-
AE& VAE 代码和结果记录
关于原理,网上讲的太多了,我就直接上代码了。
Auto Encoder 在MNIST 上记录
直接上代码
import os os.chdir(os.path.dirname(__file__)) import torch import torch.nn as nn import torch.nn.functional as F import torchvision from torchvision import transforms from torchvision.utils import save_image from torch.utils.tensorboard import SummaryWriter device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') sample_dir = 'samples' if not os.path.exists(sample_dir): os.makedirs(sample_dir, exist_ok=True) writer = SummaryWriter(sample_dir) # Hyper-parameters image_size = 784 h_dim = 400 z_dim = 20 num_epochs = 15 batch_size = 128 learning_rate = 1e-3 # MNIST dataset dataset_train = torchvision.datasets.MNIST(root='../data', train=True, transform=transforms.ToTensor(), download=True) dataset_test = torchvision.datasets.MNIST(root='../data', train=False, transform=transforms.ToTensor(), download=True) data_loader_train = torch.utils.data.DataLoader(dataset=dataset_train, batch_size=batch_size, shuffle=True) data_loader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=batch_size, shuffle=False) # AE model class AE(nn.Module): def __init__(self, image_size=784, h_dim=400, z_dim=20): super(AE, self).__init__() self.fc1 = nn.Linear(image_size, h_dim) self.fc2 = nn.Linear(h_dim, z_dim) # self.fc3 = nn.Linear(h_dim, z_dim) self.fc4 = nn.Linear(z_dim, h_dim) self.fc5 = nn.Linear(h_dim, image_size) def encode(self, x): x = F.relu(self.fc1(x)) h = F.relu(self.fc2(x)) return h def decode(self, z): h = F.relu(self.fc4(z)) return F.sigmoid(self.fc5(h)) def forward(self, x): h = self.encode(x) x_recon = self.decode(h) return x_recon def reconstruct_loss_binaray(x, y): return F.binary_cross_entropy(x, y, size_average=False) def reconstruct_loss_real(x, y): return F.mse_loss(x, y) model = AE().to(device) writer.add_graph(model, input_to_model=torch.rand(1, 28 * 28).to(device)) optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) ld = len(data_loader_train) accumulated_iter = 0 for epoch in range(num_epochs): for i, (x, _) in enumerate(data_loader_train): # forward x = x.to(device).view(-1, image_size) x_recon = model(x) loss = reconstruct_loss_real(x_recon, x) optimizer.zero_grad() loss.backward() optimizer.step() accumulated_iter += 1 writer.add_scalar('loss', loss.item(), global_step=accumulated_iter) if (i+1) % 10 == 0: print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}".format(epoch+1, num_epochs, i+1, ld, loss.item())) # 根据test数据集来看重建效果 # with torch.no_grad(): # x,_ = iter(data_loader_test).next() # x = x.to(device).view(-1, image_size) # x_recon = model(x).view(-1, 1, 28, 28) # writer.add_images('images_src', x.view(-1, 1, 28, 28), global_step=epoch) # writer.add_images('images_reconst', x_recon, global_step=epoch) # 根据随机变量decode来看重建效果 with torch.no_grad(): z = torch.randn(batch_size, z_dim).to(device) x_recon = model.decode(z).view(-1, 1, 28, 28) writer.add_images('images_reconst', x_recon, global_step=epoch) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
loss函数用了两种,一种MSE,一种是CrossEntropy。测试阶段尝试两种,一种是用test集合做测试,一种是随机给一个隐变量,解码出一个结果,效果分别如下:
test测试集效果如下

随机隐变量效果如下,可以看到非常差

