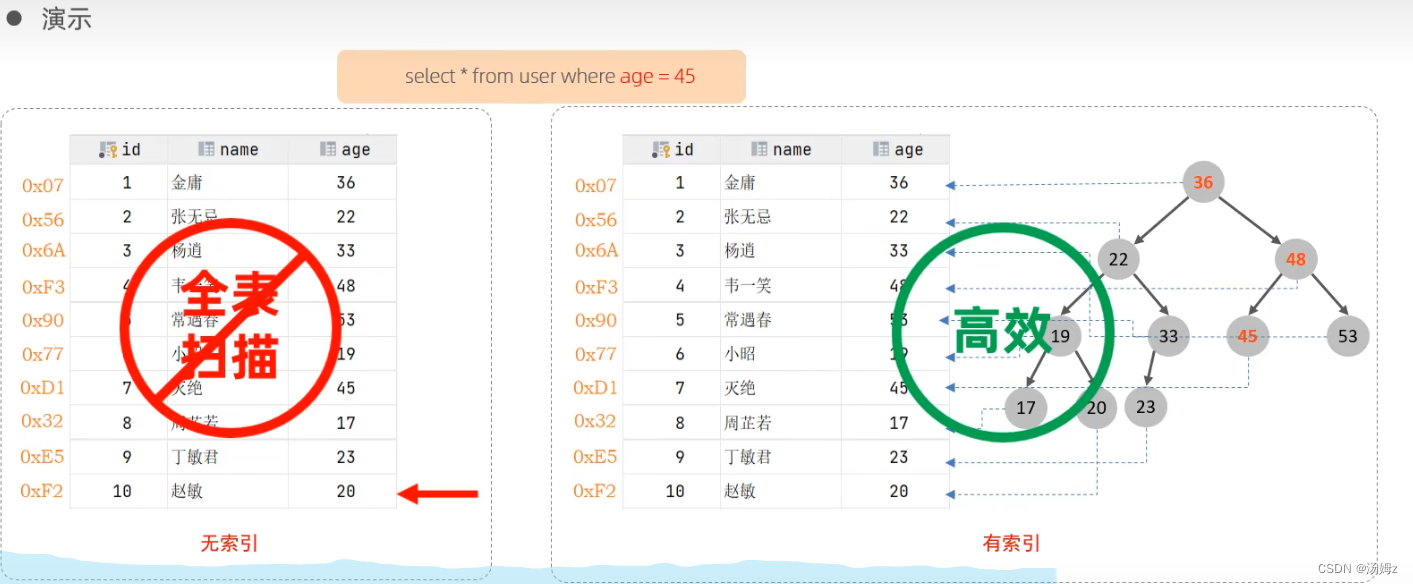


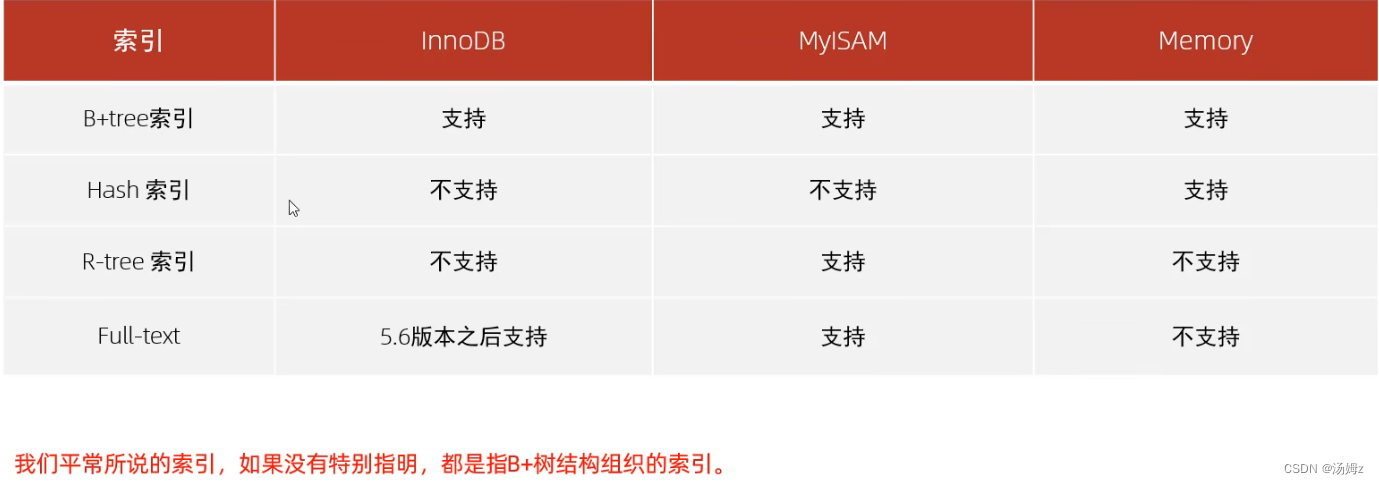
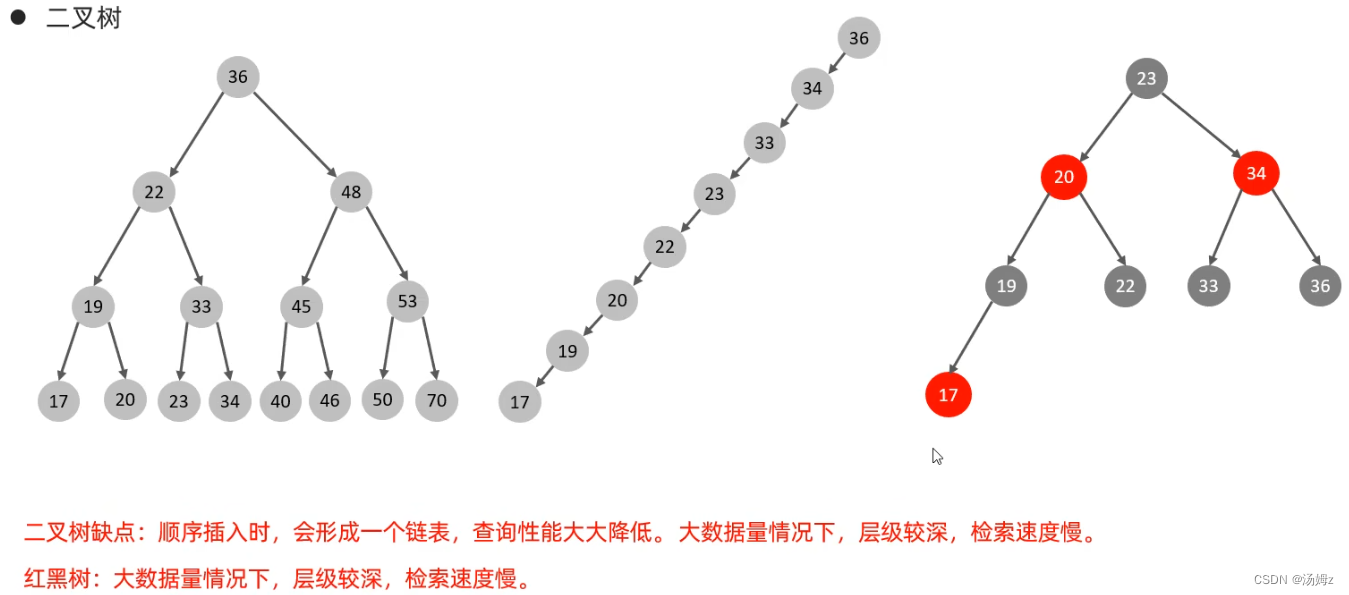
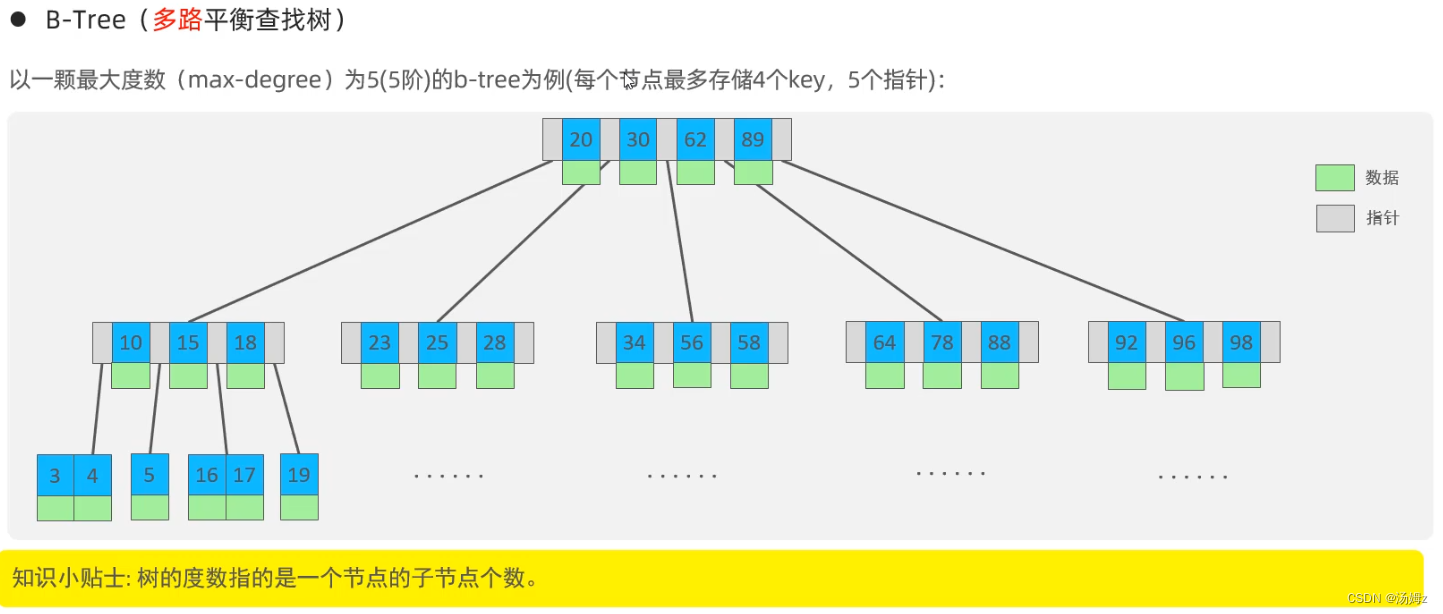

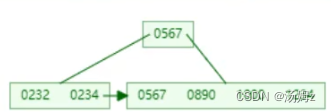
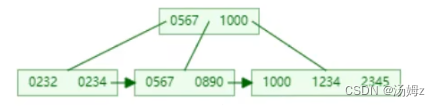

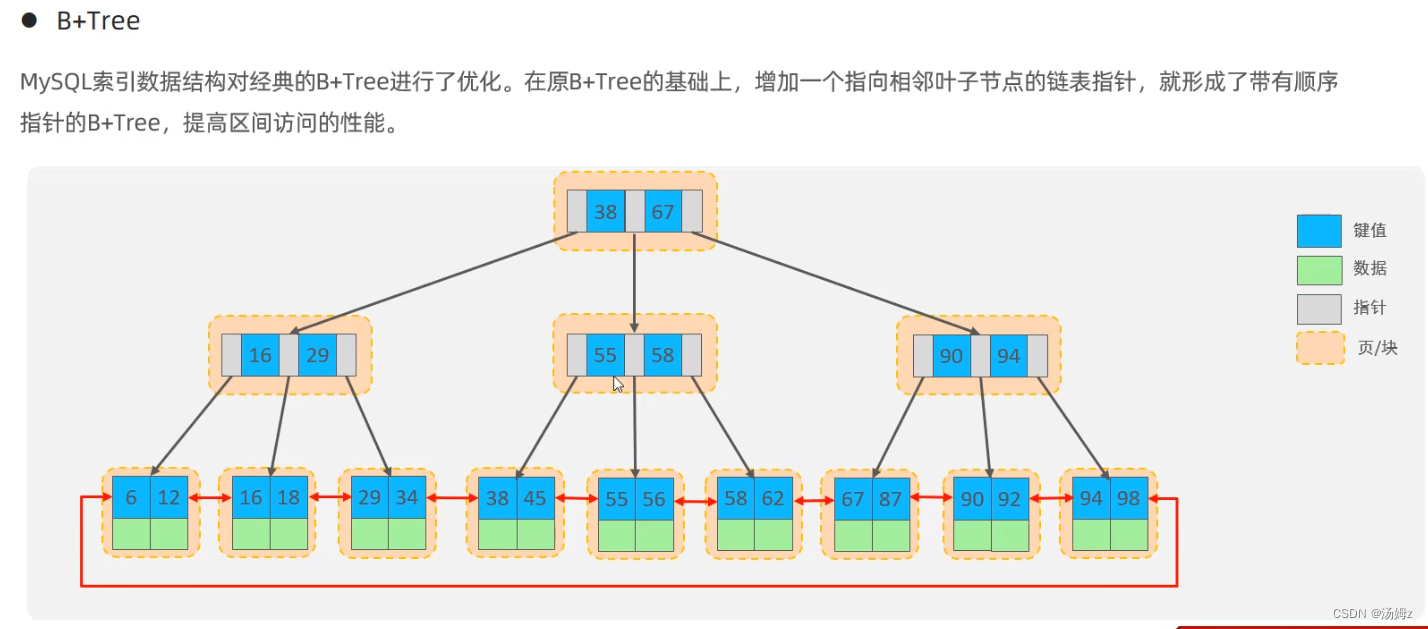
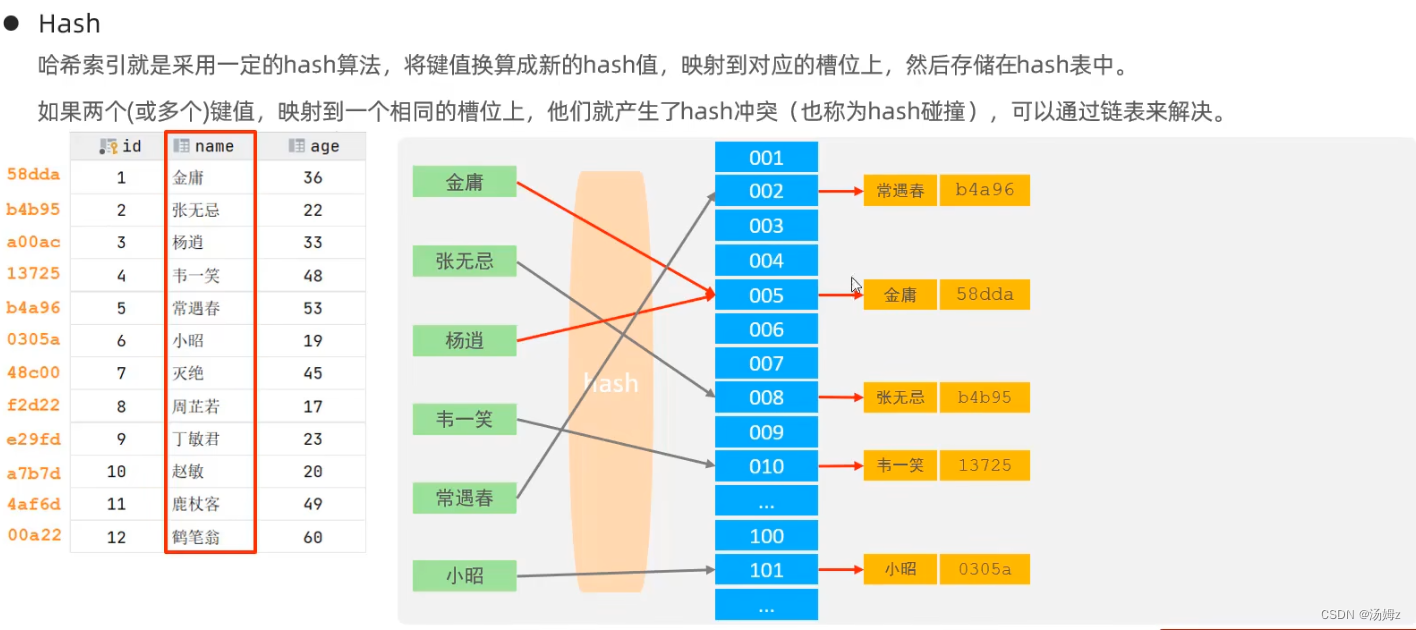

