-
CUDA 编程简介
参考资料:
- NVIDIA CUDA Programming Guide, NVIDIA. (https://docs.nvidia.com/cuda/cuda-c-programming-guide/)
- 国科大《并行与分布式计算》课程、NVIDIA 在线实验平台
GPU & CUDA
CPU 与 GPU 的硬件结构:

可以看出,GPU 与 CPU 本质上没什么区别。仅仅是 GPU 的逻辑控制单元较为简单,并拥有大量的运算单元(共享内存的众核处理器)。
GPU 除了图像处理,也可以做科学计算,然而 GPU 的 API 特别难用。CUDA(Compute Unified Device Architecture)是一种简单的轻量级软件,方便人们在 GPU 上编程。
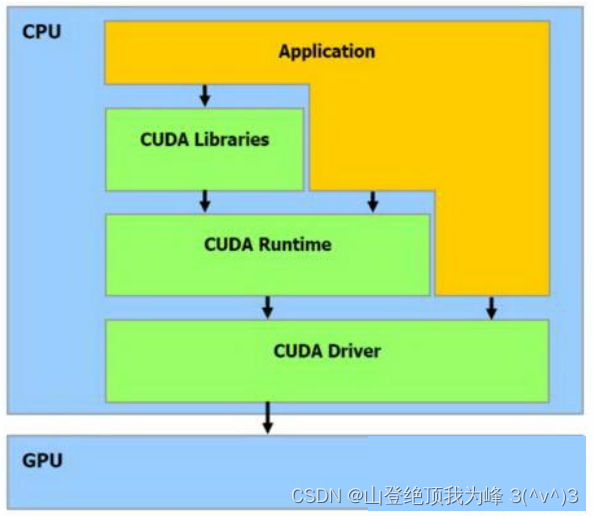
CUDA 软件栈:
下面,我们举例 Nvidia Tesla 架构,G80 型号。
G80 Graphics Mode

- SP:流处理器(streaming processors)。就是一个核(core),包含浮点运算单元 FP Unit、整数运算单元 INT Unit 以及其他部件。
- TF:纹理(texture)单元
- FB:帧(frame)缓存
G80 CUDA Mode

- Parallel Data Cache:严格地说不是 cache,数据的读写由软件操纵
- Load/Store:数据总线
- Global Memory:整个 GPU 的共享内存(显存)
流多处理器(Streaming Multiprocessor,SM):

- SFU:Special Function Units,用于加速特殊函数(sin, cos, tan)的计算
- I cache:Instruction cache,缓存指令
- C cache:Constant cache,缓存常数(只读)
- Shared memory:片上的 Parallel Data Cache,它不是 cache
汇总一下,G80 CUDA Mode 的结构图,如下:

- 一个 G80 上,包含 8 8 8 片 TPC(Texture Processor Cluster)
- 一片 TPC 上,包含 2 2 2 个 SM
- 一个 SM 上,包含 8 8 8 个 SP 以及 2 2 2 个 SFU
CUDA Programming Model
CUDA 采用 SPMD(Single Program/Multiple Data)模式:由 CPU 上串行的 host 发起在 GPU 上并行的 kernel 线程,最后汇总结果到 host 上继续串行执行。核函数启动方式为异步,CPU 代码将继续执行,无需等待核函数完成启动,也不等待核函数在 device 上完成。

