-
Python中列表生成器的使用
在Python中,列表生成器与列表推导式都属于列表的高级运用。列表推导式用于用简练的的代码生成列表,而列表生成器则用于元素比较多的列表,它可以在不占用过多内存的情况下,使用这种“大列表”。
相关链接1 列表推导式的相关内容,请参考Python中List推导式的使用方法-CSDN博客
使用列表生成器的方法有两种:一种是直接使用,另一种是通过自定义函数使用。
1 直接使用
1.1 语法
可以直接通过代码创建列表生成器,其语法如下:
(表达式 for循环 [if语句])从以上语法可以看出,列表生成器与列表推导式的格式非常相似,只是把方括号[]改为了圆括号()。
1.2 创建生成器
创建列表生成器的代码如图1所示:

图1 创建列表生成器
此时,ge1保存了创建的列表生成器,使用type(ge1)查看其类型为“generator”,即生成器。
1.3 使用生成器
此时的ge1只是一个生成器,可以把它看作是一个“算法”变量,ge1并不包括相关数据。可以通过next()方法或者for循环来动态的产生数据。
1.3.1 next()方法产生数据
可以通过以下代码产生数据:
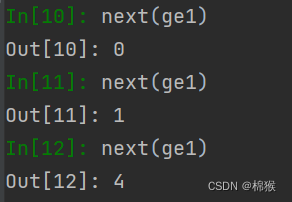
图2 通过next()产生数据
注意1 通过next()方法产生数据时,只能“向前”产生数据,不能再次产生之前的数据了。
注意2 当所有数据产生完毕后,再次调用next()方法会抛出异常。
1.3.2 for循环产生数据
使用for循环产生数据的代码如图3所示。

图3 通过for循环产生数据
注意3 通过for循环产生数据时,需要重新创建一个新的列表生成器,这样才能产生完整的数据,否则产生的数据会接着之前调用的next()方法的数据,如图4所示。
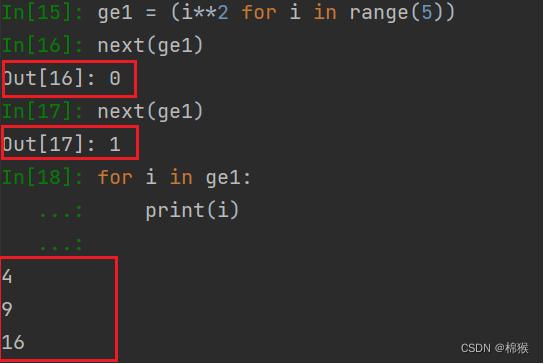
图4 for循环产生的不完整数据
2 自定义函数使用
在自定义函数中,通过关键字yield使用列表生成器,代码如图5所示。
图5 通过自定义函数使用列表生成器
从图中可以看出,在自定义函数f()中,使用yield返回了i的平方。调用f(),并且将返回值保存在ge2中,此时的ge2的类型为generator,即列表生成器。接下来就可以通过next()或者for循环通过列表生成器来产生相应数据了。
3 生成器与推导式的区别
列表推导式在创建的时候,已经产生了相应的数据,即已经占用了内存;而生成器在创建的时候,只是创建了“算法”,并没有创建相应数据,在后续调用next()或者for循环时,才会产生相应的数据。也就是说,列表推导式是不管数据用不用,先产生,用哪个的时候在去查找;而生成器是不产生数据,用哪个数据时再来产生,这样,对于包含很多元素的列表,即“大列表”,使用生成器就可以节约内存。
在PyCharm中定义如图6所示的两个变量。
图6 定义生成器和推导式变量
其中,ge1是列表生成器变量,co1是列表推导式变量,调试该代码,得到ge1与co1的结构如图7所示。

图7 co1与ge1的结构
从上图可以看到,列表推导式变量co1已经包含了所有数据;而列表生成器变量ge1仅仅是一个变量,未包含任何数据。
-
相关阅读:
Pycharm更换清华、阿里、豆瓣软件源提高依赖包下载速度
金融数学方法:有限差分法
网络模型的保存与读取
C#练习题7和8
@Slf4j打印异常信息打印出堆栈信息
Thrift 序列化协议浅析
C++二分算法的应用:乘法表中第k小的数
k3s 上的 kube-ovn 轻度体验
中国地表水体、大坝、水库和湖泊数据集
21天学习挑战赛--执行时长
- 原文地址:https://blog.csdn.net/hou09tian/article/details/133633096