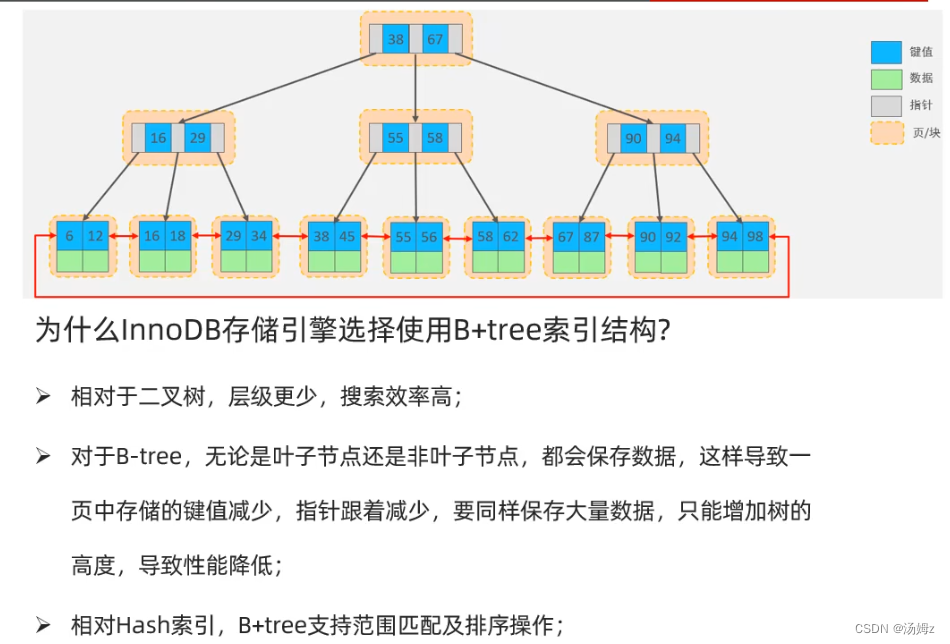
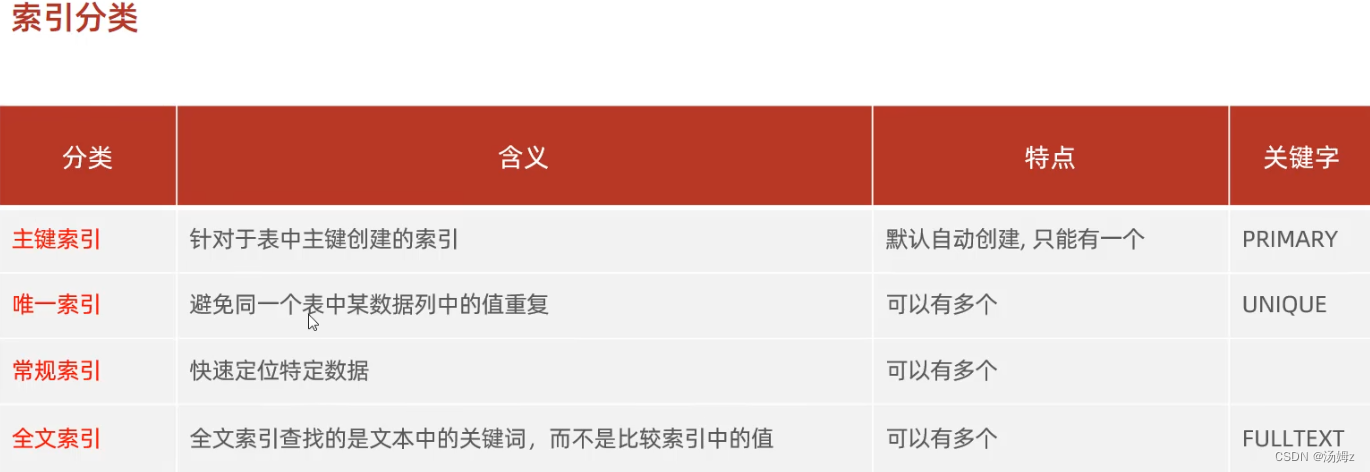

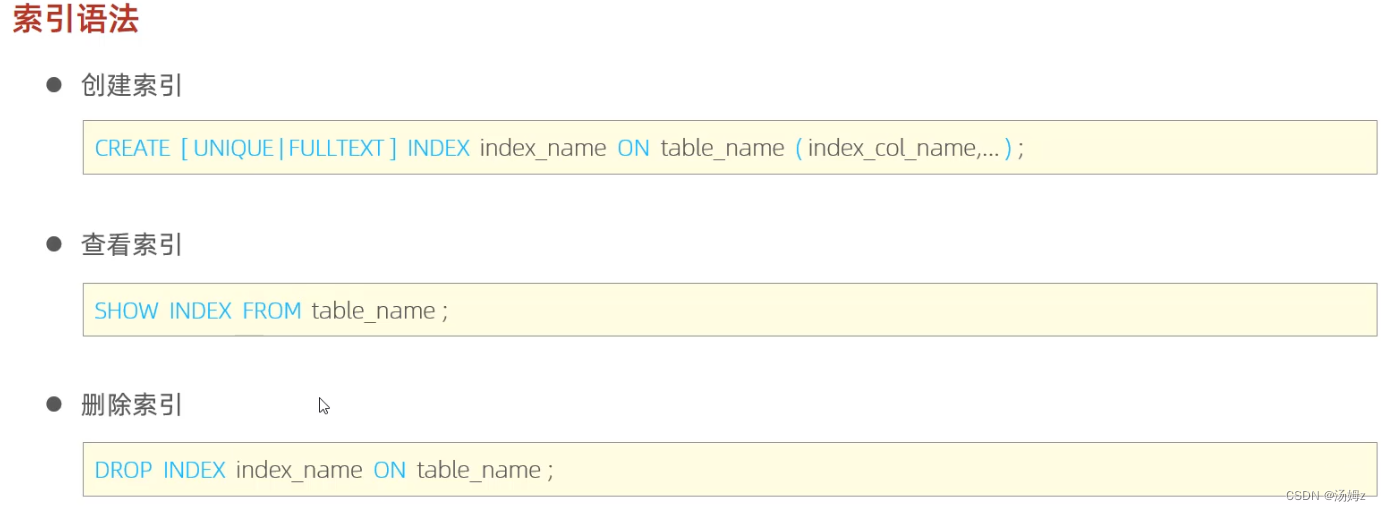
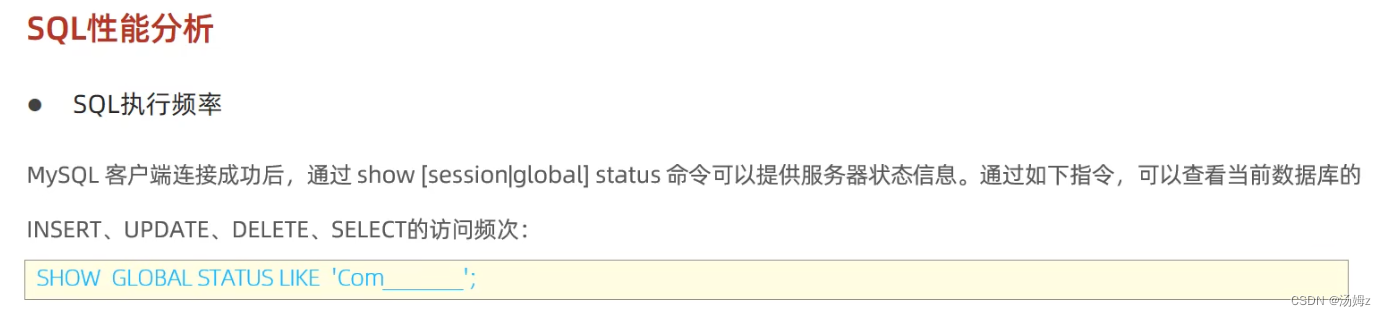 PS:如果查询占大多数,那么性能优化就用慢查询日志,查询哪些select语句需要优化
PS:如果查询占大多数,那么性能优化就用慢查询日志,查询哪些select语句需要优化
PS:查询慢查询开启否

PS:还有要优化那种业务简单却相对较长的select语句,通过profile
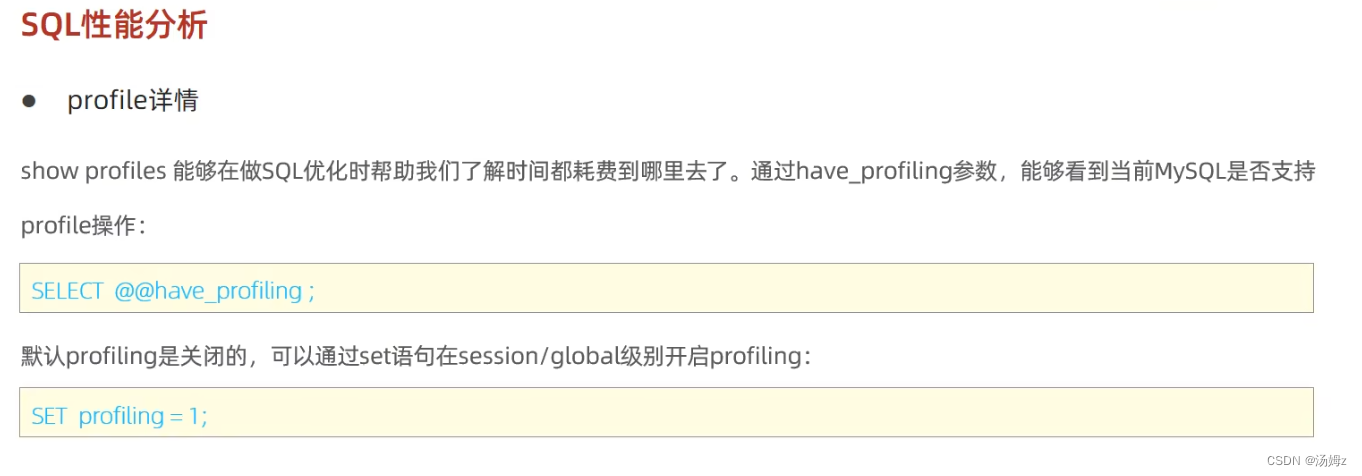
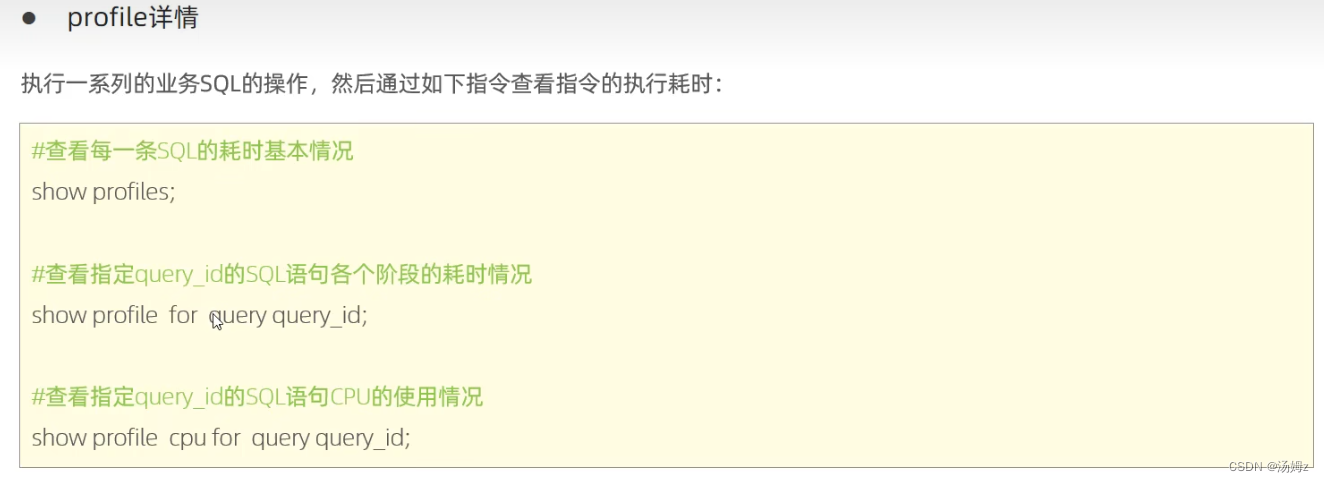
以上都是通过时间来粗略判定SQL语句的性能,要想真正的查看性能要用explain,查询是否使用索引等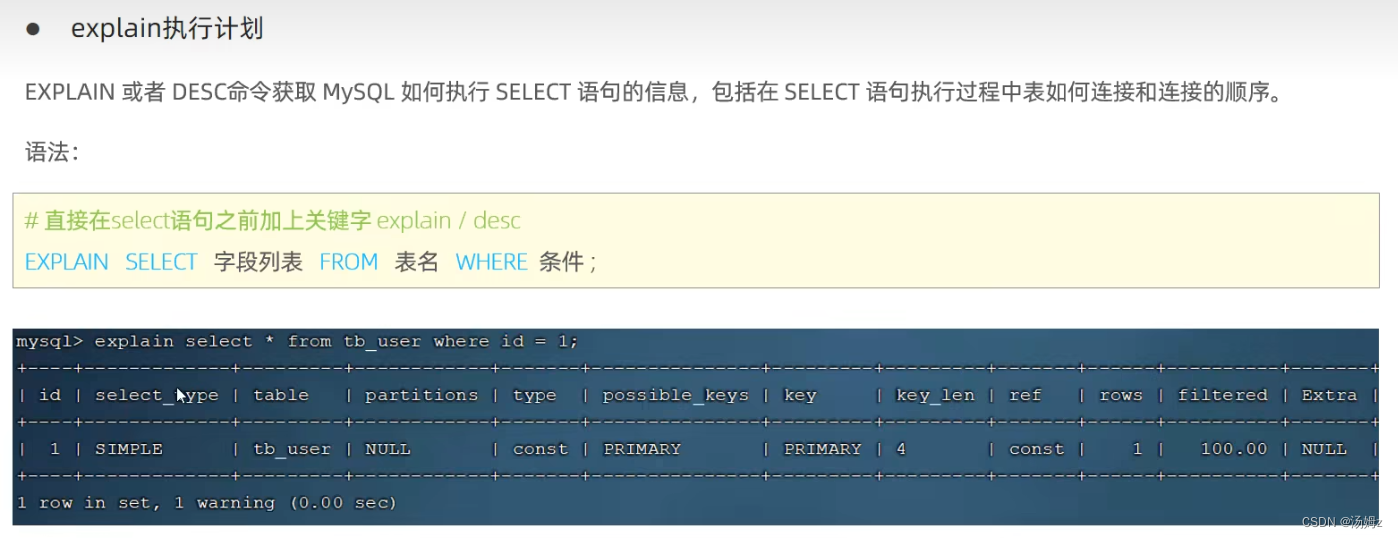


