-
【目标检测】【DDPM】DiffusionDet:用于检测的概率扩散模型
摘要
题目:DiffusionDet: Diffusion Model for Object Detection
作者:香港大学和腾讯 Shoufa Chen,Peize Sun,Yibing Song,Ping Luo
文章:https://arxiv.org/abs/2211.09788
代码:https://github.com/ShoufaChen/D我们提出了扩散det,一个新的框架,将目标检测作为一个从噪声框到目标框的去噪扩散过程。在训练阶段,目标框从gt box扩散到随机分布,模型学会了逆转这种噪声过程。在推理中,该模型以渐进的方式细化一组随机生成的box以输出结果。我们的工作在目标检测方面带来了两个重要的发现。首先,随机框虽然与预定义的锚点或学习到的查询完全不同,但也是有效的候选对象。第二,目标检测是具有代表性的感知任务之一,可以通过生成的方式来解决。
一、Introduction
目标检测的目的是预测一幅图像中目标对象的一组边界框和相关的类别标签。作为一项基本的视觉识别任务,它已成为许多相关识别场景的基石,如实例分割、姿态估计、动作识别、目标跟踪和视觉关系检测。
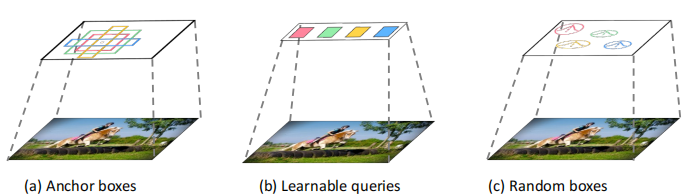
现代对象检测方法的发展随着候选对象的发展而不断发展,即从经验对象先验(faster-Rcnn、SSD等)到可学习的对象查询(ViT,Sparse r-cnn,DETR)。具体来说,大多数检测器通过对经验设计的候选对象定义代理回归和分类来解决检测任务,如滑动窗口、区域建议、锚框和参考点。DETR 提出了可学习的对象查询来消除手工设计的组件,并建立了一个端到端检测管道,这在基于查询的检测范式上引起了极大的关注。它们依赖于一组固定的可学习的查询。是否有一种更简单的方法,甚至不需要可学习查询的代理?我们设计一个新的框架,可以直接检测来自一组纯随机box中的对象,它不包含在训练中进行优化的可学习参数,我们期望逐步细化这些盒子的位置和大小,直到它们完美地覆盖目标对象。
动机如下图所示。认为 noise-to-box 范式的哲学类似于去噪扩散模型中的噪声到图像过程,这是一类基于似然的模型,通过学习的去噪模型逐步从图像中去除噪声来生成图像。扩散模型在许多生成任务[3,4,37,63,85]中取得了巨大的成功,并开始在图像分割[1,5,6,12,28,42,89]等感知任务中进行探索。(原理和推导,请见上篇blog)
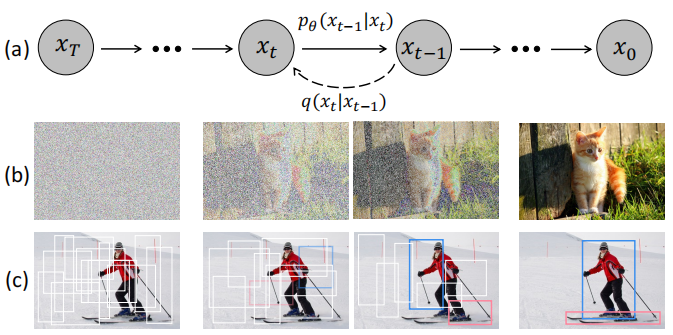
DiffusionDet,将检测作为生成任务投射在图像中的位置(中心坐标)和边界框的空间和大小(宽度和高度)上来处理目标检测任务。在训练阶段,将由
- 方差 schedual控制的高斯噪声添加到groundtruth 中,获得噪声box。