Variational Auto Encoder 在MNIST 上记录
代码如下,只有model和部分训练代码有修改
import os os.chdir(os.path.dirname(__file__)) import torch import torch.nn as nn import torch.nn.functional as F import torchvision from torchvision import transforms from torchvision.utils import save_image from torch.utils.tensorboard import SummaryWriter device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') sample_dir = 'samples' if not os.path.exists(sample_dir): os.makedirs(sample_dir, exist_ok=True) writer = SummaryWriter(sample_dir) # Hyper-parameters image_size = 784 h_dim = 400 z_dim = 20 num_epochs = 15 batch_size = 128 learning_rate = 1e-3 # MNIST dataset dataset_train = torchvision.datasets.MNIST(root='../data', train=True, transform=transforms.ToTensor(), download=True) dataset_test = torchvision.datasets.MNIST(root='../data', train=False, transform=transforms.ToTensor(), download=True) data_loader_train = torch.utils.data.DataLoader(dataset=dataset_train, batch_size=batch_size, shuffle=True) data_loader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=batch_size, shuffle=False) # VAE model class VAE(nn.Module): def __init__(self, image_size=784, h_dim=400, z_dim=20): super(VAE, self).__init__() self.fc1 = nn.Linear(image_size, h_dim) self.fc2 = nn.Linear(h_dim, z_dim) self.fc3 = nn.Linear(h_dim, z_dim) self.fc4 = nn.Linear(z_dim, h_dim) self.fc5 = nn.Linear(h_dim, image_size) def encode(self, x): h = F.relu(self.fc1(x)) return self.fc2(h), self.fc3(h) def decode(self, z): h = F.relu(self.fc4(z)) return F.sigmoid(self.fc5(h)) def reparameterize(self, mu, log_var): std = torch.exp(log_var/2) eps = torch.randn_like(std) return mu + eps * std def forward(self, x): mu, log_var = self.encode(x) z = self.reparameterize(mu, log_var) x_recon = self.decode(z) return x_recon, mu, log_var def reconstruct_loss_binaray(x, y): return F.binary_cross_entropy(x, y, size_average=False) def reconstruct_loss_real(x, y): return F.mse_loss(x, y) def kl_loss(mu, log_var): return -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) model = VAE().to(device) writer.add_graph(model, input_to_model=torch.rand(1, 28 * 28).to(device)) optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) ld = len(data_loader_train) accumulated_iter = 0 for epoch in range(num_epochs): for i, (x, _) in enumerate(data_loader_train): # forward x = x.to(device).view(-1, image_size) x_recon, mu, log_var = model(x) loss_rec = reconstruct_loss_binaray(x_recon, x) loss_kl = kl_loss(mu, log_var) loss = loss_rec + loss_kl optimizer.zero_grad() loss.backward() optimizer.step() accumulated_iter += 1 writer.add_scalar('loss', loss.item(), global_step=accumulated_iter) if (i+1) % 10 == 0: print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Loss: {:.4f}.".format(epoch+1, num_epochs, i+1, ld, loss_rec.item(), loss_kl.item())) # 根据test数据集来看重建效果 with torch.no_grad(): x,_ = iter(data_loader_test).next() x = x.to(device).view(-1, image_size) x_recon,_,_ = model(x) x_recon = x_recon.view(-1, 1, 28, 28) writer.add_images('images_src', x.view(-1, 1, 28, 28), global_step=epoch) writer.add_images('images_reconst', x_recon, global_step=epoch) # 根据随机变量decode来看重建效果 # with torch.no_grad(): # z = torch.randn(batch_size, z_dim).to(device) # x_recon = model.decode(z).view(-1, 1, 28, 28) # writer.add_images('images_reconst', x_recon, global_step=epoch) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
