-
17 | DataSource 为何物?加载过程是怎样的
最近几年 DataSource 越来越成熟,但当我们做开发的时候对 DataSource 的关心却越来越少,这是因为大多数情况都是利用 application.properties进行简单的数据源配置,项目就可以正常运行了。但是当我们想要解决一些原理性问题的时候,就需要用到 DataSource、连接池等基础知识了。
那么这一讲我将带你揭开 DataSource 的面纱,一起来了解它是什么、如何使用,以及最佳实践是什么呢?
数据源是什么?
当我们用第三方工具去连接数据库(Mysql,Oracle 等)的时候,一般都会让我们选择数据源,如下图所示:
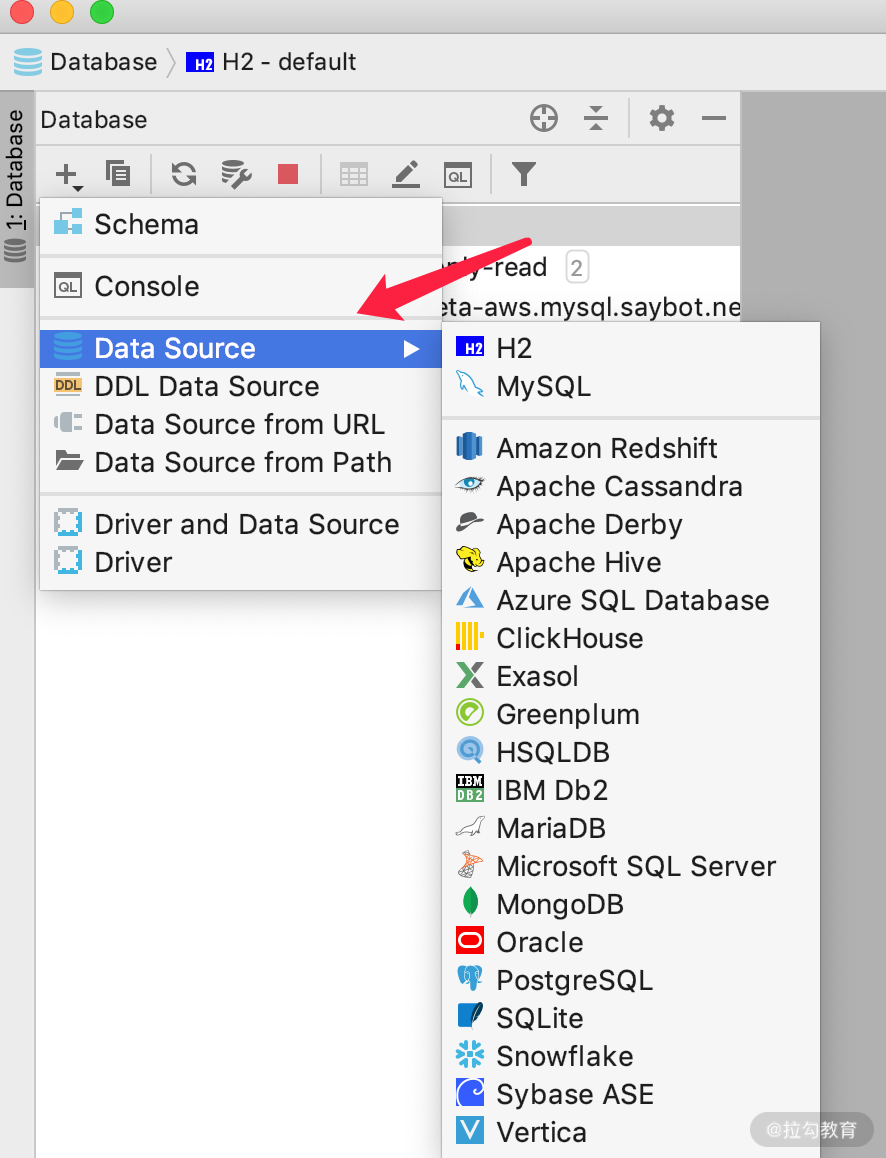
我们以 MySQL 为例,当选择 MySQL 的时候就会弹出如下图显示的界面:
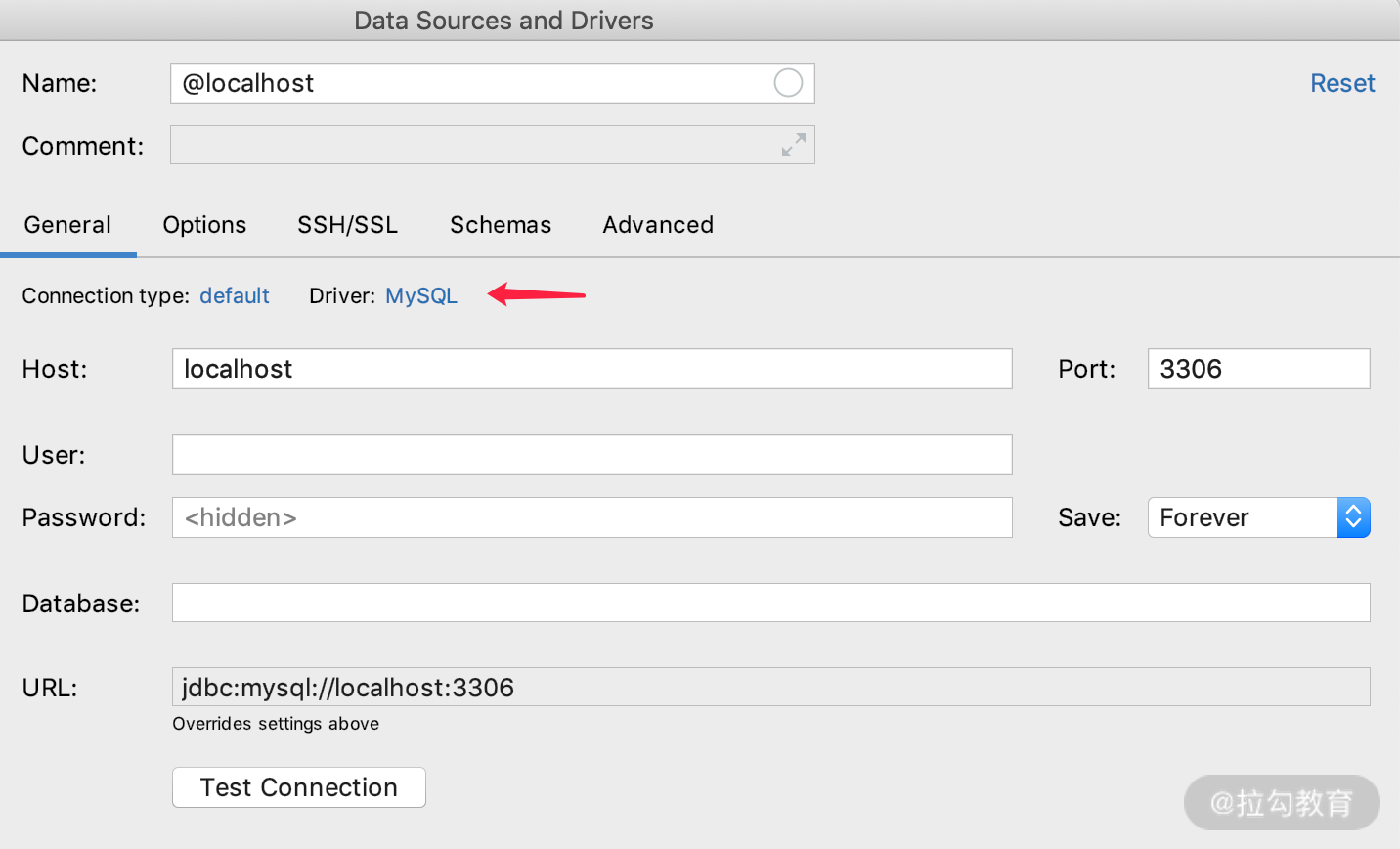
其中,我们在选择了 Driver(驱动)和 Host、UserName、Password 等之后,就可以创建一个 Connection,然后连接到数据库里面了。
同样的道理,在 Java 里面我们也需要用到 DataSource 去连接数据库,而 Java 定义了一套 JDBC 的协议标准,其中有一个 javax.sql.DataSource 接口类,通过实现此类就可以进行数据库连接,我们通过源码来分析一下。
DataSource 源码分析
DataSource 接口里面主要的代码如下所示:
复制代码
public interface DataSource extends CommonDataSource, Wrapper { Connection getConnection() throws SQLException; Connection getConnection(String username, String password) throws SQLException; }- 1
- 2
- 3
- 4
- 5
我们通过源码可以很清楚地看到,DataSource 的主要目的就是获得数据库连接,就像我们前面用工具连接数据库一样,只不过工具是通过界面实现的,而 DataSource 是通过代码实现的。
那么在程序里面如何实现呢?也有很多第三方的实现方式,常见的有C3P0、BBCP、Proxool、Druid、Hikari,而目前 Spring Boot 里面是采用 Hikari 作为默认数据源。Hikari 的优点是:开源,社区活跃,性能高,监控完整。我们通过工具看一下项目里面DataSource 的实现类有哪些,如下图所示:
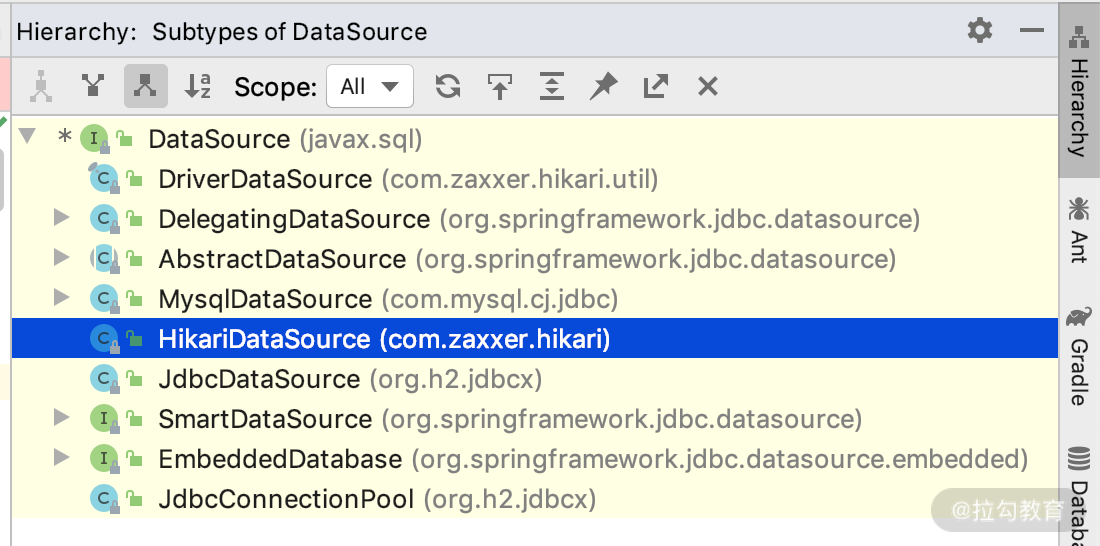
其中,当我采用默认数据源的时候,可以看到数据源的实现类有:h2 里面的 JdbcDataSource、MySQL 连接里面的 MysqlDataSource,以及今天要重点介绍的 HikariDataSource(默认数据源,也是 Spring 社区推荐的最佳数据源)。
我们直接打开 HikariDataSource 的源码看一下,它的关键代码如下:
复制代码