线程层次结构:
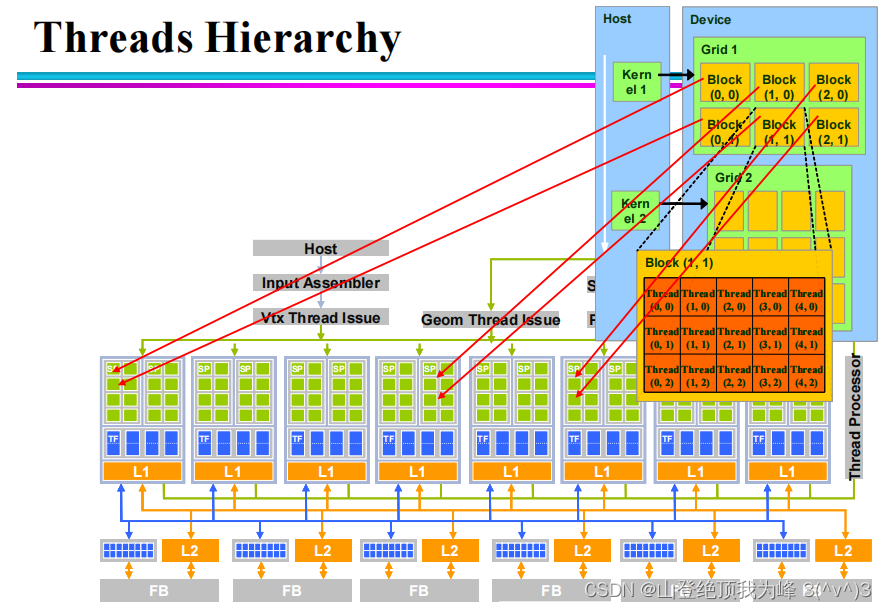
- 每当一个 kernel 被调用,需要配置一个网格(grid)。数据在 global memory 上共享。
- 每个 grid 包含多个块(block),可以按照 1D, 2D, 3D 组织起来。数据在 shared memory 上共享。
- 每个 block 都有相同数量(至多 512 512 512 个)的线程(thread),可以按照 1D, 2D, 3D 组织起来。
- GPU 的线程管理器按 block 调度,每次将 1 1 1 个 block 的任务分配到 1 1 1 个 SM 上。可以同时有多个 block 被调度到同一个 SM 上。实质上,线程在 GPU 上不是完全并行,而是分时复用。
- 每个 block 的线程被切分为若干 warp,每个 warp 包含 32 32 32 个线程。SM 上按照 warp 执行,一旦 warp 内所有线程在某条指令上(SIMD)都 ready,那么在此 SM 包含的 8 8 8 个 SP 上 32 / 8 = 4 32/8=4 32/8=4 cycles 执行完毕。只要 warp 足够多,那么 GPU 将会满负载运行,总有一些 warp 已经 ready。
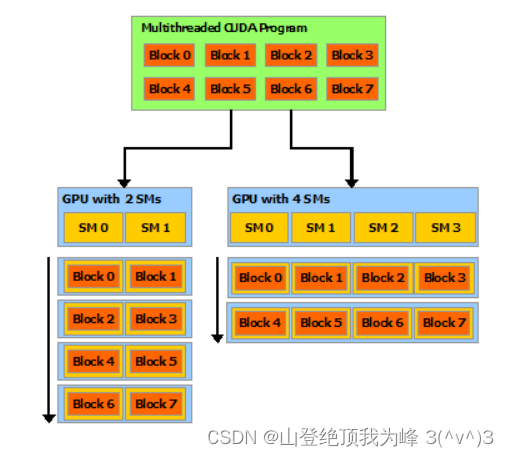
同一个 block 内的 threads 可以互操作:shared memory、atomic operations(原子,避免访存冲突)、barrier sychronization(同步,避免竞争条件)。而不同的 block 内的不可以,因为内存的时空不相交。
对比下 GPU 和 CUDA 的软硬件:
-
Tesla CUDA Mode:
GPU-TPC-SM-SP -
Threads Hierarchy:
device-grid-block-thread
CUDA Extends C
Declaration
变量类型限定符:
__device__:位于 global memory(显存),作用范围是 grid,生命周期 application,host 知道地址。__shared__:位于 shared memory(片上内存),作用范围是 block,生命周期 block,host 不知道地址。__local__:位于 local memory(显存上的虚拟空间),作用范围是 thread,生命周期 thread,host 不知道地址。__constant__,位于 constant memory(显存上的虚拟空间),作用范围是 grid,生命周期 application,host 知道地址。- automatice:不加限定符,位于 SM 的寄存器(register)或者 local memory 上,作用范围是 thread,生命周期 thread,host 不知道地址。
例如,
__shared__ int a = 1;- 1
函数类型限定符:
__host__:在 host 上执行,被 host 调用__global__:在 device 上执行,被 host 调用__device__:在 device 执行,被 device 调用
例如,
__global__ void kernel(int* arr);- 1
Keywords
变量类型:
int4:结构体,含 4 4 4 个整型,成员.x,.y,.z,.wfloat4:结构体,含 4 4 4 个浮点型,成员.x,.y,.z,.wdim3:结构体
例如,
int4 ver(1,2,3,4); int a = ver.x;- 1
- 2
保留字:
- gridDim:类型 dim3,grid 组织结构,成员
.x,.y,不使用.z - blockDim:类型 dim3,block 组织结构,成员
.x,.y,.z - blockIdx:类型 dim3,block 在 grid 内的 index,成员
.x,.y,.z - threadIdx:类型 dim3,thread 在 block 内的 index,成员
.x,.y,.z
例如,
int i = threadIdx.x + blockIdx.x * blockDim.x;- 1
API
