-
IMAGEBIND: One Embedding Space To Bind Them All论文笔记
1. Motivation
- 像CLIP这一类的方法只能实现Text-Image这两个模态的 Embedding 对齐,本文提出的ImageBind能够实现六个模态(images, text, audio, depth, thermal, and IMU data)之间的联合Embedding空间对齐。
- 本文的多模态之间的对齐也不需要专门制作一个数据集,这个数据集中的每个sample都有六种模态的对应数据,这是不现实的,成本太高。本文提出的ImageBind只需要将所有模态全部对齐到Image Embedding,uses pairs of modalities (I, M), where I represents images and M is another modality。
2. Method
2.1 数据构造
- (Image-Text) pairs from web-scale (image, text) paired data,参考《Learning transferable visual models from natural language supervision》;
- (video, audio) pairs from the Audioset dataset;
- (image, depth) pairs from the SUN RGB-D dataset;
- (image, thermal) pairs from the LLVIP dataset;
- (video, IMU) pairs from the Ego4D dataset;
Since SUN RGB-D and LLVIP are relatively small, we follow [21] and replicate them 50× for training
2.2 align pairs of modalities to image
给定一个 ( I i , M i ) (I_i, M_i) (Ii,Mi) pair, L i L_i Li 是image, M i M_i Mi 是其他模态的数据:

损失函数采用InfoNCE loss:
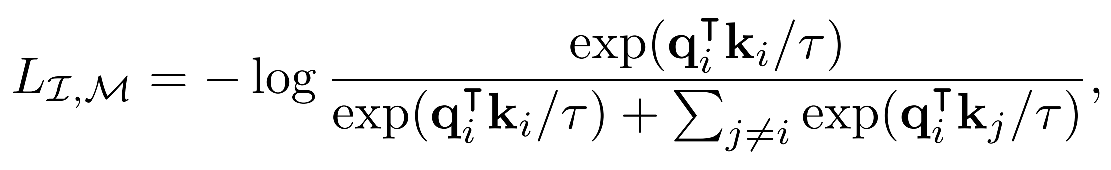
In practice, we use a symmetric loss L I , M + L M , I L_{I,M} + L_{M,I} LI,M+LM,I.
最终,We observe an emergent behavior in the embedding space that aligns two pairs of modalities (M1, M2) even though we only train using the pairs (I, M1) and (I, M2).
2.3 模型细节
- Image Encoder: Vision Transformer (ViT)
- Video Encoder: Vision Transformer (ViT) , temporally inflate the patch projection layer of the ViT and use 2 frame video clips sampled from 2 seconds. 参考《OmniMAE: Single Model Masked Pretraining on Images and Videos》
- Audio Encoder:ViT-B,convert a 2 second audio sampled at 16kHz into spectrograms using 128 mel-spectrogram bins. As the spectrogram is also a 2D signal like an image, we use a ViT with a patch size of 16 and stride 10。参考《AST: Audio Spectrogram Transformer》
- Thermal and Depth Encoder:ViT-S ,treat thermal images and depth images as one-channel images
- IMU Encoder:extract the IMU signal consisting of accelerometer and gyroscope measurements across the X, Y , and Z axes. We use 5 second clips resulting in 2K time step IMU readings which are projected using a 1D convolution with a kernel size of 8.
The resulting sequence is encoded using a Transformer - Text Encoder:follow the text encoder design from CLIP。
所有模态采用不同的Encoder,最后每一个Encoder后面加一个linear projection head讲所有的模态Embedding编码成d维。
为了降低训练复杂度,作者采用 pretrained vision (ViT-H 630M params) and text encoders (302M params) from OpenCLIP。
3. 实验
3.1 Emergent zero-shot classification
作者在论文中多次强调了ImageBind类似CLIP的Zero-Shot分类能力,但是ImageBind具有跨模态的Zero-Shot分类能力,配合一些特定任务的下游模型,也可以做到开放词汇检测,如下:

3.2 Embedding space arithmetic (Embedding 空间算术)

3.3 模态对齐能力随着视觉模型大小变大而提升

-
相关阅读:
链表删除重复的
跨域问题的原理分析
Jetson Orin平台多路 FPDlink Ⅲ相机采集套装推荐
老鼠走迷宫java ---递归
Show Me the Code之MXNet网络模型(三)
图的基本概念
删库到跑路?还得看这篇Redis数据库持久化与企业容灾备份恢复实战指南
自动铅笔的简笔画怎么画,自动化简笔画图片大全
通信达交易接口的http协议
IO地址译码实验
- 原文地址:https://blog.csdn.net/xijuezhu8128/article/details/133087426