public class HikariDataSource extends HikariConfig implements DataSource, Closeable{ private volatile HikariPool pool; public HikariDataSource(HikariConfig configuration) { configuration.validate(); configuration.copyStateTo(this); LOGGER.info("{} - Starting...", configuration.getPoolName()); pool = fastPathPool = new HikariPool(this); LOGGER.info("{} - Start completed.", configuration.getPoolName()); this.seal(); } //这个是最主要的实现逻辑,即通过连接池获得连接的逻辑 public Connection getConnection() throws SQLException{ if (isClosed()) { throw new SQLException("HikariDataSource " + this + " has been closed."); } if (fastPathPool != null) { return fastPathPool.getConnection(); } // See http://en.wikipedia.org/wiki/Double-checked_locking#Usage_in_Java HikariPool result = pool; if (result == null) { synchronized (this) { result = pool; if (result == null) { validate(); LOGGER.info("{} - Starting...", getPoolName()); try { pool = result = new HikariPool(this); this.seal(); } catch (PoolInitializationException pie) { if (pie.getCause() instanceof SQLException) { throw (SQLException) pie.getCause(); } else { throw pie; } } LOGGER.info("{} - Start completed.", getPoolName()); } } } return result.getConnection(); } ...... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
从上面的源码可以看到关键的两点问题:
- 数据源的关键配置属性有哪些?
- 连接怎么获得?连接池的作用如何?
下面我们分别详解一下。
第一个问题,HikariConfig 的配置里面描述了 Hikari 数据源主要的配置属性,我们打开来看一下,如图所示:

通过上面的源码我们可以看到数据源的关键配置信息:用户名、密码、连接池的配置、jdbcUrl、驱动的名字,等等,这些字段你可以参考课程开始时我介绍的工具,细心观察的话都可以找到对应关系,也就是创建数据源需要的一些配置项。
上面提到的第 2 个问题,我们通过 getConnection 方法里面的代码可以看到 HikariPool 的用法,也就是说,我们是通过连接池来获得连接的,这个连接用过之后没有断开,而是重新放回到连接池里面(这个地方你一定要谨记,它也说明了 connection 是可以共享的)。
而连接池的用途你应该也知道,创建连接是非常昂贵的,所以需要用到连接池技术、共享现有的连接,以增加代码的执行效率。
那么这个时候有一个问题是需要我们搞清楚并且牢记的,就是数据源和 driver(驱动)、数据库连接、连接池是什么关系?
