-
LLMs 用强化学习进行微调 RLHF: Fine-tuning with reinforcement learning
让我们把一切都整合在一起,看看您将如何在强化学习过程中使用奖励模型来更新LLM的权重,并生成与人对齐的模型。请记住,您希望从已经在您感兴趣的任务上表现良好的模型开始。您将努力使指导发现您的LLM对齐。首先,您将从提示数据集中传递一个提示。在这种情况下,“A dog is…”,传递给指导LLM,然后生成一个完成,这种情况下是"… a furry animal."一只毛茸茸的动物。接下来,您将将此完成和原始提示一起发送给奖励模型,作为提示完成对。奖励模型基于其训练的人类反馈评估对,然后返回一个奖励值。较高的值,如此处显示的0.24,表示更加对齐的响应。较不对齐的响应将获得较低的值,例如-0.53。然后,您将将这个提示完成对的奖励值传递给强化学习算法,以更新LLM的权重,并使其生成更加对齐、奖励更高的响应。
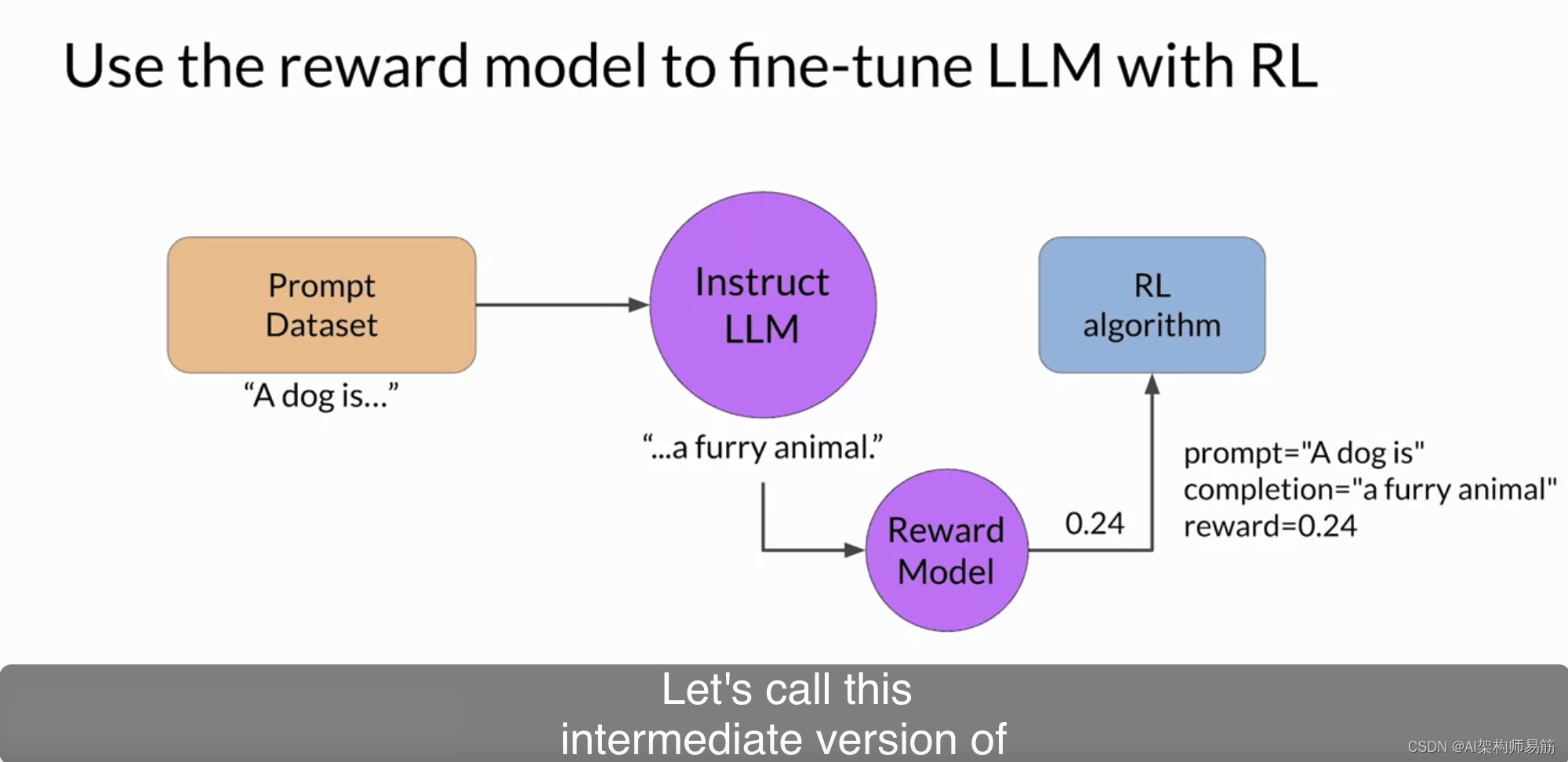