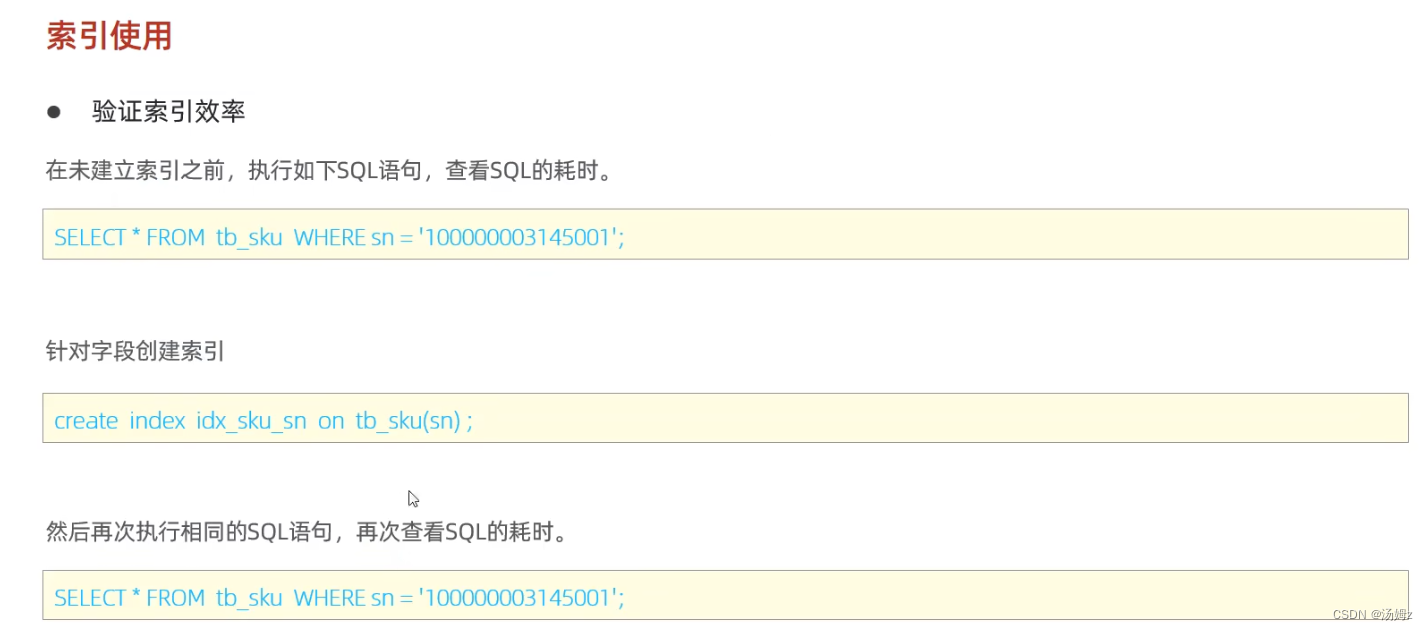
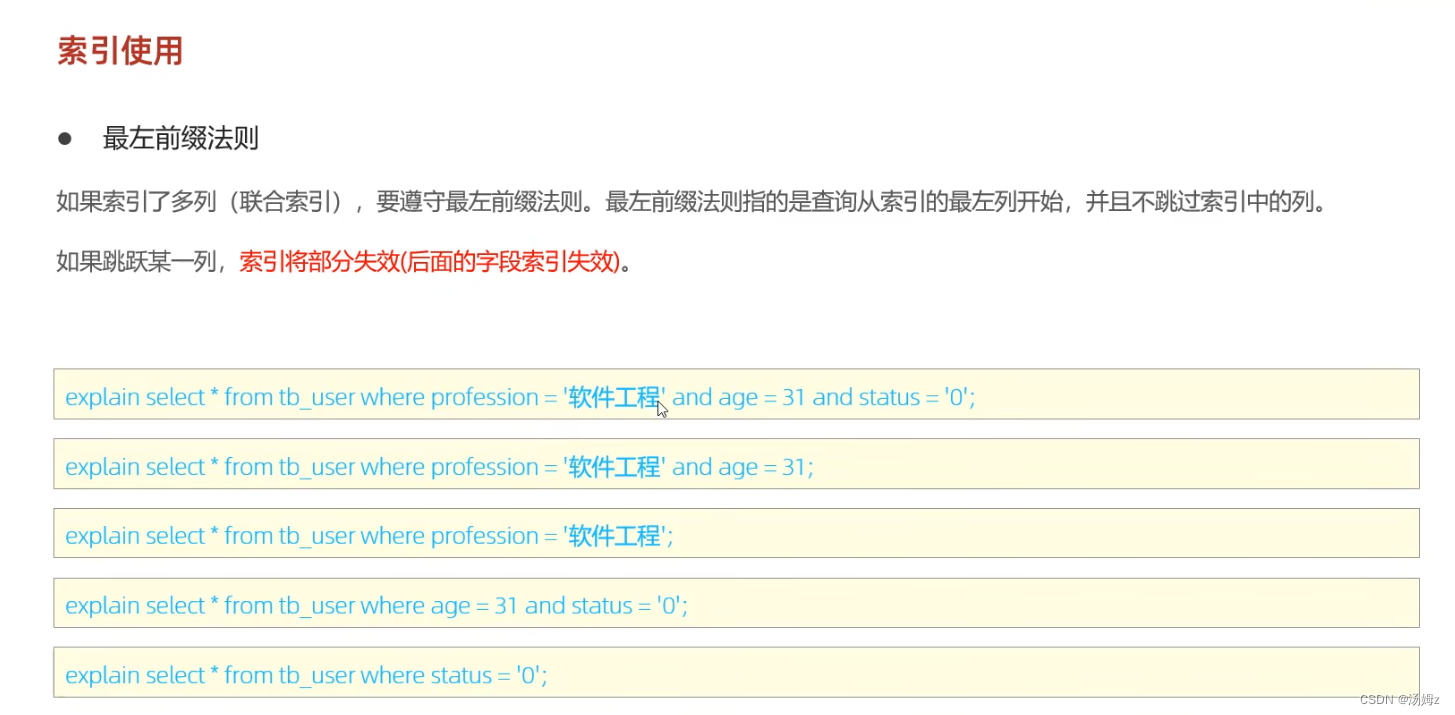
 PS:尽量使用大于等于或小于等于,否则后面的status的索引失效
PS:尽量使用大于等于或小于等于,否则后面的status的索引失效
PS:索引使用如果不注意就会变成全表扫描,费时



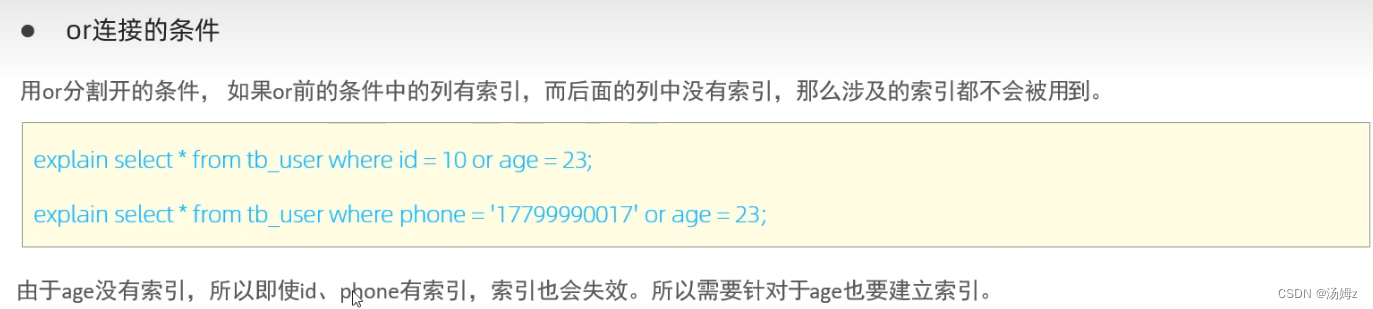
 PS:因为大多数都符合条件,那么还不如走全表扫描省时
PS:因为大多数都符合条件,那么还不如走全表扫描省时有了复合索引还能对字段再创建一个单列索引,这时候如果查询的时候可以用SQL提示来说明想用哪个索引来查询

PS:索引有单列索引和联合索引,分别就是一个和多个
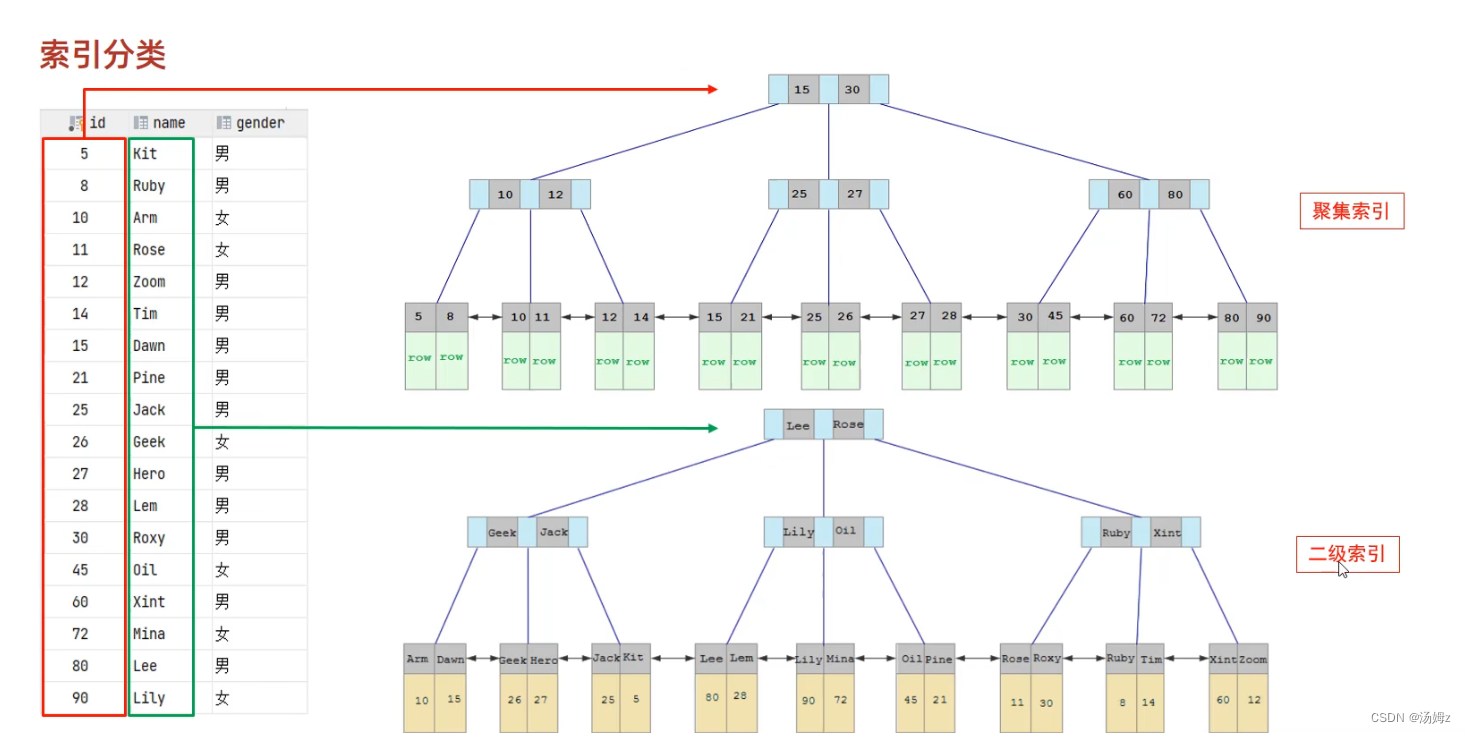
PS:第一个use只是建议,用不用是系统来评估的也可能不接受建议,第三条是强制使用 PS:在二级索引的叶子上就能找到ID,如果还要查询别的字段就需要在通过ID走聚集索引来找其他的字段,也就是回表查询数据,如果在聚集索引中用ID找*也数据覆盖索引的原则,不用回表
PS:在二级索引的叶子上就能找到ID,如果还要查询别的字段就需要在通过ID走聚集索引来找其他的字段,也就是回表查询数据,如果在聚集索引中用ID找*也数据覆盖索引的原则,不用回表
PS:这里就可以多建立联合索引,这样就不用回表查询了
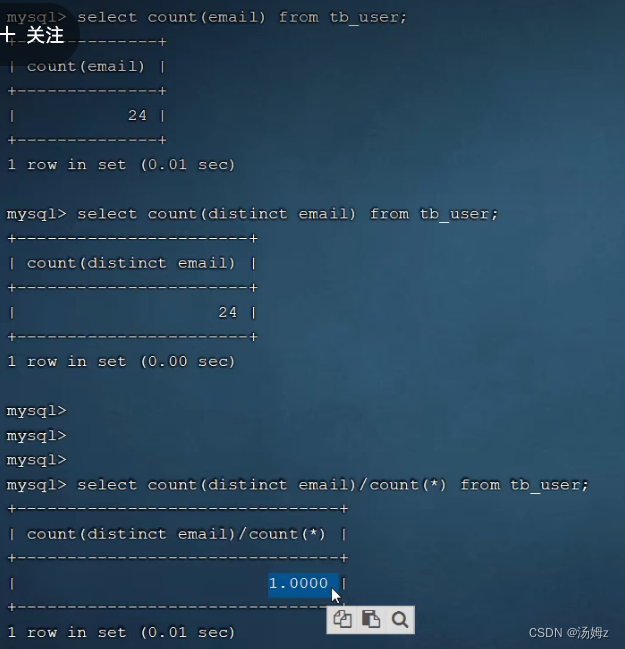
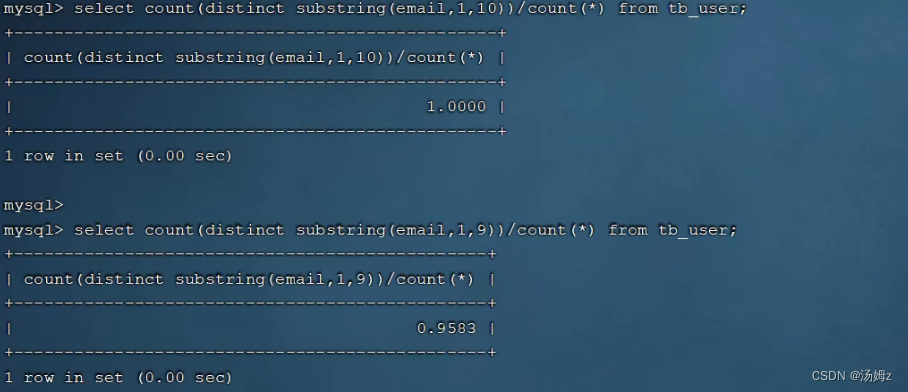 PS:自己平衡性能和大小来选择选前几个,降低索引体积提高查询效率
PS:自己平衡性能和大小来选择选前几个,降低索引体积提高查询效率
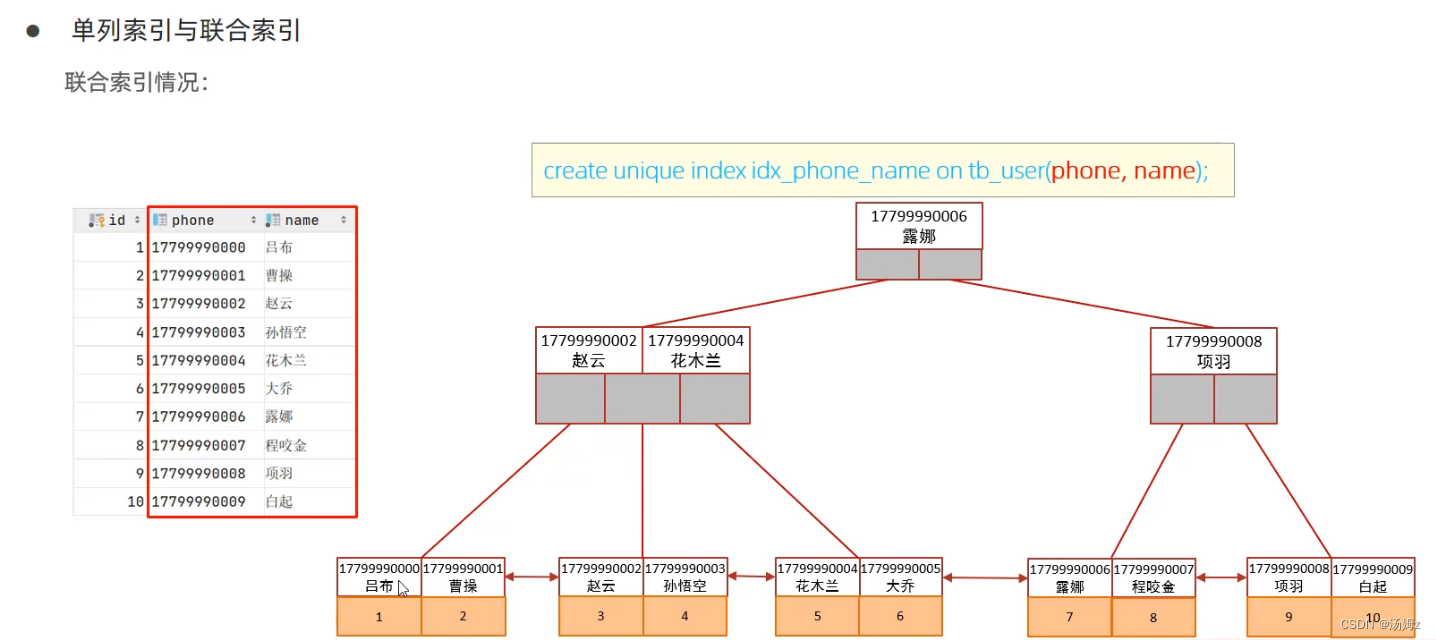
PS:一定要考虑顺序,根据最左前缀法则最左边的一定要存在,上图中是phone PS:如果数据量超过一百万就要考虑建立索引
PS:如果数据量超过一百万就要考虑建立索引


