-
MySQL
MySQL和SQL的区别是什么?之间是什么关系?
SQL(Structured Query Language)是用于管理和操作关系型数据库(RDBMS)的标准语言。SQL还可以用于这些RDBMS:MySQL、Oracle、Microsoft SQL Server、PostgreSQL。
而MySQL则是一种实现了SQL标准的关系型数据库管理系统。换句话说,MySQL是实现了SQL功能的软件,而SQL则是用于与这种软件进行交互的标准化语言。
MySQL处理数据量5千万条的数据,下性能更好。
MySQL下载地址
安装包:MySQL :: Download MySQL Installer
MySQL中的注释怎么写?
- -- 这是一个单行注释
- /*
- 这是一个多行注释,可以跨越多行
- 在这里你可以写入更多的注释内容
- */
-- 从products这个表格中把prod_name这一列取出来
-- 每个SQL语句结尾都要加一个分号- SELECT prod_name FROM products;
-- 取出数据,按照某一列(prod_name),升序排列ASC
SELECT prod_name FROM products ORDER BY prod_name ASC;-- 降序排列DESC
SELECT prod_name FROM products ORDER BY prod_name DESC;-- 取出多列。列名之间加个逗号即可
SELECT prod_id, prod_price, prod_name FROM products ORDER BY prod_price DESC;-- 在前面那个排序基础上,再增加一个排序条件。
-- 适用于在前面那个排序基础上,有些行的prod_price完全一样,我希望再用prod_name对这些前一个条件一样行按照后面那个条件再排序
-- 只需要在后面写上第二个条件的列名 和升降序- SELECT prod_id, prod_price, prod_name FROM products ORDER
- BY prod_price DESC, prod_name ASC;
-- 不想升降序,就把DESC和ASC这两个东西删掉-- ORDER BY与LIMIT组合选择符合条件的前n行
SELECT prod_price FROM products ORDER BY prod_price DESC LIMIT 10; -- 前10个取第10行开始到第18行
SELECT prod_name FROM products LIMIT 10,18;只取出这一列中不重复的数据
取出这一列的列名是vend_id
SELECT DISTINCT vend_id FROM products;数据汇总,算avg, min, max等统计指标
从products这个数据表中把prod_price取出,并计算出prod_price的平均值,返回出来
SELECT AVG(prod_price) FROM products如果你想把取出的这一列 换个其他的列名 可以用AS
SELECT AVG(prod_price) AS avg_price FROM products统计出数据集有多少行
- -- * 表示所有的数据
- SELECT COUNT(*) AS num_cust FROM customers;
统计出某一列 中 非空的行 的 行数
注意空的行,不算进去
SELECT COUNT(cust_email) AS num_cust FROM customers;取某一列的最大的那一条数据
- SELECT MAX(prod_price) AS max_price FROM products;
- -- 提取出来这一列的列名是max_price
最小的
SELECT MIN(prod_price) AS min_price FROM products;注意上面算的这些最大最小,是不把空值的内容纳入对比比较 的范围。
设定条件,只统计order_num为20005的订单号的商品,总共卖出去的商品数量quantity
用WHERE去筛选出订单号是不是20005
SELECT SUM(quantity) AS item_ordered FROM orderitems WHERE order_num = 20005如果想要取出的数据是 价格×销量,可以这样写
- SELECT SUM(quantity * item_price) AS total_price FROM orderitems
- WHERE order_num = 20005
计算prod_price的平均值,但是这个要只用非重复的价格来计算
SELECT AVG(DISTINCT prod_price) AS avg_price FROM products WHERE vend_id = 1003将前面这个 min max avg 等等统计量组合成多列
- SELECT COUNT(*) AS num_items,
- MIN(prod_price) AS price_min,
- MAX(prod_price) AS price_max.
- AVG(prod_price) AS price_avg,
- FROM products;
WHERE GROUP BY数据按照条件过滤
WHERE里面的条件不等于即可以写!=,
SELECT prod_name, prod_price FROM products WHERE prod_price != 2.50也可以写 <>
SELECT prod_name, prod_price FROM products WHERE prod_price <> 2.50大于5,小于10这种,就不能用大于和小于符号了。要用BETWEEN AND。这个两段的5和10 都是取到的,大于等于5 和小于等于10
SELECT prod_name, prod_price FROM products WHERE prod_price BETWEEN 5 AND 10;用WHERE把prod_name中 为字符串“fuses”的取出来
SELECT prod_name, prod_price FROM products WHERE prod_name = "fuse";把空的列 的 列名取出来
IS NULL 表示为空
SELECT cust_name FROM customers WHERE cust_email IS NULL;WHERE多个条件进行匹配,
同时满足用AND,
vend_id为1003,prod_price价格小于10
- SELECT prod_id, prod_price, prod_name FROM
- products WHERE vend_id = 1003 AND prod_price <= 10;
其中一个满足即可用OR
- SELECT prod_id, prod_name,prod_price, vend_id
- FROM products WHERE vend_id = 1003 OR prod_price <= 10;
如果你是很多个值OR,你不想写多少个OR。你可以用IN(所有想囊括的东西)
SELECT prod_name, prod_id, prod_price FROM products WHERE vend_id IN (1002,1003);指定不是这几个
SELECT prod_id, prod_name,prod_price FROM products WHERE vend_id NOT IN (1002,1003)分组,输出每个组元素的个数
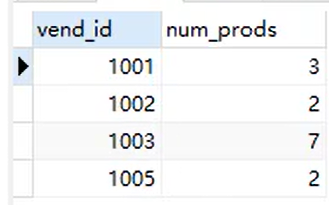
这里vend_id相同的就会被归类为一组。数出每一组数据的个数命名为num_prods这一列
vend_id这一列也取出来了
- SELECT vend_id, COUNT(*) as num_prods
- FROM products
- GROUP BY vend_id;
刚刚那个表,我希望将 num_prods数量大于等于3的筛选出来
用HAVING去写额外的条件
- SELECT vend_id, COUNT(*) AS num_prods
- FROM products
- GROUP BY vend_id
- HAVING COUNT(*) >= 3
JOIN多张表的联结,从多张表取数据
WHERE...AND...
同时从两张表上取数据
从vendors和products 这两张表上取数据 合并成一张表。合并的条件是 二者的vend_id这一列相同
- SELECT vend_name, prod_name, prod_price
- FROM vendors, poducts
- WHERE vendors.vend_id = products.vend_id;
vend_id相同的表格,提取的下面三列是这样

