-
强化学习+数据库简单小结
[1]主要利用RL实现在有限样本下学习最佳的数据库配置。设计的奖励函数可以有效地提高调优效率,DDPG算法可以在高维连续空间中找到最优配置
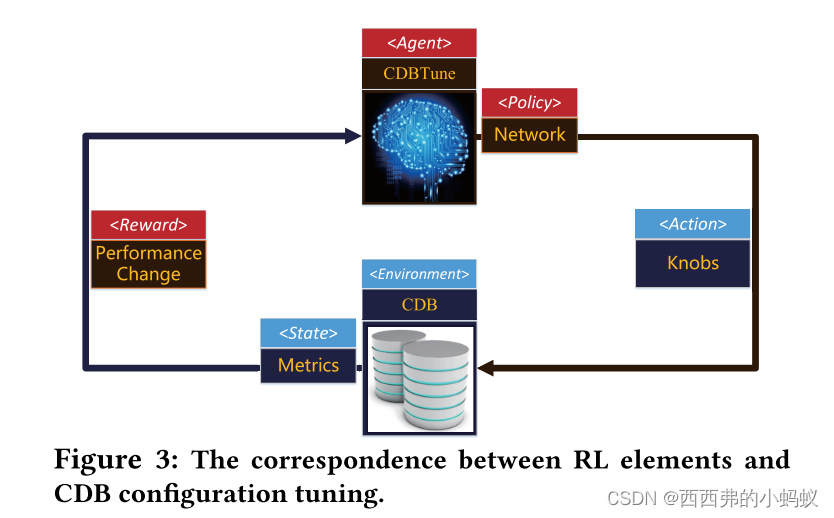
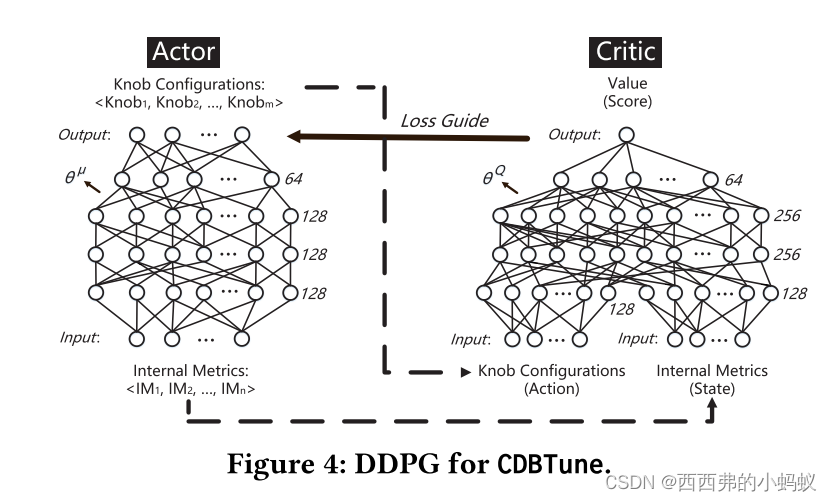
基本思想:我们尝试了RL中最经典的Qlearning和DQN模型,但这两种方法都未能解决高维空间(数据库状态,knobs组合)和连续动作(连续knobs)的问题。最后,采用基于策略的深度确定性策略梯度方法(DDPG),有效地克服了上述缺点。此外,作为RL的灵魂,奖励函数(reward function, RF)的设计至关重要,直接影响模型的效率和质量。因此,通过模拟DBA的调优体验,设计更符合调优场景的奖励函数,使算法高效执行。
本文中的reward是调优前后的性能差值。policy是给定一个CDB状态,如果调用一个操作(例如,一个旋钮调优),策略通过将操作应用于原始状态来保持下一个状态。这里的策略是深度神经网络,它保持输入(数据库状态)、输出(旋钮)和不同状态之间的转换。RL的目标是学习最好的策略
State是内部指标(例如在一段时间内从磁盘读取或写入页面的计数器)代表了CDB的当前状态。
Action是 旋钮调优操作,在CDB对应的状态下,CDB根据最新的策略执行相应的动作。
本文在学习价值函数时,没有采用Q-learning,DQN 而是采用Deep Deterministic Policy Gradient
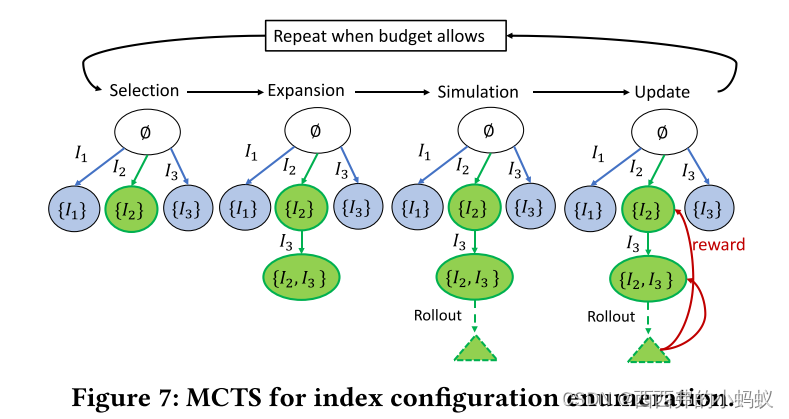
[2]索引调优的目的是为输入工作负载找到最优的索引配置。索引调优的目的是为输入工作负载找到最优的索引配置。这需要在 exploration 和 exploitation之间找到平衡。


States. We define the set of states S of the MDP as all index configurations in the search space.