单独看测试集重建结果,区别不大

根据随机数重建的效果还可以,比AE强很多了。
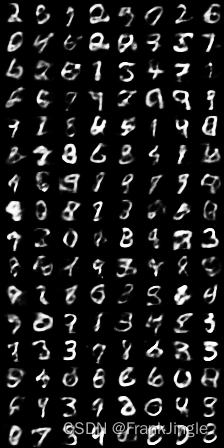
这里也试试把隐变量Z设为全0,然后前两维进行一个遍历,看看输出的结果是不是有某种规律,代码如下with torch.no_grad(): x_all = torch.zeros(10, 10, 1, 28, 28).to(device) for a, da in enumerate(torch.linspace(-0.5, 0.5, 10)): for b, db in enumerate(torch.linspace(-0.5, 0.5, 10)): z = torch.zeros(1, z_dim).to(device) z[0, 0] = da z[0, 1] = db x_recon = model.decode(z).view(-1, 1, 28, 28) x_all[a,b] = x_recon[0] x_all = x_all.view(10*10, 1, 28, 28) imgs = torchvision.utils.make_grid(x_all, pad_value=2,nrow=10) writer.add_image('images_uniform', imgs, epoch, dataformats='CHW')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
图片太小,不是很清晰,但是也能很明显的看到图像沿着x和y轴在发生形变

Auto Encoder 在Anime 上记录
这里我们试试更加复杂的数据集,二次元头像数据集,数据集下载自 https://github.com/jayleicn/animeGAN
并且我们也把模型改成CNN进行尝试
代码如下import os os.chdir(os.path.dirname(__file__)) import torch import torch.nn as nn import torch.nn.functional as F import torchvision import torchvision.datasets as dset from torchvision import transforms from torchvision.utils import save_image from torch.utils.tensorboard import SummaryWriter device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') sample_dir = 'samples' if not os.path.exists(sample_dir): os.makedirs(sample_dir, exist_ok=True) writer = SummaryWriter(sample_dir) # Hyper-parameters h_dim = 1024 z_dim = 32 num_epochs = 15 batch_size = 128 learning_rate = 1e-3 data_root = '../data/anime-faces' # Anime dataset def is_valid_file(fpath): fname = os.path.basename(fpath) return fname[0] != '.' T = transforms.Compose([ transforms.Scale(64), transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # bring images to (-1,1) ]) dataset = dset.ImageFolder( root=data_root, transform=T, is_valid_file=is_valid_file ) data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=1) # AE model class AE(nn.Module): def __init__(self, h_dim=h_dim, z_dim=z_dim): super(AE, self).__init__() self.conv1 = nn.Conv2d(3, 32, 4, stride=2, padding=1) self.conv2 = nn.Conv2d(32, 64, 4, stride=2, padding=1) self.conv3 = nn.Conv2d(64, 128, 4, stride=2, padding=1) self.conv4 = nn.Conv2d(128, 256, 4, stride=2, padding=1) self.fc1 = nn.Linear(4096, h_dim) self.fc2 = nn.Linear(h_dim, z_dim) self.deconv1 = nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1) self.deconv2 = nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1) self.deconv3 = nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1) self.deconv4 = nn.ConvTranspose2d(32, 3, 4, stride=2, padding=1) self.fc3 = nn.Linear(z_dim, h_dim) self.fc4 = nn.Linear(h_dim, 4096) def encode(self, x): bz = x.shape[0] # 128 x 3 x 64 x 64 x = F.relu(self.conv1(x)) # 128 x 32 x 32 x 32 x = F.relu(self.conv2(x)) # 128 x 64 x 16 x 16 x = F.relu(self.conv3(x)) # 128 x 128 x 8 x 8 x = F.relu(self.conv4(x)) # 128 x 256 x 4 x 4 x = torch.flatten(x, start_dim=1) # 