-
DataFrame的创建
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计1197字,阅读大概需要3分钟1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
DataFrame的创建
3. 实验学时:
4. 实验原理:
Spark支持从RDD创建DataFrame。另外,Spark还为多个外部数据源提供了内置的支持,比如JSON、CSV、JDBC、HDFS、Parquet、MYSQL、Amazon S3,等等。
5. 实验目的:
掌握通过不同数据源创建DataFrames。
掌握排序算子的使用。6. 实验内容:
使用Spark库将不同数据来源的数据转换为DataFrame,并对数据结果进行展示。掌握序列、RDD以及多种外部数据的转换和创建方法。具体包含如下内容:
1、序列与DataFrame
- SparkSession range方法创建单列DataFrame
- 元组list转换为多列DataFrame
2、RDD与DataFrame
- 从RDD创建DataFrame
- createDataFrame来将RDD转换为DataFrame
3、外部数据与DataFrame
- 从CSV文件创建DataFrame
- 从JSON创建DataFrame
- 从Parquet文件创建Dataframe
- 从ORC文件创建DataFrame
- 从JDBC创建DataFrame7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK 1.8,Spark-2.3.2,Hadoop-2.7.3,zeppelin-0.8.18. 实验步骤:
8.1 环境准备
1、在终端窗口下,输入以下命令,分别启动HDFS集群、Spark集群和Zeppelin服务器:
1. $ start-dfs.sh 2. $ cd /opt/spark 3. $ ./sbin/start-all.sh 4. $ zeppelin-daemon.sh start- 1
- 2
- 3
- 4
2、将本地数据上传至HDFS上,分别执行以下命令上传数据:
1. $ hdfs dfs -mkdir -p /data/dataset 2. $ hdfs dfs -put /data/dataset/resources /data/dataset/ 3. $ hdfs dfs -put /data/dataset/batch /data/dataset/- 1
- 2
- 3
3、因为后面的实验中需要访问MySQL数据库,所以先要将MySQL的jdbc驱动程序拷贝到Spark的jars目录下。在终端窗口,执行如下的命令:
1. $ cp /data/software/mysql-connector-java-5.1.45-bin.jar /opt/spark/jars/- 1
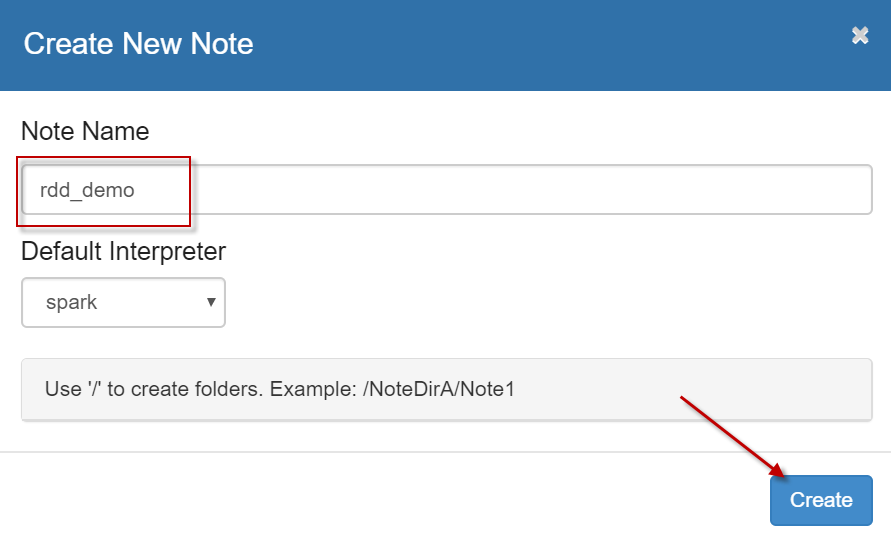
4、启动浏览器,打开zeppelin notebook首页,点击【Create new note】链接,创建一个新的笔记本,名字为【rdd_demo】,解释器默认使用【spark】,如下图所示:
8.2 序列与DataFream
1、 从SparkSession的range方法创建单列DataFrame
在zeppelin中执行如下代码:1. // 创建单列DataFrame,指定列名 2. var df1 = spark.range(5).toDF("num") 3. df1.show() 4. 5. // 另外,还可以指定范围的起始(含)和结束值(不含) 6. var df2 = spark.range(5,10).toDF("num") 7. df2.show() 8. 9. // 另外,还可以指定步长 10. var df3 = spark.range(5,15,2).toDF("num") 11. df3.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
同时按下【shift+enter】对程序进行输出。输出结果如下所示:
1. +---+ 2. |num| 3. +---+ 4. | 0| 5. | 1| 6. | 2| 7. | 3| 8. | 4| 9. +---+ 10. 11. +---+ 12. |num| 13. +---+ 14. | 5| 15. | 6| 16. | 7| 17. | 8| 18. | 9| 19. +---+ 20. 21. +---+ 22. |num| 23. +---+ 24. | 5| 25. | 7| 26. | 9| 27. | 11| 28. | 13| 29. +---+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2、将一个seq集合转换为多列DataFrame
在zeppelin中执行如下代码:1. // 定义一个Seq,包含两个元组元素 2. var movies=Seq( 3. ("Damon, Matt", "The Bourne Ultimatum", 2007), 4. ("Damon, Matt", "Good Will Hunting", 1997) 5. ) 6. 7. // 列表创建df 8. val moviesDF = spark.createDataFrame(movies).toDF("actor", "title", "year") 9. 10. // 输出模式 11. moviesDF.printSchema() 12. 13. // 显示 14. moviesDF.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
同时按下【shift+enter】对程序进行输出。输出结果如下所示:
1. root 2. |-- actor: string (nullable = true) 3. |-- title: string (nullable = true) 4. |-- year: integer (nullable = false) 5. 6. +-----------+--------------------+----+ 7. | actor| title|year| 8. +-----------+--------------------+----+ 9. |Damon, Matt|The Bourne Ultimatum|2007| 10. |Damon, Matt| Good Will Hunting|1997| 11. +-----------+--------------------+----+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8.3 RDD与DataFrame
1、从RDD创建DataFrame
在zeppelin中执行如下代码:1. // 调用RDD的toDF显式函数,将RDD转换到DataFrame,使用指定的列名。 2. // 列的类型是从RDD中的数据推断出来的。 3. import scala.util.Random 4. import org.apache.spark.sql.types._ 5. 6. // 构造RDD 7. var rdd = sc.parallelize(1 to 11).map(x => (x,scala.util.Random.nextInt(100)*x)) 8. println(rdd.getClass.getSimpleName) // 查看返回的rdd的类型 9. 10. // 将RDD转换到DataFrame[Row] 11. var kvDF = rdd.toDF("col1","col2") 12. 13. // 输出DataFrame Schema 14. kvDF.printSchema() 15. 16. // 显示 17. kvDF.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