数据源与驱动与连接和连接池的关系
我分为下述四点来说,方便你理解。
- 数据源的作用是给应用程序提供不同 DB 的连接 connection;
- 连接是通过连接池获取的,这主要是出于连接性能的考虑;
- 创建好连接之后,通过数据库的驱动来进行数据库操作;
- 而不同的 DB(MySQL / h2 / oracle),都有自己的驱动类和相应的驱动 Jar 包。
我们用一个图来表示一下:
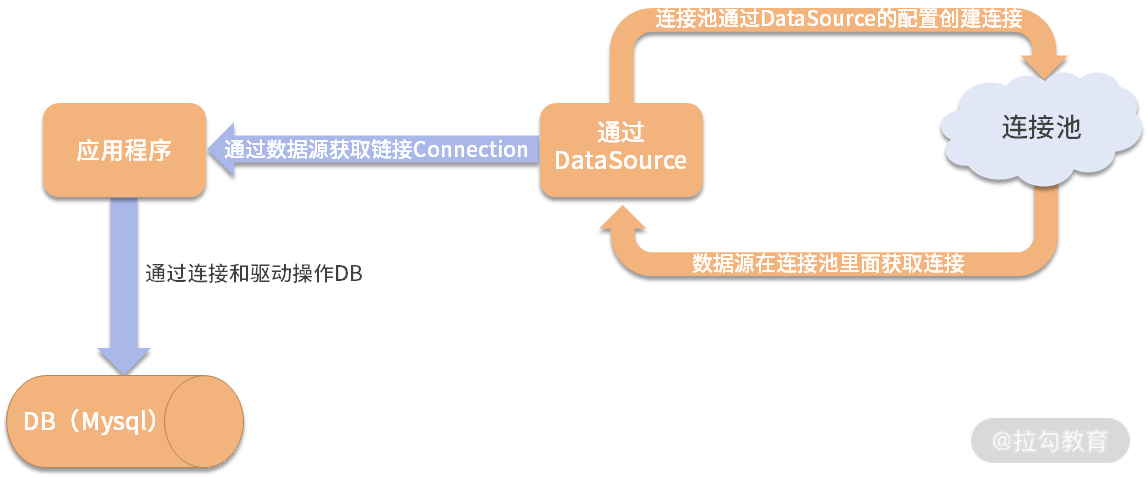
而我们常说的 MySQL 驱动,其实就是 com.mysql.cj.jdbc.Driver,而这个类主要存在于 mysql-connection-java:8.0* 的 jar 里面,也就是我们经常说的不同的数据库所代表的驱动 jar 包。
这里我们用的是 spring boot 2.3.3 版本引用的 mysql-connection-java 8.0 版本驱动 jar 包,不同的数据库引用的 jar 包是不一样的。例如,H2 数据源中,我们用的驱动类是 org.h2.Driver,其包含在 com.h2database:h2:1.4.*jar 包里面。
接下来我们通过源码分析 Spring 里面的加载原理,来看下 Hikari 都有哪些配置项。
数据源的加载原理和过程是什么样的?
我们通过 spring.factories 文件可以看到 JDBC 数据源相关的自动加载的类 DataSourceAutoConfiguration,那么我们就从这个类开始分析。
DataSourceAutoConfiguration 数据源的加载过程分析
DataSourceAutoConfiguration 的关键源码如下所示:
复制代码
//将spring.datasource.**的配置放到DataSourceProperties对象里面; @EnableConfigurationProperties(DataSourceProperties.class) @Import({ DataSourcePoolMetadataProvidersConfiguration.class, DataSourceInitializationConfiguration.class }) public class DataSourceAutoConfiguration { //默认集成的数据源,一般指的是H2,方便我们快速启动和上手,一般不在生产环境应用; @Configuration(proxyBeanMethods = false) @Conditional(EmbeddedDatabaseCondition.class) @ConditionalOnMissingBean({ DataSource.class, XADataSource.class }) @Import(EmbeddedDataSourceConfiguration.class) protected static class EmbeddedDatabaseConfiguration { } //加载不同的数据源的配置 @Configuration(proxyBeanMethods = false) @Conditional(PooledDataSourceCondition.class) @ConditionalOnMissingBean({ DataSource.class, XADataSource.class }) @Import({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class, DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.Generic.class, DataSourceJmxConfiguration.class }) protected static class PooledDataSourceConfiguration { } .... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
从源码中我们可以得到以下三点最关键的信息:
第一,通过 @EnableConfigurationProperties(DataSourceProperties.class) 可以看得出来 spring.datasource 的配置项有哪些,那么我们打开 DataSourceProperties 的源码看一下,关键代码如下:复制代码
@ConfigurationProperties(prefix = "spring.datasource") public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean { private ClassLoader classLoader; private String name; private boolean generateUniqueName = true; private Class type; private String driverClassName; private String url; private String username; private String password; //计算确定drivername的值是什么 public String determineDriverClassName() { if (StringUtils.hasText(this.driverClassName)) { Assert.state(driverClassIsLoadable(), () -> "Cannot load driver class: " + this.driverClassName); return this.driverClassName; } String driverClassName = null; //此段逻辑是,当我们没有配置自己的drivername的时候,它会根据我们配置的DB的url自动计算出来drivername的值是什么,所以就会发现我们现在很多datasource里面的配置都省去了driver-name的配置,这是Spring Boot的功劳。 