-
MySQL EXPLAIN查看执行计划
MySQL 执⾏计划是 MySQL 查询优化器分析 SQL 查询时⽣成的⼀份详细计划,包括表如何连 接、是否⾛索引、表扫描⾏数等。通过这份执⾏计划,我们可以分析这条 SQL 查询中存在的 问题(如是否出现全表扫描),从⽽进⾏针对优化。
我们可以通过EXPLAIN来查询我们SQL的执行计划。EXPLAIN
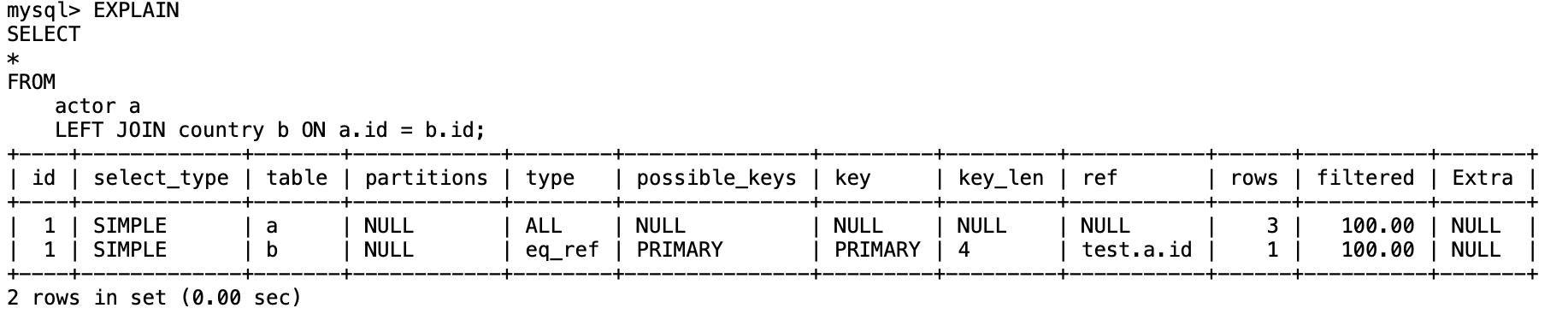
各字段的含义
Id
SELECT查询的序列号,表示执行SELECT 子句的顺序(
Id相同,从上往下执行,Id不同,值越大越先执行。)select_type
查询类型,来区分简单查询、联合查询、⼦查询等。
常⻅的类型有:- SIMPLE:简单查询,不包含表连接或⼦查询
- PRIMARY:主查询,外层的查询
- SUBQUERY:⼦查询中第⼀个
- SELECT UNION:UNION 后⾯的 SELECT 查询语句
- UNION RESULT:UNION 合并的结果
table
查询的表名(也可以是别名)
partitions
匹配的分区,没有分区的表为 NULL
type*
扫描表的方式。
常见的类型有:(性能从上到下,越来越差)
system
表中只有一行数据(系统表),这是const类型的特殊情况;
const
最多返回一条匹配的数据在查询的最开始读取。
因为是通过主键来查询的,然后我们的1也是常量级的,所以类型是const。

eq_ref
在连接查询中
被驱动表使用主键或者唯一键进行连接的时候。(被驱动表只返回一行数据),类似于外键查询。

ref
在连接查询中
被驱动表使用普通索引进行连接的时候,或者在普通查询的WHERE条件中使用索引,基于这个索引来匹配表中所有的行。(也就是在查询前就知道可能会返回多条数据)


fulltext
使用全文索引查询数据。
ref_of_null
在
ref的基础,额外添加了对NULL值的查找。

在join中也可使用

index_merge
索引合并在
key列中会显示所有使用到的索引。类似于有两个条件,这两个条件都有索引,用OR进行连接的话,最后会通过两个索引查询的所有主键值来进行合并(并集)。这个称之为`索引合并。
key列中,可以看见我们使用了两个索引range
使用索引进行范围查找。
像between,>=,>,<,<=这种查询都是范围查询。

like前缀的模糊查询也是范围查找。

index
虽然用到了索引,但是是扫描了所有的索引。

ALL
全表扫描。(注意:全表扫描并不代表就是最差的方案,就比方你本身就需要全部表的数据,你使用全表扫描还能用什么呢?)

possible_keys
这一列显示查询可能使用那些索引来查找。
explain 中有可能possible_keys中有值,但是我们的key中显示NULL的情况,这种因为表中的数据不多,MySQL认为对此查询帮助不大,选择了全表查询。key
实际采用了那个索引。
如果没有使用索引时,我们可以通过force index,ignore index,来强制使用某个索引或者忽略某个索引。key_len
表示使用
key中索引的长度。
我们创建了一个b_c_d(三个字段的联合索引)。
这里可以用的b=4来进行查询。key列中存在我们的索引,但是注意key_len是5,代表我们使用到了部分索引。