128 x 4096 h = F.relu(self.fc1(x)) # 128 x 1024 z = F.relu(self.fc2(h)) # 128 x 32 return z def decode(self, z): h = F.relu(self.fc3(z)) # 128 x 1024 x = F.relu(self.fc4(h)) # 128 x 512 x = x.view(-1, 256, 4, 4) # 128 x 256 x 4 x 4 x = F.relu(self.deconv1(x)) # 128 x 128 x 8 x 8 x = F.relu(self.deconv2(x)) # 128 x 64 x 16 x 16 x = F.relu(self.deconv3(x)) # 128 x 32 x 32 x 32 x = F.tanh(self.deconv4(x)) # 128 x 3 x 64 x 64 return x def forward(self, x): h = self.encode(x) x_recon = self.decode(h) return x_recon def reconstruct_loss_binaray(x, y): return F.binary_cross_entropy(x, y, size_average=False) def reconstruct_loss_real(x, y): return F.mse_loss(x, y, size_average=False) model = AE().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) ld = len(data_loader) accumulated_iter = 0 for epoch in range(num_epochs): for i, (x, _) in enumerate(data_loader): # forward x = x.to(device) x_recon = model(x) loss = reconstruct_loss_real(x_recon, x) optimizer.zero_grad() loss.backward() optimizer.step() accumulated_iter += 1 writer.add_scalar('loss', loss.item(), global_step=accumulated_iter) if (i+1) % 10 == 0: print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}".format(epoch+1, num_epochs, i+1, ld, loss.item())) # 根据test数据集来看重建效果 with torch.no_grad(): x,_ = iter(data_loader).next() x = x.to(device) x_recon = model(x) imgs_src = torchvision.utils.make_grid(x, pad_value=2, normalize=True) writer.add_image('images_src', imgs_src, epoch, dataformats='CHW') imgs_rec = torchvision.utils.make_grid(x_recon, pad_value=2, normalize=True) writer.add_image('images_reconst', imgs_rec, epoch, dataformats='CHW') # 根据随机变量decode来看重建效果 with torch.no_grad(): z = torch.randn(batch_size, z_dim).to(device) x_recon = model.decode(z).view(-1, 3, 64, 64) imgs_rand = torchvision.utils.make_grid(x_recon, pad_value=2, normalize=True) writer.add_image('images_random', imgs_rand, epoch, dataformats='CHW') writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
针对代码,补充一句,里面计算loss时的
size_average=False非常重要,不加上的话训练会出问题。重建的效果如下,看着马马虎虎,比较模糊,没有好好调代码,应该还可以提升

随机生成的效果就非常差了

VAE 在Anime 上记录
再看看VAE的效果。
代码我就不重复贴这么多了,把模型部分贴上来
# VAE model class VAE(nn.Module): def __init__(self, h_dim=h_dim, z_dim=z_dim): super(VAE, self).__init__() self.conv1 = nn.Conv2d(3, 32, 4, stride=2, padding=1) self.conv2 = nn.Conv2d(32, 64, 4, stride=2, padding=1) self.conv3 = nn.Conv2d(64, 128, 4, stride=2, padding=1) self.conv4 = nn.Conv2d(128, 256, 4, stride=2, padding=1) self.fc1 = nn.Linear(4096, h_dim) self.fc2_1 = nn.Linear(h_dim, z_dim) self.fc2_2 = nn.Linear(h_dim, z_dim) self.deconv1 = nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1) self.deconv2 = nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1) self.deconv3 = nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1) self.deconv4 = nn.ConvTranspose2d(32, 3, 4, stride=2, padding=1) self.fc3 = nn.Linear(z_dim, h_dim) self.fc4 = nn.Linear(h_dim, 4096) def reparameterize(self, mu, log_var): std = torch.exp(log_var/2) eps = torch.randn_like(std) return mu + eps * std def encode(self, x): bz = x.shape[0] # 128 x 3 x 64 x 64 x = F.relu(self.conv1(x)) # 