- 然后利用这些噪声box,从backbone encoder(如ResNet Swin)的输出特征图中,裁剪感兴趣区域(RoI)特征。
- 最后,将这些RoI特征发送到检测 decoder,来预测无噪声的gt box。有了这个训练目标,扩散网能够从随机盒子中预测地面真实盒子。
推理阶段,扩散det通过反转学习扩散过程生成边界盒,将噪声先验分布调整到边界框上的学习分布。
DiffusionDet的 noise to box 具有 Once-for-All 的优点:我们可以对网络进行一次训练,并在不同的设置下使用相同的网络参数进行推理。
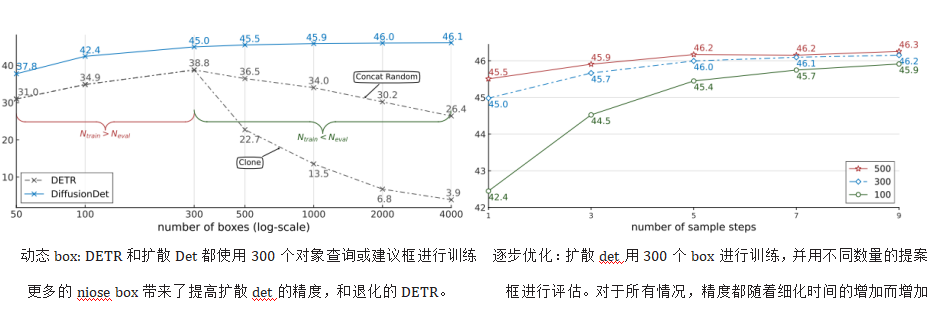
- 动态框:利用随机个 box 作为候选对象,DiffusionDet 解耦训练和评估。可以用Ntrain随机box进行训练,同时用Neval随机box进行评估(Neval是任意值)
- 渐进式细化:扩散模型的迭代细化,有利于优化扩散模型。可调整去噪采样步骤的数量来提高检测精度或加快推理速度,这种灵活性使其能够适应不同的检测场景。
二、相关工作
1.目标检测
大多数现代 object detection 方法对经验目标先验进行边框回归和类别分类,如proposal、anchor、point方法。Carion等人提出了DETR ,使用一组固定的可学习查询来检测对象。我们利用 DiffusionDet 进一步推进了目标检测pipline 的开发,如图所示。
2.Diffusion Model。扩散模型作为一类深度生成模型,从随机分布的样本出发,通过逐步去噪的过程恢复数据样本。扩散模型最近在计算机视觉、自然语言处理、音频处理、跨学科应用等领域取得了显著的成果。
3.扩散模型的感知任务。
虽然扩散模型在图像生成方面取得了巨大的成功,但它们在鉴别任务方面的潜力还有待充分探索。一些先锋工作尝试采用扩散模型进行图像分割任务[1,5,6,12,28,42,89],
1.Segdiff: Image segmentation with diffusion probabilistic models
2.Label-efficient semantic segmentation with diffusion models
3.Denoising pretraining for semantic segmentation
4.A generalist framework for panoptic segmentation of images and videos
5.Diffusion models as plug-and-play priors
6.Diffusion adversarial representation learning for self-supervised vessel segmentation.
