-
Linux编译器:gcc/g++的使用
我们在学习编译器时,我们不仅要只会使用编译器,还要理解程序的编译过程。一个程序存在两个不同的环境。第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令;第2种是执行环境,它用于实际执行代码。本篇文章将在讲解程序的翻译过程中来介绍gcc/g++的使用。
目录
程序的翻译过程:
- 预处理(进行宏替换)
- 编译(生成汇编)
- 汇编(生成机器可识别代码)
- 链接(生成可执行文件或库文件)
1.语言的发展以及自举的过程
为什么程序翻译要有怎么多过程,这里通过了解语言的发展以及自举或许可以理解。那么什么是自举呢,就是通过自己的语言实现自己的编译器。那么这时候就有问题:是先有语言还是编译器?我们这里慢慢解释。
最开始,计算机只能识别二进制,我们要向计算机传递信息时,只能通过穿孔纸带让CPU识别,也就是最初的第一代语言:机器语言。

但是于这种语言人类很难理解,为了更好的与计算机进行沟通,发展出了第二代语言:汇编语言,用助记符代替了操作码,用地址符号或标号代替地址码,这样就用符号代替了机器语言的二进制码。使用符号代替二进制码进行相关操作。
这里就可以使用汇编代码写软件了,但是既然可以使用汇编语言写软件,也就可以使用汇编语言写汇编语言的编译器,这里就实现了汇编语言的自举。很明显这里可得:是先规划的语言,再通过语言写的编译器。
后来人们认为汇编语言还是复杂,于是就发展有了第三代语言:高级语言C语言,是一种接近于人们使用习惯的程序设计语言。同汇编语言相同,所以高级语言也可以实现自举,但是这里就有一个问题了:高级语言是先将代码转换为汇编代码,再转换为二进制让机器识别,还是直接转换为二进制让机器识别?
首先我们要知道语言发展的每一步都是经历过很多困难的,二进制重写高级语言与汇编语言重写高级语言相比无疑是比较困难的,所以说用汇编代码写高级语言是更加合适的。
这里就可以理解为什么程序翻译过程中要有编译(生成汇编)和汇编(生成机器可识别代码)的过程了。理解这里之后我们继续讲解。
2. gcc如果完成各个翻译过程
格式 gcc [选项] 要编译的文件 [选项] [目标文件]
2.1 预处理(进行宏替换)
- 预处理功能主要包括替换宏定义,文件包含(拷贝),条件编译,去注释等。
- 预处理指令是以#号开头的代码行。
- 实例: gcc –E hello.c –o hello.i
- 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
- 选项“-o”是指定目标文件,“.i”文件为已经过预处理的C原始程序

通过vim编译code1.c文件,然后用 gcc 编译code1.c,如果这里没有加选项 -E,会将程序的翻译过程全部进行完,-E 就是让 gcc 预处理完就停下来,如果不加 -o 会将文件预处理完的内容直接打印到屏幕上。
这里可以用vs指令查看多个文件:
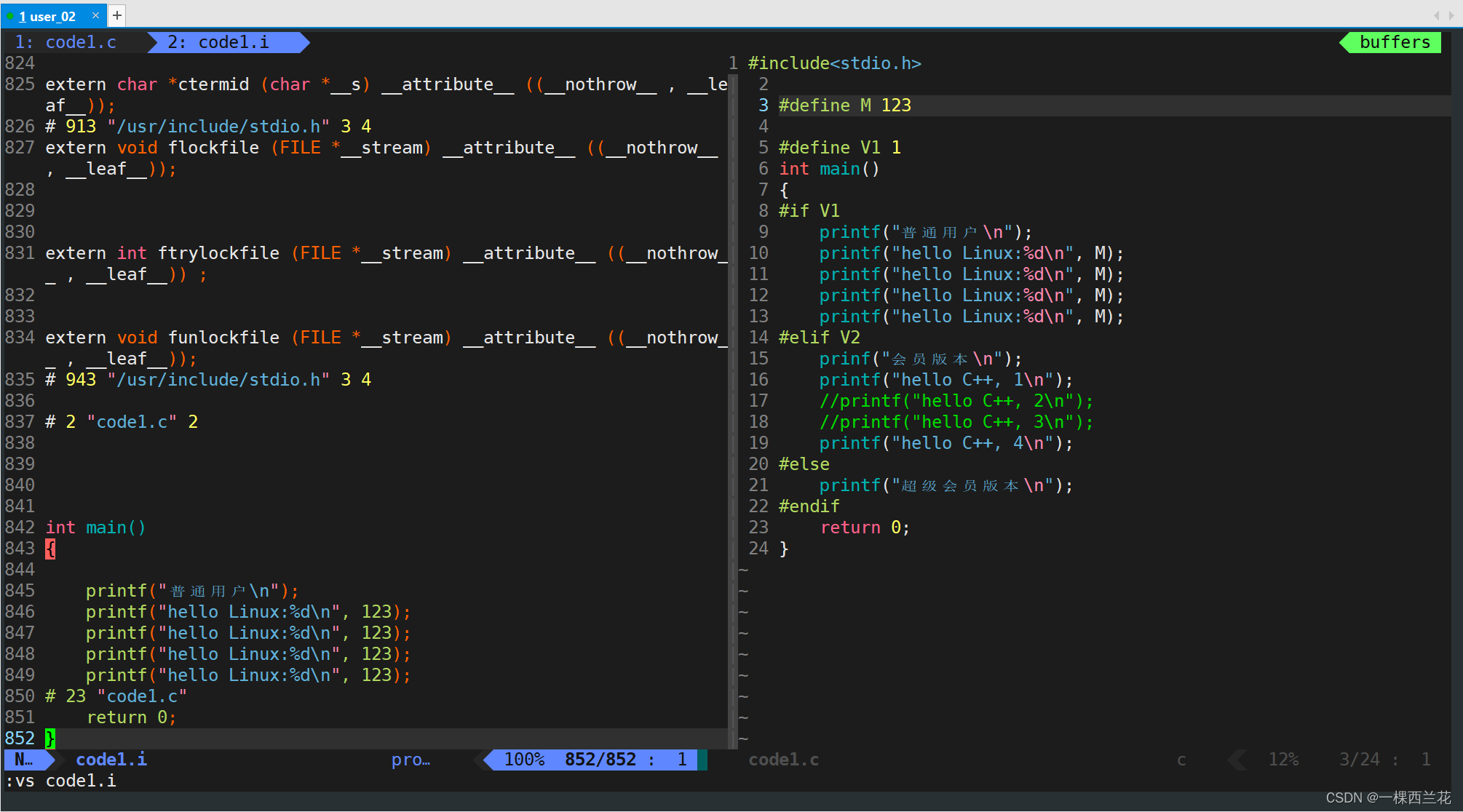
可以发现这里预处理后的 .i 文件比 .c 源文件多出了八百多行,多出的主要是包含头文件,也就是把 stdio.h 的内容拷贝了过来。还通过条件编译,实现了对代码的动态裁剪。宏常量M也被替换,注释也被去除。
这里条件编译就可以理解很多软件有免费版本和收费版本,但只需要维护一份代码。
2.2 编译(生成汇编)
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
- 用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
- 实例: gcc –S code.i –o code.s