if (StringUtils.hasText(this.url)) { driverClassName = DatabaseDriver.fromJdbcUrl(this.url).getDriverClassName(); } if (!StringUtils.hasText(driverClassName)) { driverClassName = this.embeddedDatabaseConnection.getDriverClassName(); } if (!StringUtils.hasText(driverClassName)) { throw new DataSourceBeanCreationException("Failed to determine a suitable driver class", this, this.embeddedDatabaseConnection); } return driverClassName; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
我们通过 DatabaseDriver 的源码可以看到 MySQL 的默认驱动 Spring Boot 是采用 com.mysql.cj.jdbc.Driver 来实现的。

同时,@ConfigurationProperties(prefix = “spring.datasource”) 也告诉我们,application.properties 里面的 datasource 相关的公共配置可以以 spring.datasource 为开头,这样当启动的时候,DataSourceProperties 就会将 datasource 的一切配置自动加载进来。正如我们前面在 application.properties 里面的配置的一样,如下图所示:
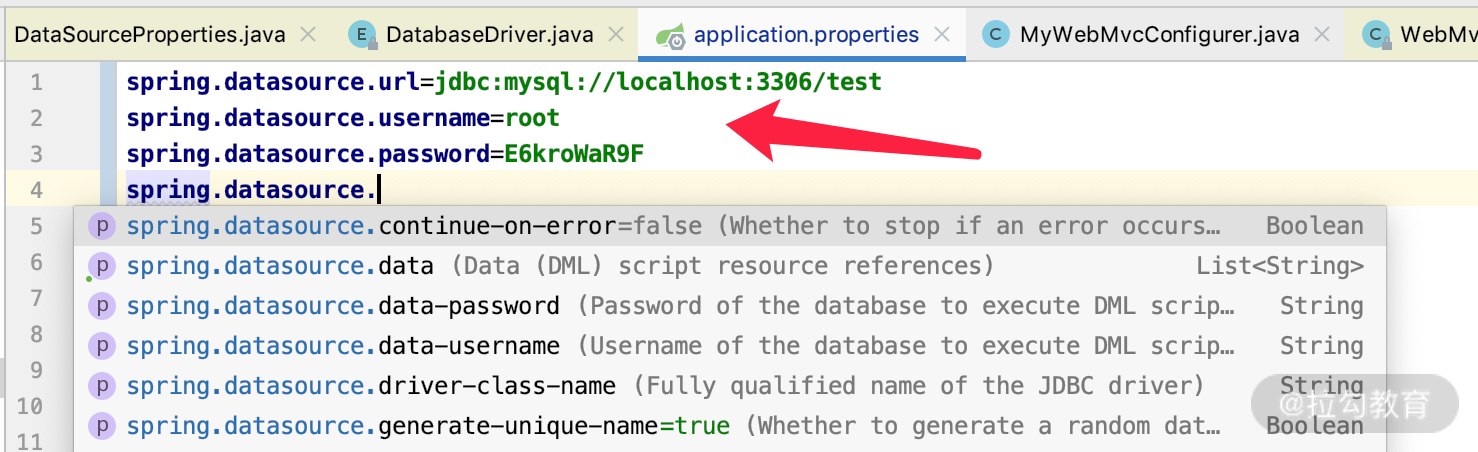
这里有 url、username、password、driver-class-name 等关键配置,不同数据源的公共配置也不多。
第二,我们通过下面这一段代码也可以看得出来不同的数据源的配置是什么样的。
复制代码
@Import({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class, DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.Generic.class, DataSourceJmxConfiguration.class })- 1
- 2
- 3
为了再进一步了解,我们打开 DataSourceConfiguration 的源码,如下所示:
复制代码
abstract class DataSourceConfiguration { @SuppressWarnings("unchecked") protected staticT createDataSource(DataSourceProperties properties, Class type) { return (T) properties.initializeDataSourceBuilder().type(type).build(); } /** * Tomcat连接池数据源的配置,前提条件需要引入tomcat-jdbc*.jar */ @Configuration(proxyBeanMethods = false) @ConditionalOnClass(org.apache.tomcat.jdbc.pool.DataSource.class) @ConditionalOnMissingBean(DataSource.class) @ConditionalOnProperty(name = "spring.datasource.type", havingValue = "org.apache.tomcat.jdbc.pool.DataSource", matchIfMissing = true) static class Tomcat { @Bean @ConfigurationProperties(prefix = "spring.datasource.tomcat") org.apache.tomcat.jdbc.pool.DataSource dataSource(DataSourceProperties properties) { org.apache.tomcat.jdbc.pool.DataSource dataSource = createDataSource(properties, org.apache.tomcat.jdbc.pool.DataSource.class); DatabaseDriver databaseDriver = DatabaseDriver.fromJdbcUrl(properties.determineUrl()); String validationQuery = databaseDriver.getValidationQuery(); if (validationQuery != null) { dataSource.setTestOnBorrow(true); dataSource.setValidationQuery(validationQuery); } return dataSource; } } /** * Hikari数据源的配置,默认Spring Boot加载的是Hikari数据源 */ @Configuration(proxyBeanMethods = false) @ConditionalOnClass(HikariDataSource.class) @ConditionalOnMissingBean(DataSource.class) @ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.zaxxer.hikari.HikariDataSource", matchIfMissing = true) static class Hikari { @Bean @ConfigurationProperties(prefix = "spring.datasource.hikari") HikariDataSource dataSource(DataSourceProperties properties) { HikariDataSource dataSource = createDataSource(properties, HikariDataSource.class); if (StringUtils.hasText(properties.getName())) { dataSource.setPoolName(properties.getName()); } return dataSource; } } /** * DBCP数据源的配置,按照Spring Boot的语法,我们必须引入CommonsDbcp**.jar依赖才有用 */ @Configuration(proxyBeanMethods = false) @ConditionalOnClass(org.apache.commons.dbcp2.BasicDataSource.class) @ConditionalOnMissingBean(DataSource.class) @ConditionalOnProperty(name = "spring.datasource.type", havingValue = "org.apache.commons.dbcp2.BasicDataSource", matchIfMissing = true) static class Dbcp2 { @Bean @ConfigurationProperties(prefix = "spring.datasource.dbcp2") org.apache.commons.dbcp2.BasicDataSource dataSource(DataSourceProperties properties) { return createDataSource(properties, org.apache.commons.dbcp2.BasicDataSource.class); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
我们通过上述源码可以看到最常见的三种数据源的配置:
- HikariDataSource
- tomcat的JDBC
- apache的dbcp
而最终用哪个,就看你引用了哪个 datasoure 的 jar 包。不过 Spring Boot 2.0 之后就推荐使用 Hikari 数据源了,你了解一下就好。
第三,我们通过 @ConfigurationProperties(prefix = “spring.datasource.hikari”) HikariDataSource dataSource(DataSourceProperties properties) 可以知道,application.properties 里面 spring.datasource.hikari 开头的配置会被映射到 HikariDataSource 对象中,而开篇我们就提到了,是 HikariDataSource 继承了 HikariConfig。
所以顺理成章地,我们就可以知道 Hikari 数据源的配置有哪些了,如下图所示:
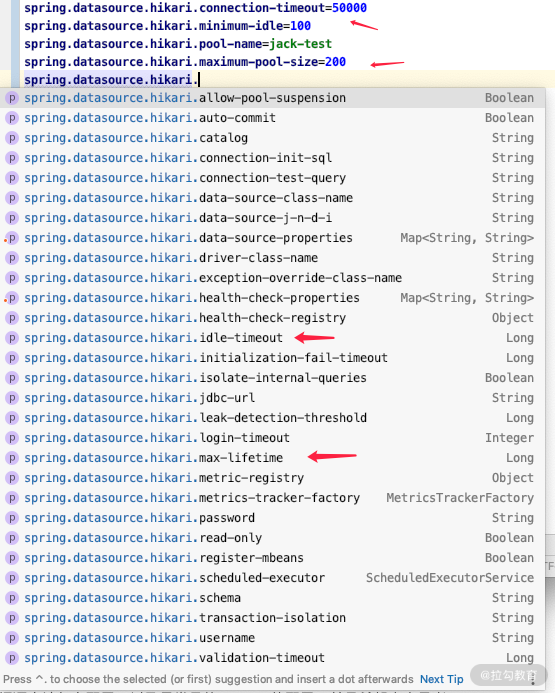
Hikari 的配置比较多,你实际工作中想要了解详细配置,可以看一下官方文档:https://github.com/brettwooldridge/HikariCP,这里我只说一下我们最需要关心的配置,有如下几个:
复制代码
## 最小空闲链接数量 spring.datasource.hikari.minimum-idle=5 ## 空闲链接存活最大时间,默认600000(10分钟) spring.datasource.hikari.idle-timeout=180000 ## 链接池最大链接数,默认是10 spring.datasource.hikari.maximum-pool-size=10 ## 此属性控制从池返回的链接的默认自动提交行为,默认值:true spring.datasource.hikari.auto-commit=true ## 数据源链接池的名称 spring.datasource.hikari.pool-name=MyHikariCP ## 此属性控制池中链接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟 spring.datasource.hikari.max-lifetime=1800000 ## 数据库链接超时时间,默认30秒,即30000 spring.datasource.hikari.connection-timeout=30000 spring.datasource.hikari.connection-test-query=SELECT 1mysql- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里我介绍的主要是针对连接池的配置,研究过线程池和连接池原理的同学都知道,连接池我们不能配置得太大,因为连接池太大的话,会有额外的 CPU 开销,处理连接池的线程切换反而会增加程序的执行时间,减低性能;相应的,连接池也不能配置太小,太小的话可能会增加请求的等待时间,也会降低业务处理的吞吐量。
下面我给你一个推荐一个常见的配置项。
Hikari 数据源下的 MySQL 配置最佳实践
直接通过代码来看看。
复制代码
##数据源的配置:logger=Slf4JLogger&profileSQL=true是用来debug显示sql的执行日志的 spring.datasource.url=jdbc:mysql://localhost:3306/test?logger=Slf4JLogger&profileSQL=true spring.datasource.username=root spring.datasource.password=E6kroWaR9F ##采用默认的 #spring.datasource.hikari.connectionTimeout=30000 #spring.datasource.hikari.idleTimeout=300000 ##指定一个链接池的名字,方便我们分析线程问题 spring.datasource.hikari.pool-name=jpa-hikari-pool ##最长生命周期15分钟够了 spring.datasource.hikari.maxLifetime=900000 spring.datasource.hikari.maximumPoolSize=8 ##最大和最小相对应减少创建线程池的消耗; spring.datasource.hikari.minimumIdle=8 spring.datasource.hikari.connectionTestQuery=select 1 from dual ##当释放连接到连接池之后,采用默认的自动提交事务 spring.datasource.hikari.autoCommit=true ##用来显示链接测trace日志 logging.level.com.zaxxer.hikari.HikariConfig=DEBUG logging.level.com.zaxxer.hikari=TRACE- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