7. Diffusion models for implicit image segmentation ensembles
8.Generating discrete data using diffusion models with self-conditioning.例如,Chen等人[4]采用位扩散模型[8]进行图像和视频的全光分割[ Panoptic segmentation.]。因为分割任务是以图像到图像的方式处理的,这在概念上更类似于图像生成任务,而目标检测是一个集合预测问题[10],它需要将候选对象分配给groundtruth。
三、方法
1.准备工作
目标检测
目标检测的学习目标是输入-目标对 (x、b、c) ,其中x是输入图像,b和c分别是图像x中对象的一组边界框和类别标签。即集合中的第i个框表示为bi =(cix,ciy,wi,hi),c 是边界框的中心坐标,w\h分别是该边界框的宽度和高度。扩散模型
扩散模型是一类基于概率的模型,其灵感来自于非平衡热力学。这些模型通过逐步向样本数据中添加噪声,定义了扩散正向过程的马尔可夫链。正向噪声过程的定义为
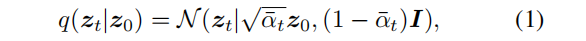
通过向 z0 中添加噪声,将数据样本z0 转换为t∈{0,1,…,T}的潜在噪声样本 zt。在训练过程中,训练一个神经网络fθ(zt,t),通过最小化训练目标来从 zt 中预测 z0:
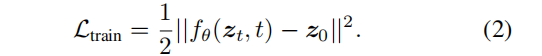
在这项工作中,我们的目标是通过扩散模型来解决目标检测任务。在我们的设置中,数据样本是一组边界框z0 = b,其中b∈RN×4是一组N个框。训练神经网络 fθ(zt,t,x) 从噪声框 zt 中预测 z0,相应地生成相应的类别标签c2.架构
由于扩散模型是迭代生成数据样本,因此在推理阶段需要多次运行模型 fθ。然而,在每一个迭代步骤中,直接将fθ应用于原始图像将是难以计算的。因此,我们建议将整个模型分为两部分,图像编码器和检测解码器,前者只运行一次,从原始输入图像 x 提取深度特征,后者把这个深层功能作为条件(而非原始图像输入),利用噪声 zt 逐步完善bounding box
2.1 图像 encoder
将原始图像作为输入,并提取其高级特征,可使用卷积神经网络如ResNet 和Swin 模型来实现 DiffusionDet。FPN 用于生成多尺度特征图。2.2 Detection decoder
借鉴于 Sparse R-CNN, 检测解码器以一组建议框作为输入,从图像编码器生成的特征图中裁剪roi特征,并将这些roi特征发送到检测头,获得回归和分类结果。检测解码器由6个级联阶段组成,与Sparse R-CNN中的解码器的区别在于:(1)扩散det从随机的 box 开始,而Sparse R-CNN使用一组固定的学习盒子进行推理;(2)稀疏R-CNN将建议box及其相应特征作为输入对,而扩散网只需要建议box;(3)扩散网在迭代采样步骤中重复使用探测器头,参数在不同步骤中共享,每个步骤通过时间步嵌入指定到扩散过程中,而稀疏R-CNN在前向传递中只使用检测解码器一次。
3、训练
训练中,首先构造从GT box 到噪声 box 的扩散过程,然后训练模型来逆转这个过程。算法1提供了扩散点训练过程的伪代码。

3.1 Groundtruth boxes 扩充.
由于感兴趣的实例数量通常因不同的图像而变化。因此,需将额外的box 填充到原始的 Groundtruth 中,则proposal的数量固定为 Ntrain。我们探索了几种填充策略,例如,重复现有的地面真实框,concat 随机框或图像大小的框。这些策略的比较见第4.4节,连接随机框效果最好。
3.2 Box corruption 目标框的破坏
在 pad 后的GT box 中加入高斯噪声。噪声尺度由 αt 控制(在等式中(1)),对不同时间步长t下的 αt采用单调递减余弦调度。由于信噪比对扩散模型的性能有显著影响,因此GT box坐标也需要进行比例缩放。我们观察到,目标检测倾向于一个比图像生成标准高的的信号缩放值。更多的讨论见第4.4节。3.3 训练损失
检测检测器以 Ntrain 加噪box作为输入,预测类别分类和 Ntrain 框坐标的预测。我们将集预测损失应用于 Ntrain 预测集。我们通过最优传输分配方法选择成本最小的前k个预测,为每个地面真相分配多个预测。4.预测过程
DiffusionDet 的推理过程是一个从噪声到目标框的去噪采样过程。从在高斯分布中采样的盒子开始,该模型逐步细化其预测:
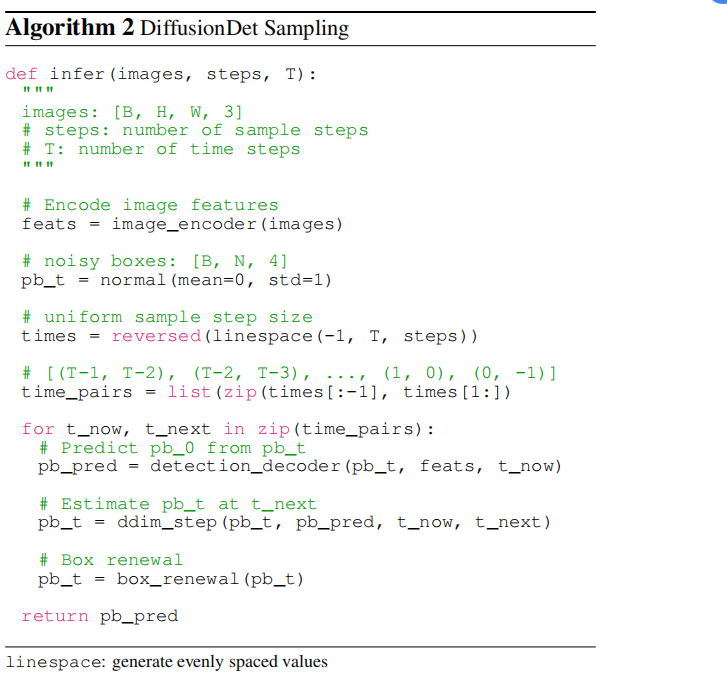
4.1采样步骤
随机box或最后一个采样步骤中的估计box ,被发送到检测解码器中,以预测类别分类和 box 坐标。在获得当前步骤的box后,采用DDIM对下一步的box 进行估算。我们注意到,将不带DDIM的预测框发送到下一步也是一种可选的渐进细化策略。然而,如第4.4节所述,它会带来严重的恶化。4.2 方框更新
在每个采样步骤之后,预测的 box 可以粗略地分为两种类型,期望预测和非期望预测。期望预测包含正确位于相应对象上的框,而非期望预测是任意分布的。直接将这些非期望box发送到下一个采样迭代不会带来好处,因为它们的分布不是由训练中的box损坏构建的。为了使推理更好地与训练相一致,我们提出了box更新的策略,通过用随机的box来恢复这些非期望的box。具体来说,首先过滤掉分数低于特定阈值的不期望的方框。然后,我们将剩余的box与从高斯分布中抽样的新的随机box连接起来。4.3 一劳永逸
由于随机box的设计,我们可以用任意数量的随机box和采样步数来评估DiffusionDet ,这不需要等于训练阶段。作为比较,以前的方法在训练和评估过程中依赖于相同数量的处理过的box,它们的检测解码器在正向传递中只使用一次。四. 实验
1.训练策略
ResNet和Swin主干分别在ImageNet-1K和ImageNet-21K上预训练。