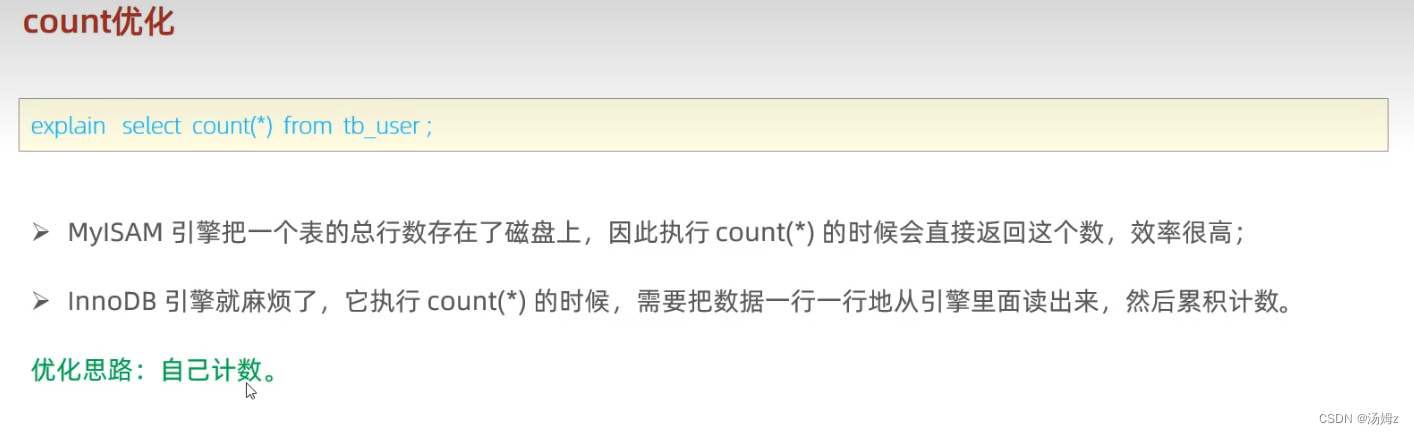
SQL优化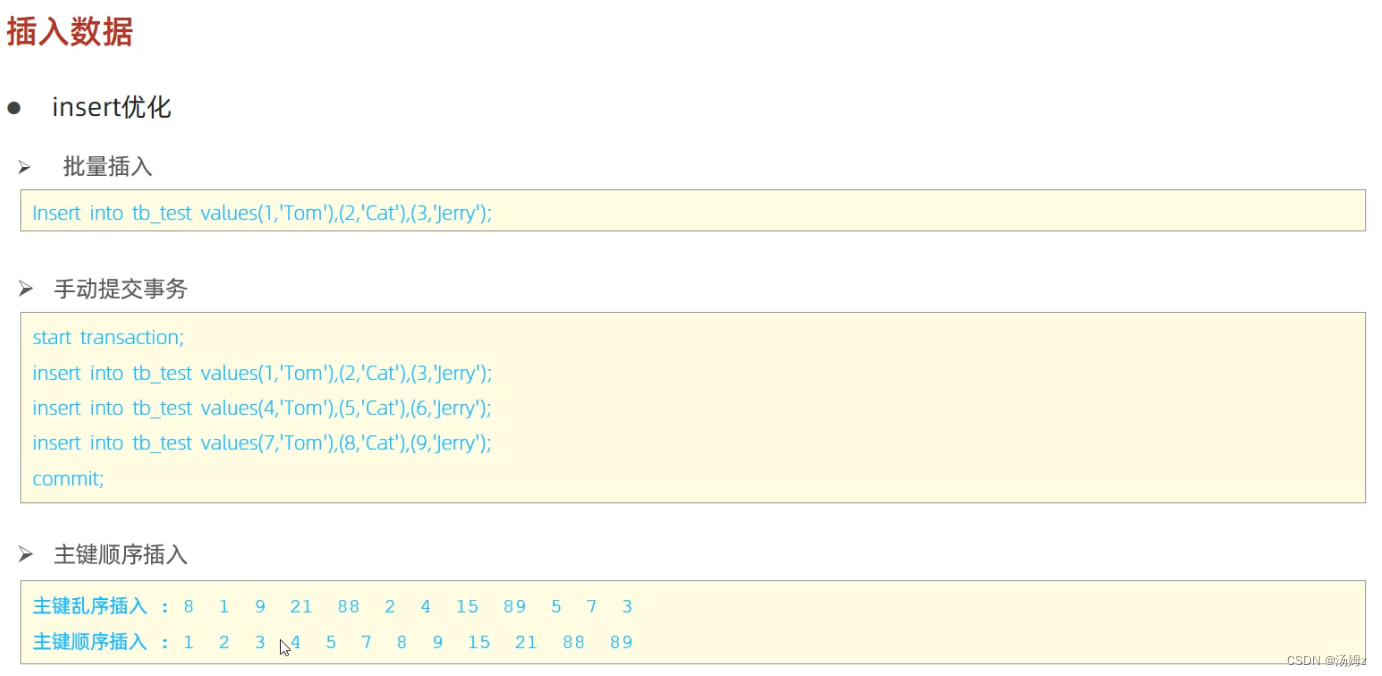
PS:避免频繁的事务的提交
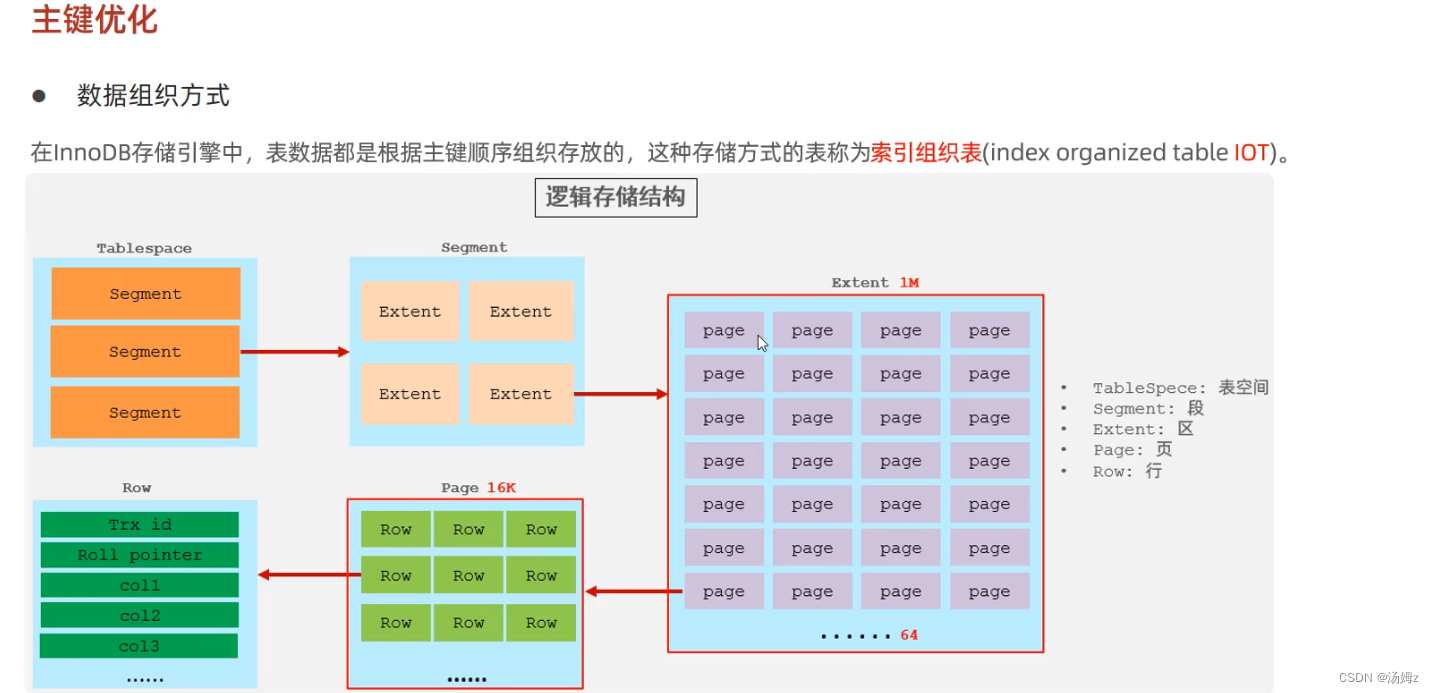