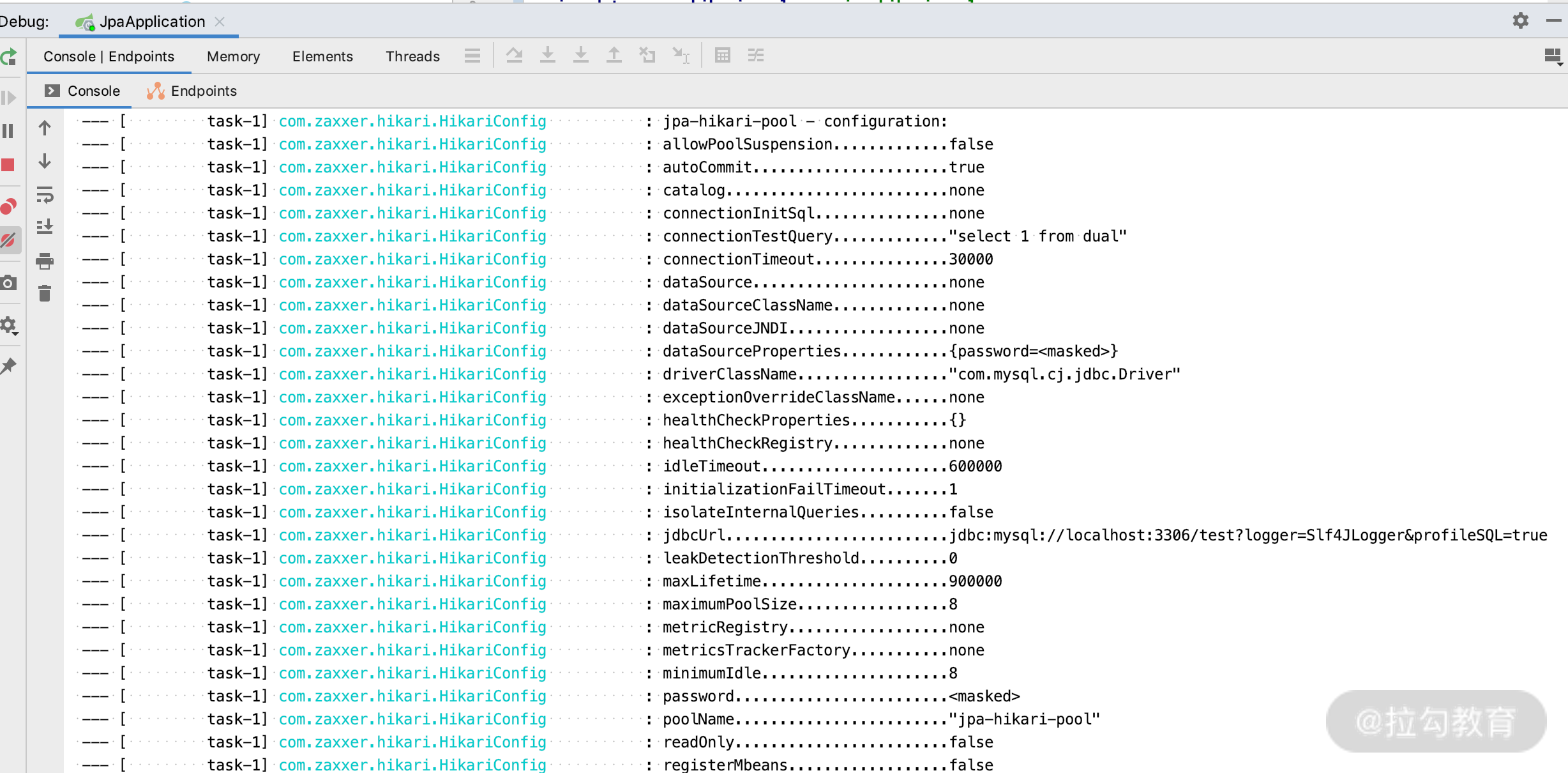
通过上面的日志配置,我们在启动的时候可以看到连接池的配置结果和 MySQL 的执行日志:
1.如下日志,显示了Hikari 的 config 配置。
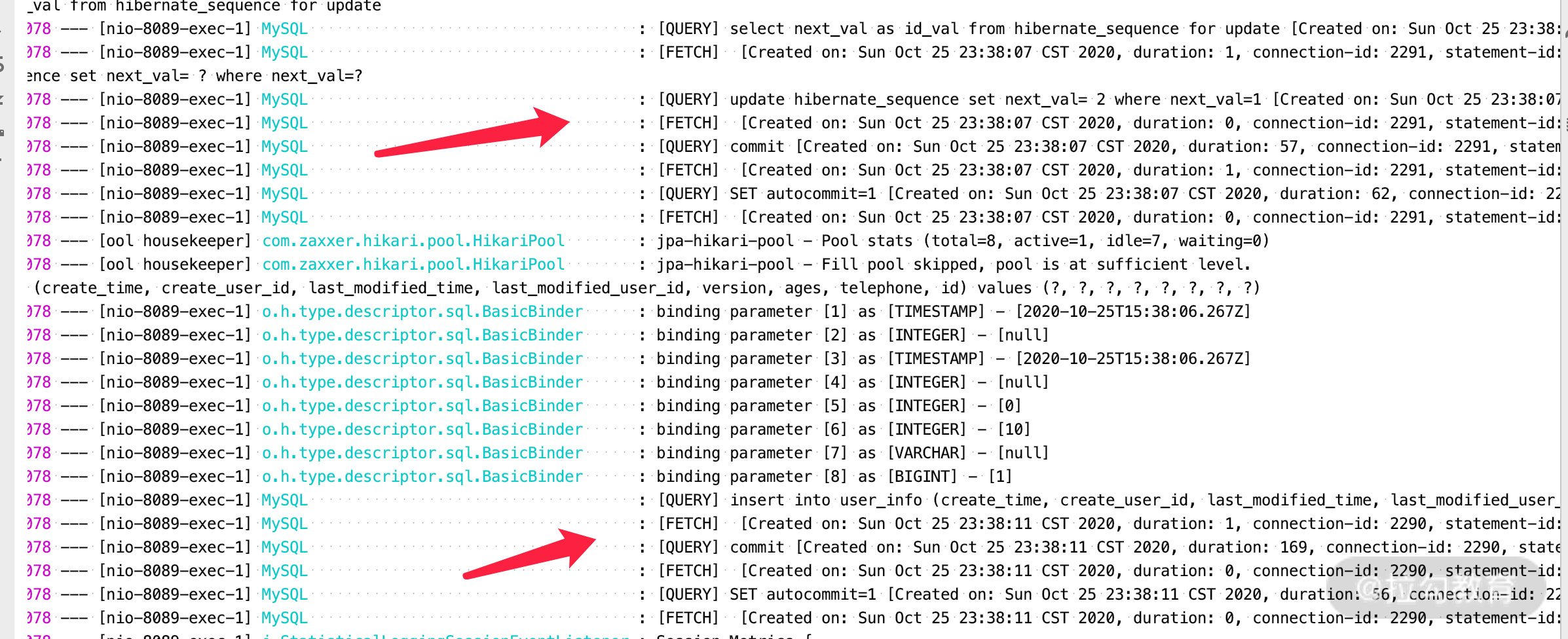
2.当我们执行一个方法的时候,到底要在一个 MySQL 的 connection 上面执行哪些 SQL 呢?通过如下日志我们可以看得出来。
3.通过开启 com.zaxxer.hikari.pool.HikariPool 类的 debug 级别,可以实时看到连接池的使用情况:软件日志如下(上图也有体现):
复制代码
com.zaxxer.hikari.pool.HikariPool : jpa-hikari-pool - Pool stats (total=8, active=1, idle=7, waiting=0)- 1
通过上面的监控日志,你在实际工作中可以根据主机的 CPU 情况和业务处理的耗时情况,再对连接池做适当的调整,但是注意差距不要太大,不要一下将连接池配置几百个,那是错误的配置。
而除了上面的这些日志之外,Hikari 还提供了 Metrics 的监控指标,我们一般配合 Prometheus 使用,甚至可以利用 Granfan 配置一些告警,我们看一下。
Hikari 数据通过 Prometheus 的监控指标应用
就像我们日志里面打印的一样,
复制代码
om.zaxxer.hikari.pool.HikariPool : jpa-hikari-pool - Pool stats (total=8, active=0, idle=8, waiting=0)- 1
Hikari 的 Metirc 也帮我们提供了 Prometheus 的监控指标,实现方法很简单,代码如下所示:
复制代码
1. gradle依赖里面添加 implementation 'io.micrometer:micrometer-registry-prometheus' 2. application.properties里面添加 #Metrics related configurations management.endpoint.metrics.enabled=true management.endpoints.web.exposure.include=* management.endpoint.prometheus.enabled=true management.metrics.export.prometheus.enabled=true- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后我们启动项目,通过下图中的地址就可以看到,Prometheus 的 Metrics 里面多了很多 HikariCP 的指标。

当看到这些指标之后,我们就可以根据 Grafana 社区里面提供的 HikariCP 的监控 Dashboards 的配置文档地址:https://grafana.com/grafana/dashboards/6083,导入到我们自己的 Grafana 里面,可以通过图表看到如下界面:
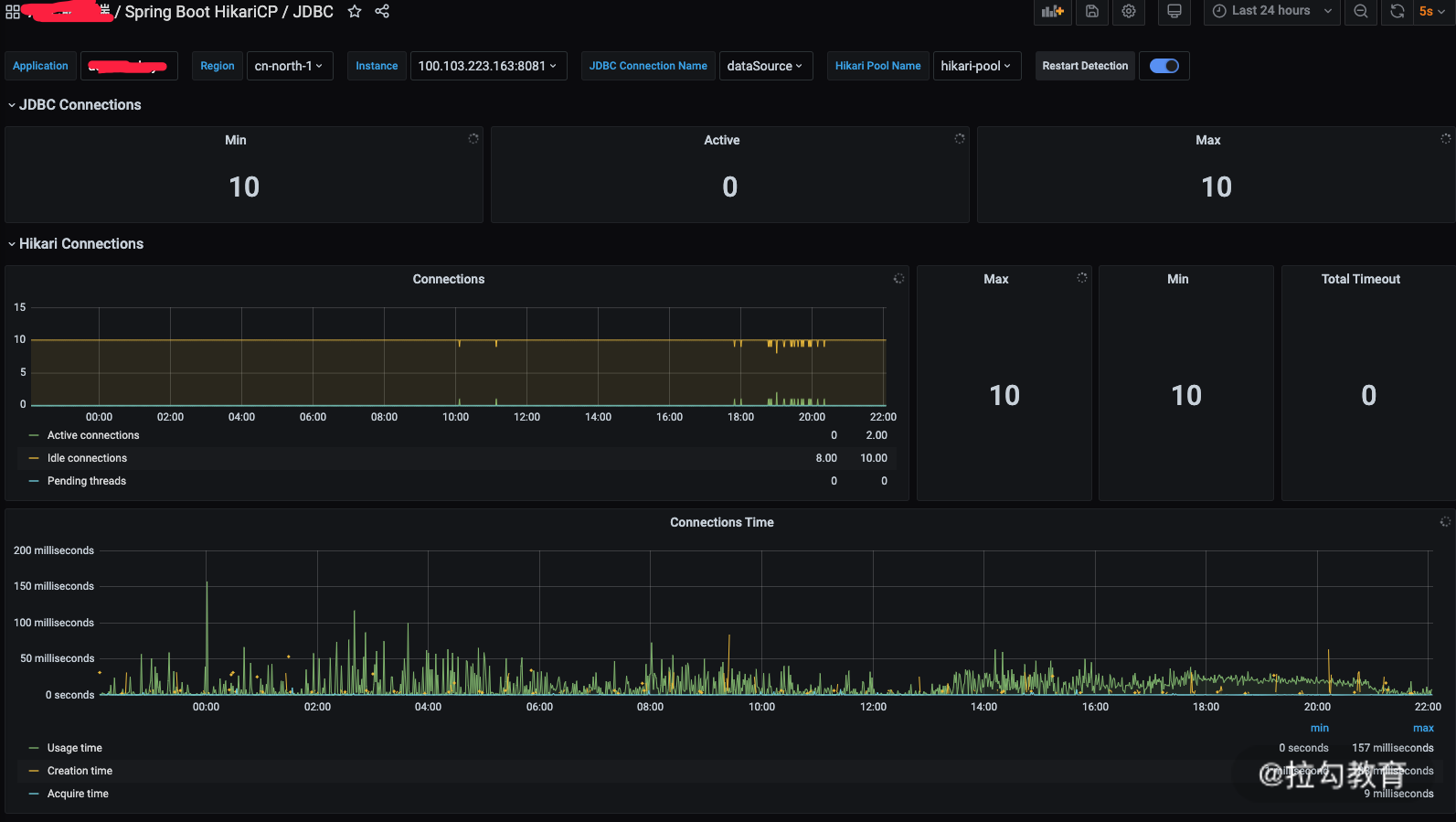
我们通过这种标准的模板就可以知道 JDBC 的连接情况、Hikari 的连接情况,以及每个连接请求时间、使用时间。这样对我们诊断 DB 性能问题非常有帮助。
下面对其中一些关键指标作一下说明:
- totalConnections:总连接数,包括空闲的连接和使用中的连接,即 totalConnections = activeConnection + idleConnections;
- idleConnections:空闲连接数,也叫可用连接数,也就是连接池里面现成的 DB 连接数;
- activeConnections:活跃连接数,非业务繁忙期一般都是 0,很快就会释放到连接池里面去;
- pendingThreads:正在等待连接的线程数量。排查性能问题时,这个指标是一个重要的参考指标,如果正在等待连接的线程在相当长一段时间内数量较多,说明我们的连接没有利用好,是不是占用连接的时间过长了?一旦有 pendingThreads 的数量了可以发个告警,查查原因,或者优化一下连接池;
- maxConnections:最大连接数,统计指标,统计到目前为止连接的最大数量。
- minConnections:最小连接数,统计指标,统计到目前为止连接的最小数量。
- usageTime:每个连接使用的时间,当连接被回收的时候会记录此指标;一般都在 m、s 级别,一旦到 s 级别了可以发个告警;
- acquireTime:获取每个连接需要等待时间,一个请求获取数据库连接后或者因为超时失败后,会记录此指标。
- connectionCreateTime:连接创建时间。
在 Granfan 图表或者 Prometheus 里面都可以配置一些邮件或者短信等告警,这样当我们 DB 连接池发生问题的时候就能实时知道。
以上内容涉及了一些运维知识,感兴趣的同学可以研究一下 Prometheus Operator:https://github.com/prometheus-operator/prometheus-operator。我们掌握了 Hikari 的数据源的配置,那么会有同学问数据源 AliDruid 是怎么配置的呢?