新添加的 detect decoder 用Xavier init 进行初始化,用AdamW优化器,初始学习率为2.5×10−5,权重衰减为10−4。模型在8个gpu上,用16的 batchsize 训练。
对于MS-COCO,450K个iter,在350K和420K迭代时,学习率除以10。对于LVIS,训练iter 为210K、250K、270K。数据增强策略包括随机水平翻转,调整输入图像大小的比例抖动,最短边至少480像素,最多800,最长边最多1333。不使用EMA和一些强大的数据增强,如MixUp [98]或Mosaic
2.main property
扩散法的主要性质在于对所有推理情况的一次训练。一旦模型被训练好了,它就可以用于在推理中改变方框的数量和样本步骤的数量,如图所示。扩散det可以通过使用更多的box或更多的细化步骤,以更高延迟为代价,从而实现更高的准确性。因此,我们可以在多个场景中部署一个扩散网络,并在不需要再训练网络的情况下获得一个期望的速度-精度的权衡。
3.消融实验
Signal scaling
信号尺度因子控制着扩散过程的信噪比(SNR)。我们研究了比例因子的影响。结果表明,2.0的比例因子达到了最佳的AP性能,优于图像生成任务的标准值1.0和全景分割的标准值0.1。我们考虑到,这是因为一个盒子只有四个表示参数,即中心坐标(cx,cy)和盒子大小(w,h),这与图像生成中只有四个像素的图像大致相似。盒子表示比密集表示更脆弱,例如,在全光分割中的512×512掩模表示。因此,与图像生成和全光分割相比,扩散det更喜欢一个增加信噪比的更容易的训练目标。五、代码分析
1.测试 demo.py
##-------------------1.提取图像特征----------------------- src = self.backbone(images.tensor) features = [src['p2'],src['p3'],src['p4'],src['p5']] results = self.ddim_sample(batched_inputs, features, images_whwh, images) # images:(800,1333), normal to(0,1) def ddim_sample(self, batch, feats, whwh, images, clip_denoised=True, do_postprocess=True): shape = (batch, self.num_proposals, 4) # (1,500,4) total_timesteps, sampling_timesteps, eta, objective = self.num_timesteps, self.sampling_timesteps, self.ddim_sampling_eta, self.objective # T=1000, sampling_timesteps=1, eta=1, objective= 'pred_x0' time_pairs = (999,-1) img = torch.randn(shape, device) # (1,500,4) preds, outputs_class, outputs_coord = self.model_predictions(backbone_feats, images_whwh, img, time=999, self_cond=None, clip_x_start=clip_denoised) # ----------------2. 随机生成bbox,循环解码6次---------------- #(随机噪声映射到图像大小,提取对应特征并继续解码) for head_idx, rcnn_head in enumerate(self.head_series): class_logits, bboxes, proposal_features = rcnn_head(features, bboxes, proposal_features, self.box_pooler, time) roi_features = pooler(features, proposal_boxes) # (1,500,4) ->(500,256,7,7) -->(500,256,49) pro_features = roi_features.view(N, nr_boxes, self.d_model, -1).mean(-1) # (500,1,256) # 1.自注意力 pro_features2 = self.self_attn(pro_features, pro_features, value=pro_features)[0] # (500,1,256) -> (500,1,256) # 2.inst_interact. pro_features2 = self.inst_interact(pro_features, roi_features) # conv+linear+prod ->(500,256) # 3.fuse_time_embedding scale_shift = self.block_time_mlp(time_emb) # conv ->(1,512) scale_shift = torch.repeat_interleave(scale_shift, nr_boxes, dim=0) # (500,512) scale, shift = scale_shift.chunk(2, dim=1) # (500,256) (500,256) fc_feature = fc_feature * (scale + 1) + shift # (500,256) # 4.