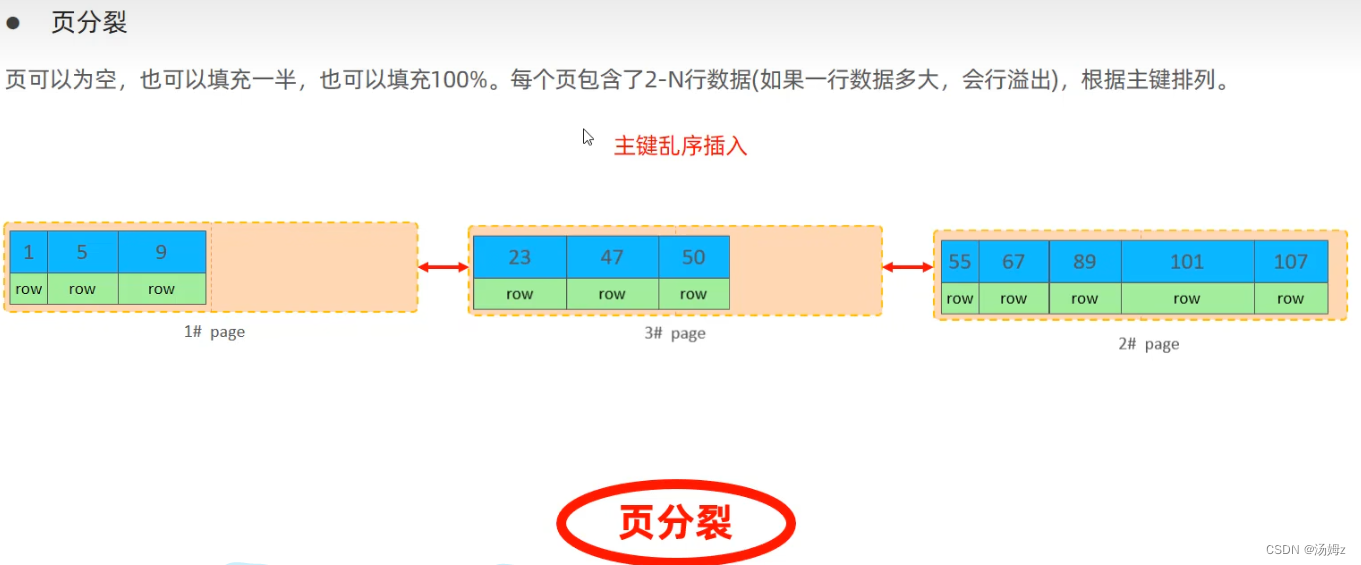


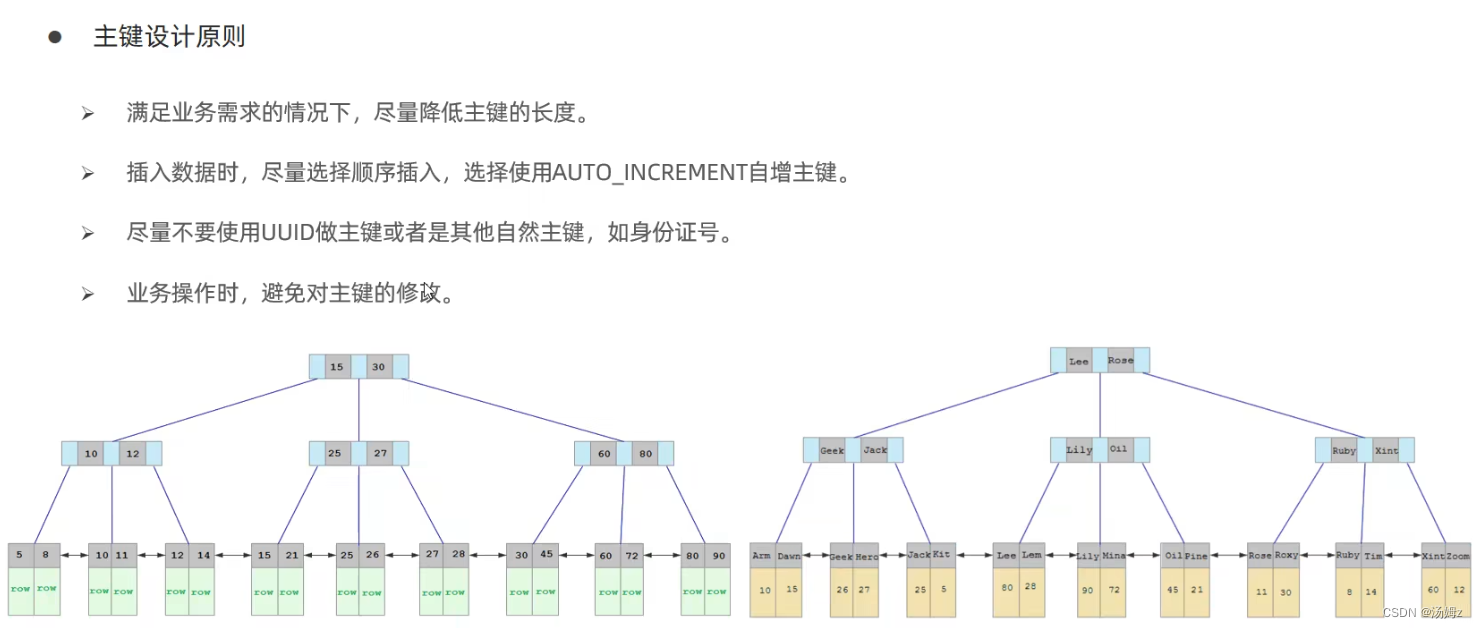 PS:二级索引有很多并且叶子节点都是主键,如果主键太长会耗费大量的磁盘空间,像UUID这类生成的时候没有规矩很可能造成乱序插入
PS:二级索引有很多并且叶子节点都是主键,如果主键太长会耗费大量的磁盘空间,像UUID这类生成的时候没有规矩很可能造成乱序插入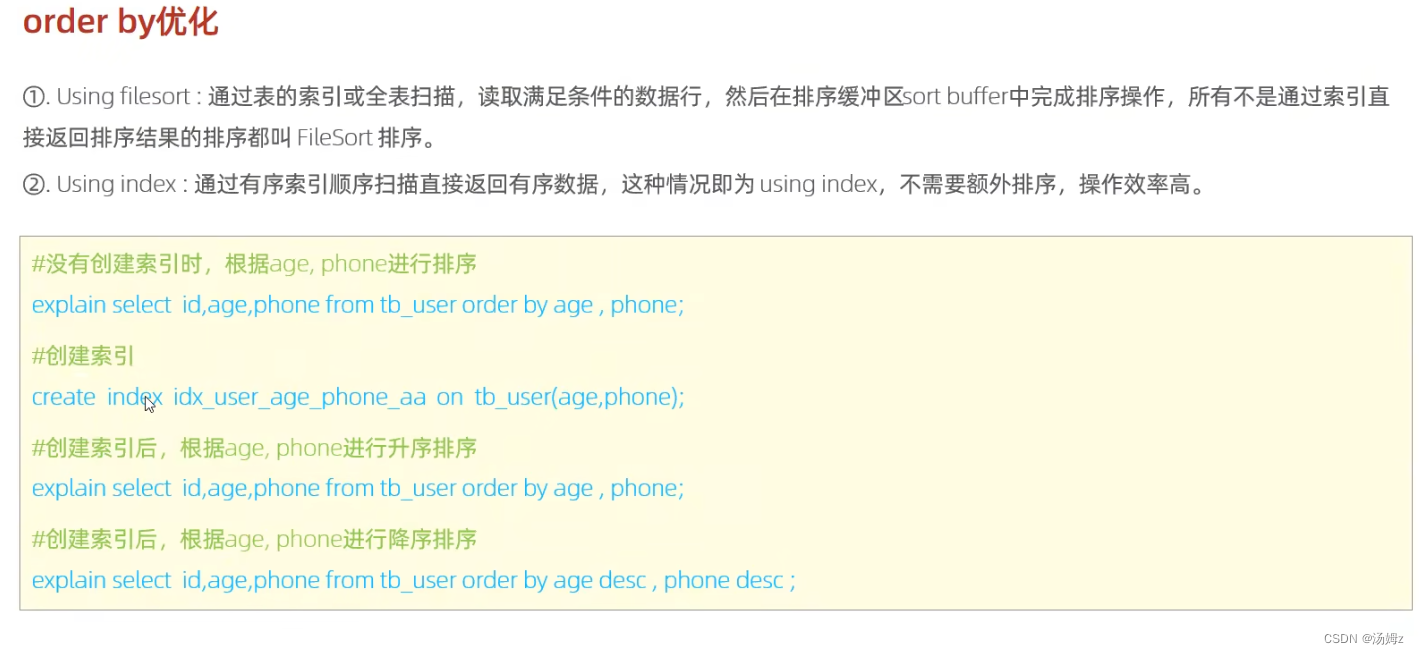

PS:可以定义不同的排序规则,这样优化的时候可以也可以一个升序一个降序
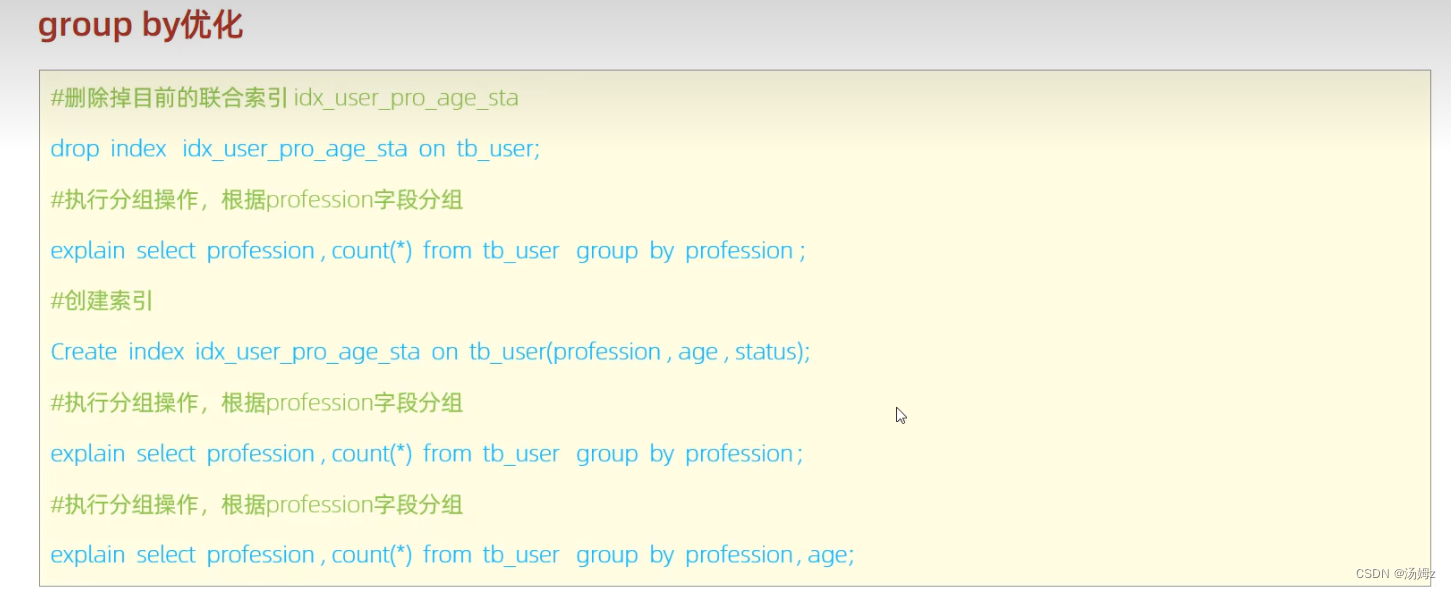
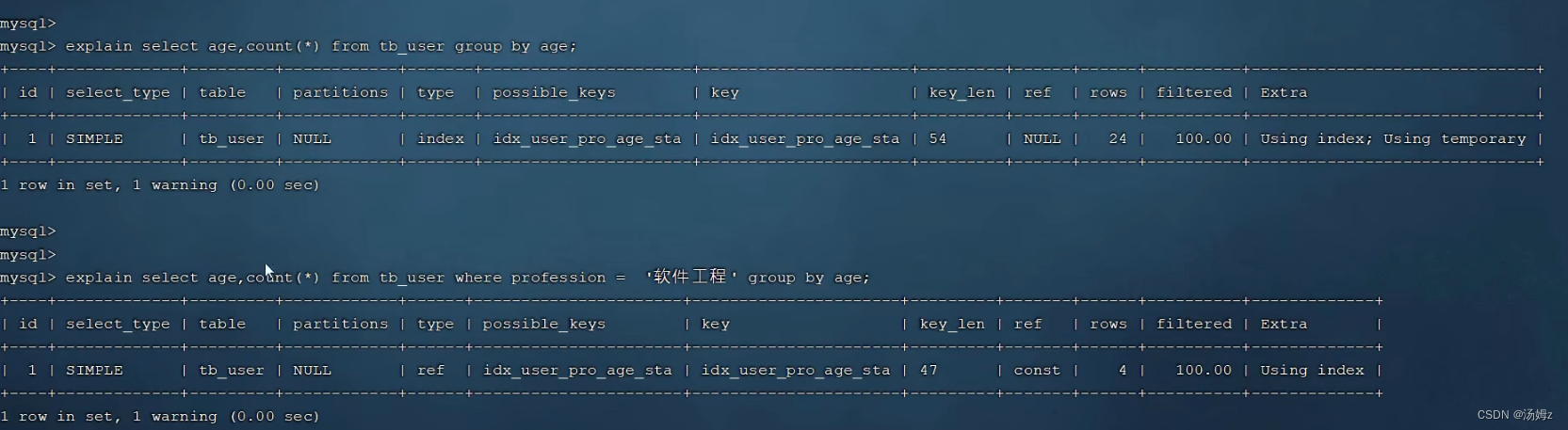 PS:下面满足最左前缀法则,不用临时表,提高效率
PS:下面满足最左前缀法则,不用临时表,提高效率


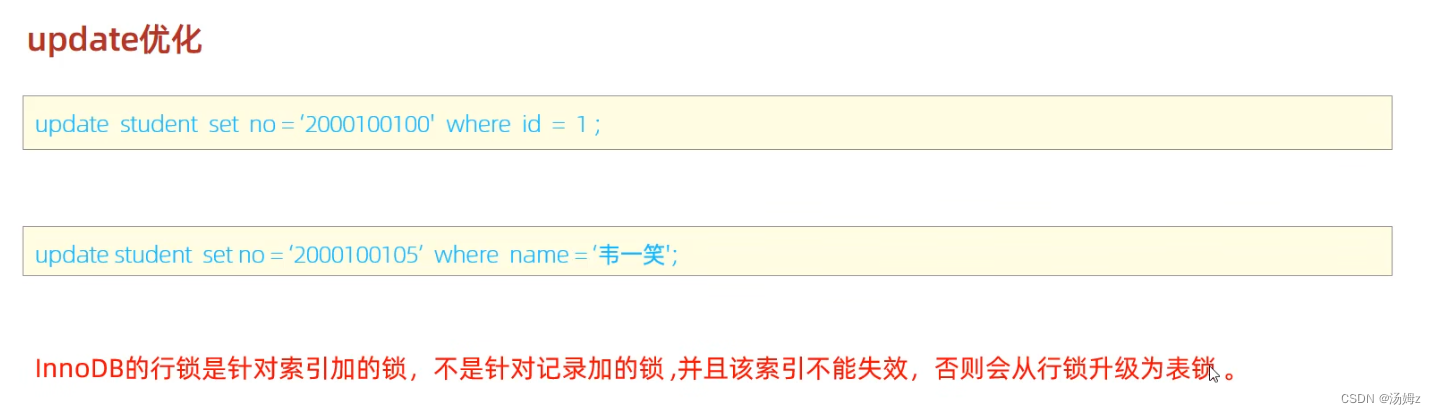
PS:一旦升级为表锁那么并发性能就会降低
视图

PS:视图是一个虚拟的表,我们可以像操作表一样操作视图,也能增删改查

PS:cascaded级连,连带检查所有依赖的视图,没有加检查就不会检查

 PS:使用简单,定义为基本的视图然后可以进行视图依赖,简化操作,数据安全也就是可以用视图来让用户只能查询和修改他们所能见到的数据,数据独立指在SQL语句中可以用起别名的方法来屏蔽真实表的结构变化如名字变化带来的影响
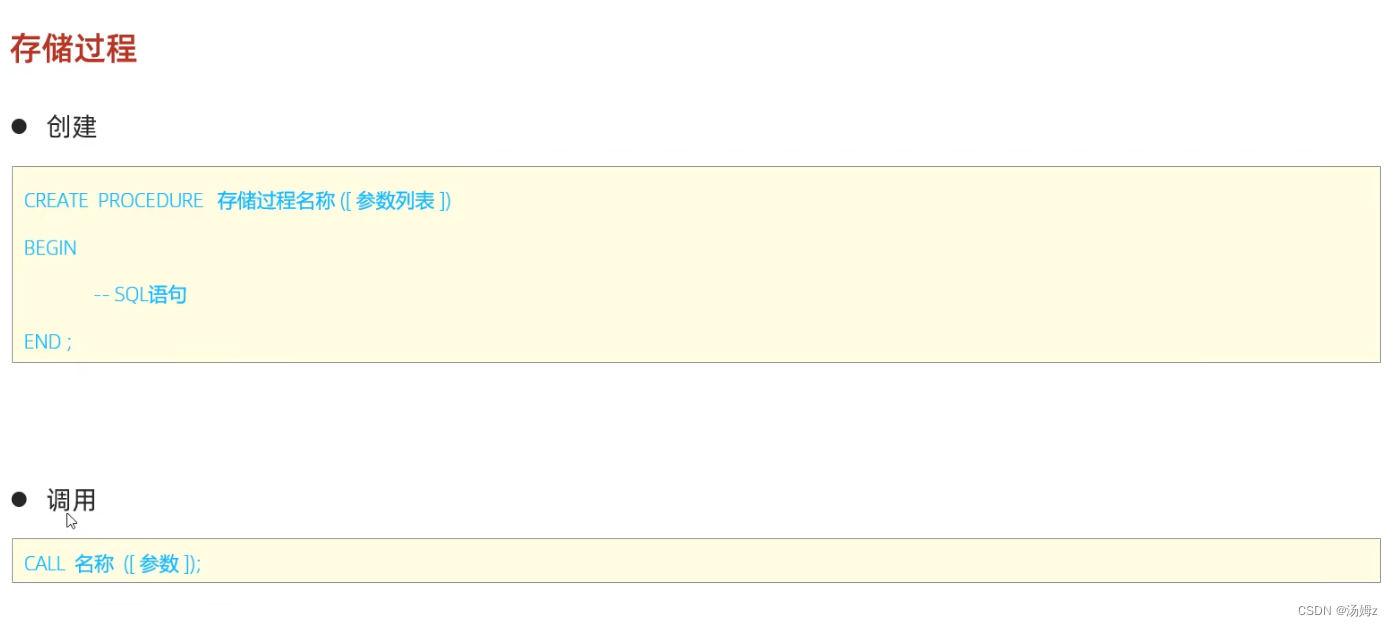
PS:使用简单,定义为基本的视图然后可以进行视图依赖,简化操作,数据安全也就是可以用视图来让用户只能查询和修改他们所能见到的数据,数据独立指在SQL语句中可以用起别名的方法来屏蔽真实表的结构变化如名字变化带来的影响存储过程
PS:每一次的SQL都代表一次网络请求