同时按下【shift+enter】对程序进行输出。输出内容如下所示:
1. MapPartitionsRDD 2. root 3. |-- col1: integer (nullable = false) 4. |-- col2: integer (nullable = false) 5. 6. +----+----+ 7. |col1|col2| 8. +----+----+ 9. | 1| 57| 10. | 2| 94| 11. | 3| 114| 12. | 4| 260| 13. | 5| 235| 14. | 6| 552| 15. | 7| 476| 16. | 8| 104| 17. | 9| 225| 18. | 10| 150| 19. | 11| 473| 20. +----+----+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、使用createDataFrame来将RDD转换为DataFrame
指定一个自定义一个schema,显示设置数据类型。在zeppelin中执行如下代码:1. // 编程创建一个schema,然后用该schema指定一个RDD。 2. // 最后,提供该RDD和schema给函数createDataFrame来转换为DataFrame 3. import org.apache.spark.sql._ 4. import org.apache.spark.sql.types._ 5. 6. // 指定一个Schema(模式) 7. val schema = StructType( 8. List( 9. StructField("id", IntegerType, true), 10. StructField("name", StringType, true), 11. StructField("age", IntegerType, true) 12. ) 13. ) 14. 15. // 构造一个RDD 16. var peopleRDD = sc.parallelize(List(Row(1,"张三",30),Row(2, "李四", 25))) 17. 18. // 从给定的RDD应用给定的Schema创建一个DataFrame 19. var peopleDF = spark.createDataFrame(peopleRDD, schema) 20. 21. // 查看DataFrame Schema 22. peopleDF.printSchema() 23. 24. // 输出 25. peopleDF.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
同时按下【shift+enter】对程序进行输出。输出内容如下所示:
1. root 2. |-- id: integer (nullable = true) 3. |-- name: string (nullable = true) 4. |-- age: integer (nullable = true) 5. 6. +---+----+---+ 7. | id|name|age| 8. +---+----+---+ 9. | 1| 张三| 30| 10. | 2| 李四| 25| 11. +---+----+---+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8.4 读取外部数据源
Spark SQL开箱即用地支持六个内置的数据源:Text、CSV、JSON、Parquet、ORC和JDBC。Spark SQL中用于读写这些数据的两个主要类分别是DataFrameReader和DataFrameWriter,它们的实例分别作为SparkSession类的read和write字段。
1、从CSV文件创建DataFrame
在zeppelin中执行如下代码:1. // 1、读取文本文件 2. var file = "/data/dataset/resources/people.txt" 3. var txtDF = spark.read.text(file) 4. 5. txtDF.printSchema() 6. txtDF.show()- 1
- 2
- 3
- 4
- 5
- 6
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- value: string (nullable = true) 3. 4. +-----------+ 5. | value| 6. +-----------+ 7. |Michael, 29| 8. | Andy, 30| 9. | Justin, 19| 10. +-----------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读取CSV文件,在zeppelin中执行如下代码:
1. // 2、读取CSV文件,使用类型推断 2. var file = "/data/dataset/batch/movies.csv" 3. var movies = spark.read.option("header","true").csv(file) 4. 5. movies.printSchema() 6. 7. println(movies.count()) 8. movies.show(5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- actor: string (nullable = true) 3. |-- title: string (nullable = true) 4. |-- year: string (nullable = true) 5. 6. 31394 7. +-----------------------+----------------+-----+ 8. | actor| title|year| 9. +-----------------------+----------------+-----+ 10. | McClure, Marc (I)|Freaky Friday|2003| 11. | McClure, Marc (I)| Coach Carter|2005| 12. | McClure, Marc (I)| Superman II|1980| 13. | McClure, Marc (I)| Apollo 13|1995| 14. | McClure, Marc (I)| Superman|1978| 15. +-----------------------+------------------+-------+ 16. only showing top 5 rows- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
读取CSV文件,自定义schema。在zeppelin中执行如下代码:
1. import org.apache.spark.sql._ 2. import org.apache.spark.sql.types._ 3. 4. // 1、读取CSV文件,自定义schema 5. var file = "/data/dataset/batch/movies.csv" 6. 7. // 指定一个Schema(模式) 8. var fields= List( 9. StructField("actor_name", StringType, true), 10. StructField("movie_title", StringType, true), 11. StructField("produced_year", LongType, true) 12. ) 13. val schema = StructType(fields) 14. 15. var movies3 = spark.read.option("header","true").schema(schema).csv(file) 16. movies3.printSchema() 17. movies3.show(5,false)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- actor_name: string (nullable = true) 3. |-- movie_title: string (nullable = true) 4. |-- produced_year: long (nullable = true) 5. 6. +----------------------+----------------+--------------------+ 7. |actor_name |movie_title |produced_year| 8. +----------------------+----------------+--------------------+ 9. |McClure, Marc (I)|Freaky Friday|2003 | 10. |McClure, Marc (I)|Coach Carter |2005 | 11. |McClure, Marc (I)|Superman II |1980 | 12. |McClure, Marc (I)|Apollo 13 |1995 | 13. |McClure, Marc (I)|Superman |1978 | 14. +----------------------+-----------------+--------------------+ 15. only showing top 5 rows- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2、从JSON创建DataFrame
读取JSON文件。在zeppelin中执行如下代码:1. // 4、读取JSON文件 2. // Spark自动地根据keys推断schema,并相应地创建一个DataFrame 3. var jsonFile = "/data/dataset/batch/movies.json" 4. var movies5 = spark.read.json(jsonFile) 5. 6. movies5.printSchema() 7. movies5.show(5,false)- 1
- 2
- 3
- 4
- 5
- 6
- 7
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- actor_name: string (nullable = true) 3. |-- movie_title: string (nullable = true) 4. |-- produced_year: long (nullable = true) 5. 6. +-----------------+------------------+-------------+ 7. |actor_name |movie_title |produced_year| 8. +-----------------+------------------+-------------+ 9. |McClure, Marc (I)|Coach Carter |2005 | 10. |McClure, Marc (I)|Superman II |1980 | 11. |McClure, Marc (I)|Apollo 13 |1995 | 12. |McClure, Marc (I)|Superman |1978 | 13. |McClure, Marc (I)|Back to the Future|1985 | 14. +-----------------+------------------+-------------+ 15. only showing top 5 rows- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3、从Parquet文件创建Dataframe
读取Parquet文件。在zeppelin中执行如下代码:1. // 5、读取Parquet文件 2. var parquetFile = "/data/dataset/batch/movies.parquet" 3. 4. // Parquet是默认的格式,因此当读取时我们不需要指定格式 5. var movies9 = spark.read.load(parquetFile) 6. 7. movies9.printSchema() 8. movies9.show(5) 9. 10. // 如果我们想要更加明确,我们可以指定parquet函数 11. var movies10 = spark.read.parquet(parquetFile) 12. 13. movies10.printSchema() 14. movies10.show(5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- actor_name: string (nullable = true) 3. |-- movie_title: string (nullable = true) 4. |-- produced_year: long (nullable = true) 5. 6. +-----------------+------------------+-------------+ 7. | actor_name| movie_title|produced_year| 8. +-----------------+------------------+-------------+ 9. |McClure, Marc (I)| Coach Carter| 2005| 10. |McClure, Marc (I)| Superman II| 1980| 11. |McClure, Marc (I)| Apollo 13| 1995| 12. |McClure, Marc (I)| Superman| 1978| 13. |McClure, Marc (I)|Back to the Future| 1985| 14. +-----------------+------------------+-------------+ 15. only showing top 5 rows 16. 17. root 18. |-- actor_name: string (nullable = true) 19. |-- movie_title: string (nullable = true) 20. |-- produced_year: long (nullable = true) 21. 22. +-----------------+------------------+-------------+ 23. | actor_name| movie_title|produced_year| 24. +-----------------+------------------+-------------+ 25. |McClure, Marc (I)| Coach Carter| 2005| 26. |McClure, Marc (I)| Superman II| 1980| 27. |McClure, Marc (I)| Apollo 13| 1995| 28. |McClure, Marc (I)| Superman| 1978| 29. |McClure, Marc (I)|Back to the Future| 1985| 30. +-----------------+------------------+-------------+ 31. only showing top 5 rows- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4、从ORC文件创建DataFrame