当我们使用b=4 and c=4,这样里的key_len是10

当我们使用b = 4 and c = 4 and d = 4,这样里的key_len是15

这里的计算方式是,1个int类型的索引是4个字节,又因为这个字段是允许为空的,所有的加+1位,则是5个字节。所有可以通过观察key_len,来判断索引是否被充分使用。key_len 计算规则
字符串
如果是utf-8,则一个数字与一个字符占一个字节,一个汉字占3个字节
- char:如果存汉字就是3n字节
- varchar:如果存汉字则长度是3n+2字节,+2的2个字节用来存储字符串长度,因为字符串长度,
数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
注意:为空的字段,索引需要在额外+1,判断是否为NULL;
索引最大长度
索引最大长度是768字节,当字符串过长时,mysql,会做一个类似于左前缀索引的处理,将前前半部分的字符提取出来做索引。
ref
这一列显示了在key列记录的索引中,表查找值所用到的列或者常量。常见的有:
const常量,字段名row
表示mysql大概扫描的行数,这个并不是真正的结果集行数。
filtered
基于
row扫描的行数,最后用到了百分之多少的数据,优化可以根据这个来做文章,因为如果说有大量扫描的数据没有被使用,那么会降低查询效率。Extra*
字段通常回会显示更多的信息,可以帮助我们发现性能问题的所在。
Using where
使用
where语句来进行过滤,并且使用的**条件未被索引**覆盖。(表级的过滤)Using index condition
查询的列
没有完全被索引覆盖,且使用where条件进行前置过滤。Using index
表示直接通过索引即可返回所需的字段信息,不需要返回表。(
索引覆盖)
就比方,需要返回一个二级索引值与主键值,使用where条件查询二级索引时,因为二级索引的叶子节点中存储的是主键值,所有不需要进行回表了。Using filesort
表示需要额外的执行排序操作。数据较小时从内存排序,否则需要在磁盘完成排序。
Using temporart
意味着需要创建临时表保存中间结果
EXPLAIN 扩展选项
EXPLAIN FORMAT = tree
按树状结构输出我们的执行计划。
缩进越深越先执行,如果缩进相同从上往下执行.EXPLAIN format = tree SELECT * FROM actor a LEFT JOIN country b ON a.id = b.id -> Nested loop left join (cost=1.60 rows=3) -> Table scan on a (cost=0.55 rows=3) -> Single-row index lookup on b using PRIMARY (Id=a.id) (cost=0.28 rows=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
EXPLAIN FORMAT = json
EXPLAIN format = json SELECT * FROM actor a LEFT JOIN country b ON a.id = b.id { "query_block": { "select_id": 1, "cost_info": { "query_cost": "1.60" }, "nested_loop": [ { "table": { "table_name": "a", "access_type": "ALL", "rows_examined_per_scan": 3, "rows_produced_per_join": 3, "filtered": "100.00", "cost_info": { "read_cost": "0.25", "eval_cost": "0.30", "prefix_cost": "0.55", "data_read_per_join": "456" }, "used_columns": [ "id", "name", "update_time" ] } }, { "table": { "table_name": "b", "access_type": "eq_ref", "possible_keys": [ "PRIMARY" ], "key": "PRIMARY", "used_key_parts": [ "Id" ], "key_length": "4", "ref": [ "test.a.id" ], "rows_examined_per_scan": 1, "rows_produced_per_join": 3, "filtered": "100.00", "cost_info": { "read_cost": "0.75", "eval_cost": "0.30", "prefix_cost": "1.60", "data_read_per_join": "4K" }, "used_columns": [ "Id", "countryname", "countrycode" ] } } ] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
EXPLAIN ANALYZE (MySQL8.0以上)
帮我们实际去执行一遍,并帮我们拿到实际的执行计划,及实际的值。
explain ANALYZE select * from T1 join T2 on T1.a = T2.a; -> Nested loop inner join (cost=1.15 rows=2) (actual time=0.048..0.073 rows=3 loops=1) -> Covering index scan on T1 using index_b (cost=0.45 rows=2) (actual time=0.034..0.043 rows=3 loops=1) -> Single-row index lookup on T2 using PRIMARY (a=t1.a) (cost=0.30 rows=1) (actual time=0.009..0.009 rows=1 loops=3)- 1
- 2
- 3
- 4
- 5
- 6
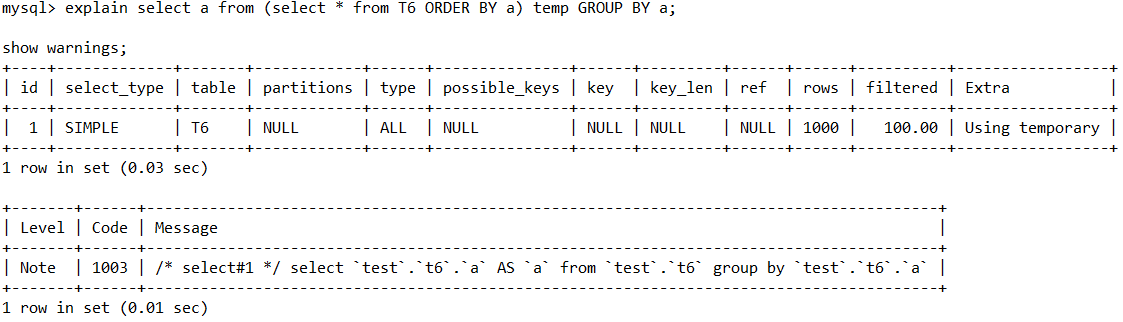
SHOW WARNINGS
可以拿到实际上被MySQL优化器,优化过后的SQL。
很经典的样例就是,子查询中的Order By被优化掉了。
因为我们这把排序放到了子查询内部,执行后发现我们的数据并没有按a来进行排序。
通过show warnings可以看见实际执行的SQL中并没有Order by
方案一:在Order by 后面加个limit ,limit的数量比你原有的结果集大就行,
方案二:Order by放最外面。
MySQL针对子查询的优化,必须不是一个包含了limit和order by才会进行优化。 -
相关阅读:
[protobuf]删除元素
3.Layui3个基本元素
vue中iframe传参/绕过跨域/绕过src不刷新问题解决
常用CSS样式属性
优思学院|精益管理的八步法
java 面试题汇总整理
【C语言数据结构】线性表-链式存储-单链表
【搭建MongoDB】
Elasticsearch系列(六)ES数据搜索之基本流程
Himall商城字符串帮助类获得指定顺序的字符在字符串中的位置索引
- 原文地址:https://blog.csdn.net/qq_43501821/article/details/134236811