AliDruidDataSource 的配置与介绍
在实际工作中,由于 HikariCP 和 Druid 各有千秋,国内的很多开发者都使用 AliDruid 作为数据源,我们看看都是怎么配置的,每一步都很简单。
第一步:引入 Gradle 依赖。
复制代码
implementation 'com.alibaba:druid-spring-boot-starter:1.2.1'- 1
第二步:配置数据源。
复制代码
spring.datasource.druid.url= # 或spring.datasource.url= spring.datasource.druid.username= # 或spring.datasource.username= spring.datasource.druid.password= # 或spring.datasource.password= spring.datasource.druid.driver-class-name= #或 spring.datasource.driver-class-name=- 1
- 2
- 3
- 4
第三步:配置连接池。
复制代码
spring.datasource.druid.initial-size= spring.datasource.druid.max-active= spring.datasource.druid.min-idle= spring.datasource.druid.max-wait= spring.datasource.druid.pool-prepared-statements= spring.datasource.druid.max-pool-prepared-statement-per-connection-size= spring.datasource.druid.max-open-prepared-statements= #和上面的等价 spring.datasource.druid.validation-query= spring.datasource.druid.validation-query-timeout= spring.datasource.druid.test-on-borrow= spring.datasource.druid.test-on-return= spring.datasource.druid.test-while-idle= spring.datasource.druid.time-between-eviction-runs-millis= spring.datasource.druid.min-evictable-idle-time-millis= spring.datasource.druid.max-evictable-idle-time-millis= spring.datasource.druid.filters= #配置多个英文逗号分隔 ....//more- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
通过以上三步就可以完成 Druid 数据源的配置了,需要注意的是,我们需要把 HikariCP 数据源给排除掉,而其他 Druid 的配置,比如监控,官方的介绍还是挺详细的:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter,你可以看一下,我就不多说了。
其官方的源码也比较简单,按照我们上面分析 HikariCP 数据源的方法,可以找一下 aliDruid 的源码,其加载的入口类:https://github.com/alibaba/druid/blob/master/druid-spring-boot-starter/src/main/java/com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.java,你一步一步去查看即可,我在这里就不重点介绍了。
接下来我们看看数据里面的表的字段,和我们实体里面字段的映射策略都有哪些。
Naming 命名策略详解及其实践
我们在配置 @Entity 时,一定会有同学好奇表名、字段名、外键名、实体字段、@Column 和数据库的字段之间,映射关系是怎么样的?默认规则映射规则又是什么?如果和默认不一样该怎么扩展?
我们下面只介绍 Hibernate 5 的命名策略,因为 H4 已经不推荐使用了,我们直接看最新的即可。Hibernate 5 里面把实体和数据库的字段名和表名的映射分成了两个步骤。
第一步:通过***ImplicitNamingStrategy***先找到实例里面定义的逻辑的字段名字。
这是通过ImplicitNamingStrategy 的实现类指定逻辑字段查找策略,也就是当实体里面定义了 @Table、@Column 注解的时候,以注解指定名字返回;而当没有这些注解的时候,返回的是实体里面的字段的名字。
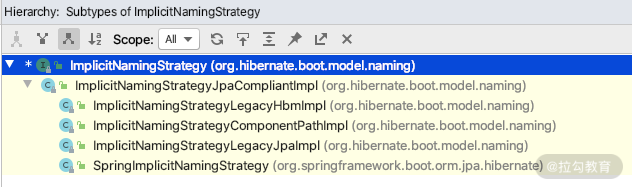
其中,org.hibernate.boot.model.naming.ImplicitNamingStrategy 是一个接口,ImplicitNamingStrategyJpaCompliantImpl 这个实现类兼容 JPA 2.0 的字段映射规范。除此之外,还有如下四个实现类:
- ImplicitNamingStrategyLegacyHbmImpl:兼容 Hibernate 老版本中的命名规范;
- ImplicitNamingStrategyLegacyJpaImpl:兼容 JPA 1.0 规范中的命名规范;
- ImplicitNamingStrategyComponentPathImpl:@Embedded 等注解标志的组件处理是通过 attributePath 完成的,因此如果我们在使用 @Embedded 注解的时候,如果要指定命名规范,可以直接继承这个类来实现;
- SpringImplicitNamingStrategy:默认的 spring data 2.2.3 的策略,只是扩展了 ImplicitNamingStrategyJpaCompliantImpl 里面的 JoinTableName 的方法,如下图所示:
这里我们只需要关心 SpringImplicitNamingStrategy 就可以了,其他的我们基本上用不到。那么 SpringImplicitNamingStrategy 效果如何呢?我们举个例子看一下 UserInfo 实体,代码如下:
复制代码
@Entity @Table(name = "userInfo") public class UserInfo extends BaseEntity { @Id @GeneratedValue(strategy= GenerationType.AUTO) private Long id; private Integer ages; private String lastName; @Column(name = "myAddress") private String emailAddress; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过第一步可以得到如下逻辑字段的映射结果:
复制代码
UserInfo -> userInfo id->id ages->ages lastName -> lastName emailAddress -> myAddress- 1
- 2
- 3
- 4
- 5
第二步:通过 PhysicalNamingStrategy 将逻辑字段转化成数据库的物理字段名字。
它的实现类负责将逻辑字段转化成带下划线,或者统一给字段加上前缀,又或者加上双引号等格式的数据库字段名字,其主要的接口是:org.hibernate.boot.model.naming.PhysicalNamingStrategy,而它的实现类也只有两个,如下图所示:

1.PhysicalNamingStrategyStandardImpl:这个类什么都没干,即直接将第一个步骤得到的逻辑字段名字当成数据库的字段名字使用。这个主要的应用场景是,如果某些字段的命名格式不是下划线的格式,我们想通过 @Column 的方式显示声明的话,可以把默认第二步的策略改成 PhysicalNamingStrategyStandardImpl。那么如果再套用第一步的例子,经过这个类的转化会变成如下形式:
复制代码
userInfo -> userInfo id->id ages->ages lastName -> lastName myAddress -> myAddress- 1
- 2
- 3
- 4
- 5
可以看出来逻辑名字到物理名字是保持不变的。
2.SpringPhysicalNamingStrategy:这个类是将第一步得到的逻辑字段名字的大写字母前面加上下划线,并且全部转化成小写,将会标识出是否需要加上双引号。此种是默认策略。我们举个例子,第一步得到的逻辑字段就会变成如下映射:
复制代码
userInfo -> user_info id->id ages->ages lastName -> last_name myAddress -> my_address- 1
- 2
- 3
- 4
- 5
我们把刚才的实体执行一下,可以看到生成的表的结构如下:
复制代码
Hibernate: create table user_info (id bigint not null, create_time timestamp, create_user_id integer, last_modified_time timestamp, last_modified_user_id integer, version integer, ages integer, my_address varchar(255), last_name varchar(255), telephone varchar(255), primary key (id));- 1
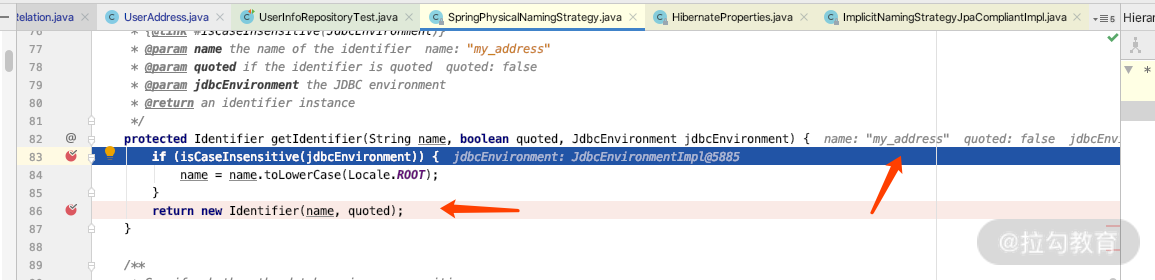
你也可以通过在 SpringPhysicalNamingStrategy 类里面设置断点,来一步一步地验证我们的说法,如下图所示:
以上就是 Naming 命名策略的详解及其实践,不知道我在这部分开头提到的那几个问题你有没有掌握,如果还是存在疑问,你要多跟着我的步骤实践几次。下面我们了解一下它的加载原理吧。
加载原理与自定义方法
如果我们修改默认策略,只需要在 application.properties 里面修改下面代码所示的两个配置,换成自己的自定义的类即可。
复制代码
spring.jpa.hibernate.naming.implicit-strategy=org.springframework.boot.orm.jpa.hibernate.SpringImplicitNamingStrategy spring.jpa.hibernate.naming.physical-strategy=org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy- 1
- 2
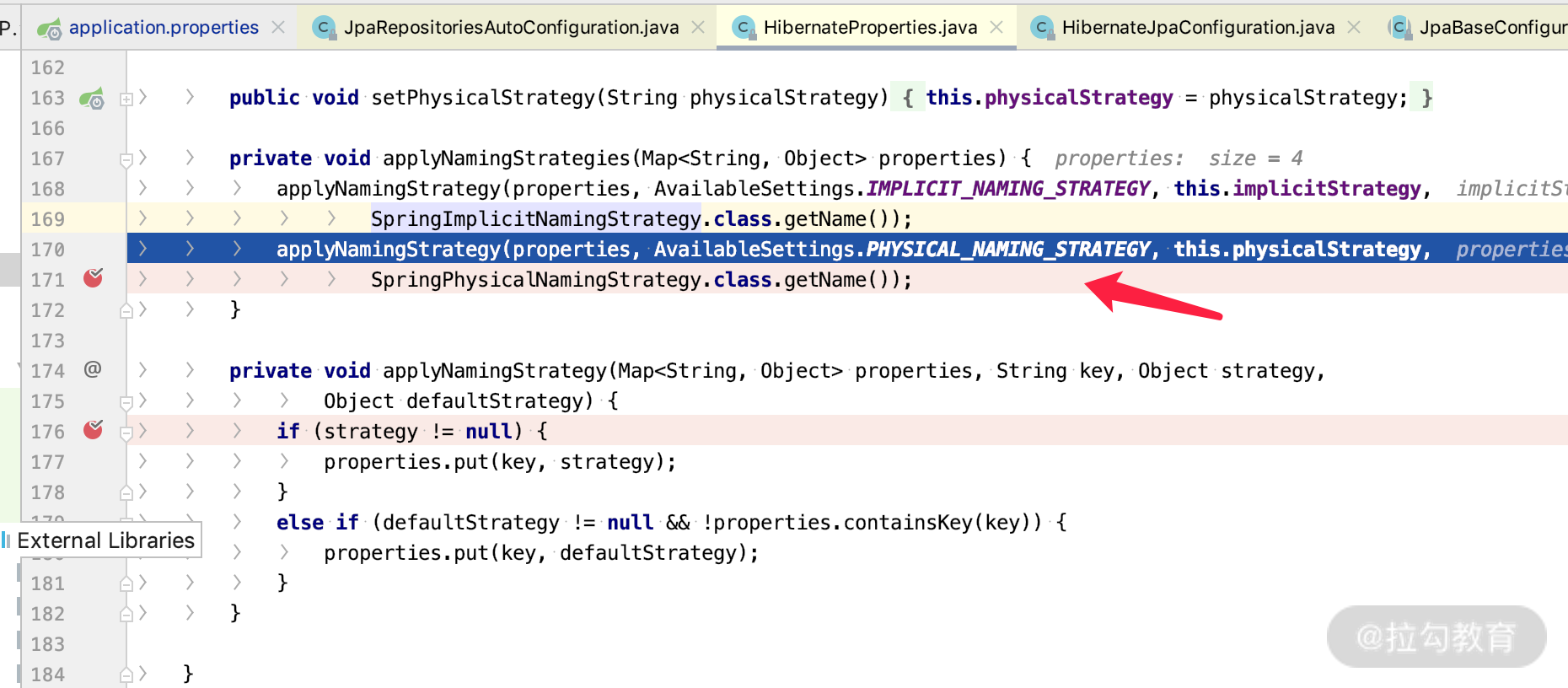
如果我们直接搜索:spring.jpa.hibernate 就会发现,其默认配置是在 org.springframework.boot.autoconfigure.orm.jpa.HibernateProerties 这类里面的,如下图所示的方法中进行加载。
其中,IMPLICIT_NAMING_STRATEGY 和 PHYSICAL_NAMING_STRATEGY 的值如下述代码所示,它是 Hibernate 5 的配置变量,用来改变 Hibernate的 naming 的策略。
复制代码
String IMPLICIT_NAMING_STRATEGY = "hibernate.implicit_naming_strategy"; String PHYSICAL_NAMING_STRATEGY = "hibernate.physical_naming_strategy";- 1
- 2
如果我们自定义的话,直接继承 SpringPhysicalNamingStrategy 这个类,然后覆盖需要实现的方法即可。那么它实际的应用场景都有哪些呢?
实际应用场景
有时候我们接触到的系统可能是老系统,表和字段的命名规范不一定是下划线形式,有可能驼峰式的命名法,也有可能不同的业务有不同的表名前缀。不管是哪一种,我们都可以通过修改第二阶段:物理映射的策略,改成 PhysicalNamingStrategyStandardImpl 的形式,请看代码。
复制代码
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl- 1
这样可以使 @Column/@Table 等注解的自定义值生效,或者改成自定义的 MyPhysicalNamingStrategy。不过我不建议你修改 implicit-strategy,因为没有必要,你只要在 physical-strategy 上做文章就足够了。
-
相关阅读:
js基础笔记学习279初步完成贪吃蛇运动2
wpf devexpress实现输入验证使用验证规则
R语言从入门到精通Day1之【R语言介绍】
ThreadLocal精进篇:子线程类InheritableThreadLocal
文件上传16.17关
【无标题】
关于IDEA没有显示日志输出?IDEA控制台没有显示Tomcat Localhost Log和Catalina Log 怎么办?
力扣周赛372 模拟 思维 位运算 java
GAME (HDU)(博弈论)
Mac/ipad/iphone之间复制粘贴失效的解决办法
- 原文地址:https://blog.csdn.net/sinat_32366329/article/details/133847263