PS:默认session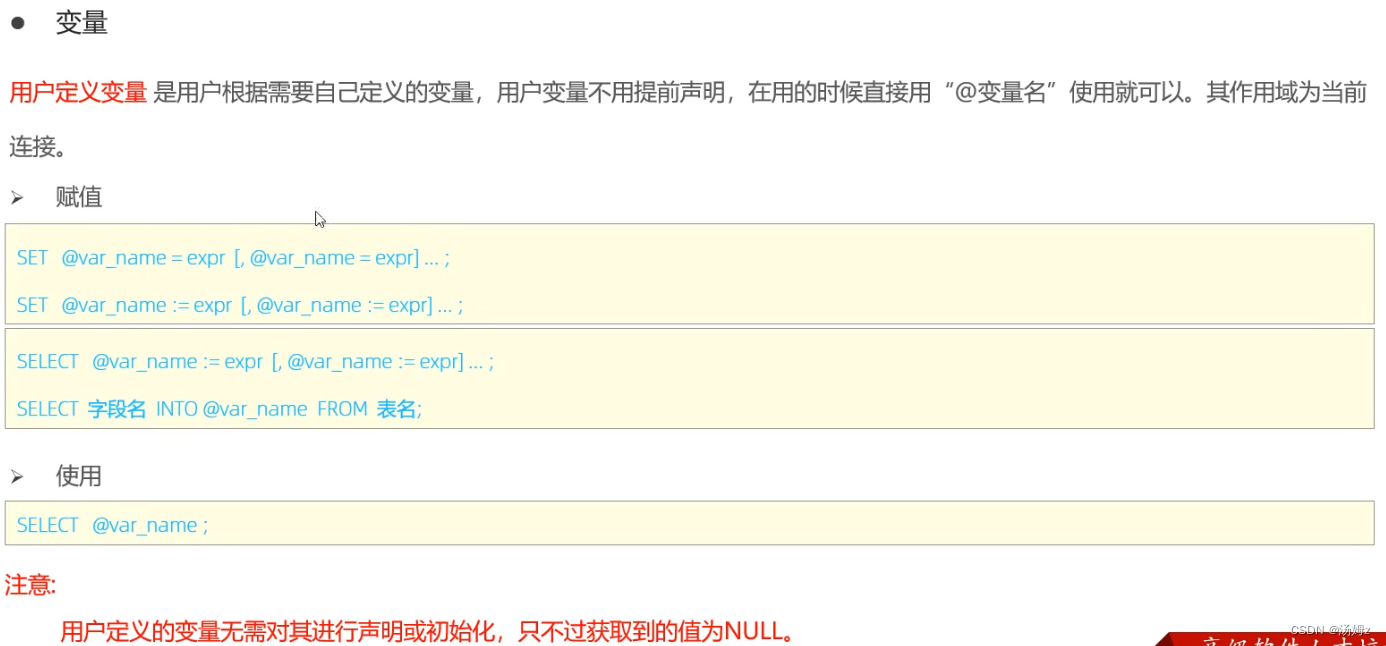
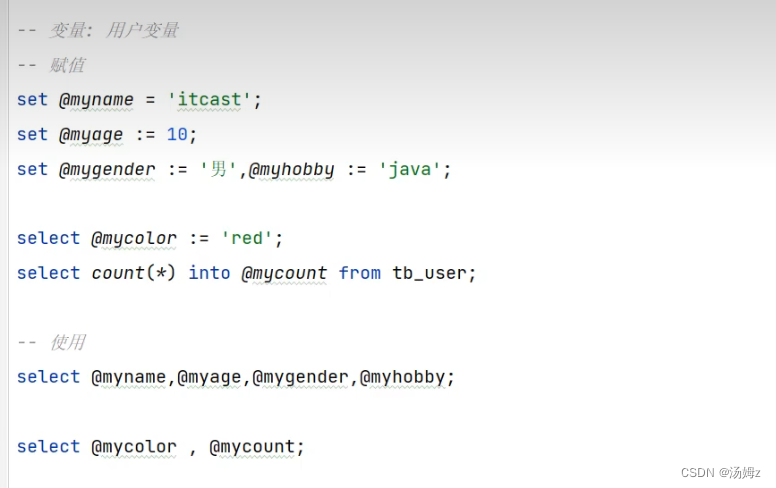
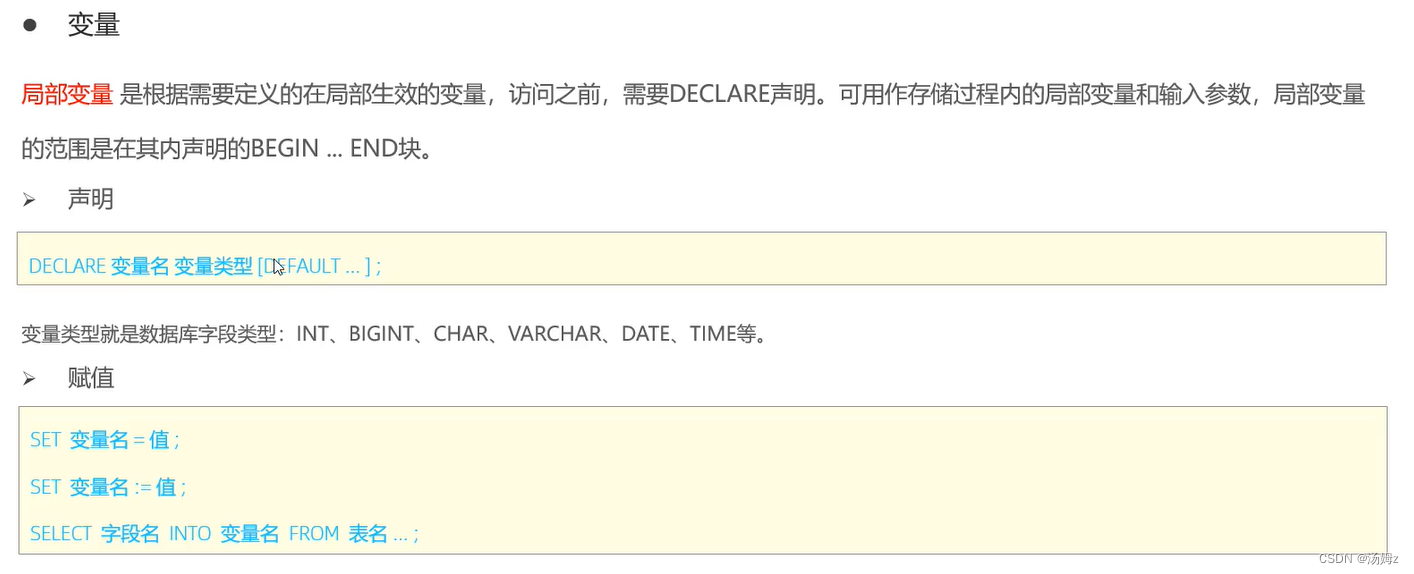
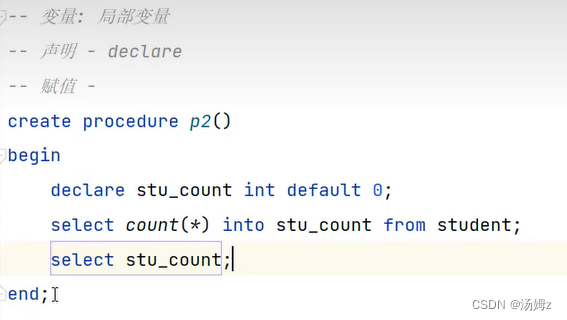


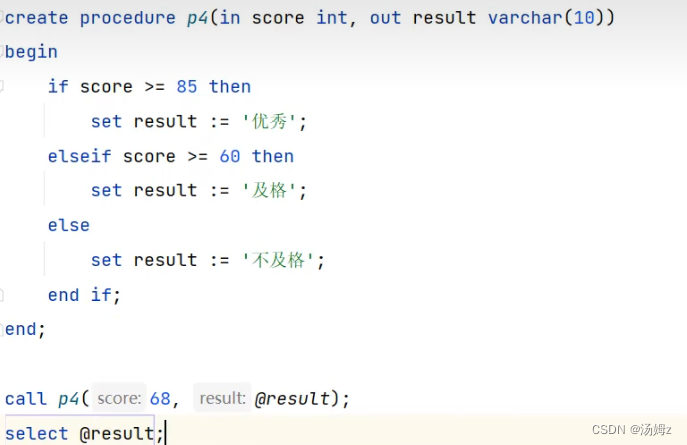 PS:有begin end的才用局部变量,否则就是用户自定义变量
PS:有begin end的才用局部变量,否则就是用户自定义变量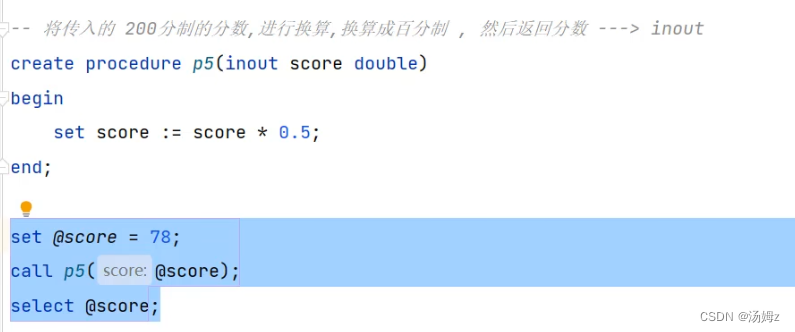
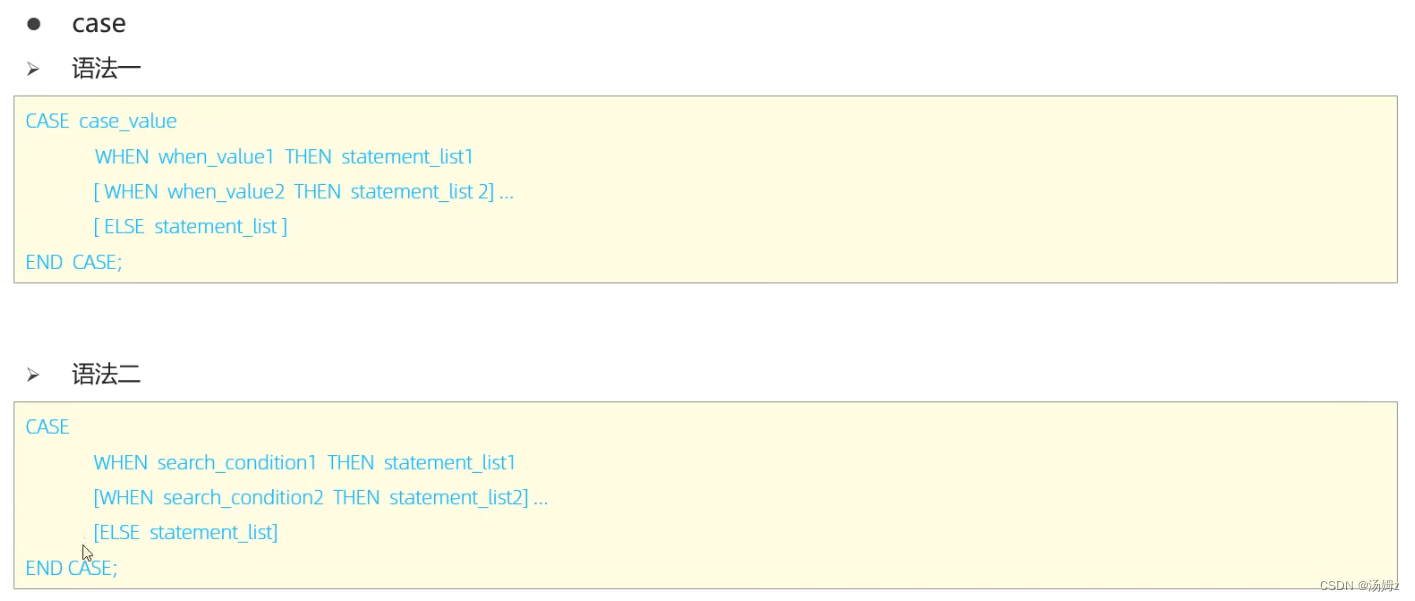
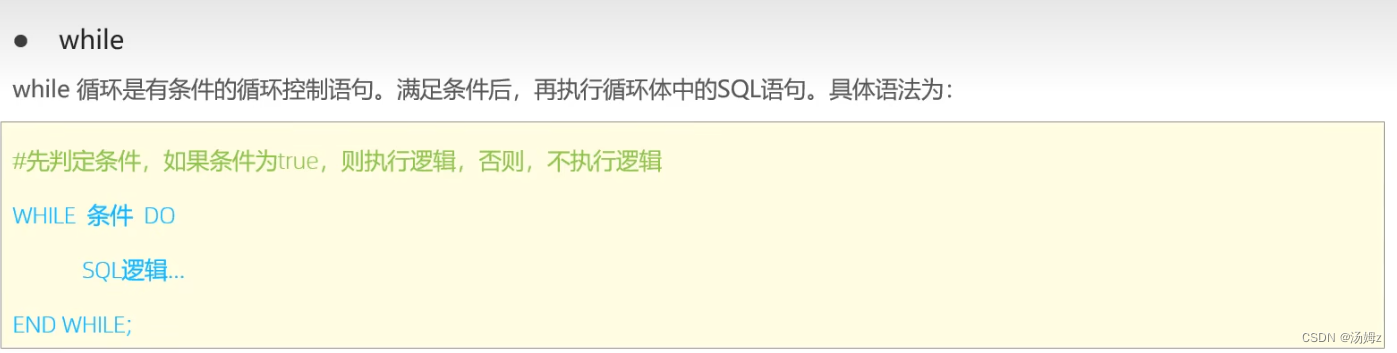
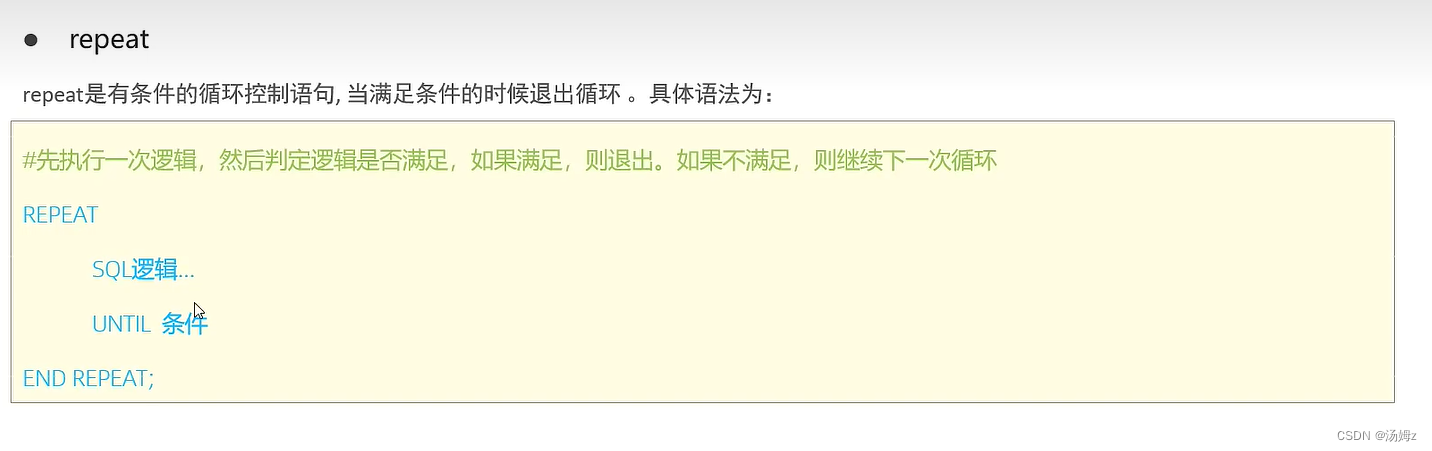

