-
8李沐动手学深度学习v2/逻辑回归(softmax回归(分类))从0开始实现
总结:
- softmax做预测输出
- 交叉熵做损失函数
- 多类别,一个样本属于每个类别的概率
- python中张量乘法都是对应位置元素相乘
- 数据 模型 超参数 参数 损失函数 优化算法 开始训练
- 梯度:谁要计算梯度requires.grad;不计算梯度detach()当前结点移出计算图;不计算梯度with torch.no_grad();清空梯度 param.grad.zero() updater.zero_grad()
- 梯度:没有对要求计算梯度的变量运算时,不用关心这个变量的梯度
- 求和不会影响求偏导结果
l.sum().backward() - 训练图示 更加关心测试精度
import torch from IPython import display from d2l import torch as d2l batch_size=256 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)- 1
- 2
- 3
- 4
- 5
- 6
# softmax回归需要input是向量将1*28*28=784的图片拉长为784的向量 # 数据集有10个类别所以网络输出维度=10 num_inputs=784 num_outputs=10 # size,因为是向量元素相乘所以是这个size。inputShape=(784*1),WShape=(784*10) # W的shape如何确定,两层之间的连线有多少条 W=torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True) # X=[...,1] W=[...,bi] # b的shape如何确定,b是W的最下面一行,下一层结点个数 b=torch.zeros(num_outputs,requires_grad=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# 补充,矩阵按照某个轴求和 X=torch.tensor([[1.0,2.0,3.0],[4.0,5.0,6.0]]) # 原sum对某个轴求和这个轴就消失 print(X.sum(0,keepdim=True)) print(X.sum(1,keepdim=True))- 1
- 2
- 3
- 4
- 5
tensor([[5., 7., 9.]]) tensor([[ 6.], [15.]])- 1
- 2
- 3
实现 s o f t m a x ( X i j ) = X i j ∑ k e x p ( X i k ) \rm{softmax}(\boldsymbol{\rm{X}}_{ij})=\frac{\boldsymbol{\rm{X}_{ij}}}{\sum_kexp(\boldsymbol{\rm{X}_{ik}})} softmax(Xij)=∑kexp(Xik)Xij,这里X是向量,X向量对每1个元素做softmax
def softmax(X): ''' :param X,行代表张数,列代表一张图片 :return shape=(张数,28*28=784) ''' # X.shape=(张数,28*28=784) X_exp=torch.exp(X) # partition.shape=(张数,1) partition=X_exp.sum(1,keepdim=True) # 用到了广播机制,复制了partition # X_exp.shape=(张数,28*28=784),广播partition.shape=(张数,784) return X_exp/partition # 测试softmax X=torch.normal(0,0.01,(2,5)) X_prob=softmax(X) print(X_prob) # 行和为1 print(X_prob.sum(1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
tensor([[0.1993, 0.2022, 0.1992, 0.1978, 0.2015], [0.2014, 0.2012, 0.1994, 0.1987, 0.1992]]) tensor([1., 1.])- 1
- 2
- 3
模型实现:softmax回归
def net(X): # -1由计算得出结果。X变换维度后shape=(784,张数) # reshape需要传入1个tuple return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W)+b)- 1
- 2
- 3
- 4
# 补充 根据标号获取样本属于某个类别的概率 # 真实值,两个样本第1个样本的标号(属于某个类别的索引)是0,第2个样本的标号是2 y=torch.tensor([0,2]) # softmax预测值,共两个样本,每个样本属于所有类别(有3个类别)的概率 y_hat=torch.tensor([[0.1,0.3,0.6],[0.3,0.2,0.5]]) # y_hat[0][y[0]],y_hat[1][y[1]] y_hat[[0,1],y]- 1
- 2
- 3
- 4
- 5
- 6
- 7
tensor([0.1000, 0.5000])- 1
实现损失函数(交叉熵): l ( y , y ^ ) = − ∑ i y i l o g y i ^ = − l o g y ^ y l(\boldsymbol{\rm{y}},\boldsymbol{\rm{\hat{y}}})=-\sum_i y_ilog\hat{y_i}=-log\hat{y}_y l(y,y^)=−∑iyilogyi^=−logy^y
def cross_entropy(y_hat,y): ''' 交叉熵,吴恩达 二分类损失函数 两个部分是等价的,只不过是2分类所以这样表示 :param y_hat 预测值 第i个样本属于每个类别的概率 :param y 真实值 第i个样本真实类别的索引 ''' # len(y_hat)样本数量 return -torch.log(y_hat[range(len(y_hat)),y]) cross_entropy(y_hat,y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
tensor([2.3026, 0.6931])- 1