创建条件,联结多个表
将三个表中 vend_id相等、prod_id相等 ,且order_num 为20005的 四列取出来
- SELECT prod_name, vend_name, prod_price, quantity
- FROM
- orderitems, products, vendors
- WHERE
- products.vend_id = vendors.vend_id
- AND
- orderitems.prod_id = products.prod_Id
- AND
- order_num = 20005;

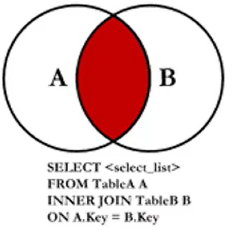
内部联结
INNER JOIN
INNER JOIN 取两个集合的交集
现在这段代码实际就是在取vendors和products这两个集合的交集。“交”体现在取vendors和products这两个集合中 符合 vend_id相同的那一部分
- SELECT vend_name, prod_name, prod_price
- FROM vendors, products
- WHERE vendors.vend_id = products.vend_id;
实际上上面这段取交集的代码,有下面这个更简便的写法
- SELECT vend_name, prod_name, prod_price
- FROM vendors INNER JOIN products
- ON vendors.vend_id = products.vend_id;
FROM写表格出处的时候,两个表格,vendors和products使用INNER JOIN来连接
交集的条件写在ON之后,是vendor和products的vend_id相同
INNER JOIN这个交集,画图表示就是下面
LEFT JOIN
而LEFT JOIN就像下面这个图表示的这样,LEFT JOIN左边的集合A全都取,写在右边的集合,只取A和B的交集,除去这个交集,B的任何东西都不取

代码是下面这样,把INNER JOIN替换成LEFT JOIN即可
- SELECT vend_name, prod_name, prod_price
- FROM vendors LEFT JOIN products
- ON vendors.vend_id = products.vend_id;
下面这个是查询出的表格。空的这两行就是vendors这个表格里面有,products这个表格所没有的。其他那些非空的就是vendors和products 的交集。

RIGHT JOIN
只取右边的,右边的所有都取,左边的只取A和B的交集,左边其他的东西都不取
其实直接SELECT B 不是更好?哈哈哈哈哈哈
代码如下,就是把LEFT JOIN替换成RIGHT JOIN
- SELECT vend_name, prod_name, prod_price
- FROM vendors RIGHT JOIN products
- ON vendors.vend_id = products.vend_id;

