-
手写一个摸鱼神器:使用python手写一个看小说的脚本,在ide中输出小说内容,同事直呼“还得是你”
一、准备python环境
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据二、分析小说网的章节目录
最近迷上了《史上最全炼气期》,我们以这一部小说为例:
小说章节列表:http://www.yetianlian.cc/yt4017/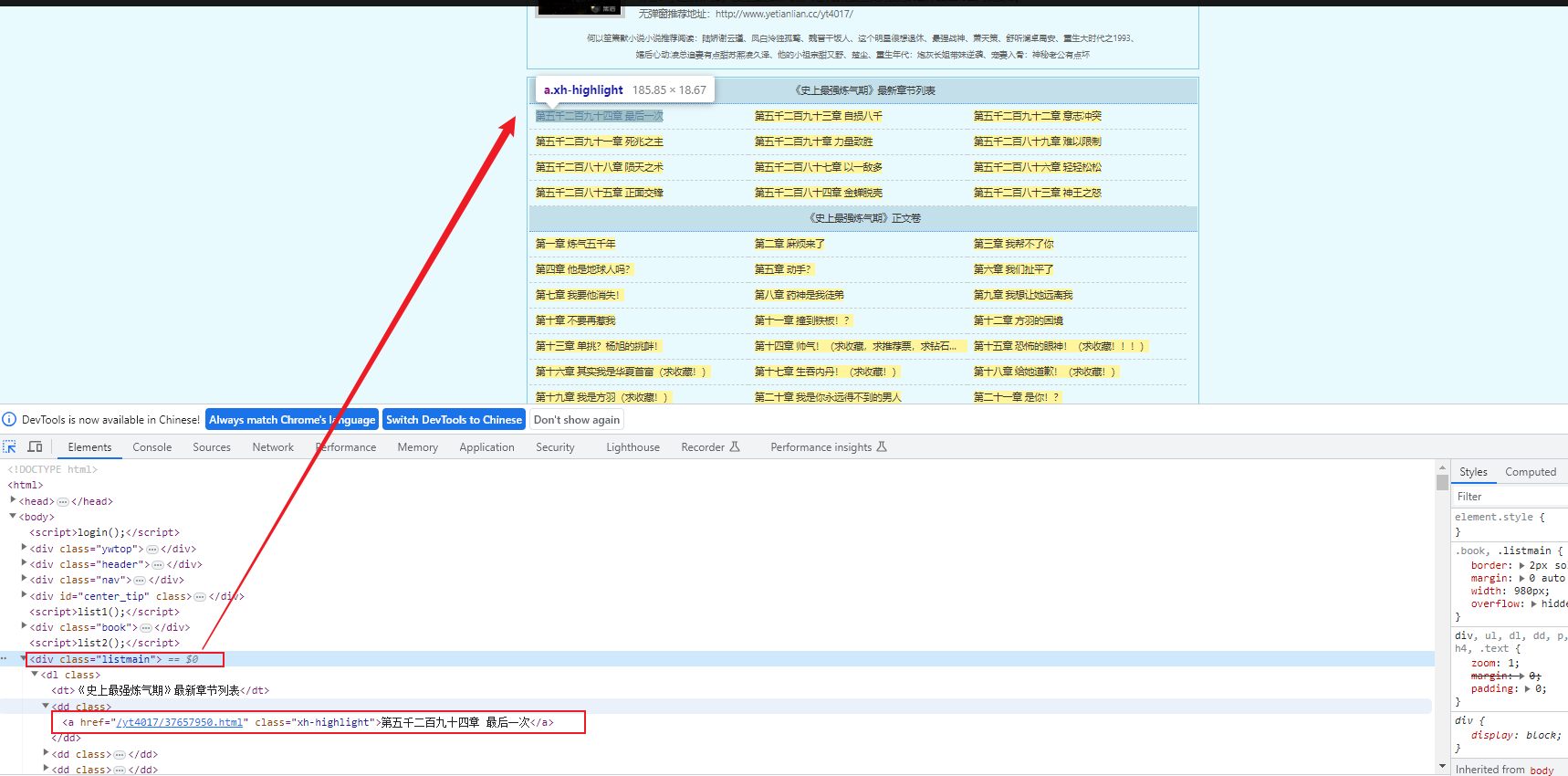
我们可以爬取关键信息:章节名和章节的url,遍历章节名,通过章节的url即可获取每一章的内容!三、分析小说网的章节内容
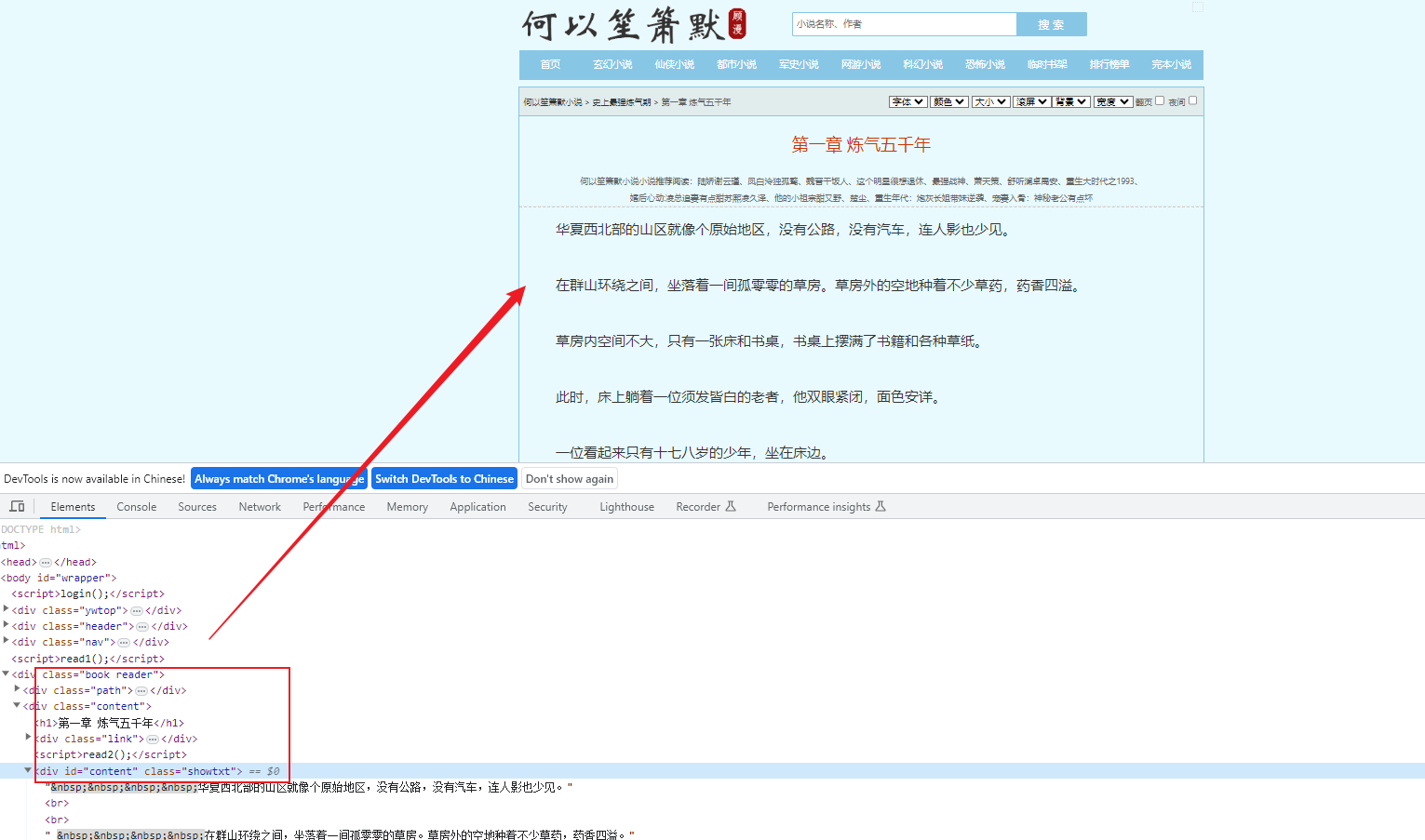
每一章的内容,也可以很轻松的得到。接下来就是编码了。
四、编写python脚本
import urllib.request from lxml import etree def create_request(url): ''' 构造请求request ''' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } request = urllib.request.Request(url = url, headers = headers) return request def get_content(request): ''' 得到响应内容 ''' response = urllib.request.urlopen(request) content = response.read().decode('utf-8') return content if __name__ == '__main__': # 获取所有章节 base_url = 'http://www.yetianlian.cc/yt4017/' request = create_request(base_url) content = get_content(request) base_tree = etree.HTML(content) # 章节名 name_list = base_tree.xpath('//div[@class="listmain"]/dl/dd/a/text()') # 章节地址 url_list = base_tree.xpath('//div[@class="listmain"]/dl/dd/a/@href') # 定位到从哪一章开始读 key = input('请输入要阅读的章节:') begin = 0 for i in range(0, len(name_list)-1): if(key in name_list[i]): begin = i for i in range(begin, len(name_list)-1): input('章节名---------------------->' + name_list[i]) # 获取具体哪一章的内容 url = 'http://www.yetianlian.cc' + url_list[i] request = create_request(url) content = get_content(request) tree = etree.HTML(content) # 获取小说的内容 result = tree.xpath('//div[@id="content"]/text()') # 遍历内容 for res in result: input(res) print('-------------->end')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
五、验证一下吧
我们随便使用一个ide,在下面打开命令行,执行命令,执行脚本:
python story.py- 1
然后输入要阅读的章节,不断的按回车键,就可以一直刷出内容了!是不是摸鱼神器~

-
相关阅读:
这段时间面试遇到的问题
抖音开放平台探索价值共生新生态,促进高校招生就业提质增效
【Java面试小短文】HashMap是如何解决Hash冲突的?
Aztec的隐私抽象:在尊重EVM合约开发习惯的情况下实现智能合约隐私
普通Java类成员变量应该用private还是public
208道最常见的Java面试题整理(面试必备)
python 学习笔记
vueDay03——计算属性
跨设备操作
利用HbuilderX制作简单网页: HTML5期末大作业——html5漫画风格个人主页
- 原文地址:https://blog.csdn.net/A_art_xiang/article/details/132720692
