-
【论文解读】The Power of Scale for Parameter-Efficient Prompt Tuning
一.介绍
1.1 promote tuning 和 prefix tuning 的关系
“前缀调优”的简化版
1.2 大致实现
冻结了整个预训练模型,并且只允许每个下游任务附加k个可调令牌到输入文本。这种“软提示”是端到端训练的,可以压缩来自完整标记数据集的信号,使我们的方法优于少量提示,并通过模型调整缩小质量差距。同时,由于单个预训练模型可用于所有下游任务,因此我们保留了冻结模型的高效服务优势
1.3 核心贡献
- 提出提示调优,并在大型语言模型中展示其与模型调优的竞争力。
- 消除许多设计选择,并显示质量和健壮性随着规模而提高。
- 在域移位问题上显示提示调优优于模型调优。
- 提出“即时整合”并展示其有效性。
二.promote tuning
2.1 问题建模
将所有任务都转换为文本生成。将分类建模为给定某些输入的输出类的概率
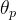 ,其中X是一系列标记,y是单个类标签,现在我们将其建模为条件生成,其中y是表示类标签的标记序列。
,其中X是一系列标记,y是单个类标签,现在我们将其建模为条件生成,其中y是表示类标签的标记序列。2.2 promote 如何work的
提示是在Y生成过程中为模型添加额外信息的方法。通常,提示是通过在输入X前添加一系列标记P来完成的,这样模型就可以最大化生成Y的正确Y的可能性。通常,提示是通过在输入X前添加一系列标记P来完成的,这样模型就可以最大化正确Y的可能性,
![Pr_{\theta } (Y|[P;X])](https://1000bd.com/contentImg/2024/03/08/220742444.png) ,同时保持模型参数θ不变。
,同时保持模型参数θ不变。提示调优本质上就是使用专用参数
建模promote信息作为提示符,这些提示符被连接到嵌入的输入,直接通过模型(encoder-decoder架构)2.3 与其他工作的对比
文章第四节对比了该方法和其他方法的异同,但是没有给出数据对比
三.代码实现
【pytorch参考代码】
只训练soft promote 权重
- # Only update soft prompt'weights for prompt-tuning. ie, all weights in LM are set as `require_grad=False`.
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if n == "soft_prompt.weight"],
- "weight_decay": args.weight_decay,
- }
- ]
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )
初始化权重
- def initialize_soft_prompt(
- self,
- n_tokens: int = 20,
- initialize_from_vocab: bool = True,
- random_range: float = 0.5,
- ) -> None:
- self.n_tokens = n_tokens
- if initialize_from_vocab:
- init_prompt_value = self.transformer.wte.weight[:n_tokens].clone().detach()
- else:
- init_prompt_value = torch.FloatTensor(2, 10).uniform_(
- -random_range, random_range
- )
- self.soft_prompt = nn.Embedding(n_tokens, self.config.n_embd)
- # Initialize weight
- self.soft_prompt.weight = nn.parameter.Parameter(init_prompt_value)
处理输入
- def _cat_learned_embedding_to_input(self, input_ids) -> torch.Tensor:
- inputs_embeds = self.transformer.wte(input_ids)
- if len(list(inputs_embeds.shape)) == 2:
- inputs_embeds = inputs_embeds.unsqueeze(0)
- # [batch_size, n_tokens, n_embd]
- learned_embeds = self.soft_prompt.weight.repeat(inputs_embeds.size(0), 1, 1)
- inputs_embeds = torch.cat([learned_embeds, inputs_embeds], dim=1)
- return inputs_embeds
-
相关阅读:
扬帆际海—shopee跨境店和本土店谁更有优势?
【结构体类型——详细讲解】
数据结构——栈
docker如何下载国外镜像
Unigui中获取手机特征码
iNFTnews|Facebook、Twitter先后扑街,社交媒体的未来属于Web3?
iOS小技能:RSA签名、验签、加密、解密的原理
使用TPDSS连接GaussDB数据库
多台云服务器的 Kubernetes 集群搭建
Tune-A-Video论文阅读
- 原文地址:https://blog.csdn.net/weixin_50862344/article/details/133953048