128 x 32 x 32 x 32 x = F.relu(self.conv2(x)) # 128 x 64 x 16 x 16 x = F.relu(self.conv3(x)) # 128 x 128 x 8 x 8 x = F.relu(self.conv4(x)) # 128 x 256 x 4 x 4 x = torch.flatten(x, start_dim=1) # 128 x 4096 h = F.relu(self.fc1(x)) # 128 x 1024 return self.fc2_1(h), self.fc2_2(h), # 128 x 30 def decode(self, z): h = F.relu(self.fc3(z)) # 128 x 1024 x = F.relu(self.fc4(h)) # 128 x 512 x = x.view(-1, 256, 4, 4) # 128 x 256 x 4 x 4 x = F.relu(self.deconv1(x)) # 128 x 128 x 8 x 8 x = F.relu(self.deconv2(x)) # 128 x 64 x 16 x 16 x = F.relu(self.deconv3(x)) # 128 x 32 x 32 x 32 x = F.tanh(self.deconv4(x)) # 128 x 3 x 64 x 64 return x def forward(self, x): mu, log_var = self.encode(x) z = self.reparameterize(mu, log_var) x_recon = self.decode(z) return x_recon, mu, log_var- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
再就是训练的时候
for epoch in range(num_epochs): for i, (x, _) in enumerate(data_loader): # forward x = x.to(device) x_recon, mu, log_var = model(x) loss_rec = reconstruct_loss_real(x_recon, x) loss_kl = kl_loss(mu, log_var) loss = loss_rec + loss_kl optimizer.zero_grad() loss.backward() optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
针对代码,补充一句,里面计算loss时的
size_average=False非常重要,不加上的话训练会出问题。但是有一个问题我没想明白,就是在我设为True的时候,为什么也会影响到kl_loss的计算出来的值的大小呢?设为True,kl_loss值非常小,设为False,值会比较大,按道理,这个的计算与计算重建loss是独立的才对。重建的结果

随机生成的结果

总结
VAE的变体非常的多,包括CNN做backbone也有很多不同设计,还有在loss的设计上,包括用Jaccard loss的
def continuous_jaccard(x, y): """ Implementation of the continuous version of the Jaccard distance: 1 - [sum_i min(x_i, y_i)] / [sum_i max(x_i, y_i)] """ c = torch.cat((x.view(-1).unsqueeze(1), y.view(-1).unsqueeze(1)), dim=1) numerator = torch.sum(torch.min(c, dim=1)[0]) denominator = torch.sum(torch.max(c, dim=1)[0]) return 1. - numerator/denominator- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
一种比较经典的变体是Conditional VAE,也叫CVAE,会把一些额外信息引入,比如,在encoder的时候,会把图片的label做编码(one-hot),然后和feature concat起来,作为隐式表达,在decoder的时候,也会送入想要生成那个类别,把这个类别也做one-hot,送进入参与decode过程,这样就可以自由控制想要生成的类别了。代码例如
def encoder(self, features, targets): ### Add condition onehot_targets = to_onehot(targets, self.num_classes, device) x = torch.cat((features, onehot_targets), dim=1) ### ENCODER x = self.hidden_1(x) x = F.leaky_relu(x) z_mean = self.z_mean(x) z_log_var = self.z_log_var(x) encoded = self.reparameterize(z_mean, z_log_var) return z_mean, z_log_var, encoded def decoder(self, encoded, targets): ### Add condition onehot_targets = to_onehot(targets, self.num_classes, device) encoded = torch.cat((encoded, onehot_targets), dim=1) ### DECODER x = self.linear_3(encoded) x = F.leaky_relu(x) x = self.linear_4(x) decoded = torch.sigmoid(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
感兴趣的可以参考 https://github.com/rasbt/deeplearning-models/tree/master/pytorch_ipynb/autoencoder
-
相关阅读:
revit二次开发——过滤器
Structured Streaming Source
基于检索增强的 GPT-3.5 的文本到 SQL 框架,具有样本感知提示和动态修订链。
Vue 通过 Hash、Histroy 实现一个SPA、VueRouter 的简单实现(分享)
php练习04
Spark - RDD 算子介绍及使用 Scala、Java、Python 三种语言演示
云存储解决方案-阿里云OSS
【数据结构】图的存储结构—邻接表
异常体系与项目实践
C++hello world出门遇到坑
- 原文地址:https://blog.csdn.net/fangjin_kl/article/details/127998348