这里也可以直接通过gcc -S .c 文件,-S让文件翻译到编译结束后就停下来。
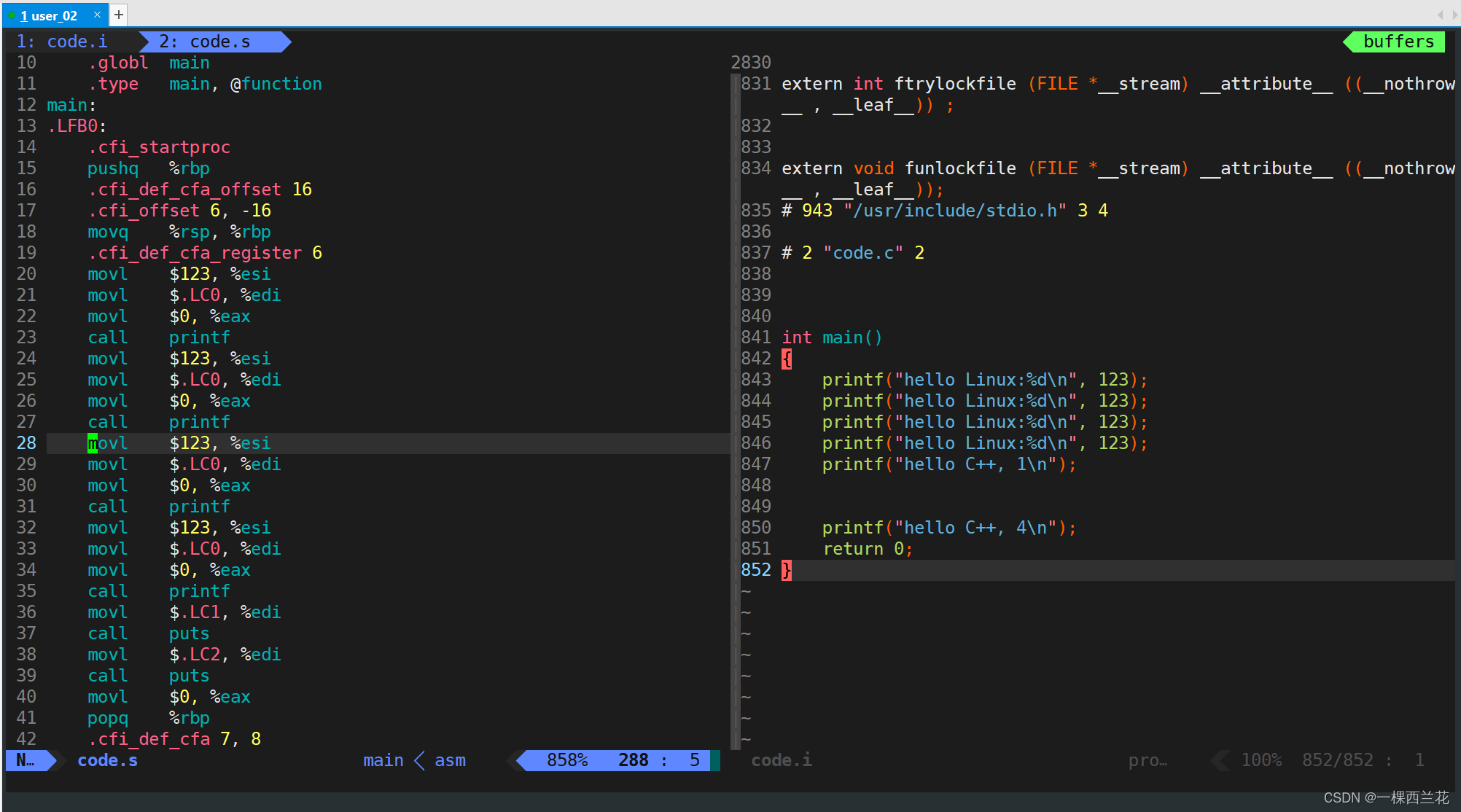
可以发现 .s 文件内部已经生成了汇编代码。
2.3 汇编(生成机器可识别代码)
- 汇编阶段是把编译阶段生成的“.s”文件转成目标文件
- 读者在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了
- 实例: gcc –c code.s –o code.o
-c 就是将文件翻译进行到汇编结束后就停下来,这里生成 .o 目标文件