我们将称这个中间版本的模型为RL更新的LLM。这一系列步骤组成了RLHF过程的单次迭代。
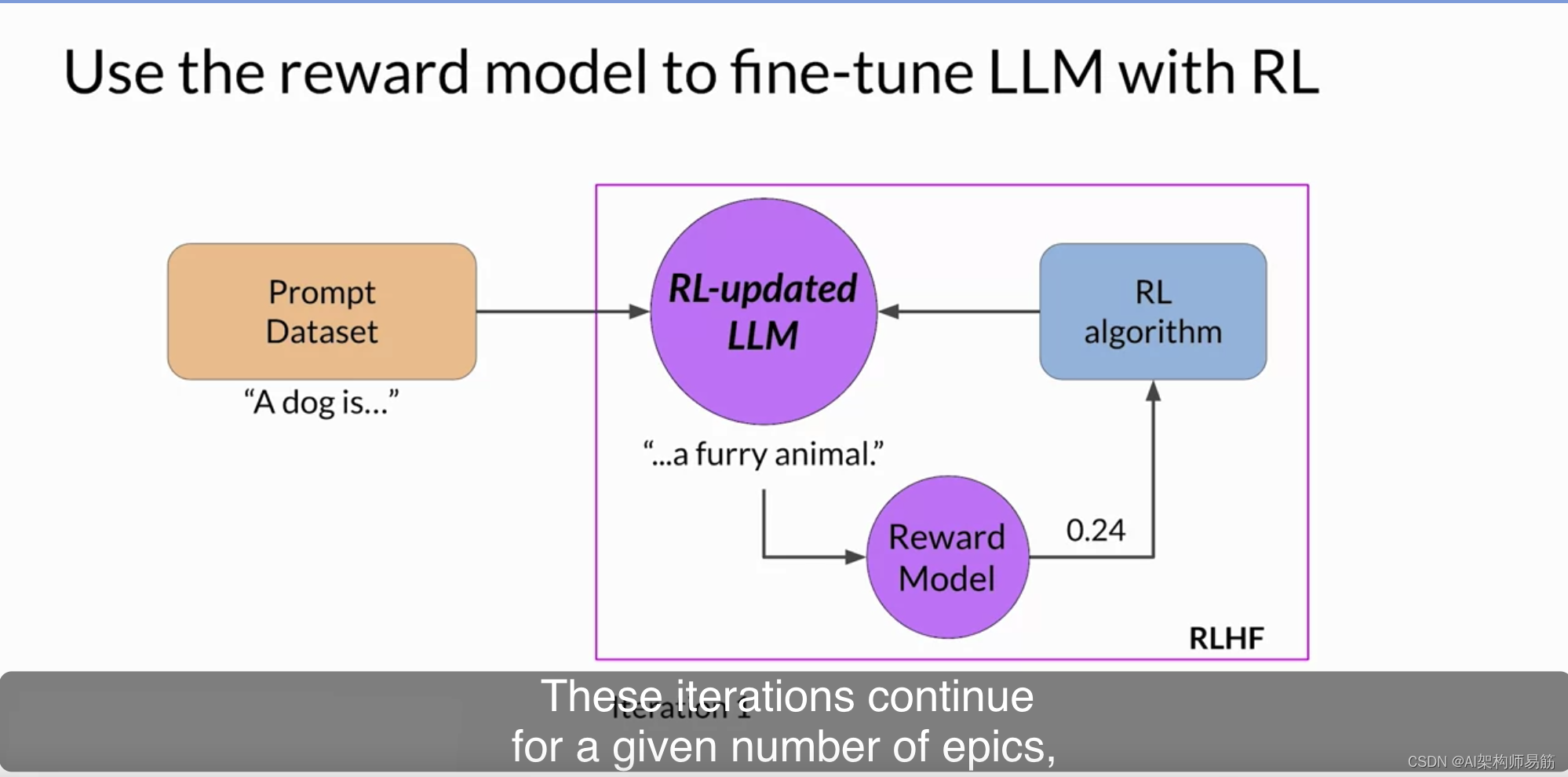
这些迭代将继续进行一定数量的回合,类似于其他类型的微调。在这里,您可以看到RL更新的LLM生成的完成获得了更高的奖励分数,表明权重的更新导致了更加对齐的完成。
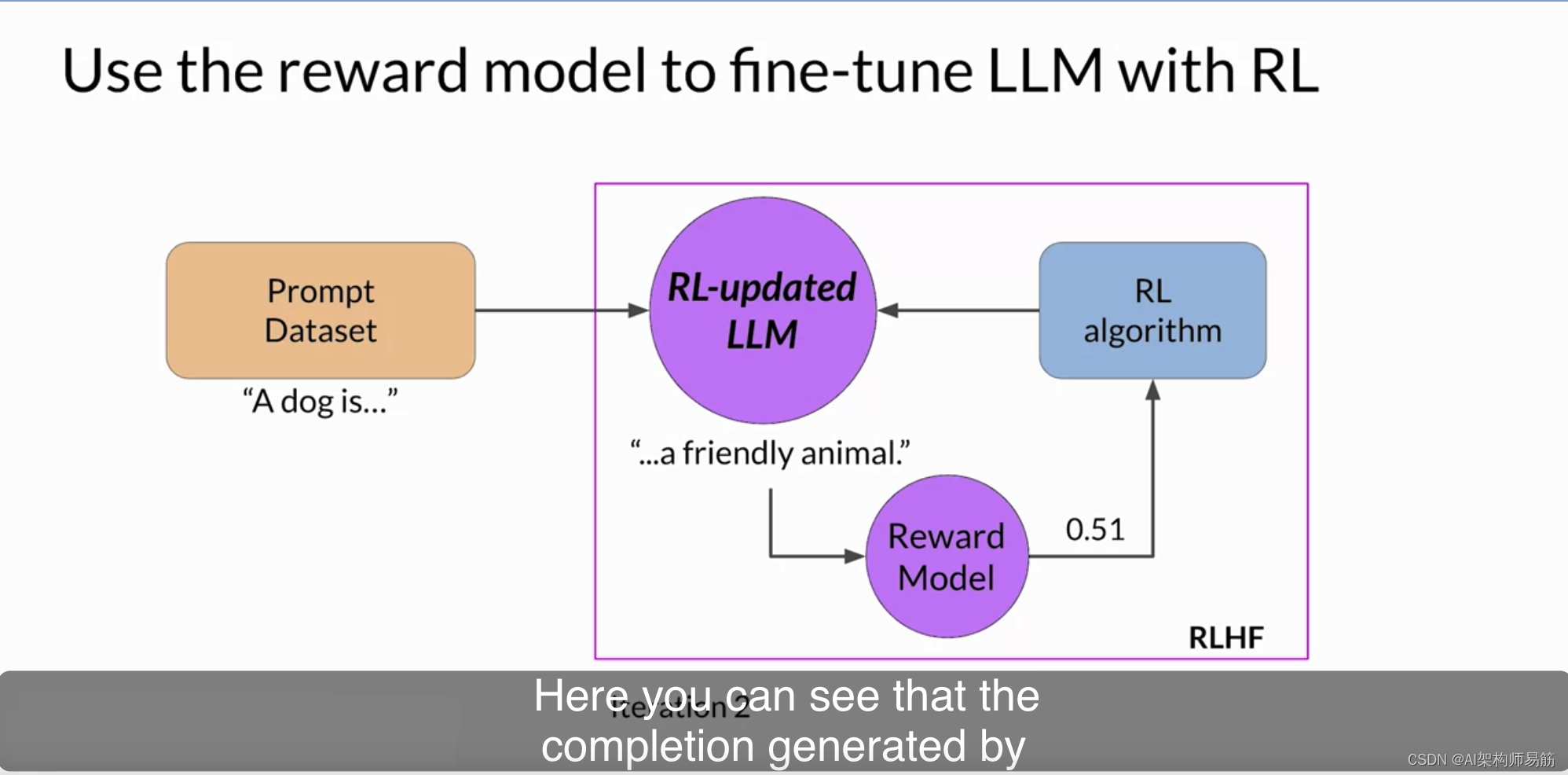