分类/回归 class_logits = self.class_logits(fc_feature) # conv->(500,80) bboxes_deltas = self.bboxes_delta(fc_feature) # conv->(500,4) pred_bboxes = self.apply_deltas(bboxes_deltas, bboxes.view(-1, 4)) # decode-> xyxy outputs_class.append(class_logits) # (6,500,80) outputs_coord.append(pred_bboxes) # (6,500,4) #--------------------3.----------------------- x_start = outputs_coord[-1]/images_whwh # 取最后一次结果,做归一化 pred_noise = self.predict_noise_from_start(img, t=999, x_start) # 输入输出dim相同 # img(1,500,4)为最开始生成的噪声,X0(即x_start)为最终预测边界框,其具体代码为: (extract(self.sqrt_recip_alphas_cumprod, t, img.shape) * img - x_start) / extract(self.sqrt_recipm1_alphas_cumprod, t, img.shape) #------------------------------4.nms与后处理--------------------------------- # 貌似没用到pred_noise和cls_score, 直接nms得到500个proposal中的230个目标 results = self.inference(box_cls, box_pred, images.image_sizes) # nms 筛选并得到具体类别 r = detector_postprocess(results_per_image, 300, 500) # resize回原尺寸300,500 #------------------------------5.分数筛选--------------------- new_instances = instances[instances.scores > self.threshold=0.5] # (215)--> (9)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
2.训练 train-net.py
0.提取特征 features = self.backbone(images.tensor) 1.targets, x_boxes, noises, t = self.prepare_targets(gt_instances) def prepare_targets(self, targets): # 循环所有图像 batch gt_boxes = xyxy_to_cxcywh(gt_boxes/ image_size_xyxy) # 归一化 d_boxes, d_noise, d_t = self.prepare_diffusion_concat(gt_boxes) d_t = torch.randint(0, T = 1000).long() # 随机选 t d_noise = torch.randn( num_proposals=500, 4 ) # 01.真实目标不够500,补充到500 if num_gt < self.num_proposals: box_placeholder = torch.randn(500 - num_gt, 4) / 6. + 0.5 # 3sigma= 1/2 -> sigma: 1/6 x_start = torch.cat((gt_boxes, box_placeholder), dim=0) # (500,4) # 02.预测分布 q(x_t-1|x_t, x_0) d_boxes = self.q_sample(x_start=x_start, t=d_t, noise=d_noise) # 即公式: qrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x_start.shape) sqrt_one_minus_alphas_cumprod_t = extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) x = sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise d_boxes = box_cxcywh_to_xyxy(x) x_boxes = cat(d_boxes) target["labels"] = gt_classes # [29,0,1] target["boxes"] = gt_boxes # 归一化坐标 target["boxes_xyxy"] = targets_per_image.gt_boxes # (3,4) target["image_size_xyxy"] = image_size_xyxy image_size_xyxy_tgt = image_size_xyxy.unsqueeze(0).repeat(len(gt_boxes), 1) target["image_size_xyxy_tgt"] = image_size_xyxy_tgt target["area"] = targets_per_image.gt_boxes.area() x_boxes = x_boxes * images_whwh[:, None, :] # (bs,500,4) 2.计算网络输出 outputs_class, outputs_coord = self.head(features, x_boxes, t, None) # t:(8) # outputs_class:(6,bs,500,80) outputs_coord:(6,bs,500,4) output = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} if self.deep_supervision: # True output['aux_outputs'] = [{'pred_logits': outputs_class[:-1], 'pred_boxes': outputs_coord[:-1]}] 3.