比较预测值与真实值,y_hat和y
def accuracy(y_hat,y): ''' :param y_hat.shape=(样本数量,样本属于每个类别的概率) :param y.shape=(样本数量,类别) :return 预测正确的样本数量 ''' # 是多类别问题 if len(y_hat.shape)>1 and y_hat.shape[1]>1: # 取置信度最大的索引 y_hat=y_hat.argmax(axis=1) # 将y_hat的数据类型转为y的数据类型 cmp=y_hat.type(y.dtype)==y # cmp是buool类型,cmp转成y类型 return float(cmp.type(y.dtype).sum()) # 精度=预测正确的样本数量/总样本数量 accuracy(y_hat,y)/len(y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
0.5- 1
指定数据集上模型的精度
def evaluate_accuracy(net,data_iter): ''' 指定数据集上模型的精度 :param net 网络模型 :param data_iter 数据迭代器,获取数据 ''' # net是Module类的实例 if isinstance(net,torch.nn.Module): # 模型设置为评估模式 net.eval() # 累加器,累加 样本预测正确数量 样本总数 # 为什么需要累加?因为数据是一小批量一小批量的来的 metric=Accumulator(2) # for in 迭代器 # 累加 一小批量一小批量的来的数据的精度 for X,y in data_iter: # 累加器累加 每个批量的预测精度和预测样本数量 metric.add(accuracy(net(X),y),y.numel()) # 精度=预测正确的样本数量/总样本数量 return metric[0]/metric[1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
class Accumulator(object): ''' 在n个变量上累加 ''' def __init__(self,n): self.data=[0.0]*n def add(self,*args): ''' :param *args ''' # a来自self.data self.data=[a+float(b) for a,b in zip(self.data,args)] def reset(self): self.data=[0.0]*len(self.data) def __getitem__(self,idx): ''' __代表private ''' return self.data[idx] evaluate_accuracy(net,test_iter)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
0.1442- 1
定义训练模型1个epoch
def train_epoch_ch3(net,train_iter,loss,updater): ''' 训练模型1个epoch :param train_iter 数据 :param net 模型 :param updater 参数 :param loss 损失函数 ''' if isinstance(net,torch.nn.Module): # 告诉pytorch,开始训练,开始隐式计算梯度 net.train() # 累加器,3个基准 metric=Accumulator(3) # 每次获得batch_size数量的样本 for X,y in train_iter: y_hat=net(X) # 1.损失函数 l=loss(y_hat,y) # updater是torch内置优化器的实例 if isinstance(updater,torch.optim.Optimizer): # 2. 梯度归0 updater.zero_grad() # 3. 后向传播,计算梯度 l.backward() # 4. 向前1步,更新参数W和b updater.step() # 损失和,预测正确样本数,样本数量 metric.add(float(l)*len(y),accuracy(y_hat,y),y.size().numel()) else: # updater不是torch内置优化器的实例,l是向量,不求sum将导致“向量对矩阵求导=三维张量” # 求和不会影响求偏导结果 l.sum().backward() # X.shape=(张数,28*28=784),参数更新每一张图片的W和b updater(X.shape[0]) # 损失和,精度,样本数 metric.add(float(l.sum()),accuracy(y_hat,y),y.numel()) # 损失率=损失和/样本总数,精度=预测正确样本数/总样本数 return metric[0]/metric[2],metric[1]/metric[2]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
动画展示训练过程
class Animator: ''' 动画类 动画展示训练过程 ''' def __init__(self, xlabel=None,ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear',yscale='linear', fmts=('-','m--','g--','r:'), nrows=1,ncols=1, figsize=(3.5,2.5)): ''' :param xlabel x轴标签控制 字体大小类型 :param legend 标记 :param xlim x轴范围 :param xscale x轴缩放类型 这里线性缩放 :param fmts 线条样式 :nrows 坐标轴行数 :figsize 画布大小 ''' if legend is None: legend=[] # 使用svg格式展示的更加清晰 d2l.use_svg_display() # 获取画布和轴 self.fig,self.axes=d2l.plt.subplots(nrows,ncols,figsize=figsize) if nrows*ncols==1: self.axes=[self.axes,] # 配置轴 # lambda函数,匿名函数,sum=lambda 入参: 函数体,例子 sum=lambda x,y : x+y # 使用lambda函数捕获参数 self.config_axes=lambda: d2l.set_axes(self.axes[0], xlabel,ylabel, xlim,ylim, xscale,yscale, legend) self.X,self.Y,self.fmts=None,None,fmts def add(self,x,y): ''' 向图中增加数据点 todo ''' if not hasattr(y,'__len__'): y=[y] n=len(y) if not hasattr(x,'__len__'): x=[x]*n if not self.X: self.X=[[] for _ in range(n)] if not self.Y: self.Y=[[] for _ in range(n)] # 1个x对应1个yi for i,(a,b) in enumerate(zip(x,y)): if a is not None and b is not None: self.X[i].append(a) self.Y[i].append(b) # cla()清除当前轴 self.axes[0].cla() for x,y,fmt in zip(self.X,self.Y,self.fmts): self.axes[0].plot(x,y,fmt) self.config_axes() display.display(self.fig) display.clear_output(wait=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
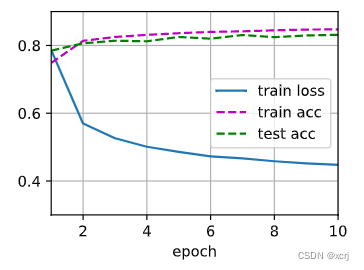
def train_ch3(net,train_iter,test_iter,loss,num_epochs,updater): ''' :train_iter 数据 :test_iter 数据 :net 模型 :num_epochs 超参数 :loss 损失函数 ''' # 实例化用于可视化的Animator(动画片) # xlim x轴范围,ylim y轴范围,legend折线标记, animator=Animator(xlabel='epoch',xlim=[1,num_epochs],ylim=[0.3,0.9],legend=['train loss', 'train acc', 'test acc']) for epoch in range(num_epochs): # 训练1个epoch train_metrics=train_epoch_ch3(net,train_iter,loss,updater) # 在测试集上评估模型 test_acc=evaluate_accuracy(net,test_iter) # 动画显示这个epoch的(损失率=损失和/样本总数,训练精度=预测正确样本数/总样本数,测试精度) # 创建含有1个元素的tuple (test_acc,) # tuple append,tuple+(element,) animator.add(epoch+1,train_metrics+(test_acc,)) train_loss,train_acc=train_metrics # assert train_loss<0.5, train_loss # assert train_acc<=1 and train_acc>0.7, train_acc # assert test_acc<=1 and test_acc>0.7,test_acc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
优化算法
lr=0.1 def updater(batch_size): ''' 随机小批量梯度下降算法更新参数W和b ''' return d2l.sgd([W,b],lr,batch_size)- 1
- 2
- 3
- 4
- 5
- 6
开始训练
num_epochs=10 # 数据 模型 超参数 参数 损失函数 优化算法 开始训练 train_ch3(net,train_iter,test_iter,cross_entropy,num_epochs,updater) # 更加关心测试精度- 1
- 2
- 3
- 4
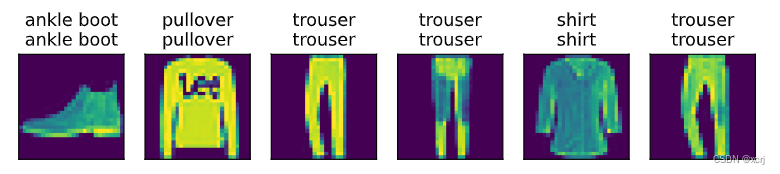
应用:图像分类预测
def predict_ch3(net,test_iter,n=6): ''' 预测标签 :param n=6 展示6张图片 ''' # 只操作一个batch_size for X,y in test_iter: break trues=d2l.get_fashion_mnist_labels(y) preds=d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) titles=[true+'\n'+pred for true,pred in zip(trues,preds)] # X[0:6]将6张图片reshape d2l.show_images(X[0:n].reshape((n,28,28)),1,n,titles=titles[0:n]) predict_ch3(net,test_iter)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
相关阅读:
JDK1.8下载、安装和环境配置使用
【Git】第一篇:Git安装(centos)
华为数字化转型之道 方法篇 第三章 数字化转型框架
Linux防火墙入门:学会使用firewalld和iptables
平均回复在5s内的快捷短语
仿真与烧录程序有哪几种方式?(包含常用工具与使用方式)
【ELM分类】基于matlab鲸鱼算法优化核极限学习机数据分类【含Matlab源码 2012期】
Swift编写爬取商品详情页面的爬虫程序
【对比学习】Understanding the Behaviour of Contrastive Loss (CVPR‘21)
利用URL语法命令,API 接口获取淘宝天猫,拼多多,1688 商品详情等平台,其他API接口
- 原文地址:https://blog.csdn.net/baidu_35805755/article/details/126609998