如果这个过程运行良好,您将看到在每次迭代后奖励得到改善,
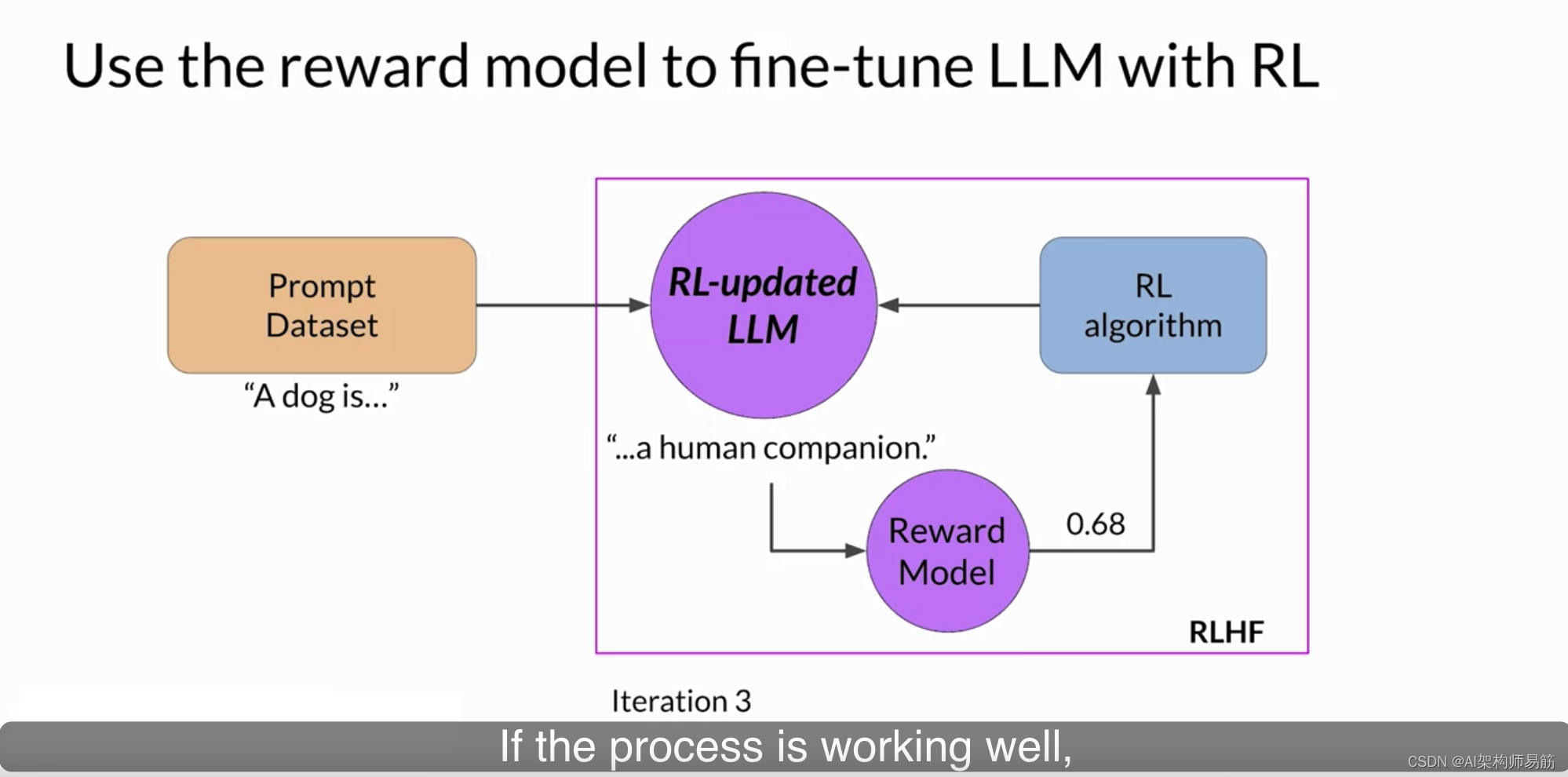
因为模型生成的文本越来越符合人类的偏好。
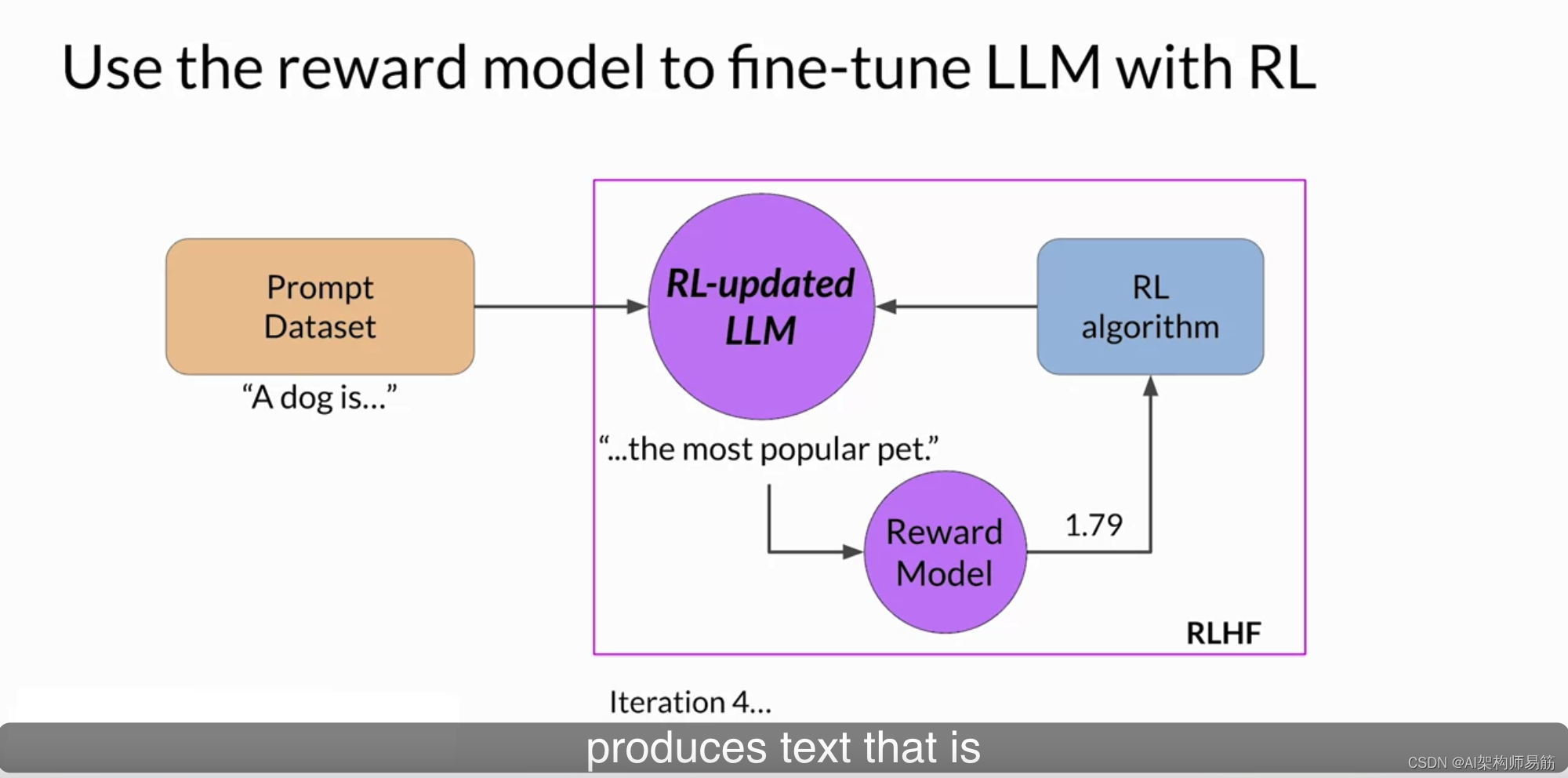
您将继续进行这个迭代过程,直到您的模型根据某些评估标准对齐。例如,达到您定义的有用性的阈值。您还可以定义一个最大步数,例如20,000,作为停止标准。在这一点上,让我们将经过微调的模型称为与人对齐的LLM。
