-
DataFrame 遍历访问方法
DataFrame 遍历访问方法
1. 数据准备
(1)测试数据
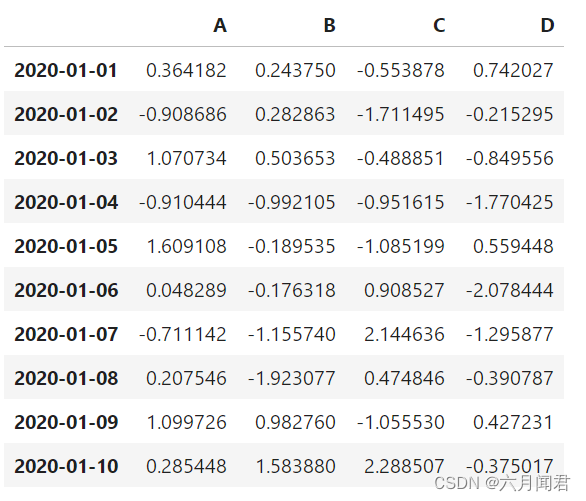
构建一个有index的dataframe 数据。
import numpy as np import pandas as pd ts = pd.Series(np.random.randn(10), index=pd.date_range('2020-1-1', periods=10)) df = pd.DataFrame(np.random.randn(10, 4), index=ts.index, columns=list('ABCD')) df- 1
- 2
- 3
- 4
- 5
- 6
(2)pandas版本
检查pandas版本
print(pd.__version__)- 1
2.0.3
2.访问方法
常用的一共五种方法,可以遍历dataframe数据。
(1)iterrows
通过iterrows方法,可以提取index,行记录。
for index ,row in df.iterrows() : print(index,row['A'],row['D']) 2020-01-01 00:00:00 0.3641823474478886 0.7420267293577939 2020-01-02 00:00:00 -0.9086858514122141 -0.21529516253391381 2020-01-03 00:00:00 1.0707335521425283 -0.8495555020555525 2020-01-04 00:00:00 -0.9104436159077746 -1.7704251732279581 2020-01-05 00:00:00 1.6091084193842462 0.5594481402153169 2020-01-06 00:00:00 0.04828934029765889 -2.078443945278677 2020-01-07 00:00:00 -0.7111418530010771 -1.29587734532037 2020-01-08 00:00:00 0.20754578301393778 -0.39078747556747734 2020-01-09 00:00:00 1.0997255380859803 0.4272308690661768 2020-01-10 00:00:00 0.28544790543277 -0.37501666198259165- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
看一下数据类型,index 是pandas类型的子类
row是series ,可以通过列名调用。print(type(index)) print(type(row['A'])) print(type(row))- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)loc
通过index索引,组合列名访问,用loc方法
for row in df.index: print(df.loc[row]['A']) 0.3641823474478886 -0.9086858514122141 1.0707335521425283 -0.9104436159077746 1.6091084193842462 0.04828934029765889 -0.7111418530010771 0.20754578301393778 1.0997255380859803 0.28544790543277- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)iloc
通过shape取行数,用iloc行标,结合列名,遍历数据
for row_id in range(df.shape[0]): print(df.iloc[row_id]['B']) 0.2437495579604519 0.2828630441432169 0.5036532101096077 -0.9921045754369142 -0.18953453071322154 -0.17631832794049856 -1.1557403411733949 -1.9230766108049244 0.9827603665898592 1.5838796545007081- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(4)itertuples
通过itertuples方法将行转换为tuple 类型,然后访问。
0列是索引,1列对应列名A ,3列对应列名Cfor tup in df.itertuples(): print(tup[0],tup[1],tup[3]) 2020-01-01 00:00:00 0.3641823474478886 -0.5538779087811666 2020-01-02 00:00:00 -0.9086858514122141 -1.7114951319715501 2020-01-03 00:00:00 1.0707335521425283 -0.48885052901155274 2020-01-04 00:00:00 -0.9104436159077746 -0.9516150263977505 2020-01-05 00:00:00 1.6091084193842462 -1.0851994280481798 2020-01-06 00:00:00 0.04828934029765889 0.9085265155873162 2020-01-07 00:00:00 -0.7111418530010771 2.1446364650140746 2020-01-08 00:00:00 0.20754578301393778 0.4748462568719993 2020-01-09 00:00:00 1.0997255380859803 -1.0555296783745742 2020-01-10 00:00:00 0.28544790543277 2.288507229443556- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
直接打印元组数据,效果如下:
for tup in df.itertuples(): print(tup) Pandas(Index=Timestamp('2020-01-01 00:00:00'), A=0.3641823474478886, B=0.2437495579604519, C=-0.5538779087811666, D=0.7420267293577939) Pandas(Index=Timestamp('2020-01-02 00:00:00'), A=-0.9086858514122141, B=0.2828630441432169, C=-1.7114951319715501, D=-0.21529516253391381) Pandas(Index=Timestamp('2020-01-03 00:00:00'), A=1.0707335521425283, B=0.5036532101096077, C=-0.48885052901155274, D=-0.8495555020555525) Pandas(Index=Timestamp('2020-01-04 00:00:00'), A=-0.9104436159077746, B=-0.9921045754369142, C=-0.9516150263977505, D=-1.7704251732279581) Pandas(Index=Timestamp('2020-01-05 00:00:00'), A=1.6091084193842462, B=-0.18953453071322154, C=-1.0851994280481798, D=0.5594481402153169) Pandas(Index=Timestamp('2020-01-06 00:00:00'), A=0.04828934029765889, B=-0.17631832794049856, C=0.9085265155873162, D=-2.078443945278677) Pandas(Index=Timestamp('2020-01-07 00:00:00'), A=-0.7111418530010771, B=-1.1557403411733949, C=2.1446364650140746, D=-1.29587734532037) Pandas(Index=Timestamp('2020-01-08 00:00:00'), A=0.20754578301393778, B=-1.9230766108049244, C=0.4748462568719993, D=-0.39078747556747734) Pandas(Index=Timestamp('2020-01-09 00:00:00'), A=1.0997255380859803, B=0.9827603665898592, C=-1.0555296783745742, D=0.4272308690661768) Pandas(Index=Timestamp('2020-01-10 00:00:00'), A=0.28544790543277, B=1.5838796545007081, C=2.288507229443556, D=-0.37501666198259165)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(5)values
通过pandas的values属性,访问数据。
0123分别对应ABCD列,效果如下:for row in df.values: print(row[0], ' ', row[1], ' ', row[2], ' ', row[3]) 0.3641823474478886 0.2437495579604519 -0.5538779087811666 0.7420267293577939 -0.9086858514122141 0.2828630441432169 -1.7114951319715501 -0.21529516253391381 1.0707335521425283 0.5036532101096077 -0.48885052901155274 -0.8495555020555525 -0.9104436159077746 -0.9921045754369142 -0.9516150263977505 -1.7704251732279581 1.6091084193842462 -0.18953453071322154 -1.0851994280481798 0.5594481402153169 0.04828934029765889 -0.17631832794049856 0.9085265155873162 -2.078443945278677 -0.7111418530010771 -1.1557403411733949 2.1446364650140746 -1.29587734532037 0.20754578301393778 -1.9230766108049244 0.4748462568719993 -0.39078747556747734 1.0997255380859803 0.9827603665898592 -1.0555296783745742 0.4272308690661768 0.28544790543277 1.5838796545007081 2.288507229443556 -0.37501666198259165- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意:row并不是list,是numpy.ndarray
for row in df.values: print(row) print(type(row)) [ 0.36418235 0.24374956 -0.55387791 0.74202673] [-0.90868585 0.28286304 -1.71149513 -0.21529516] [ 1.07073355 0.50365321 -0.48885053 -0.8495555 ] [-0.91044362 -0.99210458 -0.95161503 -1.77042517] [ 1.60910842 -0.18953453 -1.08519943 0.55944814] [ 0.04828934 -0.17631833 0.90852652 -2.07844395] [-0.71114185 -1.15574034 2.14463647 -1.29587735] [ 0.20754578 -1.92307661 0.47484626 -0.39078748] [ 1.09972554 0.98276037 -1.05552968 0.42723087] [ 0.28544791 1.58387965 2.28850723 -0.37501666]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(6)iteritems
网上还有不少介绍,还可以通过iteritems方法访问,但是报错。
for index, col in df.iteritems(): print(index,col.iloc[0]) 报错信息如下: AttributeError: 'DataFrame' object has no attribute 'iteritems'- 1
- 2
- 3
- 4
网上查询,是原来pandas低版本有iteritems方法,据说是在1.5.X版本上有,未验证。
2.0.X版本上肯定不支持此功能。 -
相关阅读:
PHP+经贸时间轴 毕业设计-附源码211617
【华为OD机试真题 JS】一种字符串压缩表示的解压
大数据发展史
JDBC概念及连接数据库
编码通信与魔术初步(五)——编码通信魔术入门《3 * 7的感应》
【经验之谈】关于维修电子设备的几点建议和经验
企业数据的存储形式与方案选择
四维轻云平台倾斜模型三种加载方式及单体化操作介绍
数学建模--三维图像绘制的Python实现
正点原子linux应用编程——入门篇1
- 原文地址:https://blog.csdn.net/qq_39065491/article/details/134015049