-
Redis网络模型
目录
Redis网络模型
进程的寻址空间会划分为两部分:内核空间、用户空间
用户空间和内核态空间
用户空间我们平常运行的应用程序都是运行在此空间,而且不能直接调用系统资源,必须通过内核提供的接口来访问
内核空间调用一切系统资源,比如文件管理、进程通信、内存管理等
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
-
写数据时,要把用户缓冲区数据拷贝到内核缓冲区,然后写入设备
-
读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
阻塞IO(BIO)
用户空间和内核空间的交互:
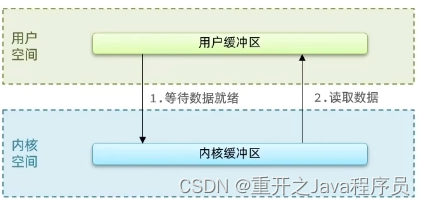
应用程序发起read调用后,会一直阻塞,直到内核把数据拷贝到用户空间
总结:
阻塞IO就是两个阶段都必须阻塞等待
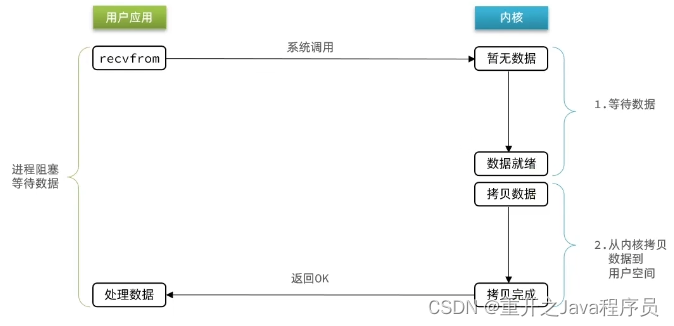
阶段一:
-
用户进程尝试读取数据(比如网卡数据)
-
此时数据尚未到达,内核需要等待数据
-
此时用户进程也处于阻塞状态
阶段二:
-
数据到达并拷贝到内核缓冲区,代表已就绪
-
将内核数据拷贝到用户缓冲区
-
拷贝过程中,用户进程依然阻塞等待
-
拷贝完成,用户进程解除阻塞,处理数据
此类IO在客户端连接数量不多的情况下是没问题的,但是如果在百万级甚至千万级连接的情况下,传统的BIO是无能为力的。
非阻塞IO(NIO)
非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程

用户在read数据的时候,数据未到达,内核需要等待数据,返回异常给用户进程,用户进程拿到error后,再次尝试读取,一直循环,直到数据就绪。将内核数据拷贝到用户缓冲区,拷贝过程中,用户进程依然阻塞等待,拷贝完成,用户进程解除阻塞,处理数据
-
但是,这种 IO 模型同样存在问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
-
如果调用recvfrom时,恰好没数据,阻塞IO会使进程阻塞,非阻塞IO会使CPU空转,都不能充分发挥CPU作用
-
如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
这就像服务员给顾客点餐,分两步:
-
顾客思考吃什么(等待数据就绪)
-
顾客想好了,开始点餐(读取数据)
提高效率的方法:
-
增加多线程(但是也不是最好的方案)
-
不排队,谁想好了吃什么(数据就绪),服务员就给谁点餐(用户应用就去读取数据)
问题:用户进程如何知道内核中数据是否就绪呢?
文件描述符(File Descriptor):简称FD,是一个从0开始递增的无符号整数,用来关联Linux中的一个文件,Linux中,一切皆文件
IO多路复用:单个线程同时监听多个FD,并在某个FD可读,可写时得到通知,从而避免无效的等待,充分利用CPU资源
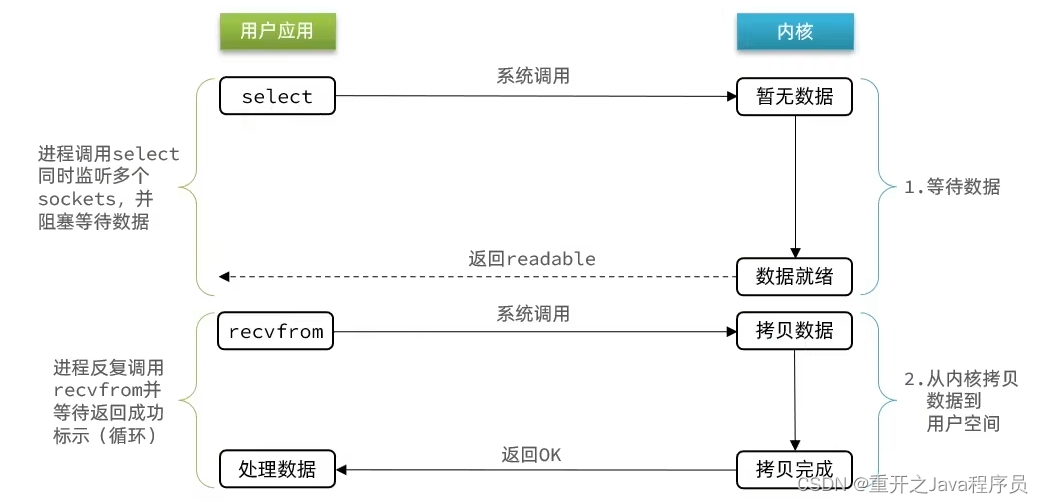
监听FD的方式、通知方式有多种实现:
-
select
-
poll
-
epoll
差异:
-
select和poll只会通知用户进程有FD就绪,但是不确定是哪一个,用户需要逐个遍历FD
-
epoll则会通知用户进程FD就绪的同时,把已经就绪的FD写入用户空间
信号驱动IO
是与内核建立SIGIO的信号关联并设置回调,当内核有FD就绪时,就会发出SIGIO信号通知用户,期间用户应用就可以执行其他业务,无需阻塞等待.
