-
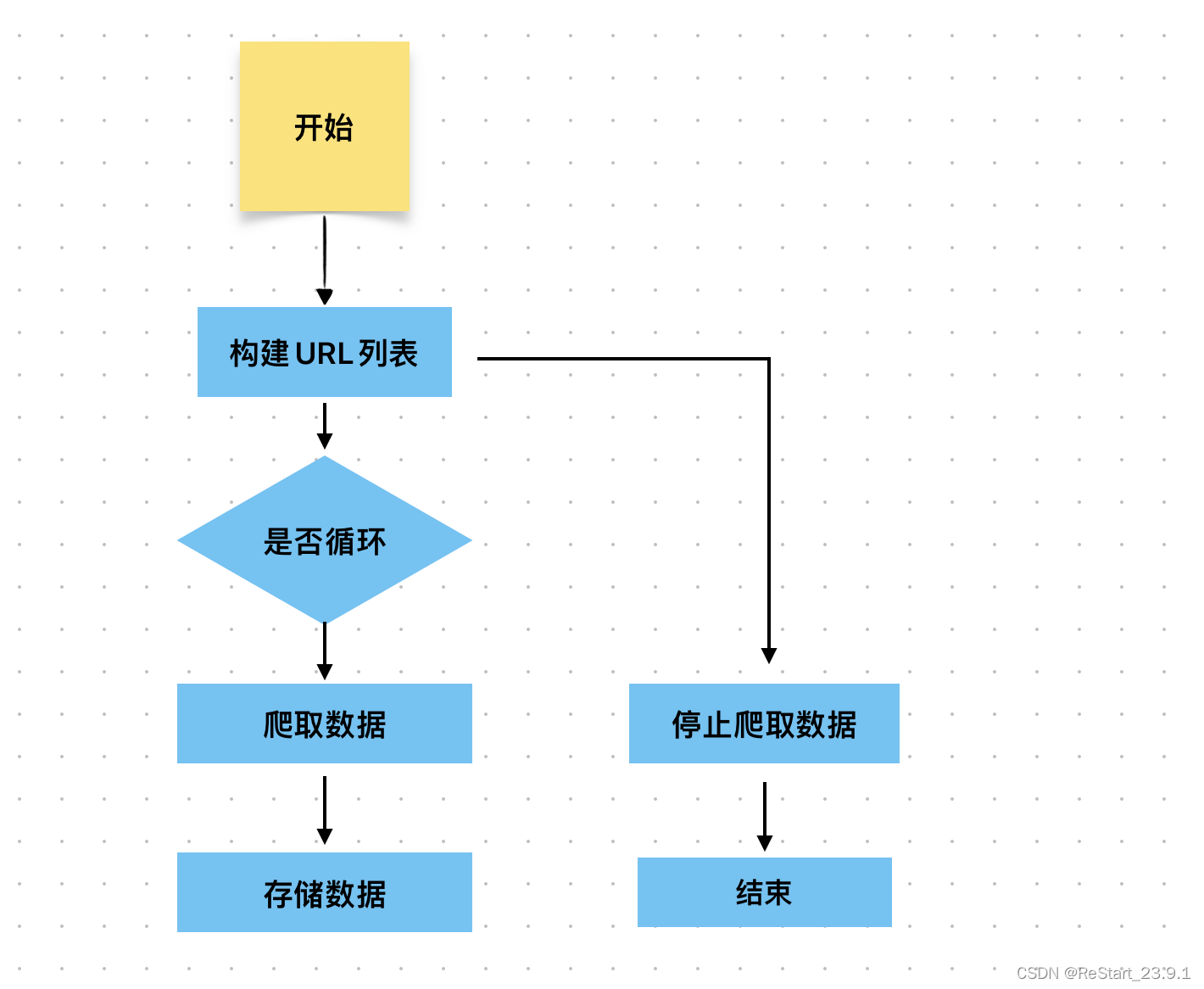
Python 网络爬虫
-
相关阅读:
前后端分离项目,vue+uni-app+php+mysql订座预约小程序系统 开题报告
二叉树—堆(C语言实现)
面试:gradle添加自定义task
MySQL派生表合并优化的原理和实现
智能合约安全新范式,超越 `require`和`assert`
【TypeScript笔记】04 - 在React中使用TypeScript
计算机毕业设计Java城镇保障性住房管理系统(源码+系统+mysql数据库+lw文档)
【LWE问题简介】
Java项目:ssm医院管理系统
时间、时间戳互转、日期格式化、获取各种天数
- 原文地址:https://blog.csdn.net/fly_with_bb/article/details/133897280