计算损失 loss_dict = self.criterion(output, targets) # Hungarian匹配损失 indices, _ = self.matcher(outputs_class[-1], outputs_coord[-1], targets) fg_mask, is_in_boxes_and_center = self.get_in_boxes_info( box_xyxy_to_cxcywh(bz_boxes), # absolute (3,4):x, y, w, h box_xyxy_to_cxcywh(bz_gtboxs_abs_xyxy), # absolute (500,4):x, y, w, h expanded_strides=32) # 筛选出500个pro是否在3个gt的 (框内|中心点2.5范围内),返回两个值都是(500)×[True,False] # 01.IOU损失 pair_wise_ious = ops.box_iou(bz_boxes, bz_gtboxs_abs_xyxy) # 之间的iou (500,3) # 02.类别损失 if self.use_focal: # True alpha = self.focal_loss_alpha # 0.25 gamma = self.focal_loss_gamma # 2 neg_cost_class = (1 - alpha) * (bz_out_prob ** gamma) * (-(1 - bz_out_prob + 1e-8).log()) # (500,80) pos_cost_class = alpha * ((1 - bz_out_prob) ** gamma) * (-(bz_out_prob + 1e-8).log()) cost_class = pos_cost_class[:, bz_tgt_ids] - neg_cost_class[:, bz_tgt_ids] # (500,3) # 03.距离损失 cost_bbox = torch.cdist(bz_out_bbox_, bz_tgt_bbox_, p=1) # (500,3) # 04.giou cost_giou = -generalized_box_iou(bz_boxes, bz_gtboxs_abs_xyxy) # (500,3) # 05.总损失 cost = 5*cost_bbox+ 2*cost_class + 2*cost_giou + 100.0 * (~is_in_boxes_and_center) cost[~fg_mask] = cost[~fg_mask] + 10000.0 # (500,3) indices_batchi, matched_qidx = self.dynamic_k_matching(cost, pair_wise_ious, bz_gtboxs.shape[0]) # k=5 动态匹配: def dynamic_k_matching(self, cost, pair_wise_ious, num_gt): matching_matrix = torch.zeros_like(cost) # [300,num_gt] ious_in_boxes_matrix = pair_wise_ious n_candidate_k = self.ota_k # Take the sum of the predicted value and the top 10 iou of gt with the largest iou as dynamic_k topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=0) # (500,3) -> (5,3) dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1) # sum(5,3) -> (3) for gt_idx in range(num_gt): _, pos_idx = torch.topk(cost[:, gt_idx], k=dynamic_ks[gt_idx].item(), largest=False) # [376] 500中分数最大的那一个索引 matching_matrix[:, gt_idx][pos_idx] = 1.0 # (500,3)中只有3个1 anchor_matching_gt = matching_matrix.sum(1) selected_query = matching_matrix.sum(1) > 0 # (500) :[F,F,F,F...T,F] gt_indices = matching_matrix[selected_query].max(1)[1] # [1,0,2] assert selected_query.sum() == len(gt_indices) cost[matching_matrix == 0] = cost[matching_matrix == 0] + float('inf') matched_query_id = torch.min(cost, dim=0)[1] # [ 376, 32, 403 ] return (selected_query, gt_indices), matched_query_id 4.更新损失 losses = {} or loss in self.losses: losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes)) # 循环6次,把6次解码损失,按同样方法计算,并更新损失 if 'aux_outputs' in outputs: for i, aux_outputs in enumerate(outputs['aux_outputs']): indices, _ = self.matcher(aux_outputs, targets)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