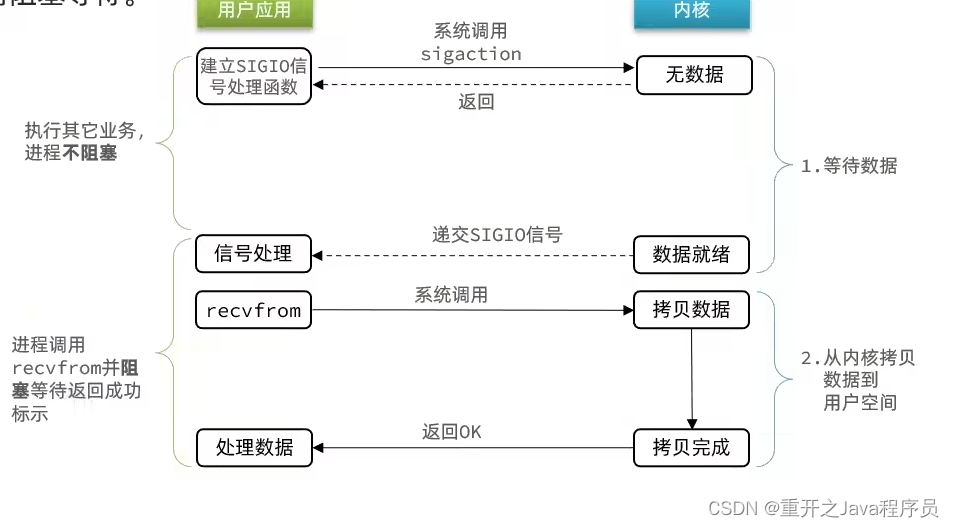
问题:
当有大量IO操作时,信号较多,SIGIO处理函数不及时导致信号队列溢出.
异步IO(AIO)
整个过程是非阻塞的,用户进程调用完异步API后就可以去做其他事情,内核等待数据就绪并拷贝到用户空间后才会递交信号,通知用户进程。
也就是说应用操作完之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续操作
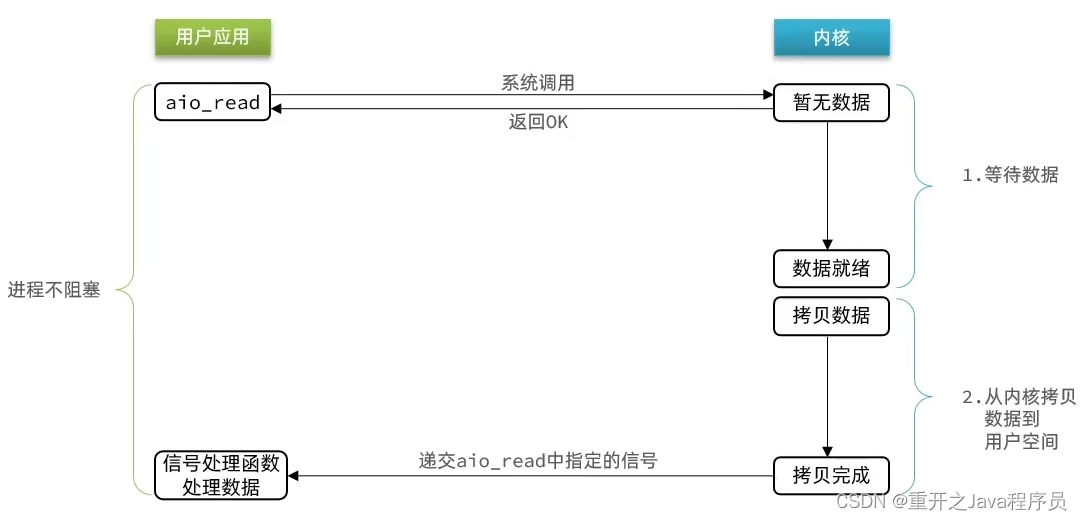
需要控制并发,否则高并发下可能会崩溃
Redis到底是单线程还是多线程?
-
如果仅仅聊Redis核心业务部分(命令处理),是单线程
-
如果聊整个Redis,那就是多线程
Redis v4.0:引入多线程异步处理一些耗时较长的任务,例如异步删除命令unlink
Redis v6.0:在核心网络模型引入多线程,进一步提高多核CPU利用率
为什么要使用单线程?
-
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程带来不了多大提升
-
多线程会导致过多的上下文切换,带来不必要的开销
-
引入多线程会有线程安全问题,必然要引入锁,性能也就会降低
-
-
相关阅读:
Effective Modern C++[实践]->只要函数不会发射异常,就为其加上noexcept
Python 潮流周刊第 42 期(摘要)+ 赠书《流畅的Python》6本
word文档太大怎么压缩?快速压缩word文档
为什么修补应用程序漏洞并不容易
uniapp小程序中的登录完整代码(兼容小程序和app)
如何进行并发编程和线程同步?
【考研数学】概率论与数理统计 —— 第七章 | 参数估计(2,参数估计量的评价、正态总体的区间估计)
电动汽车有序无序充放电的优化调度附matlab代码
手写RPC Day3 服务注册
golang工程——gRPC keep alive 配置
- 原文地址:https://blog.csdn.net/weixin_51971817/article/details/132649432