数据新增、插入
按照现有数据表的列名,把新增的这一行,每一列的数据都填入
表格有8列,你就必须填进去8个值,缺一个也不行
在SQL里空值用大写的NULL表示
INSERT INTO表示向里面插入,VALUESB表示插入的值是后面那些
- INSERT INTO customers
- VALUES(NULL,
- 'Pep E. LaPew',
- '100 Main Street',
- 'Los Angeles',
- 'CA',
- '90046',
- 'USA',
- NULL,
- NULL);
插入成功是这样
如果你想在插入值的过程里,指定每一个插入的数据填进去哪些值,可以用在VALUES前面,customers这个表明后面加个括号,括号里面写列名
每一个后面的字符串或者数字,对应填入 前面那个的位置的表头对应的列名
- INSERT INTO customers(cust_name,
- cust_address,
- cust_city,
- cust_state,
- cust_zip,
- cust_country,
- cust_contact,
- cust_email)
- VALUES( 'Pep E. LaPew2',
- '100 Main Street',
- 'Los Angeles',
- 'CA',
- '90046',
- 'USA',
- NULL,
- NULL);
如果你某些列是空的,你可以在指定列名的时候直接不去填写这些缺失的列的列名。SQL就会默认给这些列分配一个NULL值
比如上面那个cust_contact和cust_email这两列,新添加进去的值为NULL。下面就演示一下,不写列名,也不写填充值为空,让系统自动填充的功能。
- INSERT INTO customers(cust_name,
- cust_address,
- cust_city,
- cust_state,
- cust_zip,
- cust_country,
- )
- VALUES('Pep E. LaPew2',
- '100 Main Street',
- 'Los Angeles',
- 'CA',
- '90046',
- 'USA');
新增数据的时候把列名也写进去的好处是,你可以自由的安排列名之间的顺序,然后按照你设定的顺序来输入每一列对应的数据。这样数据的录入更加清楚你输进去的每个数字对应哪个维度新增的数据。
比如下面我在写列名的时候就调转了cust_address和cust_name的顺序,录入数据的时候 两个数据的位置也调转了。但是录进去,cust_address还是对应'100 Main Street', cust_name还是对应'Pep E. LaPew3'
- INSERT INTO customers(
- cust_address,
- cust_name,
- cust_city,
- cust_state,
- cust_zip,
- cust_country,
- )
- VALUES(
- '100 Main Street',
- 'Pep E. LaPews',
- 'Los Angeles',
- 'CA',
- '90046',
- 'USA');
同一套列名,刚才是插入一条数据,如果插入多条数据呢?
VALUES,前一个数据括号后面加个逗号 ,一个新的括号,录入数据
- INSERT INTO customers(
- cust_address,
- cust_name,
- cust_city,
- cust_state,
- cust_zip,
- cust_country,
- )
- VALUES(
- '100 Main Street',
- 'Pep E. LaPews',
- 'Los Angeles',
- 'CA',
- '90046',
- 'USA'),
- (
- 'M. Martian',
- '42 Galaxy',
- 'New York',
- 'NY',
- '11213',
- 'USA'
- );
数据更新UPDATE
把某一行的某一列的值替换成其他的值
UPDATE关键字打头,SET后面写你要修改的列的名字,等于号后面写被修改替换成的数据内容, Where后面写条件限制是哪几行
- UPDATE customers
- SET cust_email = 'R_U_OK@hsbc.com'
- WHERE cust_id = 10005;
也可以同时更改同一行的多列数据
- UPDATE customers
- SET cust_name = 'A piece of Shit'
- cust_email = 'King_of_SB@icbc.com'
- WHERE cust_id = 10005;
数据删除
注意使用UPDATE和DELETE的同时一定要加WHERE限制条件,否则会删除整个表格或者将整个表格的数据都修改了
将用户id为10006的行都删掉
- DELETE FROM customers
- WHERE cust_id = 10006;
其他
Redis 是一个开源的,高性能的 key-value 系统,可以用来缓存或存储数据。Redis数据库不是关系型数据库
SQL是关系型数据库。关系型数据库,是指采用了关系模型来组织数据的数据库。简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
-
相关阅读:
虚拟ip、浮动ip
CenterNet算法by bilibili
第一章计算机网络
初试小程序轮播组件
Mybatis练习(多条件查询)
android studio 编译Telegram源码经验总结(2023-11-05)
8李沐动手学深度学习v2/逻辑回归(softmax回归(分类))从0开始实现
使用pytorch进行FFT和STFT
基于ArcGIS的Python数据处理、空间分析和可视化
LAMMPS 报错Temperature compute degrees of freedom < 0
- 原文地址:https://blog.csdn.net/Albert233333/article/details/134274819