其实代码更像是Cascade-RCNN,只是初始anchor是随机生成,并利用DDPM公式做了解码。
3.Hungarian 损失
匈牙利损失最近常见,如DETR等,用于将perd 与 GT 做无序匹配。这里把代码做以分析:
with torch.no_grad(): bz_boxes = out_bbox[batch_idx] # [500, 4] 预测的绝对坐标:xyxy bz_out_prob = out_prob[batch_idx] # [500, 80] 预测类别 bz_tgt_ids = targets[batch_idx]["labels"] # [ 29, 0, 3 ] bz_gtboxs = targets[batch_idx]['boxes'] # [num_gt, 4] 归一化的 (cx, xy, w, h) bz_gtboxs_abs_xyxy = targets[batch_idx]['boxes_xyxy'] fg_mask, is_in_boxes_and_center = self.get_in_boxes_info( box_xyxy_to_cxcywh(bz_boxes), box_xyxy_to_cxcywh(bz_gtboxs_abs_xyxy), expanded_strides=32 ) xy_target_gts = box_cxcywh_to_xyxy(target_gts) # (x1, y1, x2, y2) (num_gt=3,4) anchor_center_x = boxes[:, 0].unsqueeze(1) anchor_center_y = boxes[:, 1].unsqueeze(1) # whether the center of each anchor is inside a gt box b_l = anchor_center_x > xy_target_gts[:, 0].unsqueeze(0) # (500,gt=3) b_r = anchor_center_x < xy_target_gts[:, 2].unsqueeze(0) b_t = anchor_center_y > xy_target_gts[:, 1].unsqueeze(0) b_b = anchor_center_y < xy_target_gts[:, 3].unsqueeze(0) # (b_l.long()+b_r.long()+b_t.long()+b_b.long())==4 [300,num_gt] , is_in_boxes = ((b_l.long() + b_r.long() + b_t.long() + b_b.long()) == 4) # (500,gt=3) is_in_boxes_all = is_in_boxes.sum(1) > 0 # (500) is_in_boxes_all.sum()=12 center_radius = 2.5 # 用预测(anchor)框中心点与gt中心点距离判断: x_gt-x<2.5w x-x_gt<2.5w # https://github.com/dulucas/UVO_Challenge/blob/main/Track1/detection/mmdet/core/bbox/assigners/rpn_sim_ota_assigner.py#L212 b_l = anchor_center_x > (target_gts[:, 0] - (center_radius * (xy_target_gts[:, 2] - xy_target_gts[:, 0]))).unsqueeze(0) b_r = anchor_center_x < (target_gts[:, 0] + (center_radius * (xy_target_gts[:, 2] - xy_target_gts[:, 0]))).unsqueeze(0) b_t = anchor_center_y > (target_gts[:, 1] - (center_radius * (xy_target_gts[:, 3] - xy_target_gts[:, 1]))).unsqueeze(0) b_b = anchor_center_y < (target_gts[:, 1] + (center_radius * (xy_target_gts[:, 3] - xy_target_gts[:, 1]))).unsqueeze(0) is_in_centers = ((b_l.long() + b_r.long() + b_t.long() + b_b.long()) == 4) is_in_centers_all = is_in_centers.sum(1) > 0 is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all # (500) 212个true is_in_boxes_and_center = (is_in_boxes & is_in_centers) # (500,3) 12个true return is_in_boxes_anchor, is_in_boxes_and_center pair_wise_ious = ops.box_iou(bz_boxes, bz_gtboxs_abs_xyxy) # (500,3) torchvision.ops if self.use_focal: alpha = self.focal_loss_alpha # 0.25 gamma = self.focal_loss_gamma # 2 neg_cost_class = (1 - alpha) * (bz_out_prob ** gamma) * (-(1 - bz_out_prob + 1e-8).log()) # (500,80) pos_cost_class = alpha * ((1 - bz_out_prob) ** gamma) * (-(bz_out_prob + 1e-8).log()) # bz_out_prob=[29,0,0] cost_class = pos_cost_class[:, bz_tgt_ids] - neg_cost_class[:, bz_tgt_ids] # (500,3) bz_image_size_out = targets[batch_idx]['image_size_xyxy'] # (4) bz_image_size_tgt = targets[batch_idx]['image_size_xyxy_tgt'] # (3,4) bz_out_bbox_ = bz_boxes / bz_image_size_out # normalize (500,4)(x1, y1, x2, y2) bz_tgt_bbox_ = bz_gtboxs_abs_xyxy / bz_image_size_tgt # normalize (3,4) (x1, y1, x2, y2) cost_bbox = torch.cdist(bz_out_bbox_, bz_tgt_bbox_, p=1) # (500,3=gt) cost_giou = -generalized_box_iou(bz_boxes, bz_gtboxs_abs_xyxy) # (500,3) 绝对坐标 xyxy的iou cost = 5 * cost_bbox + 2 * cost_class + 2 * cost_giou + 100.0 * (~is_in_boxes_and_center) cost[~fg_mask] = cost[~fg_mask] + 10000.0 # (288,3) negtive sample indices_batchi, matched_qidx = self.dynamic_k_matching(cost, pair_wise_ious, bz_gtboxs.shape[0]) # bz_gtboxs:归一化xywh indices.append(indices_batchi) matched_ids.append(matched_qidx) return indices, matched_ids- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
iou函数:
def box_iou(boxes1, boxes2): area1 = box_area(boxes1) area2 = box_area(boxes2) lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2] rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2] wh = (rb - lt).clamp(min=0) # [N,M,2] inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] union = area1[:, None] + area2 - inter iou = inter / union return iou, union def generalized_box_iou(boxes1, boxes2): assert (boxes1[:, 2:] >= boxes1[:, :2]).all() assert (boxes2[:, 2:] >= boxes2[:, :2]).all() iou, union = box_iou(boxes1, boxes2) lt = torch.min(boxes1[:, None, :2], boxes2[:, :2]) rb = torch.max(boxes1[:, None, 2:], boxes2[:, 2:]) wh = (rb - lt).clamp(min=0) # [N,M,2] area = wh[:, :, 0] * wh[:, :, 1] return iou - (area - union) / area- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
总结
在这项工作中,我们提出了一种新的检测范式,扩散det,通过将目标检测视为一个从噪声box到物体box的去噪扩散过程。我们的 noise-> box 管道有几个吸引人的特性,包括动态box 和逐步细化,使我们能够使用相同的网络参数来获得所需的速度-精度的权衡,而不需要重新训练模型。在标准检测基准上的实验表明,与成熟的探测器相比,扩散器取得了良好的性能。为了进一步探索扩散模型在解决对象级识别任务中的潜力,未来的一些工作是有益的。一种尝试将扩散数据应用于视频层任务,例如物体跟踪和动作识别。另一种方法是将扩散网络从封闭世界扩展到开放世界或开放词汇表对象检测。
-
相关阅读:
spring源码篇(八)事务的原理
淘宝API接口参考
阿里云服务器价格表,轻量和服务器最新活动价格表汇总
[附源码]java毕业设计大学生足球预约信息
大小屏适配
Spring Boot中的max-http-header-size配置
CUDA工程的CMakeLists.txt
Python爬虫html网址实战笔记
Codeforces Round #835 (Div. 4)A.B.C.D.E.F
设计模式之职责链模式应用例题
- 原文地址:https://blog.csdn.net/qq_45752541/article/details/128014839