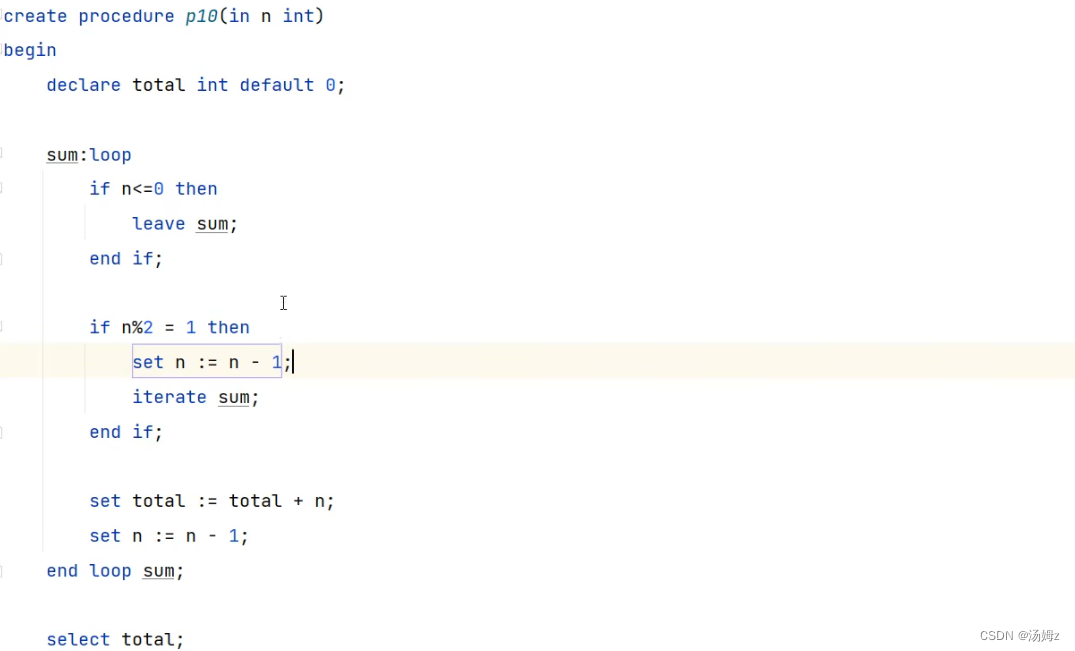 PS:累加偶数
PS:累加偶数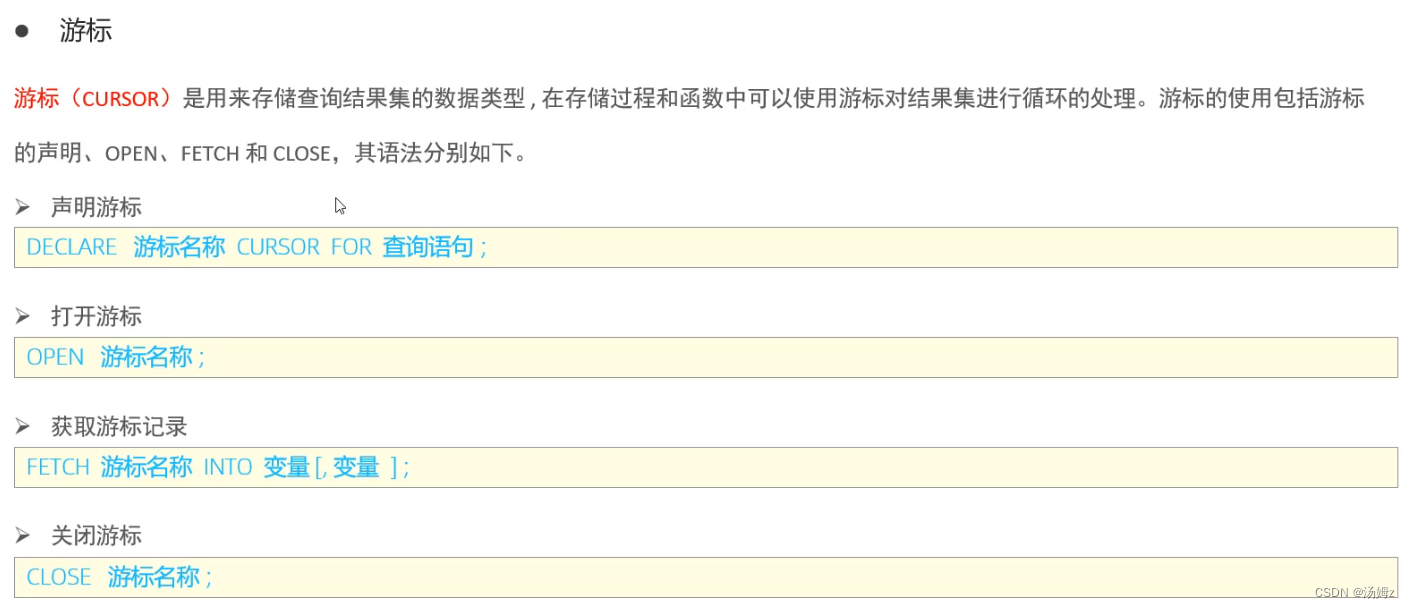
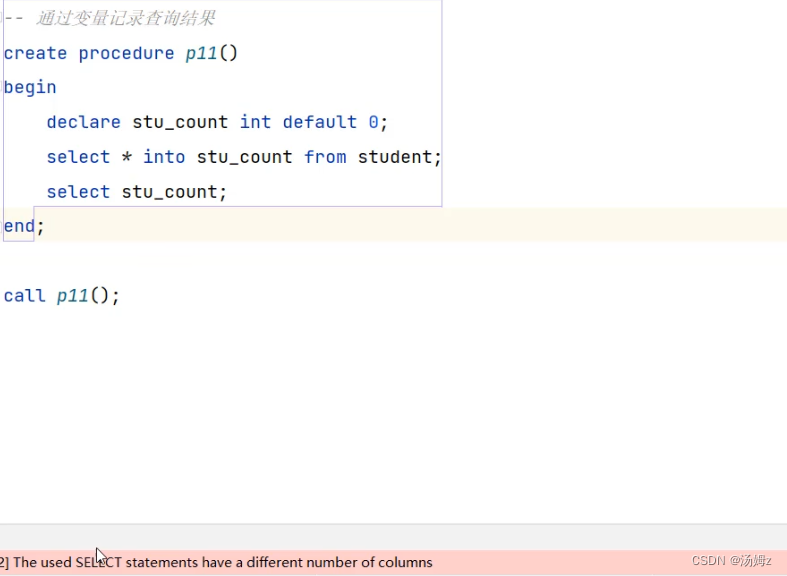
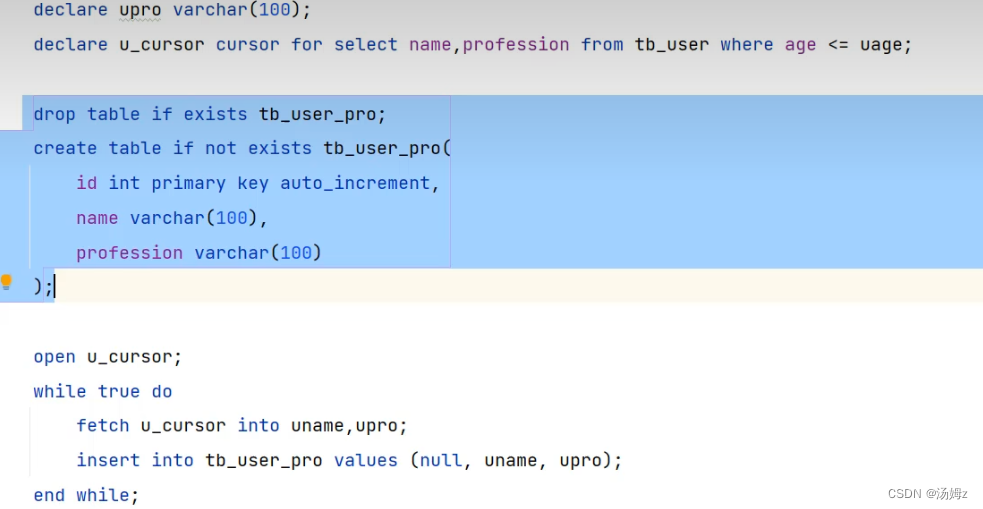
PS:要先声明局部变量再声明游标,那么如何结束循环?看下面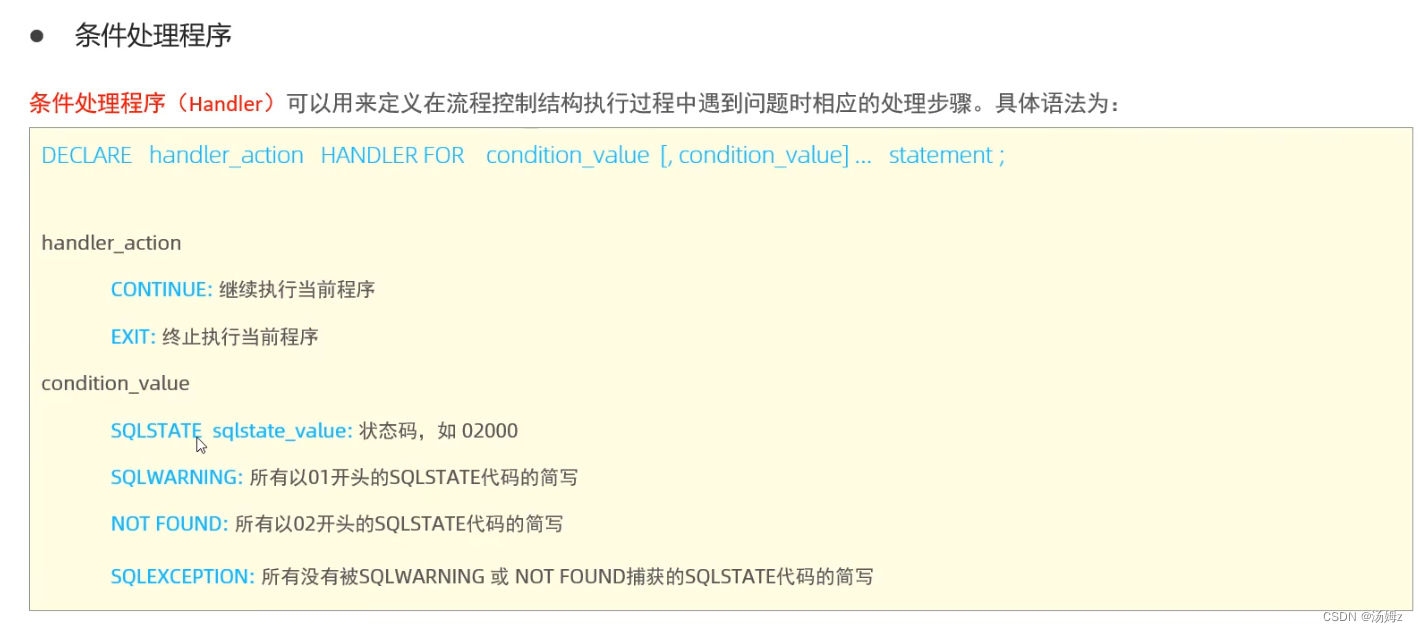