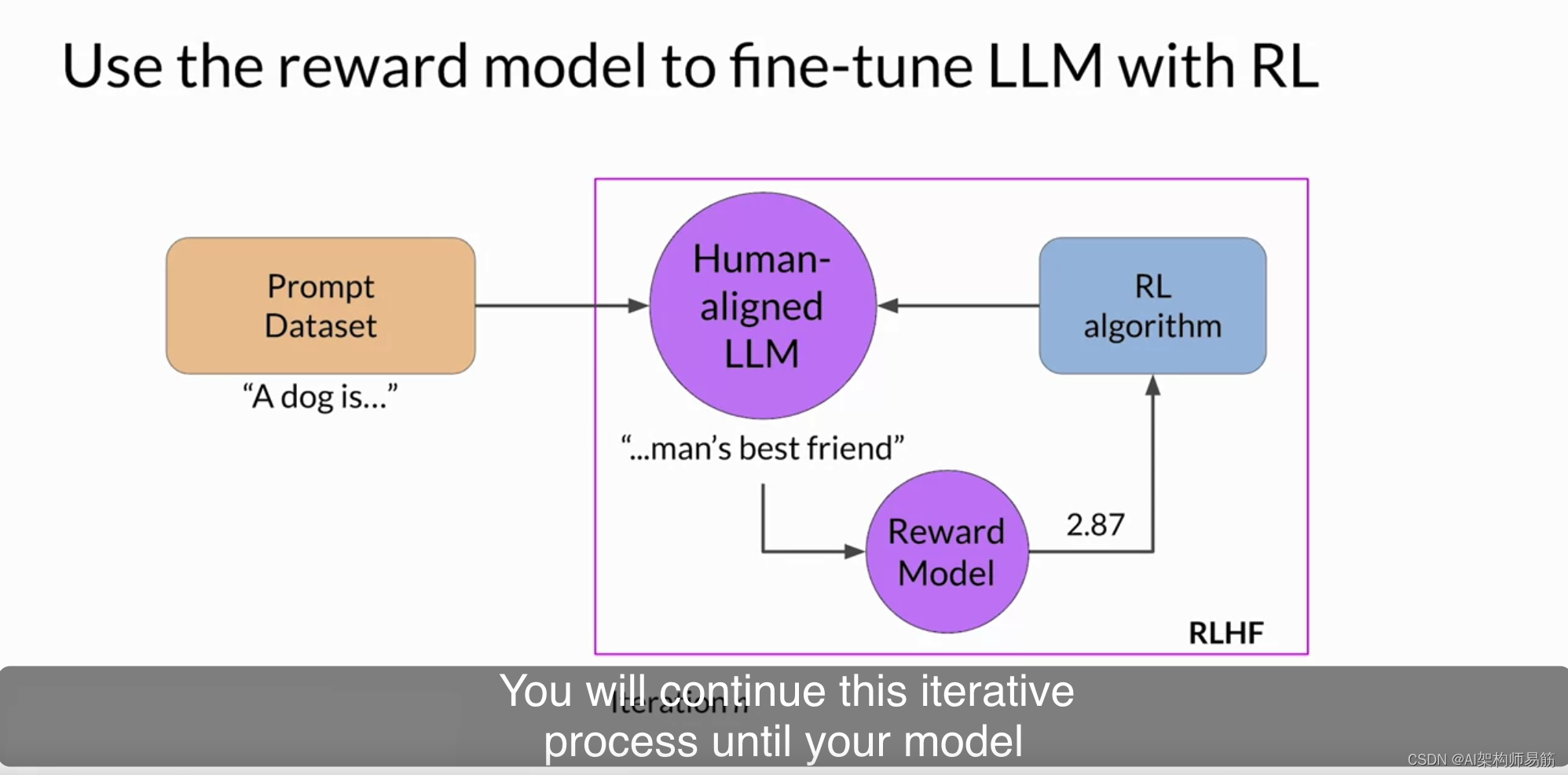
我们尚未讨论的一个细节是强化学习算法的确切性质。
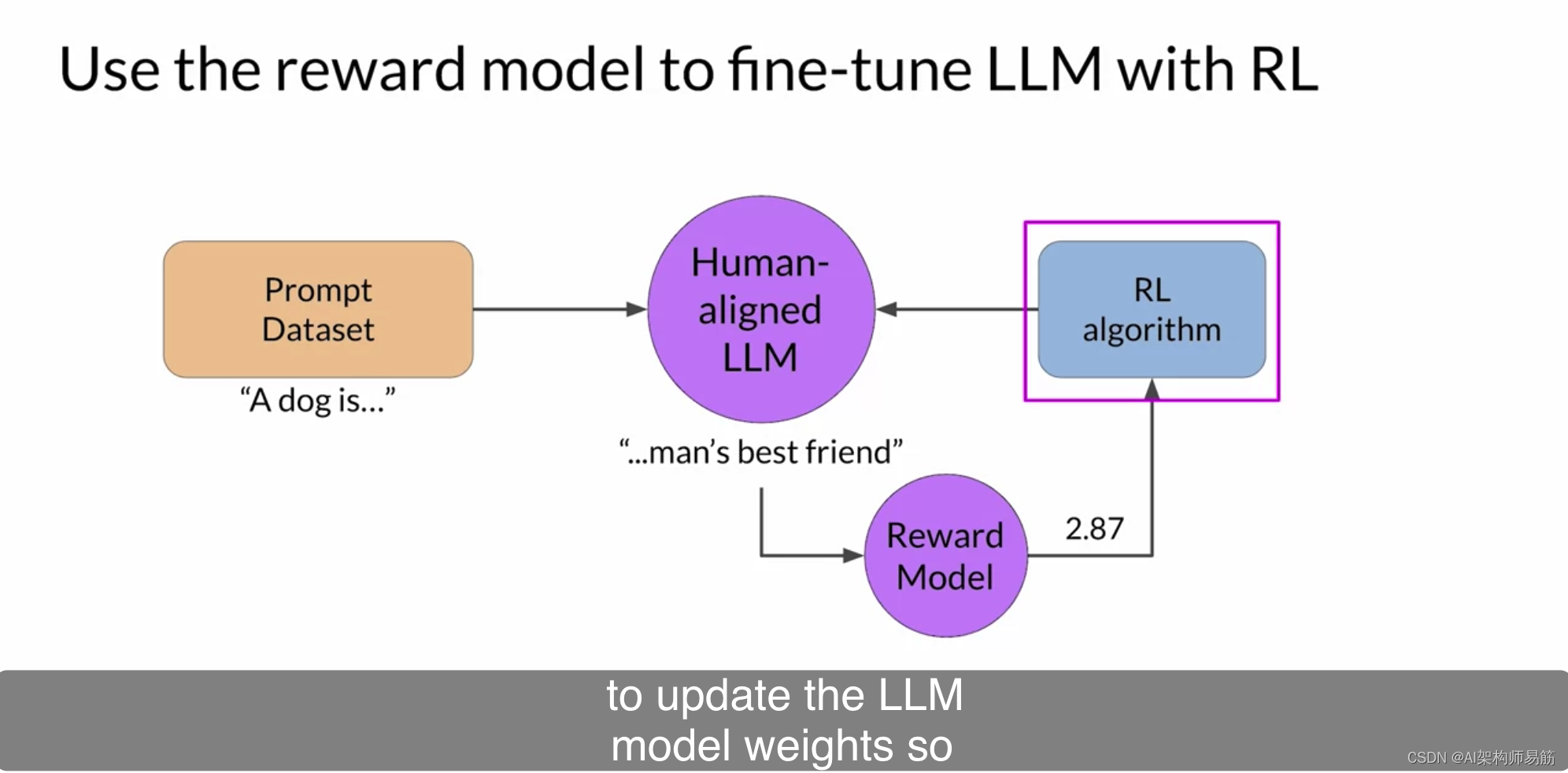
这是一个算法,它接受奖励模型的输出,并使用它来随着时间的推移更新LLM模型的权重,以增加奖励分数。有几种不同的算法可以用于RLHF过程的这一部分。一个常见的选择是近端策略优化Proximal Policy Optimization,简称PPO。