__syncthreads():同步 block,使得这一个 block 内的 threads 执行完毕,然后才能继续执行后续指令。cudaDeviceSynchronize():同步 grid,导致主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。cudaMalloc(void** ptr, size_t size):在 global memory 上分配内存。cudaFree():释放 global memory。cudaMemcpy(dst, src, size, type):同步的,在 host 与 device 之间迁移数据。迁移类型 type 的取值有:cudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyHostToHostcudaMemcpyDeviceToDevice
cudaMemcpyAsync():异步的,在 host 与 device 之间迁移数据。不等待迁移完成。cudaMallocManaged(void** ptr, size_t size):被包装的 API,在“一致内存”(UM)上分配内存,数据会自动在 CPU 和 GPU 上来回迁移。cudaFree(void* ptr):释放内存。
例如,
int N = 2<<20; size_t size = N * sizeof(int); int *a; cudaMallocManaged(&a, size); // Use `a` on the CPU and/or on any GPU in the accelerated system. cudaFree(a);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
更多 API 详见 CUDA 文档 #api-reference。
Error
许多 CUDA 函数(例如 内存管理函数 等)会返回类型为
cudaError_t的值,该值可用于检查调用函数时是否发生错误。cudaError_t cudaGetLastError():捕获前一个错误cudaGetErrorString(cudaError_t err):打印错误信息
为捕捉异步错误(例如,在异步核函数执行期间),请务必检查后续同步 CUDA 运行时 API 调用所返回的状态(例如
cudaDeviceSynchronize);如果之前启动的其中一个核函数失败,则将返回错误。例如,
#include#include inline cudaError_t checkCuda(cudaError_t result) { if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", \\ cudaGetErrorString(result)); assert(result == cudaSuccess); } return result; } int main() { //捕获最近的一个错误 kernel<<<1, -1>>>(); // -1 is not a valid number of threads. cudaError_t err = cudaGetLastError(); checkCuda(err); //捕获异步错误 kernel<<<2, 5>>>(); checkCuda(cudaDeviceSynchronize()); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Function launch
KernelFunc<<:在 host 上配置 kernel,配置 block 的数量、每个 block 包含多少个 threads、使用的 shared memory 的空间大小。例如,
dim3 dimGrid(2, 2); //grid包含4个blocks dim3 dimBlock(4, 2, 2); //block包含16个threads size_t Bytes = 64; //shared memory大小为64字节 kernel<<- 1
- 2
- 3
- 4
NVCC
CUDA 平台附带 NVIDIA CUDA 编译器
nvcc,可以编译 CUDA 加速应用程序,其中包含主机和设备代码。nvcc -arch=sm_70 -o out some-CUDA.cu -run- 1
-
相关阅读:
【博客446】ovs控制工具的区别和使用
mac的m1芯片安装nvm踩坑完全版
【JS缓存技术】-本地存储
[附源码]计算机毕业设计JAVA广州中小学学校信息管理系统
dubbo的Failed to save registry store file问题
everything的高效使用方法
camunda7流程跳转和流程退回的实现方法
Java 17新特性,是真的猛,惊呆了!
数据仓库项目从来不是技术项目
GBase 8c V3.0.0数据类型——EXTRACT
- 原文地址:https://blog.csdn.net/weixin_44885334/article/details/128167526