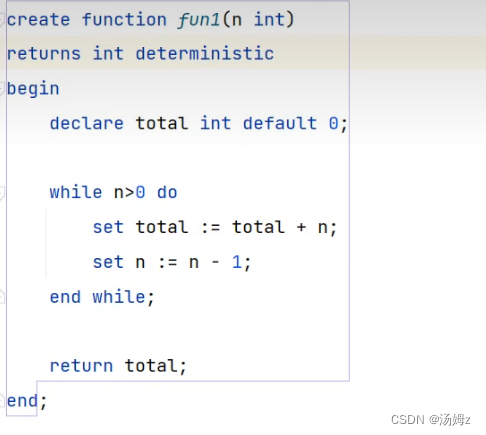

PS:用的比较少,因为存储函数能完成的存储过程都能完成,并且存储函数强制必须有返回值,这是弊端
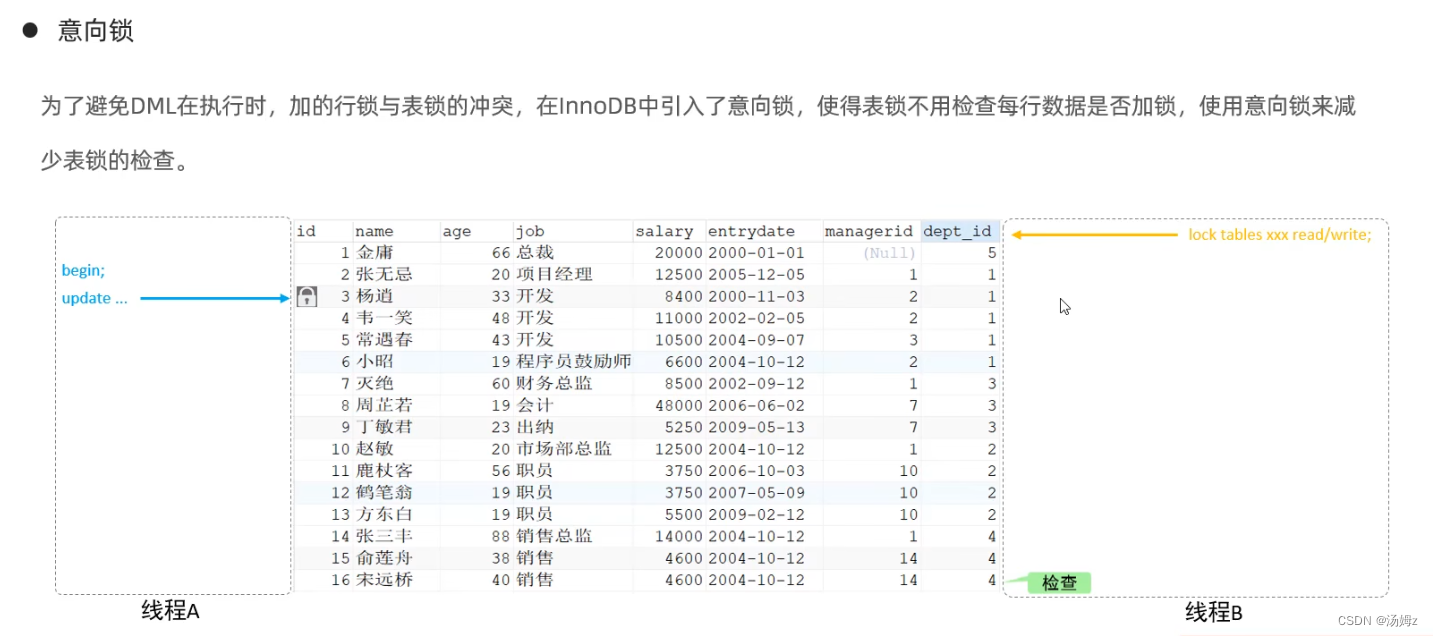
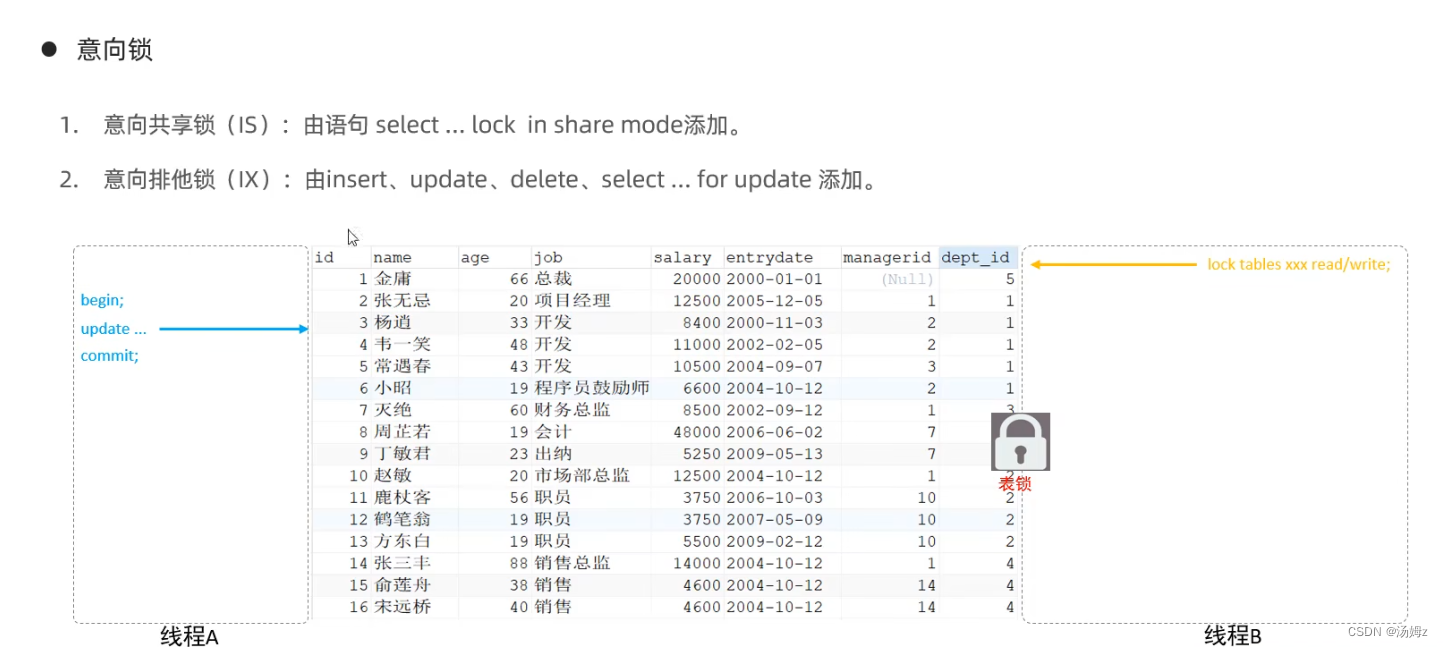

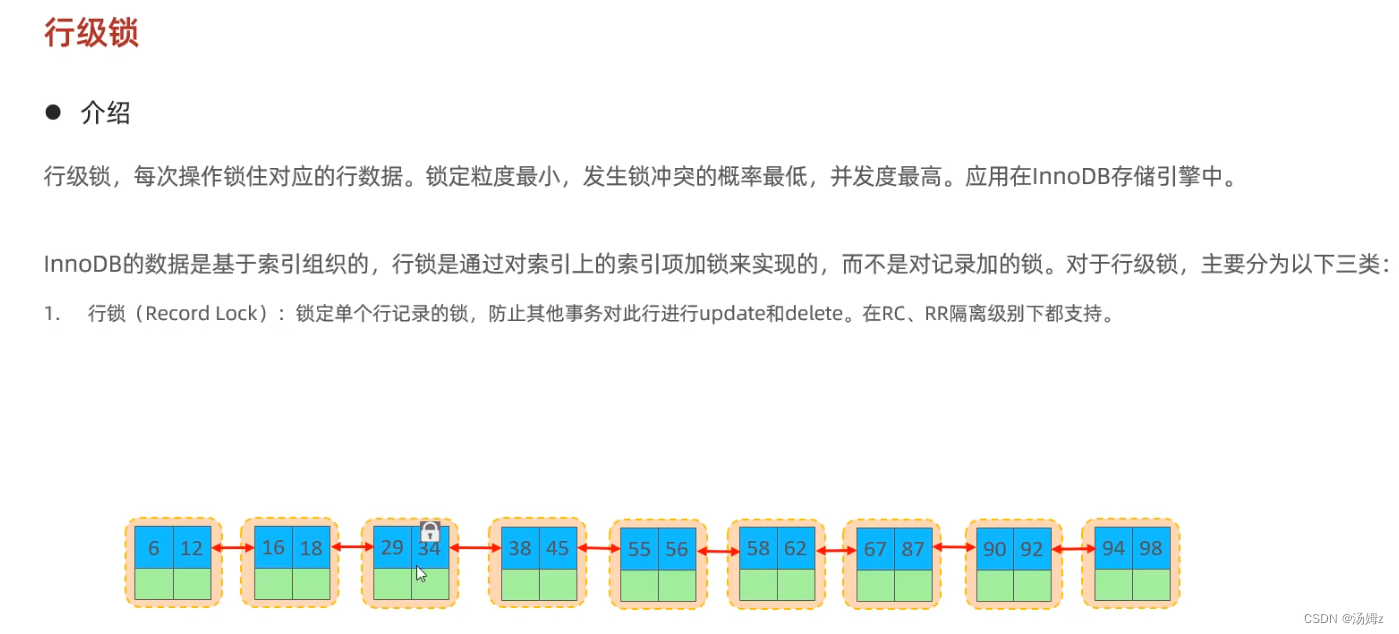
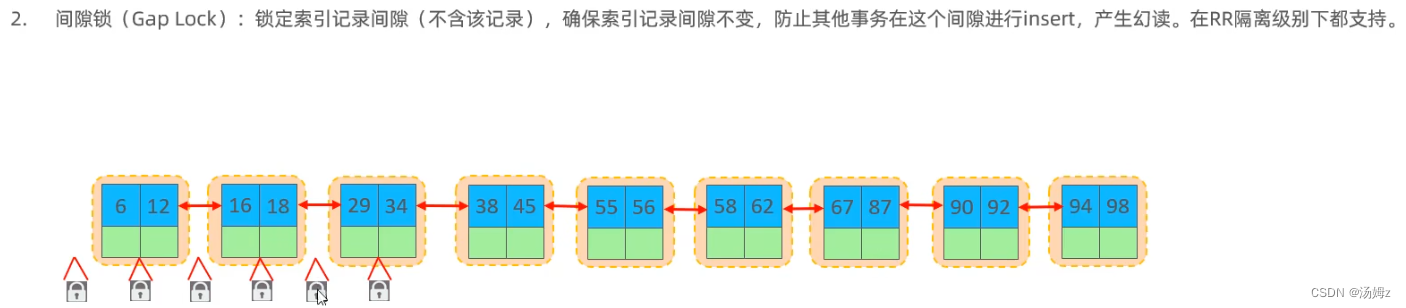
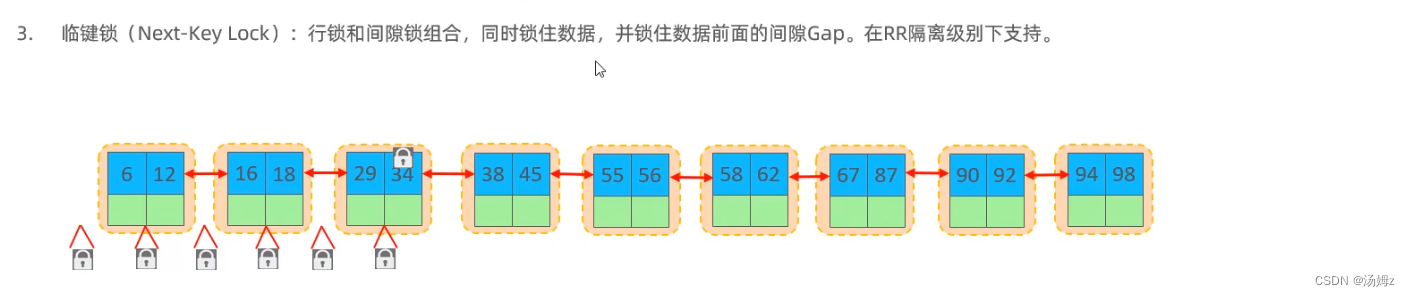




 INNODB引擎
INNODB引擎Mysql管理
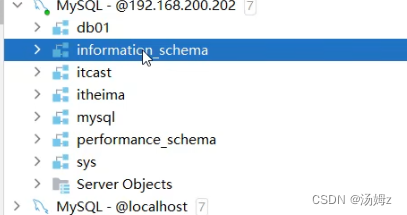
自带四个数据库

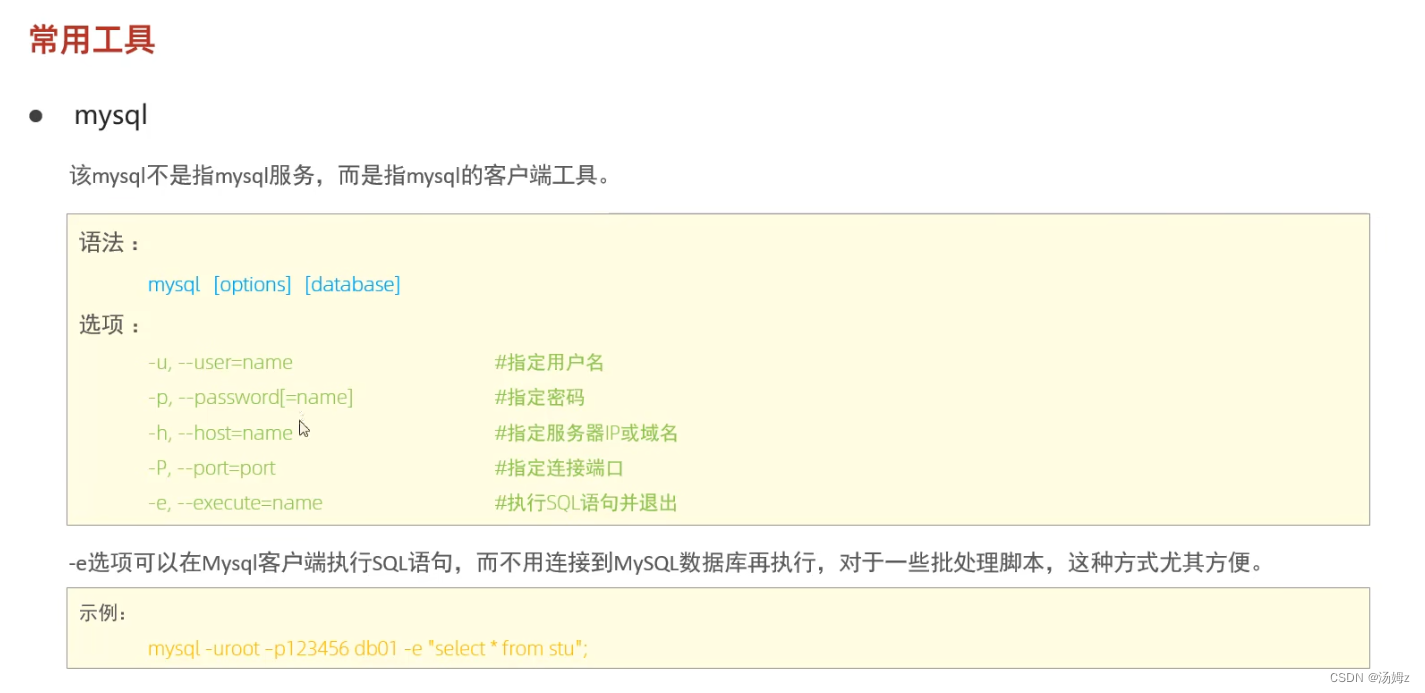
运维阶段
-
相关阅读:
在 IconFont 上获取图标资源的操作方法与感悟
vite工具官方地址 +前端工具插件
Linux学习笔记——系统文件与目录操作函数
《MongoDB入门教程》第12篇 查询结果排序
Docker创建Spring容器【方便服务迁移】
ES6模块
Unity3d C#使用Screen.SetResolution设置无效的问题(问题在于Screen.width、Screen.height)
计算模型参数量的方法
神经网络控制simulink仿真,神经网络控制系统仿真
手写 Vue 系列 之 Vue1.x
- 原文地址:https://blog.csdn.net/nalidour/article/details/126141099