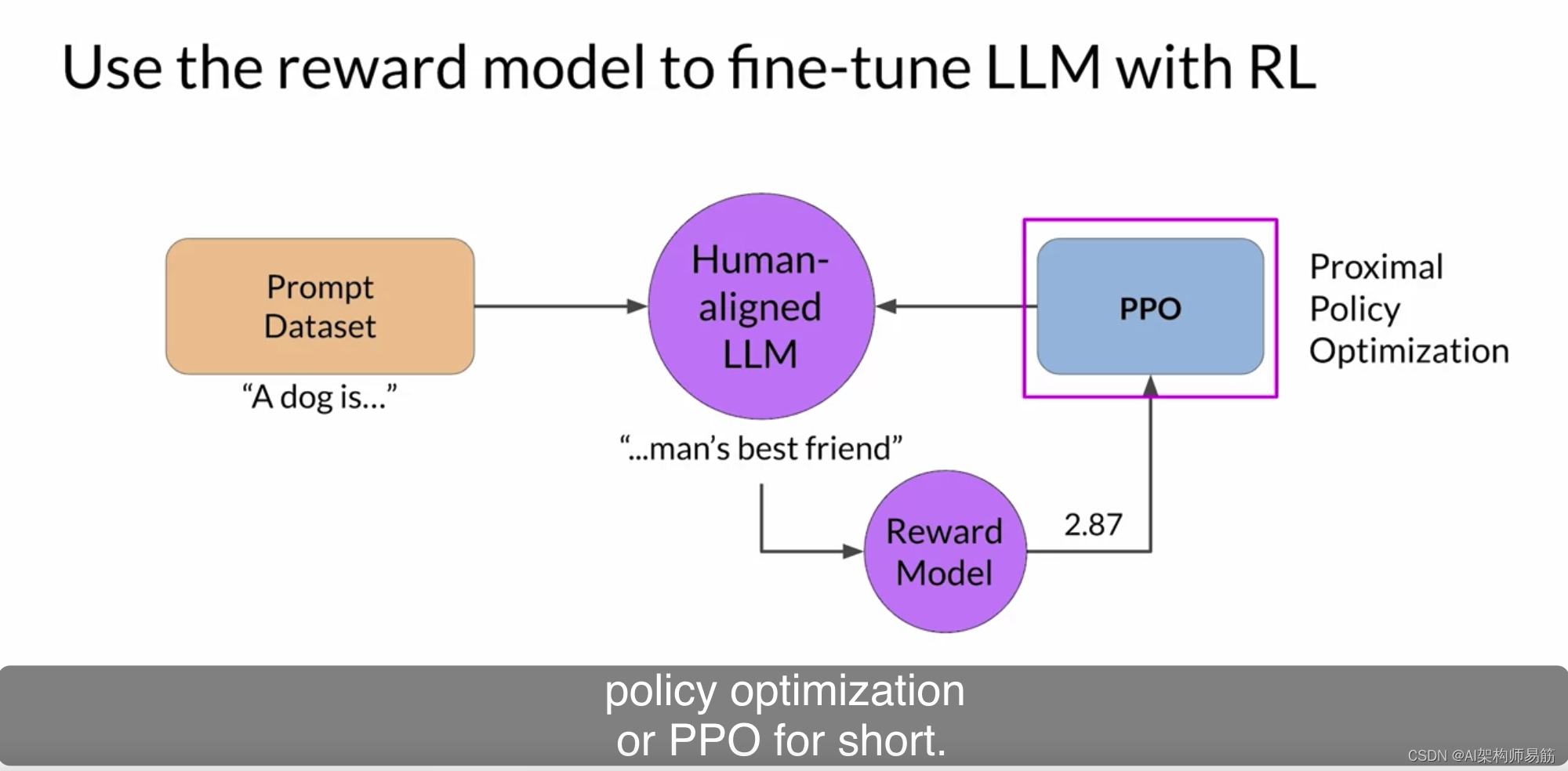
PPO是一个相当复杂的算法,您不必熟悉所有细节就能使用它。然而,这可能是一个难以实现的算法,如果您在使其工作时遇到问题,更详细地了解其内部工作原理可能有助于您进行故障排除。为了更详细地解释PPO算法的工作原理,我邀请了我的AWS同事Ek为您提供有关技术细节的更深入了解。下一个视频是可选的,您可以随意跳过它,转到奖励作弊视频。您不需要这里的信息来完成测验或本周的实验。但是,我鼓励您查看这些详细信息,因为RLHF在确保LLM在部署中以安全和对齐的方式行为方面变得越来越重要。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/sAKto/rlhf-fine-tuning-with-reinforcement-learning
-
相关阅读:
JAVA:实现AES算法(附完整源码)
CG-01 室外温湿度变送器
合肥大厂校招
编码与解码
2021 Jiangsu Collegiate Programming Contest F. Jumping Monkey II 树剖+线段树
linux 系统调用流程分析
快收下这份拼接视频方法攻略,制作出你想要的视频
基于SSM的医院科室人员管理系统
中国毫米波雷达产业分析1——毫米波雷达行业概述
PCL ICP精配准(点到点)
- 原文地址:https://blog.csdn.net/zgpeace/article/details/133573792