-
【多线程进阶】synchronized 原理
前言
在前面章节中, 提到了多线程中的锁策略, 那么我们 Java 中的锁 synchronized 背后都采取了哪些锁策略呢? 又是如何进行工作的呢? 本节我们就来谈一谈.
关注收藏, 开始学习吧🧐
1. 基本锁策略
在 Java 中, synchronized 具有以下特性(这里以 JDK 1.8 为例):
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁. (自适应)
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁. (自适应)
- 轻量级锁部分是基于自旋锁实现的, 重量级锁部分是基于系统的互斥锁实现的.
- 是非公平锁. (不会遵守先来后到. 锁释放后, 哪个线程拿到锁各凭本事)
- 是可重入锁. (内部会记录哪个线程拿到了锁, 并且记录引用条数)
- 不是读写锁.
2. 加锁工作过程
JVM 将 synchronized 锁分为 无锁, 偏向锁, 轻量级锁, 重量级锁 状态. 会根据情况, 进行依次升级.
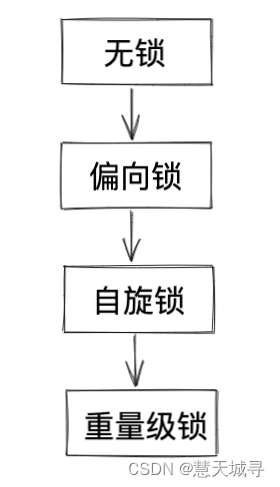
2.1 偏向锁
第一个尝试加锁的线程, 优先进入偏向锁状态.
- 偏向锁不是真的 “加锁”, 只是给对象头中做一个 “偏向锁的标记”, 记录这个锁属于哪个线程.
- 如果后续没有其他线程来竞争该锁, 那么就不用进行其他同步操作了(避免了加锁解锁的开销)
- 如果后续有其他线程来竞争该锁(刚才已经在锁对象中记录了当前锁属于哪个线程了, 很容易识别当前申请锁的线程是不是之前记录的线程), 那就取消原来的偏向锁状态, 进入一般的轻量级锁状态.
- 偏向锁本质上相当于 “延迟加锁” . 能不加锁就不加锁, 尽量来避免不必要的加锁开销. 但是该做的标记还是得做的, 否则无法区分何时需要真正加锁.
2.2 轻量级锁
随着其他线程进入竞争, 偏向锁状态被消除, 进入轻量级锁状态(自适应的自旋锁). 此处的轻量级锁就是通过 CAS(Compare And Swap) 来实现. CAS 就是字面意思比较并交换, 之后会有章节来讲 CAS 是什么.
- 通过 CAS 检查并更新一块内存 (比如 null => 该线程引用)
- 如果更新成功, 则认为加锁成功
- 如果更新失败, 则认为锁被占用, 继续自旋式的等待(并不放弃 CPU).
自旋操作是一直让 CPU 空转, 比较浪费 CPU 资源. 但此处的自旋并不会一直持续进行, 而是达到一定的时间/重试次数, 就不再自旋了. 就会升级为重量级锁, 也就是所谓的 “自适应”.
2.3 重量级锁
如果竞争进一步激烈, 自旋不能快速获取到锁状态, 就会膨胀为重量级锁. 此处的重量级锁就是指用到内核提供的 mutex .
- 执行加锁操作, 先进入内核态.
- 在内核态判定当前锁是否已经被占用
- 如果该锁没有占用, 则加锁成功, 并切换回用户态.
- 如果该锁被占用, 则加锁失败. 此时线程进入锁的等待队列, 挂起. 等待被操作系统唤醒.
- 经历了一系列的沧海桑田, 这个锁被其他线程释放了, 操作系统也想起了这个挂起的线程, 于是唤醒这个线程, 尝试重新获取锁.
3. 其他的优化操作
3.1 锁消除
有些应用程序的代码中, 用到了 synchronized, 但其实没有在多线程环境下. (例如 StringBuffer)
StringBuffer sb = new StringBuffer(); sb.append("a"); sb.append("b"); sb.append("c"); sb.append("d");- 1
- 2
- 3
- 4
- 5
此时每个 append 的调用都会涉及加锁和解锁. 但如果只是在单线程中执行这个代码, 那么这些加锁解锁操作是没有必要的, 白白浪费了一些资源开销.
而 JVM + 编译器, 会智能的判定, 当前的代码, 是否有必要进行加锁. 在其认为没有必要加锁的情况下, 程序员写了加锁, 就会在编译时把加锁操作自动删除掉. 当然, 在进行优化时, 是会保证优化前后逻辑是一致的.
3.2 锁粗化
一段逻辑中如果出现多次加锁解锁, 编译器 + JVM 会自动进行锁的粗化.

关于锁的粒度
在加锁操作中包含的要执行的代码越多, 我们就认为锁的粒度越大.

实际开发过程中, 使用细粒度锁, 是期望释放锁的时候其他线程能使用锁.但是实际上可能并没有其他线程来抢占这个锁. 这种情况 JVM 就会自动把锁粗化, 避免频繁申请释放锁.
总结
✨ 本文主要讲解了 Java 中 synchronized 锁的一些原理, 是如何进行加锁的, 加锁工程又是怎样的, 以及一些内部的优化操作.
✨ 想了解更多的多线程知识, 可以收藏一下本人的多线程学习专栏, 里面会持续更新本人的学习记录, 跟随我一起不断学习.
✨ 感谢你们的耐心阅读, 博主本人也是一名学生, 也还有需要很多学习的东西. 写这篇文章是以本人所学内容为基础, 日后也会不断更新自己的学习记录, 我们一起努力进步, 变得优秀, 小小菜鸟, 也能有大大梦想, 关注我, 一起学习.再次感谢你们的阅读, 你们的鼓励是我创作的最大动力!!!!! -
相关阅读:
VS code运行vue项目
SQL注入简介
算法竞赛Java数据结构与算法类详解
linux yum源被禁用,yum源管理
第二证券:“零容忍”执法 资本市场加大防假打假力度
MySQL表名区分不区分大小写,规则是怎样
品牌创意二维码营销活动:MoneyLion 在纽约全城“撒钱”,月增百万级曝光!
强化学习+数据库简单小结
【CSS】css常用复杂选择器都有哪些?看这一篇就够了_07
DataFrame的创建
- 原文地址:https://blog.csdn.net/qq_60366454/article/details/133554953