读取ORC文件。在zeppelin中执行如下代码:1. // 6、读取ORC文件 2. var orcFile = "/data/dataset/batch/movies.orc" 3. var movies11 = spark.read.orc(orcFile) 4. 5. movies11.printSchema() 6. movies11.show(5)- 1
- 2
- 3
- 4
- 5
- 6
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- actor_name: string (nullable = true) 3. |-- movie_title: string (nullable = true) 4. |-- produced_year: long (nullable = true) 5. 6. +-----------------+------------------+-------------+ 7. | actor_name| movie_title|produced_year| 8. +-----------------+------------------+-------------+ 9. |McClure, Marc (I)| Coach Carter| 2005| 10. |McClure, Marc (I)| Superman II| 1980| 11. |McClure, Marc (I)| Apollo 13| 1995| 12. |McClure, Marc (I)| Superman| 1978| 13. |McClure, Marc (I)|Back to the Future| 1985| 14. +-----------------+------------------+-------------+ 15. only showing top 5 rows- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5、从JDBC创建DataFrame
(1)首先启动MySQL服务器。在终端窗口中,执行以下命令:1. $ service mysql start- 1
(2)登录MySQL服务器。在终端窗口中,执行以下命令:
1. $ mysql -u root -p- 1
然后根据提示,输入登录密码:root。
(3)执行以下SQL语句,创建测试表:1. mysql> create database simple; 2. mysql> use simple; 3. mysql> create table peoples( 4. id int, 5. name varchar(20), 6. age int 7. ); 8. 9. //修改中文列的编码格式 10. mysql> alter table peoples change name name varchar(20) character set utf8; 11. 12. mysql> insert into peoples values 13. (1,"张三",23), 14. (2,"李四",21), 15. (3,"王老五",33); 16. mysql> select * from peoples; 17. mysql> exit;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(4)在zeppelin中执行如下代码:
1. // 7、从JDBC创建DataFrame 2. // 从MariaDB/MySQL服务器的一个表中读取数据 3. var mysqlURL= "jdbc:mysql://localhost:3306/simple" 4. var peoplesDF = spark.read.format("jdbc") 5. .option("driver", "com.mysql.jdbc.Driver") 6. .option("url", mysqlURL) 7. .option("dbtable", "peoples") 8. .option("user", "root") 9. .option("password","root") 10. .load() 11. 12. peoplesDF.printSchema() 13. peoplesDF.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
同时按下【shift+enter】对程序进行输出。输出内容如下:
1. root 2. |-- id: integer (nullable = true) 3. |-- name: string (nullable = true) 4. |-- age: integer (nullable = true) 5. 6. +---+----+---+ 7. | id|name|age| 8. +---+----+---+ 9. | 1| 张三| 23| 10. | 2| 李四| 21| 11. | 3| 王老五| 33| 12. +---+----+---+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过练习 Spark实现TopN,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
使用sortByKey算子,按key排序,然后再使用take算子,取前几个元素,就得到了 Top N 的结果。
12、实验测试
1、schema参数作用正确的是(){单选}
A、指定数据路径
B、指定列名
C、指定数据类型
D、指定索引13、实验拓展
1、给定一个集合元素,请编写代码,将其转换为DataFrame:
peoples = (“Michael,29”, “Andy,30”, “Justin,19”)
-
相关阅读:
10分钟掌握Go泛型
P1586 四方定理-完全背包(dp)
宝塔 xdebug idea 调试 php
优维EasyOps®全平台又一波新功能上线,操作体验更带劲
【飞控开发基础教程6】疯壳·开源编队无人机-SPI(六轴传感器数据获取)
Ascend C算子开发(入门)章节小测
c++调用Lua(table嵌套写法)
Docker搭建Redis cluster集群
实习记录--(海量数据如何判重?)--每天都要保持学习状态和专注的状态啊!!!---你的未来值得你去奋斗
python(10)
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125570576