通过vim打开文件,可以发现已经生成了我们看不懂的可重定位二进制文件。
可以使用od命令查看二进制文件,但也是看不懂的
gcc 指令记忆 -ESc ,与键盘上的退出键相同,但要注意大小写。
生成文件的后缀 -iso
2.4 链接(生成可执行文件或库文件)
- 多个可重定位文件(二进制文件)合并成一个可执行文件,进行符号解析和重定位
- 实例: gcc code.o –o code,这里gcc不加指令即可直接生成可执行程序。
在当先文件目录下是,直接 ./文件名 即可执行。因为执行一个程序需要找到它的位置,这里是相对路径,. 代表当前目录。
可执行文件是由我们的代码+头文件+库组成的,这里就涉及到库的知识,我们下面讲解:
- 我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实“printf”函数的呢?
- 最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”了,而这也就是链接的作用。lib表示是库文件,.so表示动态库,.6是版本号,所以这个库的名字是c,即c标准库。
2.4.1 函数库一般分为静态库和动态库两种
- 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
- 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销,所谓的动态链接,就是把要链接库中的函数地址拷贝到我们可执行程序的特定位置。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。 gcc code.o –o code
- gcc默认生成的二进制程序,是动态链接的。
- Windows下静态库后缀.lib,动态库后缀.dll
2.4.2 动态链接与静态链接
动态链接优缺点:
- 优点:形成的可执行程序体积比较小,比较节省资源的
- 缺点∶稍慢一些,强依赖动态库,动态库没了,所有的依赖这个库的程序都无法运行了
静态链接优缺点︰
- 优点:无视库,可以独立运行
- 缺点:体积太大,浪费资源
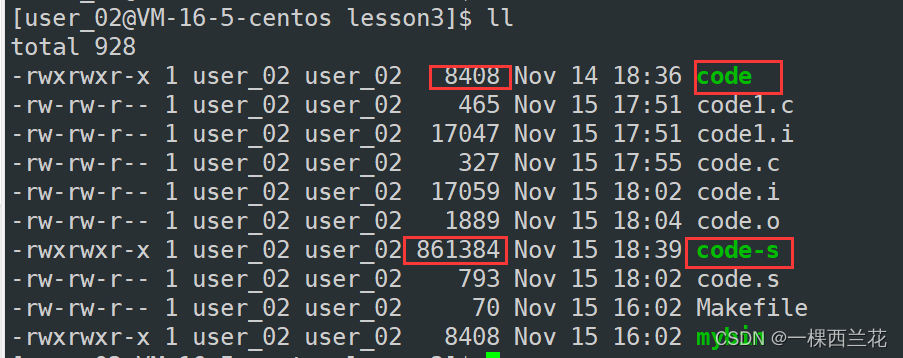
ldd指令查看可执行程序所依赖的库。gcc 后加-static 可以链接静态库

下面可以发现静态链接比动态链接生成的可执行程序体积要大很多。
默认情况下,云服务器是没有安装c静态库的,只有动态库,安装方法:
- C语言静态库:sudo yum install glibc-static
- C++的静态库: sudo yum install -y libstdc++-static
g++ 可以编译C语言和C++,但是gcc只能编译C语言,其他操作是类似的。
本篇结束!

-
相关阅读:
【mysql】mysql数据库出现Communications link failure
python造测试数据存到excel
SLAM程序Linux版第一节
yocs_velocity_smoother速度平滑库知识
搭建react项目
jQuery来了--效果--隐藏和显示,淡入淡出,滑动
经典OJ题:环形节点是否存在!
77. 组合
【2023提前批 之 面经】~ 联发科
Nginx一网打尽:动静分离、压缩、缓存、黑白名单、跨域、高可用、性能优化
- 原文地址:https://blog.csdn.net/qq_72916130/article/details/134423301