-
Python UI自动化 —— 关键字+excel表格数据驱动

步骤:
1. 对selenium进行二次封装,创建关键字的库
2. 准备一个表格文件来写入所有测试用例步骤
3. 对表格内容进行读取,使用映射关系来对用例进行调用执行
4. 执行用例
1. 对selenium进行二次封装,创建关键字的库
- from time import sleep
- from selenium import webdriver
- class Key:
- def __init__(self):
- self.driver = webdriver.Chrome()
- # 浏览器操作------------------------------------------------------------------
- def open(self, txt):
- # 打开网址
- self.driver.get(txt)
- # 最大化浏览器窗口
- self.driver.maximize_window()
- # 隐式等待10秒
- self.driver.implicitly_wait(10)
- def quit(self):
- # 退出浏览器
- self.driver.quit()
- def sleep(self, txt):
- # 强制等待
- sleep(txt)
- # 元素操作函数-----------------------------------------------------------------
- def input(self, txt, value, name="xpath"):
- # 输入
- el = self.driver.find_element(name, value)
- el.send_keys(txt)
- def click(self, value, name="xpath"):
- # 点击
- el = self.driver.find_element(name, value)
- el.click()
2. 创建一个表格,写入测试步骤
将表格放入项目任意路径下,记住路径,待会读取文件需要用到,我这里是放在这里

解释一下:(定位方法)为空,是因为关键字方法封装时,已经带上了默认参数

3. 写一个excel表格读取方法,对表格内容进行读取,使用映射关系来对用例进行调用执行。
看注释就明白是啥意思了
- import os
- import openpyxl
- from UI.Base.selenium_key import Key
- # 获取该路径“../TestExampleExcel”模板下所有xlsx文件
- filenames = os.listdir(r"../TestExampleExcel")
- # 实例化驱动
- wd = Key()
- # 遍历所有xlsx文件
- for i in filenames:
- excel = openpyxl.load_workbook(f'../TestExampleExcel/{i}')
- # 获取全部sheet页,遍历sheet页执行不同sheet页中的用例
- for name in excel.sheetnames:
- sheet = excel[name]
- print(f"正在执行{i}文件中的{name}用例")
- # 打印每一行表格数据
- for values in sheet.values:
- # 如果excel表格的第三列不是int类型,则不打印。
- if isinstance(values[2], int):
- data = {}
- data['name'] = values[4]
- data['value'] = values[5]
- data['txt'] = values[6]
- # 将字典中的None值给去除掉
- for k in list(data.keys()):
- if data[k] is None:
- del data[k]
- print(f"正在执行:{values[1]}")
- getattr(wd, values[3])(**data)
4. 执行用例
执行Excel文件读取方法即可
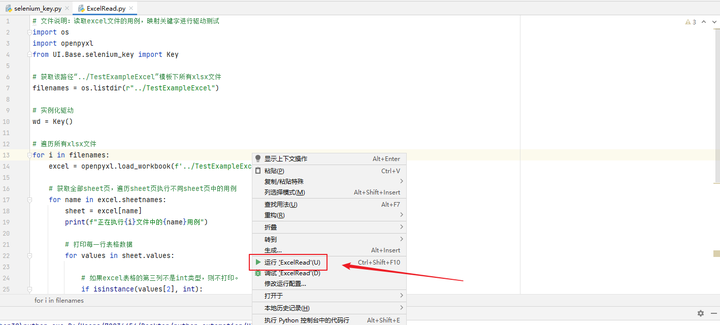

最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


-
相关阅读:
全国职业技能大赛云计算--高职组赛题卷②(私有云)
浅谈c/c++中main(),int main(),void main(),int main(void)四者之间的区别
冒泡排序算法
order模块给User模块发送http请求
飞机牵引车-阅读相关规范
线程池自义定参数设置及预估
Java基础知识篇02——Java基本语法
Selenium实现批量将CSDN文章改为【粉丝可见】
手把手开发Admin 系列三(自定义模板篇)
.NET周刊【6月第1期 2024-06-02】
- 原文地址:https://blog.csdn.net/IT_LanTian/article/details/132723296