Actions. For a state 𝑠 ∈ S, we define its set of actions A(𝑠) as the indexes that are not included by 𝑠


dynamic programming to find 𝑉∗(𝑠) or 𝑄∗(𝑠, 𝑎)计算时间和内存数量将是巨大的, 因此,我们必须为这类MDP问题寻求近似的解决方案。接下来,我们将展示如何调整蒙特卡洛树搜索(MCTS),这是一种流行的RL技术,不需要显式地表示整个状态/动作空间[14],以解决可伸缩性的挑战。

[3]提出了一种基于强化学习(reinforcement learning, RL)的查询生成框架LearnedSQLGen,用于生成满足约束的查询。LearnedSQLGen采用一种探索-利用策略,从查询执行反馈中学习到查询约束,然后根据查询约束挖掘生成方向。我们明智地设计了RL中的奖励函数,以准确地指导生成过程。我们还在模型中集成了一个有限状态机来生成有效的SQL查询。

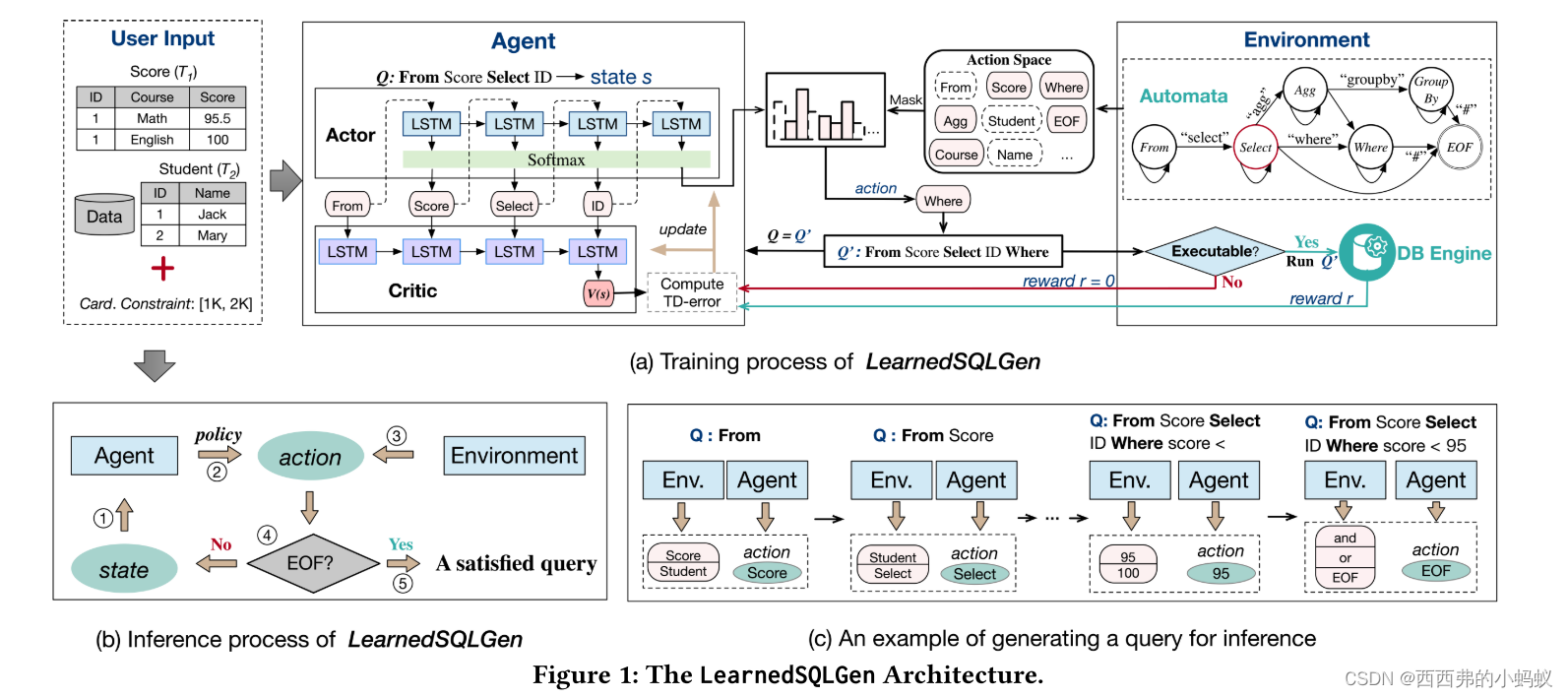
最初,训练过程如算法1所示,以约束C和数据库D作为输入,整个动作空间A是固定的。然后开始训练步骤。提出使用RL模型生成查询,并将这些查询与其估计的基数关联起来作为训练数据来更新模型。
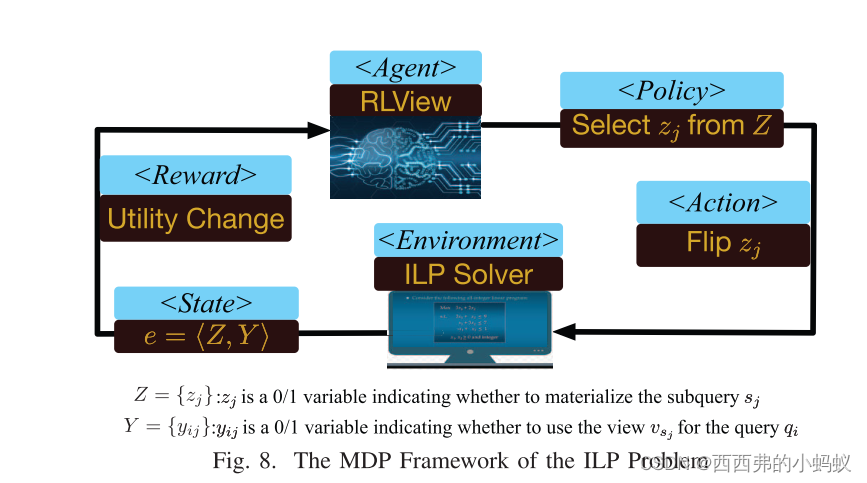
【4】提出了一种视图自动生成方法,该方法明智地选择“高度有益”的子查询生成实体化视图。然而,有两个挑战。(1)如何评估使用物化视图进行查询的好处?(2)如何选择最优子查询生成实体化视图?为了应对第二个挑战,我们将迭代优化过程建模为一个MDP(马尔可夫决策过程),并使用深度强化学习模型来解决问题。
[1]An End-to-End Automatic Cloud Database TuningSystem Using Deep Reinforcement Learning
[2]Budget-aware Index Tuning with Reinforcement Learning[3]LearnedSQLGen: Constraint-aware SQL Generation using Reinforcement Learning
[4]Automatic View Generation with Deep Learning and Reinforcement Learning
-
相关阅读:
智云通CRM:如何将客户回绝扭转乾坤?
GIS工具maptalks开发手册(二)01-11——渲染文字及参数注释
Lstm+transformer的刀具磨损预测
凸度(bulge)是AutoCAD 中独有的概念
鸿蒙OS app开发环境搭建
接口测试常用工具及测试方法
字符串题目
Python算法题2023 输出123456789到98765432中完全不包含2023的数有多少
Spring Cloud 系列:基于Seata 实现 XA模式
JAVA毕业设计酒店管理系统设计与实现计算机源码+lw文档+系统+调试部署+数据库
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/125897277